ElasticSearch查询
DSL查询
GET /hotel/_search
{
"query": {
"查询方式": {
"查询字段": "条件值"
}
}
}
查询全部
GET /hotel/_search
{
"query": {
"match_all": {}
}
}
结果:
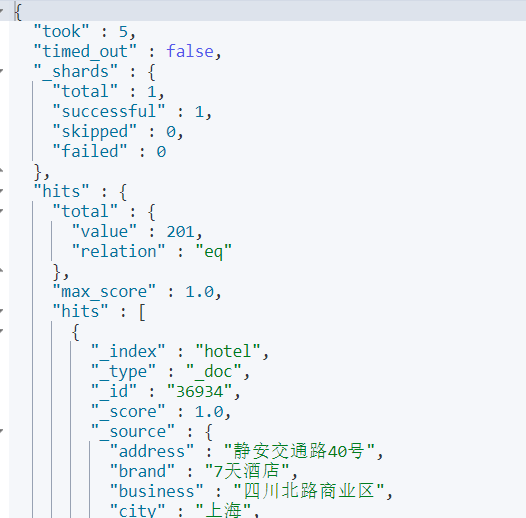
默认情况下并不返回所有,大概只返回十条数据,需要用到分页查询的语法才能查后面的。
全文检索查询
单字段查询:
GET /hotel/_search
{
"query": {
"match": {
"all": "上海速8酒店"
}
}
}
多字段查询:
GET /hotel/_search
{
"query": {
"multi_match": {
"query": "外滩上海如家",
"fields": ["all", "business"]
}
}
}
参与查询的字段越多查询的性能越低下,推荐将多个需要被全文检索参考的字段通过
copy_to拷贝到一个字段上,然后用单字段查询,比如上面的all。
精确匹配
term查询:
GET /hotel/_search
{
"query": {
"term": {
"city": {
"value": "上海"
}
}
}
}
range查询:
GET /hotel/_search
{
"query": {
"range": {
"price": {
"gte": 200,
"lte": 300
}
}
}
}
经纬度查询
矩形范围查询:
GET /hotel/_search
{
"query": {
"geo_bounding_box": {
"location": {
"top_left": {
"lat": 31.1,
"lon": 121.5
},
"bottom_right": {
"lat": 30.9,
"lon": 121.7
}
}
}
}
}
中心距离查询:
GET /hotel/_search
{
"query": {
"geo_distance": {
"distance": "15km",
"location": "31.21, 121.5"
}
}
}
重新算分
默认情况下,匹配搜索词越多的文档分数越高,但有时候,我们会对匹配结果中的某些文档进行重新算分,比如某些品牌竞价的情况下:
GET /hotel/_search
{
"query": {
"function_score": {
"query": {
"match": {
"all": "外滩"
}
},
"functions": [
{
"filter": {"term": {"brand": "如家"}},
"weight": 10
}
],
"boost_mode": "multiply"
}
}
}
functions可以指定一系列重新算分的函数用于对query中匹配到的结果进行重新算分,如果结果中包含filter指定的内容,就通过一个算分函数来重新算分。
weight是一个简单的只返回常量的算分函数,boost_mode指定了重新计算的分数和原分数之间的计算方式,multiply的意思是与原分数相乘,作为新的分数。
算分函数有如下几个要素:
- 过滤函数:过滤出要重新算分的文档
- 算分函数:计算出一个新的分数
- 加权方式:重新算出来的分数(function score)和查询出的分数(query score)如何计算
复合查询
复合查询是使用一系列逻辑运算来对多种条件进行运算,所以它的关键字是bool,也叫布尔查询。
以下是可用的一些逻辑运算:
must:必须匹配每个子查询,类似“与”should:选择性匹配每个子查询,类似“或”must_not:必须不匹配,不参与算分,类似“非”filter:必须匹配,不参与算分
