Mybatis缓存
一级缓存的实现原理#
官方文档中说一级缓存是Session级别的,默认开启,我们看看它是怎么实现的。
去到DefaultSession中,里面并没有维护任何和缓存相关的成员变量,如果说非要有,可能就只有一个用于记录缓存是否变脏的dirty吧。
private boolean dirty;
查看clearCache的代码,其中将清除缓存的请求委托给了executor,也就是实际执行SQL语句的对象:
@Override
public void clearCache() {
executor.clearLocalCache();
}
这证明一级缓存是从Executor中实现的,BaseExecutor中实现了缓存功能,并声明了两个缓存:
public abstract class BaseExecutor implements Executor {
protected PerpetualCache localCache;
protected PerpetualCache localOutputParameterCache;
}
我还不知道第二个缓存是用来干啥的,MyBatis的源码中没有任何解释,先往下看源码。
query的执行步骤#
BaseExecutor的query方法中首先获取了缓存:
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
// 如果有必要刷新缓存,先清除缓存,从后面的代码中可以得知,queryStack貌似是当前正在执行查询的数量
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
// 尝试先从缓存中获取
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
// 如果取到了,调用本地的一个方法
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
}
// 如果没取到,从数据库获取
else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
// 好像有一个`localCacheScope`配置参数能配置一级缓存的作用域,如果作用域是语句,那么每次执行语句都清除缓存,这样的话缓存好像就没啥用了。
// 可选值有SESSION、STATEMENT
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
所以,MyBatis在查询时
- 尝试在
Executor的本地缓存中获取(根据计算出的CacheKey),如果取到,就使用缓存 - 否则去数据库获取
在第一步中,MyBatis还调用了一个本地方法——handleLocallyCachedOutputParameters,我们现在还不知道它是干啥的,不过从名字来看,它应该是用于操作localOutputParameterCache的
queryFromDatabase的执行步骤#
该方法的代码清晰明了:
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
// 先向`localCache`中存储一个占位符
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// 实际执行查询
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
// 移除占位符
localCache.removeObject(key);
}
// 实际添加缓存
localCache.putObject(key, list);
// 如果执行的语句是一个存储过程,那么向`localOutputParameterCache`存储一些东西
// 所以,看起来,`localOutputParameterCache`是用来缓存存储过程参数的
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
只需要知道,Executor在向数据库查询时会向本地的缓存中添加缓存即可。
SqlSession是线程不安全的,所以操作缓存时并没有任何保护,一个疑点是既然SqlSession是单线程的那么为啥要保存一个占位符,可能还有其它用处吧。
update中失效缓存#
在Executor的update方法中,也就是任何增删改最后会调用到的方法中,都先调用clearLocalCache清除了缓存。
@Override
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
clearLocalCache();
return doUpdate(ms, parameter);
}
commit和rollback时清除缓存#
BaseExecutor中,事务提交和回滚时都清空缓存。
@Override
public void commit(boolean required) throws SQLException {
if (closed) {
throw new ExecutorException("Cannot commit, transaction is already closed");
}
clearLocalCache();
flushStatements();
if (required) {
transaction.commit();
}
}
@Override
public void rollback(boolean required) throws SQLException {
if (!closed) {
try {
clearLocalCache();
flushStatements(true);
} finally {
if (required) {
transaction.rollback();
}
}
}
}
CacheKey如何计算#
在Mybatis的缓存中使用了CacheKey作为缓存的key
CacheKey实际上是个散列,每次update操作都在之前的基础上根据一个对象进行再散列得到一个新的散列值,而BaseExecutor中的createCacheKey是这样实现的:
@Override
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
if (closed) {
throw new ExecutorException("Executor was closed.");
}
CacheKey cacheKey = new CacheKey();
// MappedStatement.id
cacheKey.update(ms.getId());
// 分页的offset
cacheKey.update(rowBounds.getOffset());
// 分页的limit
cacheKey.update(rowBounds.getLimit());
// sql语句
cacheKey.update(boundSql.getSql());
// 下面是存储过程相关的
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();
// mimic DefaultParameterHandler logic
for (ParameterMapping parameterMapping : parameterMappings) {
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) {
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
cacheKey.update(value);
}
}
if (configuration.getEnvironment() != null) {
// issue #176
cacheKey.update(configuration.getEnvironment().getId());
}
return cacheKey;
}
所以,所有继承BaseExecutor的一级缓存都会考虑到:
- MappedStatement.getId,这个id就是Mapper中定义的查询的
namespace.id - 如果有分页,会考虑到分页的参数
- 然后考虑到SQL语句
- 如果有存储过程相关,还考虑存储过程的参数
所以即使具有相同的SQL语句,它们的StatementId不同也不会应用缓存
