ApplicationContext源码浅析
接口分析

EnvironmentCapable
spring-core模块中的接口:
public interface EnvironmentCapable {
/**
* 返回与该组件关联的Environment
*/
Environment getEnvironment();
}
一个组件若实现了该接口,意味着它包含一个Environment的引用并向外界暴露。
所有的Spring ApplicationContext都是EnvironmentCapable,也就是说ApplicationContext有获取与当前应用程序所运行的环境相关的信息(比如一些环境变量)的能力。
BeanFactory
spring-beans模块中的接口
继承了两个BeanFactory,意味着ApplicationContext具有作为Bean的容器的能力。
HierarchicalBeanFactory,这代表每一个ApplicationContext都是一个层次化的BeanFactory,具有父子层级关系ListableBeanFactory,这代表每一个ApplicationContext都是一个可枚举的BeanFactory,可以对其中所有的Bean进行枚举
MessageSource
spring-context模块中的接口
public interface MessageSource {
@Nullable
String getMessage(String code, @Nullable Object[] args, @Nullable String defaultMessage, Locale locale);
String getMessage(String code, @Nullable Object[] args, Locale locale) throws NoSuchMessageException;
String getMessage(MessageSourceResolvable resolvable, Locale locale) throws NoSuchMessageException;
}
注意到,它的每个getMessage的参数中都有一个Locale对象,还有一个code,看起来是使用消息码并且根据一个区域信息来解析出指定区域下的消息内容,也就是用于支持国际化的。
ResourcePatternResolver
位于spring-core模块
用于将一个模式(比如Ant风格路径模式)解析成一个Resource对象。
public interface ResourcePatternResolver extends ResourceLoader {
String CLASSPATH_ALL_URL_PREFIX = "classpath*:";
Resource[] getResources(String locationPattern) throws IOException;
}
ApplicationEventPublisher
位于spring-context模块
它是一个封装了事件发布功能的接口,实现了该接口的类具有事件发布功能。
@FunctionalInterface
public interface ApplicationEventPublisher {
default void publishEvent(ApplicationEvent event) {
publishEvent((Object) event);
}
void publishEvent(Object event);
}
该接口并没有定义如何注册事件的订阅者。
ApplicationContext中的方法
看了它继承的接口,在看看ApplicationContext中定义了什么方法:
// 返回ApplicationContext的唯一ID
@Nullable
String getId();
// 返回该context所属的应用程序的名字
String getApplicationName();
// 返回一个该context的更加友好的名字
String getDisplayName();
// 返回context刚加载时的时间戳
long getStartupDate();
// 返回父context,或者null(当没有父context时)
@Nullable
ApplicationContext getParent();
// 暴露该context的AutowireCapableBeanFactory功能
// 抛出IllegalStateException —— 如果context不支持AutowireCapableBeanFactory接口或尚未持有一个autowire-capable bean工厂(比如`refresh`方法从没被调用过),或者context已经被关闭
AutowireCapableBeanFactory getAutowireCapableBeanFactory() throws IllegalStateException;
总结
所以,ApplicationContext具有如下功能:
- 发现、定义、维护、管理Bean
- 可以向外界暴露当前程序所运行的环境信息
- 国际化
- 事件发布/订阅
- 解析资源
- context是层次化的
- 一些context可能通过持有
AutowireCapableBeanFactory来支持自动装载能力
ConfigurableApplicationContext
提供了配置ApplicationContext的功能。
配置和生命周期方法被封装在这里,以避免它们对使用ApplicationContext的客户代码可见。这些方法只应该被开启和关闭(ApplicationContext)的代码使用。
属性
ConfigurableApplicationContext接口中还定义了如下变量来指定一些与实现类约定的用名(Bean名、某些线程名、通用的分隔符):
// 任意数量的下面的字符都会被认为是多个context配置路径之间的分隔符
String CONFIG_LOCATION_DELIMITERS = ",; \t\n";
// ConversionService Bean在工厂中的名字
String CONVERSION_SERVICE_BEAN_NAME = "conversionService";
// LoadTimeWeaver Bean在工厂中的名字
String LOAD_TIME_WEAVER_BEAN_NAME = "loadTimeWeaver";
// Environment Bean在工厂中的名字
String ENVIRONMENT_BEAN_NAME = "environment";
// 系统属性Bean在工厂中的名字
String SYSTEM_PROPERTIES_BEAN_NAME = "systemProperties";