原则:由于算分会消耗资源,所以除了用户输入文本查询之外,其它的查询条件都应该尽量使用不参与算分的查询方式,提升查询性能。
比如下面的例子,匹配在上海的,如家或者华美达,价格不能超过500,评分必须大于45的,虽然它明显不符合上面的原则:
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"city": {
"value": "上海"
}
}
}
],
"should": [
{
"term": {
"business": {
"value": "如家"
}
}
},
{
"term": {
"business": {
"value": "华美达"
}
}
}
],
"must_not": [
{
"range": {
"price": {
"gt": 500
}
}
}
],
"filter": [
{
"range": {
"score": {
"gte": 45
}
}
}
]
}
}
}
搜索名字包含如家,价格不高于400,在31.21, 121.5周围10km范围内的酒店:
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{"match": {"name": "如家"}}
],
"must_not": [
{"range": {"price": {"gt": 400}}}
],
"filter": [
{"geo_distance": {
"distance": "10km",
"location": {
"lat": 31.21,
"lon": 121.5
}
}}
]
}
}
}
DSL查询总结
- 无条件查询,可以使用
match_all - 需要分词匹配的,可以使用
match - 精确匹配的,可以使用
term - 范围查询,可以使用
range - 经纬度相关的查询,可以使用
geo_bouding_box和geo_distance等 - 对于需要对查询结果进行重新算分的,可以使用
function_score查询 - 对于复合查询,可以使用
bool - 复合查询中,可以使用
must作为与条件,should作为或条件,还有不参与算分的must_not作为非条件,同样不参与算分的filter作为与条件
原则:
- 分词匹配的,匹配字段越少性能越高,可以在建立mapping时使用
copy_to将它们都复制到一个字段 - 复合查询时,参与算分的字段越少性能越高,所以,只将用户输入的需要分词匹配的字段放到需要算分的条件中
DSL查询结果处理
排序
默认ES会通过打分算法将查询结果打分,并按照分数排序,如果你指定了排序算法,就无需进行打分操作了。
可以排序的类型
- 数值
- 日期
- keyword(字典序)
- 地理坐标
查询所有酒店,按照用户评分降序排序,当评分相同时,按照价格升序排序:
GET /hotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"score": {
"order": "desc"
},
"price": {
"order": "asc"
}
}
]
}
值得注意的是,当你指定了排序方式后,再次查询时ES用于对文档进行打分的字段_score就为空了,也就是它不打分了,并且查询结果多了个sort属性,这里面就是用于排序的字段的值:
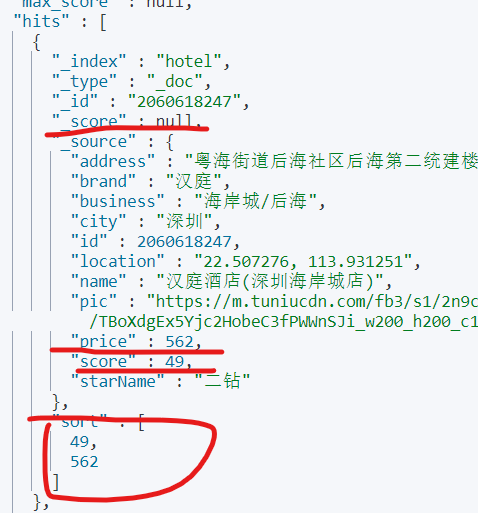
对于地理位置信息,用于排序的字段往往不直接是经纬度,而是距离某个经纬度的直线距离,所以,地理位置的排序稍微麻烦了一点:
GET /hotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance": {
"location": {
"lon": 121.13259,
"lat": 41.10093
},
"unit": "km",
"order": "asc"
}