一级缓存的设计导致它无法探测到另一个Session的更新#
从上面的源码分析中,我们也能发现,每个Session在本地持有着自己的缓存,它们在更新时只能刷新自己内部的缓存,所以,一个SqlSession更新时,其它SqlSession是不知道的,还是持有着旧的缓存。下面的测试中会看到一个例子。
一级缓存的测试#
public class CacheTest {
static Logger logger = LogManager.getLogger(CacheTest.class);
SqlSession session;
InstructorMapper instructorMapper;
String TEST_INSTRUCTOR_ID = "10101";
@BeforeEach
void setup() throws IOException {
session = SqlSessions.defaultSqlSession();
instructorMapper = session.getMapper(InstructorMapper.class);
}
// 测试一级缓存可用性
@Test
void test1stLevelCache() throws IOException {
Instructor instructor;
// This query send sql statement to database server.
instructor = instructorMapper.findInstructorById(TEST_INSTRUCTOR_ID);
logger.info("Query instructor first time! instructor => " + instructor);
// Execute the same query once again! But mybatis doesn't request server this time!
instructor = instructorMapper.findInstructorById(TEST_INSTRUCTOR_ID);
logger.info("Second time! instructor => " + instructor);
}
// 测试清空缓存
@Test
void testClearCache() throws IOException {
Instructor instructor;
// This query send sql statement to database server.
instructor = instructorMapper.findInstructorById(TEST_INSTRUCTOR_ID);
logger.info("Query instructor first time! instructor => " + instructor);
// Try to clear the cache in local session!
session.clearCache();
logger.info("Session cache cleared!");
// Execute the same query once again! Mybatis will resent the statement again to the server because session cache was cleard!
instructor = instructorMapper.findInstructorById(TEST_INSTRUCTOR_ID);
logger.info("Second time! instructor => " + instructor);
}
// 测试在namespace+id不一样的情况下,缓存无效
@Test
void testCacheNotApplyWhenStatementIdIsNotSameButSqlIsTheSame() {
Instructor instructor;
// This query send sql statement to database server.
instructor = instructorMapper.findInstructorById(TEST_INSTRUCTOR_ID);
logger.info("Query instructor first time! instructor => " + instructor);
// Execute the same query once again! Mybatis will resent the statement again to the server because the mapper statement id is different.
instructor = instructorMapper.findInstructorById2(TEST_INSTRUCTOR_ID);
logger.info("Second time! instructor => " + instructor);
}
// 测试缓存在提交时失效
@Test
void testCacheInvalidateWhenCommit() throws IOException {
SqlSessionFactory factory = SqlSessionFactorys.getDefault();
SqlSession session = factory.openSession();
InstructorMapper instructorMapper = session.getMapper(InstructorMapper.class);
Instructor instructor;
// This query send sql statement to database server.
instructor = instructorMapper.findInstructorById(TEST_INSTRUCTOR_ID);
logger.info("Query instructor first time! instructor => " + instructor);
// 这里由于没有更新语句,所以使用`commit(true)`强制提交
session.commit(true);
// Execute the same query once again! Mybatis will resent the statement again to the server because the cache was invalidated during commit
instructor = instructorMapper.findInstructorById(TEST_INSTRUCTOR_ID);
logger.info("Second time! instructor => " + instructor);
}
// 测试在使用两个SqlSession时出现的脏读问题
@Test
void testDirtyReadWhenUseTwoSqlSession() throws IOException {
SqlSessionFactory factory = SqlSessionFactorys.getDefault();
SqlSession session1 = factory.openSession();
InstructorMapper instructorMapper1 = session1.getMapper(InstructorMapper.class);
SqlSession session2 = factory.openSession();
InstructorMapper instructorMapper2 = session2.getMapper(InstructorMapper.class);
// Load data to cache
Instructor instructorFrom1 = instructorMapper1.findInstructorById(TEST_INSTRUCTOR_ID);
Instructor instructorFrom2 = instructorMapper2.findInstructorById(TEST_INSTRUCTOR_ID);
// It's the same if nobody change the salary of this instructor between thoese two fetch above.