// 系统环境变量在Bean中的名字
String SYSTEM_ENVIRONMENT_BEAN_NAME = "systemEnvironment";
// ApplicationStartup Bean在工厂中的名字
String APPLICATION_STARTUP_BEAN_NAME = "applicationStartup";
// shutdown hook线程的名字
String SHUTDOWN_HOOK_THREAD_NAME = "SpringContextShutdownHook";
也就是说,实现类可能会在初始化时就向工厂中预注册一些Bean,这里是约定的Bean名。
方法
ConfigurableApplicationContext提供了一些方法,你可以在这里看到,在ApplicationContext中的getXXX方法,在这里都有了对应的setter。
| 方法 | 功能 |
|---|---|
| setId | 设置context唯一id |
| setParent | 设置父context |
| setEnvironment | 设置context的Environment |
| getEnvironment | 该接口覆盖了这个方法,返回一个ConfigurableEnvironment |
| setApplicationStartup | 设置context的ApplicationStartup |
| addBeanFactoryPostProcessor | 向其中添加BeanFactoryPostProcessor |
| addApplicationListener | 前面说了,ApplicationContext是一个可发布事件的组件,这个方法定义了如何注册事件的监听器 |
| setClassLoader | 设置用于加载bean类和classpath资源的ClassLoader |
| refresh | 加载或刷新配置的持久层表示,可能是Java Config类、XML文件、properties文件或关系型数据库模式。在该方法调用完毕时,要么所有singleton都被初始化完毕,要么一个都没有初始化(失败时销毁所有已经创建的singleton) |
| registerShutdownHook | 注册一个JVM运行时的关闭钩子,用于在JVM关闭时关闭context |
| close | 关闭context,释放所有资源和实现持有的锁,销毁所有缓存的singleton |
| isActive | 当前context是否是active的,即它至少被refresh一次且尚未被关闭 |
| getBeanFactory | 返回application context内部的BeanFactory。它返回的是一个ConfigurableListableBeanFactory |
AbstractApplicationContext
我们已经分析了足够的接口,下面让我们来分析一个抽象实现——AbstractApplicationContext。
public abstract class AbstractApplicationContext
extends DefaultResourceLoader
implements ConfigurableApplicationContext
它继承自DefaultResourceLoader,看起来是ResourceLoader的一个实现类,也就是说这个类一下载具有了资源加载的功能,然后估计就是用父类DefaultResourceLoader的功能来实现ResourcePatternResolver接口的功能。同时,它实现了ConfigurableApplicationContext,这说明它是一个可配置的ApplicationContext。
AbstractApplicationContext并不限制配置信息的存储类型,只实现了context的通用功能,所以,它使用了模板设计模式,让具体子类来确定抽象部分。
那些简单的set/get方法就不解释了,其原理都是在类中维护一个变量,我们主要看一些核心的内容。
refresh
接口中refresh方法的定义:
加载或刷新配置的持久层表示,可能是Java Config类、XML文件、properties文件或关系型数据库模式。在该方法调用完毕时,要么所有singleton都被初始化完毕,要么一个都没有初始化(失败时销毁所有已经创建的singleton)
refresh的代码非常过程式,就是由一系列过程调用组成的:
public void refresh() throws BeansException, IllegalStateException {
// 先锁住开启关闭监视器,这意味着refresh的进入与开启关闭context的过程是互斥的
synchronized (this.startupShutdownMonitor) {
// 为refreshing操作而准备context
prepareRefresh();
// 告诉子类刷新内部BeanFactory(obtainFrashBeanFactory由子类实现)
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// 准备这个context内用到的bean factory
prepareBeanFactory(beanFactory);
try {
// 允许对子类中的bean工厂进行post-processing
postProcessBeanFactory(beanFactory);
// 调用在context中被注册成Bean的factory processor
invokeBeanFactoryPostProcessors(beanFactory);
// 注册用于拦截Bean创建的BeanPostProcessor
registerBeanPostProcessors(beanFactory);
// 初始化context的messageSource
initMessageSource();
// 为context初始化事件多播器
initApplicationEventMulticaster();
// 初始化特定子类上下文中的其它特殊bean(这里也是模板模式)
onRefresh();
// 检查listener bean并注册它们
registerListeners();
// 实例化所有剩余的(非懒初始化)singleton
finishBeanFactoryInitialization(beanFactory);
// 最后一步:发布对应的事件
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
// 如果失败就销毁所有Bean
destroyBeans();
// 重新设置active标志
cancelRefresh(ex);