}
]
}
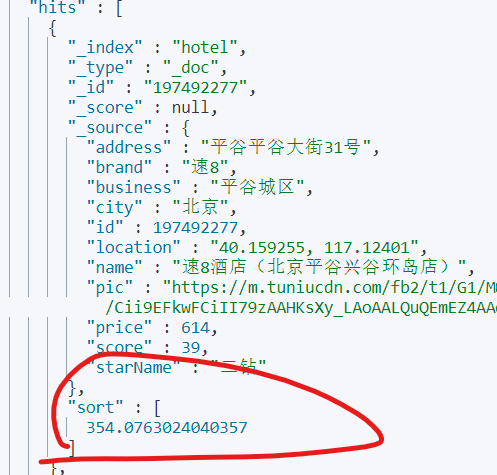
需要填写要与文档中的位置字段计算直线距离的另一个点的经纬度,unit指定的是出现在结果的sort中的数值的单位,从结果来看,排名第一的酒店距离我的直线距离为354km:
分页
ES默认只返回匹配的前十条的数据,如果你需要修改这个行为,你需要使用分页。
分页的两个参数是:from、size,相当于MySQL的offset和limit,下面的例子是按照price排序,并且从排序结果的第0个数据开始,返回20个数据
GET /hotel/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 20,
"sort": [
{
"price": "asc"
}
]
}
分页限制
考虑你现在要有一个from=990, size=10的分页,ES的索引结构导致它必须先将所有数据排序,然后获取前from+size条,在其中截取第990到999条(下标从0开始),它并不像MySQL这种B+树索引可以跳过前989条并直接拿到后面连续的10条。
当ES处于集群模式时,这个问题更加严重,集群中存储不一样的数据,如果此时有10台集群,那么每一个集群都要重复上面的内容,排序,找前1000条数据,但这时它们不能贸然的截取,然后它们要把各自的前1000条数据汇总,最终再次排序,找出实际的前1000条,并截取990~999条。所以,在集群的情况下,最终汇总排序的文档个数是(from + size) * 集群数量。
所以,在ES中,包括现在所有的搜索引擎技术中,都有这样一个痛点,就是from+size的组合不能太大,否则会影响性能。百度、京东等公司产品的搜索功能也都有这方面的限制。
ES的分页限制是from+size不能大于10000。
search after
一种解决深度分页时超出页数限制的办法。
它的思路和MySQL中在具有排序的查找中避免分页时需要扫描limit前所有数据的方式一样,考虑对MySQL进行分页,即在查询时记录页面当中的排序字段的最后一个值,下次直接通过一个条件过滤掉小于这个值的数据即可利用索引的高效性快速的跳过这些用不到的数据。
该方法也有一些限制:
- 查询必须对结果进行排序
- 必须记录排序属性的最后一个值
- 无法前向翻页,但适合手机向下滚动翻页的需求
关键字高亮
对于搜索类功能,常常需要的是将搜索结果中用户搜索的关键字高亮,ES也提供了这个功能。高亮只在分词模糊搜索时有意义。
你可以通过highlight来指定需要高亮的字段,一般情况下我们的搜索是通过一个聚合索引字段all来搜索的,但由于原文档中根本不包含all,所以我们不会对它来进行高亮(虽然这种行为也被允许)。
我们需要在highlight的fields属性中添加被高亮度字段,同时,该字段默认必须是在查询条件中的字段,但你可以通过require_field_match来指定它不必须在查询条件中,这比较复合我们的需求。
pre_tags和post_tags是在高亮字段前后添加的标签
GET /hotel/_search
{
"query": {
"match": {
"all": "如家"
}
},
"highlight": {
"fields": {
"name": {
"require_field_match": "false",
"pre_tags": "<em>",
"post_tags": "</em>"
}
}
}
}
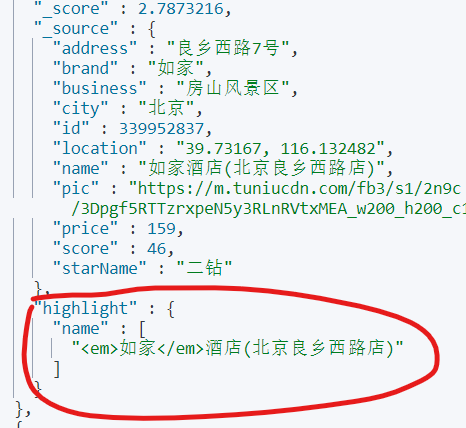
现在,在返回结果中,已经有了高亮结果:
注意,不管是排序还是高亮,它们都是在原文档之外提供了新的字段来表示,原文档是不会被修改的。所以,你需要自己用
highlight中的内容替换原来的内容

 浙公网安备 33010602011771号
浙公网安备 33010602011771号