Assertions.assertEquals(instructorFrom1.getSalary(), instructorFrom2.getSalary());
logger.info("Salary from 1 " + instructorFrom1.getSalary() + ", Salary from 2 " + instructorFrom2.getSalary());
// Let session1 update the instructor
instructorFrom1.setSalary(0.0);
instructorMapper1.updateInstructor(instructorFrom1);
// Find instructor again
instructorFrom1 = instructorMapper1.findInstructorById(TEST_INSTRUCTOR_ID);
instructorFrom2 = instructorMapper2.findInstructorById(TEST_INSTRUCTOR_ID);
// It's the not same if nobody change the salary of this instructor between thoese two fetch above.
// Because the session2 use the old cache.
Assertions.assertNotEquals(instructorFrom1.getSalary(), instructorFrom2.getSalary());
logger.info("Salary from 1 " + instructorFrom1.getSalary() + ", Salary from 2 " + instructorFrom2.getSalary());
}
}
一级缓存总结#
- Executor内部使用两个
PerpetualCache对象来缓存,一个用于缓存查询结果,一个用于缓存存储过程参数。这种对象实际就是包装的Map。 - 在查询时首先会检测缓存中是否有需要的结果,如果有,就直接使用
- 如果没有,就执行数据库查询,并保存到缓存中
- 在update中会直接清除所有缓存
- 在事务提交,回滚时都会清除缓存
- 缓存匹配依赖mapper的namespace和id、sql语句、分页参数以及存储过程参数
- SqlSession的缓存只有内部可见,所以有可能其它SqlSession更新了数据,而另一个SqlSession还使用旧数据,所以,一级缓存应该跟事务一同使用
- 由于SqlSession被要求只在单线程内调用,所以Executor中的缓存也没有实现线程安全的特性
二级缓存#
官方宣称二级缓存是一个全局的缓存,它能在多个SqlSession间共享。
二级缓存的开启#
在Mybatis配置文件中添加如下设置:
<setting name="cacheEnabled" value="true"/>
在mapper中添加cache表示开启缓存功能:
<cache/>
MappedStatement介绍#
为了继续,我们必须在这里先把MappedStatement这个类搞明白,其实它之前已经出现过几次了。
Configuration类中持有着一个MappedStatement的Map,大概是这样:
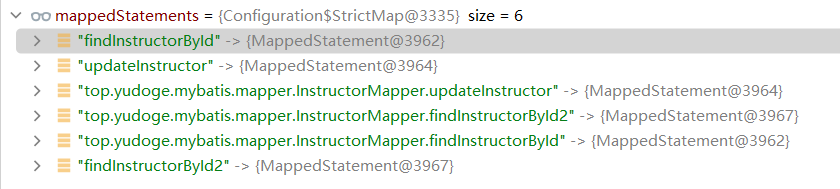