// 传递异常给调用者
throw ex;
}
finally {
resetCommonCaches();
contextRefresh.end();
}
}
}
这些过程中,有Bean相关的、BeanPostProcessor相关的、BeanFactoryPostProcessor相关的、事件发布相关的、messageSource相关的。总之就是一系列过程调用嘛,下面我们将按顺序到这些过程调用里去看看。对于很多过程调用,我们可能看了之后也不知道它是干啥的,但是看看起码对它有个基本的概念。
prepareRefresh
为了refresh操作,准备该context。设置它的启动时间、active标记以及任何PropertySource的初始化
protected void prepareRefresh() {
this.startupDate = System.currentTimeMillis();
this.closed.set(false);
this.active.set(true);
// 初始化context environment中的任何property source占位符
initPropertySources();
// 验证是否所有被标记为`required`的属性都是可以被解析的
getEnvironment().validateRequiredProperties();
if (this.earlyApplicationListeners == null) {
this.earlyApplicationListeners = new LinkedHashSet<>(this.applicationListeners);
}
else {
this.applicationListeners.clear();
this.applicationListeners.addAll(this.earlyApplicationListeners);
}
this.earlyApplicationEvents = new LinkedHashSet<>();
}
initPropertySources默认情况下什么都不做,需要子类来实现。
obtainFreshBeanFactory
告诉子类刷新内部的beanFactory,返回刷新后的BeanFactory
protected ConfigurableListableBeanFactory obtainFreshBeanFactory() {
refreshBeanFactory();
return getBeanFactory();
}
上面的两个方法都是由子类实现的。
prepareBeanFactory
这个方法有点重要,它用于对beanFactory进行一些上下文的个性化设置,来实现上下文的功能。它参数中的
beanFactory就是子类刚刚刷新好的beanFactory。
protected void prepareBeanFactory(ConfigurableListableBeanFactory beanFactory) {
// 告诉beanFactory使用什么classLoader
beanFactory.setBeanClassLoader(getClassLoader());
// 如果不应该忽略spel,那么设置beanFactory的表达式解析器
if (!shouldIgnoreSpel) {
beanFactory.setBeanExpressionResolver(new StandardBeanExpressionResolver(beanFactory.getBeanClassLoader()));
}
// 不知道干啥的
beanFactory.addPropertyEditorRegistrar(new ResourceEditorRegistrar(this, getEnvironment()));
// 使用上下文回调配置bean factory
// BeanFactory的Bean初始化过程中有对Aware接口Bean的调用
// ApplicationContext中由于引入了很多新功能,比如Environment
// 所以Bean可能会想要Aware更多接口,ApplicationContext通过添加一个BeanPostProcessor来实现它所扩展的Aware接口的检测及调用
beanFactory.addBeanPostProcessor(new ApplicationContextAwareProcessor(this));
// 指定在自动装载(autowire)时忽略的接口
beanFactory.ignoreDependencyInterface(EnvironmentAware.class);
beanFactory.ignoreDependencyInterface(EmbeddedValueResolverAware.class);
beanFactory.ignoreDependencyInterface(ResourceLoaderAware.class);
beanFactory.ignoreDependencyInterface(ApplicationEventPublisherAware.class);
beanFactory.ignoreDependencyInterface(MessageSourceAware.class);
beanFactory.ignoreDependencyInterface(ApplicationContextAware.class);
beanFactory.ignoreDependencyInterface(ApplicationStartupAware.class);
// 注册一些特殊的用于自动装载的类型的值
// 也就是说如果容器中有需要自动装载BeanFactory的,就将持有的BeanFactory传进去
beanFactory.registerResolvableDependency(BeanFactory.class, beanFactory);
beanFactory.registerResolvableDependency(ResourceLoader.class, this);
beanFactory.registerResolvableDependency(ApplicationEventPublisher.class, this);
beanFactory.registerResolvableDependency(ApplicationContext.class, this);
// 不知道干啥的
beanFactory.addBeanPostProcessor(new ApplicationListenerDetector(this));
// Detect a LoadTimeWeaver and prepare for weaving, if found.
