Mybatis分页
RowBounds的内存分页#
SqlSession的各种查询方法中都有一个可选的RowBounds参数,该对象用于MyBatis实现内存分页:

RowBounds有这样两个属性:
private final int offset;
private final int limit;
limit是每一页中的记录条数,offset是当前选中的页偏移量,如果使用过数据库的分页,其实是很容易理解的。
你在Mapper中定义一个全表查找的Statement:
<select id="findInstructorByPage" resultType="Instructor">
SELECT * FROM instructor;
</select>
然后在查询这个Statement时传入RowBounds参数,Mybatis就会帮你实现分页:
private static final String STATEMENT_ID = "top.yudoge.mybatis.mapper.InstructorMapper.findInstructorByPage";
@Test
void testInIbatisWay() {
SqlSession session = SqlSessions.defaultSqlSession();
RowBounds rowBounds = new RowBounds(0, 5);
List<Instructor> instructors = session.selectList(STATEMENT_ID, null, rowBounds);
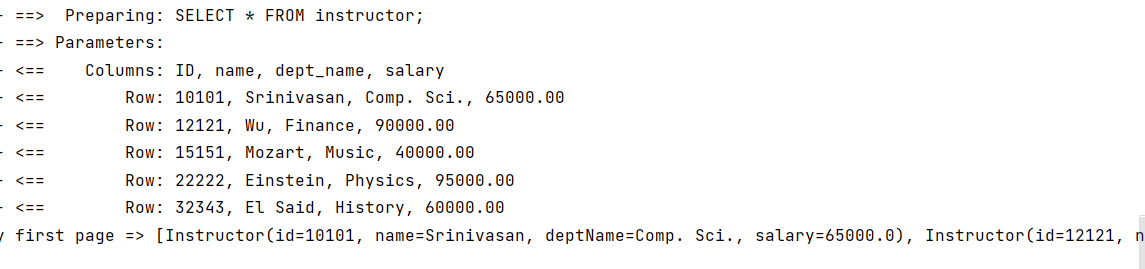
logger.info("Query first page => " + instructors);
}
查询出来的是全表的前五条数据。
你也可以使用MyBatis的接口方式:
List<Instructor> findInstructorByPage(RowBounds bounds);
RowBounds方式的限制#
从日志中可以看出,RowBounds方式分页发送的SQL语句依然是全表查询的语句,所以MyBatis实际上是将全表查询的数据拿到内存中进行内存分页。
而且,MyBatis的BaseExecutor创建缓存Key的方法中不知道出于什么考虑,将分页参数也作为缓存Key计算的一个指标,也就是虽然内存分页每次都把全表数据拿到了后端服务器,但是两次分页查找中如果limit或offset不同,依然用不到缓存。
对于这一点,我们可以测试:
@Test
void testQueryWithRowBounds() {
// 第一次发起,获取第0页
InstructorMapper instructorMapper = Mappers.getMapper(InstructorMapper.class);
RowBounds rowBounds = new RowBounds(0, 5);
List<Instructor> instructors = instructorMapper.findInstructorByPage(rowBounds);
logger.info("Query the first page => " + instructors);
// 第二次发起,获取第1页
RowBounds rowBounds1 = new RowBounds(1, 5);
List<Instructor> instructors1 = instructorMapper.findInstructorByPage(rowBounds1);
logger.info("Query the second page => " + instructors);
}
两次都实际发送了数据:
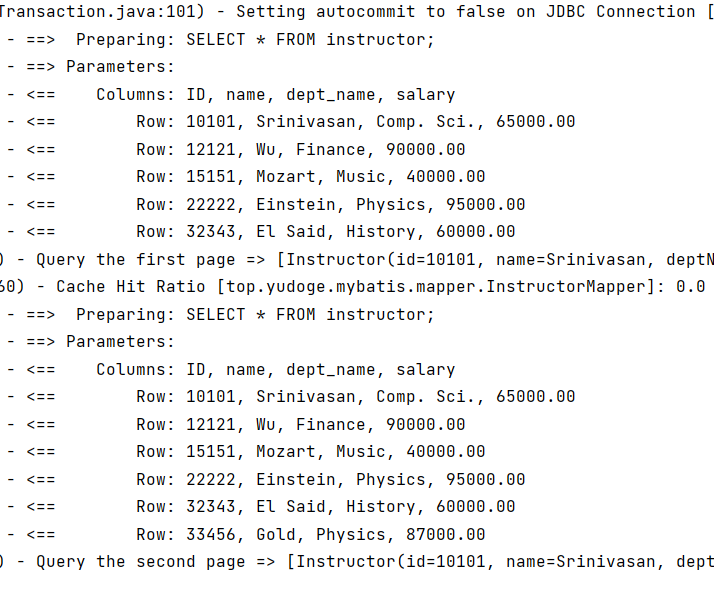
所以,RowBounds的每次分页都是一个全表扫描操作,并且多次之间,只要分页参数不同都无法用到缓存,即使理应使用缓存,无论从哪个角度来说,这种内置的分页方式都不是一个好的选择。
插件分页#
PageHelper是一款开源的MyBatis分页插件,它的原理就是使用MyBatis的插件接口——Interceptor,拦截SQL的执行,在执行之前修改SQL语句
配置pom:
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>${mybatis.pagehelper.version}</version>
</dependency>
将它作为plugin配置到mybatis中:
<plugins>
<plugin interceptor="com.github.pagehelper.PageInterceptor">
</plugin>
</plugins>
使用RowBounds方式#
在配置完插件以后,再使用RowBounds分页,PageHelper就会自动拦截到这个参数并且根据这个参数修改SQL语句:
@Test
void testRowBounds() {
InstructorMapper mapper = Mappers.getMapper(InstructorMapper.class);
List<Instructor> instructorList = mapper.findInstructorByPage(new RowBounds(0, 5));
logger.info("Query first page => " + instructorList);
}
此时,SQL语句已经加上了分页的子句:
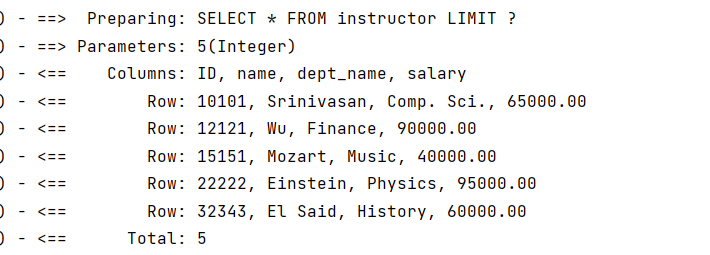
注意:使用该插件时确保你的SQL语句不是以分号结尾,该插件不会自动去除SQL语句末尾的分号
PageHelper方式#
在查询时先调用PageHelper.startPage或PageHelper.offsetPage来进行待查页面的设置:
@Test
void testPageHelper() {
PageHelper.startPage(1, 5);
InstructorMapper mapper = Mappers.getMapper(InstructorMapper.class);
List<Instructor> instructors = mapper.findInstructorByPage2();
logger.info("Query first page => " + instructors);
}
PageHelper使用一个ThreadLocal来保存当前线程私有的分页信息,所以这种查询方式(如果你应用得当的话)是线程安全的。
这种方式的一个问题就是,我们不知道当前的服务代码运行的线程的拥有者是谁。它是一个线程池吗?还是只是单独创建了一个线程,我的服务代码走完线程就会被销毁。
如果是线程池的话,我们的服务代码结束后,这个运行线程稍后有可能还会被其它服务代码使用,此时若ThreadLocal中的分页变量没有被清理,那这个分页变量可能会对其它服务代码造成副作用。
PageHelper提供了clearPage方法用于清除ThreadLocal中的分页变量:
PageHelper.clearPage();
即使你手动clearPage,在PageHelper的afterAll方法中,也会会自动调用clearPage:
@Override
public void afterAll() {
//这个方法即使不分页也会被执行,所以要判断 null
AbstractHelperDialect delegate = autoDialect.getDelegate();
if (delegate != null) {
delegate.afterAll();
autoDialect.clearDelegate();
}
clearPage();
}
注意:
afterAll是在插件的intercept方法中最后的finally块中被调用的,这意味着只要执行了查询操作,那么它怎样都会被调用,但同样也意味着,如果最终没执行查询,它就不会被调用,线程中的Page信息也不会被清理。所以,下面的代码可能会出现问题:
PageHelper.startPage(1, 10); if (someCondition) { mapper.doQuery(); } else { doSomeOtherThing(); }在上面的代码中,查询有可能执行,有可能不执行,但在查询未执行的分支中却没有任何手动清除线程私有分页变量的代码。在
else中添加PageHelper.clearPage即可解决问题。其实,更好的写法是将