键就是你mapper中定义的所有SQL语句的namespace.id,值就是对应的MappedStatement,并且我们注意到不加namespace的纯SQL ID也在里面。
在DefaultSession的各种与数据库交互的方法中,都通过用户传入的statement名调用了Configuration.getMappedStatement来获取一个MappedStatement,再用它来调用Executor。
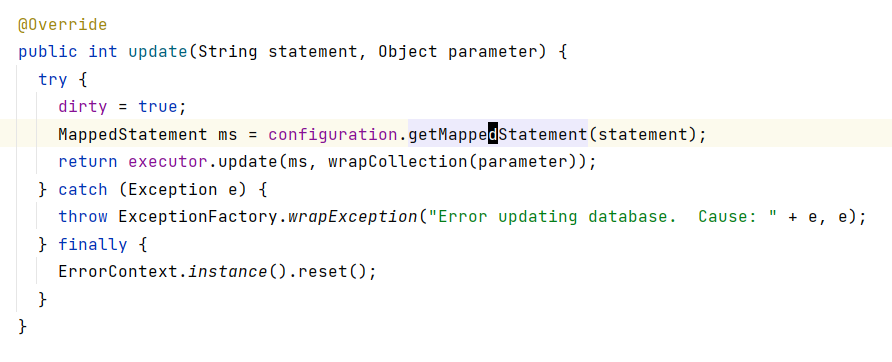
所以,MappedStatement就是你在mapper文件中定义的SQL语句的Java表示,它其中保存的属性就是我们经常在mapper文件中的SQL语句上使用的那些,比如resultMap、parameterMap、id、useCache、flushCache等:

Cache的层级关系#
Cache接口也是我们想要继续之前必须搞明白的接口,我们已经接触过一个它的实现类——基于Map的PerpetualCache。
Cache接口就是简单的缓存而已,putObject(key, value)用来添加一条缓存,getObject(key)用来获取一条缓存。
目前Cache接口有11个实现类,但只有几个是实际存储数据的,其它的都是用装饰器模式扩展一些功能:
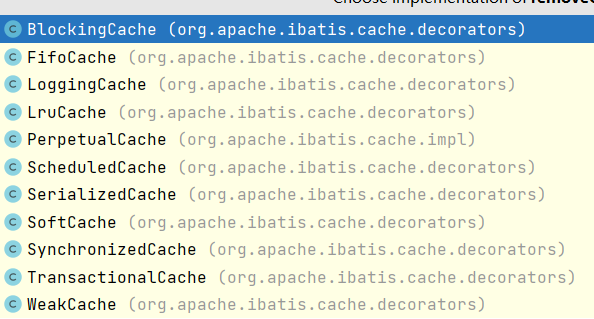
什么是装饰器扩展功能?看一个例子,这是FifoCache的putObject方法:
// 一个其它的Cache实现类,FifoCache委托它来实现保存缓存功能
private final Cache delegate;
// 保存缓存的key的队列,用于维护Fifo队列
private final Deque<Object> keyList;
@Override
public void putObject(Object key, Object value) {
// 将key添加到队列尾部
keyList.addLast(key);
// 如果缓存容量超限
if (keyList.size() > size) {
// 获取最旧的key并移除
Object oldestKey = keyList.removeFirst();
// 委托其它cache来移除这个缓存
delegate.removeObject(oldestKey);
}
// 委托其它Cache实现来保存Object
delegate.putObject(key, value);
}
FifoCache不保存缓存,而是利用其它缓存,你可以通过构造new FifoCache(realCache)来让realCache具有先入先出缓存的功能。这就是装饰器模式。
介绍其中几个Cache:
PerpetualCache:使用简单的Map来做缓存LoggingCache:装饰器缓存,记录了一个hits变量代表缓存命中率,并且在获取缓存时输出日志SerializedCache:装饰器缓存,它提供的功能是将对象序列化成字节数组后保存,并在获取对象时反序列化成对象,这样缓存间不共享同一个对象,就没有线程安全问题LruCache:装饰器缓存,实现了最近最少使用的缓存失效算法SychronizedCache:装饰器缓存,使用synchronized包裹方法,提供多线程间缓存访问的同步
开启二级缓存后MappedStatement的变化#
每一个MappedStatement中都持有一个Cache对象,在二级缓存没有开启之前(useCache=false或mapper的缓存关闭或配置文件里没开启二级缓存),这个对象是null:
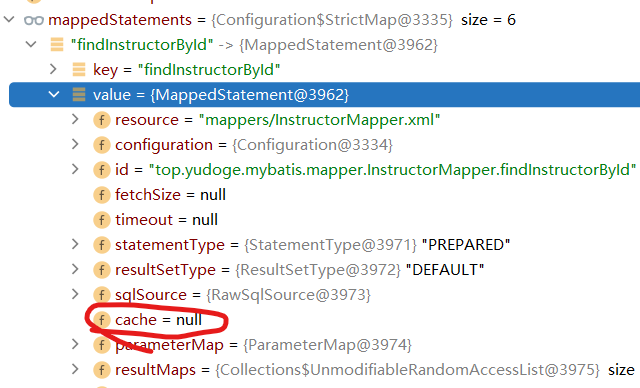
而当你的设置导致二级缓存对这个MappedStatement可用时(上面括号里的三个条件都满足),它的cache属性有值:
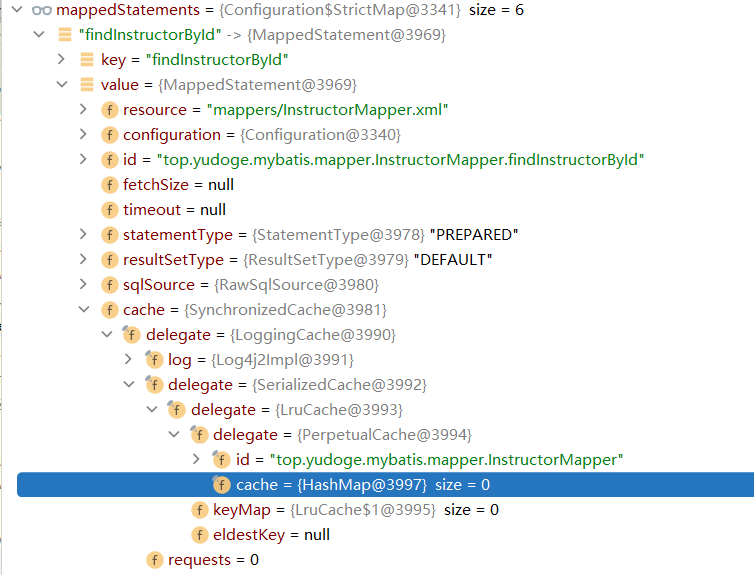
看看这个Cache被包裹了那么多层装饰器,它具有如下功能:
- 使用Lru算法在缓存容量超限时将最近最少使用的缓存丢掉
- 缓存后再拿出的对象不是原对象,而是序列化反序列化后的对象
- 每次拿取缓存时都会输出日志
- 缓存的访问在多线程间同步
而且,所有的MappedStatement中的缓存是相同的对象,所以,这个Cache是一个全局的缓存,被设置到了每一个MappedStatement中。
CachingExecutor#
DefaultSqlSessionFactory在创建SqlSession时会调用Configuration.newExecutor方法为SqlSession选择一个合适的Executor:
它会根据你传入的ExecutorType来选择一个合适的Executor,最后,如果二级缓存被打开了(Configuration对应MyBatis的配置文件,其中的cacheEnabled就是二级缓存开关),就使用一个CachingExecutor来包装实际的Executor类型,这里再一次用到了装饰器模式:

CachingExecutor为它包装的Executor添加了访问二级缓存的功能,看它的query方法:
private final Executor delegate;
private final TransactionalCacheManager tcm = new TransactionalCacheManager();
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
// 从MappedStatement中获取全局缓存
Cache cache = ms.getCache();
// 如果缓存不为空
if (cache != null) {
// 判断是否有必要刷新缓存(ms.isFlushCacheRequired() == true),也就是你mapper中的`flashCache`属性的设置
// 对于SELECT默认为false,其它语句默认为true
flushCacheIfRequired(ms);
// 如果使用缓存
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
// 先从缓存中获取
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
// 没获取到就执行实际的查询并放到缓存中
if (list == null) {
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
// 如果缓存为空,执行实际的查询
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
所以,现在二级缓存的原理好像也明白了,但还有一个问题,上面的代码中没有直接操作cache对象,而是使用tcm来操作,tcm是啥???