PageHelper.startPage和mapper.doQuery紧挨在一起,中间不会有任何代码打破它们的顺序执行(比如异常、分支),除此之外,你都要周详的考虑异常的处理,如果由于异常导致查询不能被执行但分页信息已经记录也会出问题。try-finally块虽然可以解决问题,但它很容易被我们忘掉并且使我们的代码不美观。
Page对象#
可能你已经发现,当我们使用这个分页插件时,返回的数据已经不再是一个简单的List,它是一个Page对象:

它其中包含了页数,页大小,总页数和总条数等信息,这些信息经常需要被前端使用。(所以由此也可以断定,分页插件并不仅仅只是简单的拼接SQL,最起码,它还得发送额外的count语句来获取总记录数)
Page是ArrayList的一个子类:
public class Page<E> extends ArrayList<E> implements Closeable {
private static final long serialVersionUID = 1L;
所以,所有需要List的地方,分页插件都可以返回一个Page。
使用PageInfo对结果进行包装#
上面说了,使用分页插件之后,返回的实际对象不是List而是Page。
可是我们的Mapper接口中定义的都是List,List接口中没有那些总页数总条数的信息,所以即使返回了,我们也访问不到。这时我们可以用PageInfo类来包装这个List:
@Test
void testPageInfo() {
PageHelper.startPage(1, 5);
InstructorMapper mapper = Mappers.getMapper(InstructorMapper.class);
List<Instructor> instructors = mapper.findInstructorByPage2();
logger.info("Query first page => " + instructors);
PageInfo page = new PageInfo(instructors);
logger.info("Total page => " + page.getPages());
logger.info("Is first page => " + page.isIsFirstPage());
}
这样就可以访问返回页的一些信息了。
使用参数方式#
PageHelper允许使用Mapper的参数进行分页,在这之前,你需要先设置插件的两个属性:
<plugins>
<plugin interceptor="com.github.pagehelper.PageInterceptor">
<property name="supportMethodsArguments" value="true"/>
<property name="params" value="pageNum=pageNum;pageSize=pageSize;"/>
</plugin>
</plugins>
supportMethodsArguments属性开启方法参数的支持,params属性设置页号和页大小的参数名。
然后,Mapper方法中:
List<Instructor> findInstructorByPage3(
@Param("pageNum") Integer pageNum,
@Param("pageSize") Integer pageSize);
测试:
@Test
void testMethodArgument() {
InstructorMapper mapper = Mappers.getMapper(InstructorMapper.class);
List<Instructor> instructors = mapper.findInstructorByPage3(1, 5);
logger.info("Query first page => " + instructors);
}
作者:Yudoge
出处:https://www.cnblogs.com/lilpig/p/16524275.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
欢迎按协议规定转载,方便的话,发个站内信给我嗷~




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· winform 绘制太阳,地球,月球 运作规律
· 上周热点回顾(3.3-3.9)