TransactionalCacheManager - tcm#
我真的是服了Mybatis,源码里一行注释也没有啊,你好歹解释一下每个组件的用途吧。
TCM的代码就很简单,它的作用说白了就是给每一个Cache创建一个TransactionalCache,并把对Cache的操作委托给TransactionalCache,一般情况下这个Cache一个项目中只有一个,就是那个全局的二级缓存:
public class TransactionalCacheManager {
// 维护一个Cache对象到TransactionalCache对象的映射
// 后面的所有操作,委托给Cache对应的TransactionalCache
private final Map<Cache, TransactionalCache> transactionalCaches = new HashMap<>();
// 清空,委托Cache对应的TransactionalCache
public void clear(Cache cache) {
getTransactionalCache(cache).clear();
}
// 获取缓存,委托Cache对应的TransactionalCache
public Object getObject(Cache cache, CacheKey key) {
return getTransactionalCache(cache).getObject(key);
}
// 放置缓存,委托Cache对应的TransactionalCache
public void putObject(Cache cache, CacheKey key, Object value) {
getTransactionalCache(cache).putObject(key, value);
}
// 提交,调用所有缓存对应的TransactionalCache的提交
public void commit() {
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.commit();
}
}
// 回滚,调用所有缓存对应的TransactionalCache的回滚
public void rollback() {
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.rollback();
}
}
// 从映射表中获取一个Cache对应的TransactionalCache,没有则新建
private TransactionalCache getTransactionalCache(Cache cache) {
return MapUtil.computeIfAbsent(transactionalCaches, cache, TransactionalCache::new);
}
}
所以,这个类存在的原因貌似就是给本不支持事务的Cache扩展成事务相关的Cache,在提交和回滚时会操作缓存。
TransactionalCache#
先看下该类的属性:
// 该类也是一个Cache,只不过扩展了事务提交和回滚相关的操作
public class TransactionalCache implements Cache {
// 委托的实际Cache
private final Cache delegate;
// 提交时是否清空缓存,默认为false
private boolean clearOnCommit;
// 记录在提交时需要被添加的缓存KeyValue集合
private final Map<Object, Object> entriesToAddOnCommit;
// 缓存未命中的Key集合
private final Set<Object> entriesMissedInCache;
}
已经前进了这么多,回顾一下,所有这些Cache都是在SqlSession中持有的Executor里被维护的,不管是一级缓存还是二级缓存,二级缓存只不过在一级缓存之上利用MappedStatement中的全局共享缓存对象来构建。
用户可以调用SqlSession来提交或回滚数据,SqlSession会委托Exectuor来完成提交或回滚操作,而在CachingExecutor中,提交和回滚操作会被TransactionalCacheManager接管,而对于每一个二级缓存对象,TransactionCacheManager会将它映射成一个TransactionalCache对象,并调用它的提交和回滚动作,整个流程是这样的:
DefaultSqlSession -> CachingExecutor -> TransactionalCacheManager -> TransactionalCache
另外,二级缓存对象是被全局所有用到那个对象的MappedStatement所共享的,但二级缓存所转换到的TransactionalCache却是每个Session独立的,这一点非常重要
另外,二级缓存对象是被全局所有用到那个对象的MappedStatement所共享的,但二级缓存所转换到的TransactionalCache却是每个Session独立的,这一点非常重要
另外,二级缓存对象是被全局所有用到那个对象的MappedStatement所共享的,但二级缓存所转换到的TransactionalCache却是每个Session独立的,这一点非常重要
尝试理解entriesToAddCommit&entriesMissedInCache#
现在,我们以事务的角度来思考,尝试理解entriesToAddOnCommit和entriesMissedInCache
一个事务的执行过程中,可能会进行多次查询,同时还可能有其它的事务正在执行查询,过程中还可能有其它的事务提交,所以一个事务查询出来的东西在未提交前是不希望保存到全局的缓存中的,所以entriesToAddCommit用来缓存事务在未提交前所查询到的实体,可以认为是缓存的缓存。
entriesMissedInCache很好理解,就是在本次事务的查询中没有走二级缓存,实际进行了数据库查询的key。也就是未命中的缓存。
TransactionalCache具体的缓存策略#
获取缓存:
@Override
public Object getObject(Object key) {
// 向实际的二级缓存中查询
Object object = delegate.getObject(key);
// 如果没有,在未命中key中记录
if (object == null) {
entriesMissedInCache.add(key);
}
// 如果设置了`clearOnCommit`,代表本次事务中已经调用过了`clear`清空缓存
if (clearOnCommit) {
return null;
} else {
return object;
}
}
getObject从不尝试在entriesToAddOnCommit中获取,也就是说它不把本次事务中产生的缓存当作缓存的依据,这不代表本次事务中的所有一样的查询无法利用缓存,因为还有一级缓存在,这正是一级缓存解决的场景。
注意,在getObject返回null时,Executor会向数据库发起查询,并通过putObject将缓存设置进来,所以getObject返回null会导致putObject被调用。所以entriesMissedInCache和entriesToAddOnCommit中的key往往是一样的。
添加缓存:
@Override
public void putObject(Object key, Object object) {
// 添加缓存时先不添加到二级缓存中,先在本地的缓存中
entriesToAddOnCommit.put(key, object);
}
清空缓存:
@Override
public void clear() {
// clear会在产生Insert/Update/Delete时被调用
// 这里并不直接清空,而是将清空延后到提交时
// 因为这个事务完全可能最终不提交,也就是它的增删改可能不实际执行
clearOnCommit = true;
// 将本地的缓存清空,但并未清空`entriesMissedInCache`,这里可能导致Map和Set中的内容不一致,导致Set中有的Key, Map中没有,Set比Map中多的那部分就是被清空的部分,稍后会在提交的代码中看到
entriesToAddOnCommit.clear();
}
提交:
public void commit() {
// 如果需要清空,调用二级缓存进行清空
if (clearOnCommit) {
delegate.clear();
}
// 刷新待处理的实体(也就是本次事务中产生的那些还没添加到二级缓存中的缓存项)
flushPendingEntries();
// 重置
// 1. 设置clearOnCommit = false
// 2. 将用于支持事务的Map和Set清空,即entriesToAddOnCommit和entriesMissedInCache
reset();
}
flushPendingEntries:
private void flushPendingEntries() {
// 将本次事务中产生的所有缓存添加到二级缓存
for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) {
delegate.putObject(entry.getKey(), entry.getValue());
}
// 对于所有在本次事务中被清空的那些缓存key(这个清空可能是由于事务中发生了增删或改),在实际的二级代理中也清空
for (Object entry : entriesMissedInCache) {
if (!entriesToAddOnCommit.containsKey(entry)) {
delegate.putObject(entry, null);
}
}
}
回滚操作:
public void rollback() {
// 移除未命中实体
unlockMissedEntries();
// 重置
reset();
}
private void unlockMissedEntries() {
for (Object entry : entriesMissedInCache) {
try {
delegate.removeObject(entry);
} catch (Exception e) {
log.warn("Unexpected exception while notifying a rollback to the cache adapter. "
+ "Consider upgrading your cache adapter to the latest version. Cause: " + e);
}
}
}
rollback操作中,对于所有本次事务中的未命中实体,在缓存中移除。这一步不知道是为啥,按理来说这些实体应该还没被实际加入到二级代理中啊,但是其它事务有可能加入,这个操作会把其它事务在这期间加入的在本次事务未命中key中的缓存给移除。
总结#
- 二级缓存是全局的
- 一个事务只有在提交时才会把它产生的全部缓存加入到二级缓存中
- 一个事务可能由于insert/update/delete操作清空缓存,这个清空会被延后到该事务提交后才对其它事务可见
- 第二点和第三点可以被总结为一个事务做的全部缓存操作只有在它提交后才会被应用
- 一个事务回滚时不会产生二级缓存
- 事务过程中的缓存是由一级缓存提供的,而非二级缓存
还有个小笑话,我刚刚在写二级缓存的测试时发现了一个问题,就是我的二级缓存应用不上,后来我发现,我的两个MappedStatement持有的
cache对象不是同一个对象。排查了半天,我发现它们不是用一个SqlSessionFactory创建的,我自作聪明写的工具方法害我找了半天的Bug。
作者:Yudoge
出处:https://www.cnblogs.com/lilpig/p/16520289.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
欢迎按协议规定转载,方便的话,发个站内信给我嗷~




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· winform 绘制太阳,地球,月球 运作规律
· 上周热点回顾(3.3-3.9)