// 检测一个`LoadTimeWeaver`,并且如果检测到的话,准备织入
if (!NativeDetector.inNativeImage() && beanFactory.containsBean(LOAD_TIME_WEAVER_BEAN_NAME)) {
beanFactory.addBeanPostProcessor(new LoadTimeWeaverAwareProcessor(beanFactory));
// Set a temporary ClassLoader for type matching.
beanFactory.setTempClassLoader(new ContextTypeMatchClassLoader(beanFactory.getBeanClassLoader()));
}
// 注册默认的Environment Bean
if (!beanFactory.containsLocalBean(ENVIRONMENT_BEAN_NAME)) {
beanFactory.registerSingleton(ENVIRONMENT_BEAN_NAME, getEnvironment());
}
if (!beanFactory.containsLocalBean(SYSTEM_PROPERTIES_BEAN_NAME)) {
beanFactory.registerSingleton(SYSTEM_PROPERTIES_BEAN_NAME, getEnvironment().getSystemProperties());
}
if (!beanFactory.containsLocalBean(SYSTEM_ENVIRONMENT_BEAN_NAME)) {
beanFactory.registerSingleton(SYSTEM_ENVIRONMENT_BEAN_NAME, getEnvironment().getSystemEnvironment());
}
if (!beanFactory.containsLocalBean(APPLICATION_STARTUP_BEAN_NAME)) {
beanFactory.registerSingleton(APPLICATION_STARTUP_BEAN_NAME, getApplicationStartup());
}
}
所以,prepareBeanFactory方法是context为了实现功能,对内部的BeanFactory进行的一些设置,包括加载一些用于实现特定功能的BeanPostProcessor,注册一些Bean到BeanFactory。
postProcessBeanFactory
在基本初始化后修改ApplicationContext内部的BeanFactory,所有BeanDefinition都将被加载,但还没有bean被实例化。这个方法允许在特定的ApplicationContext实现中注册特定的BeanPostProcessor。
protected void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) {
}
invokeBeanFactoryPostProcessors
略,其功能就是调用所有注册在context中的BeanFactoryPostProcessor
registerBeanPostProcessors
略,其功能就是将所有注册在BeanFactory中作为Bean的BeanPostProcessor实际添加成BeanFactory的BeanPostProcessor。
所以,在ApplicationContext中,如果你想注册一个BeanPostProcessor,你可以选择将它注册成一个Bean。
请注意
BeanFactoryPostProcessor和BeanPostProcessor的区别
对于那些事件相关的方法,这里暂时不进入查看
finishBeanFactoryInitialization
完成这个context的bean factory的初始化,初始化所有剩余的singleton bean。
该方法先是将ConversionService、LoadTimeWeaverAware这些Bean通过实际调用getBean给初始化了,然后调用beanfactory.freezeConfiguration冻结Bean工厂中的BeanDefinition,不允许进一步更改,最后,调用preInstantiateSingletons来预实例化singleton:
protected void finishBeanFactoryInitialization(ConfigurableListableBeanFactory beanFactory) {
if (beanFactory.containsBean(CONVERSION_SERVICE_BEAN_NAME) &&
beanFactory.isTypeMatch(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class)) {
beanFactory.setConversionService(
beanFactory.getBean(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class));
}
if (!beanFactory.hasEmbeddedValueResolver()) {
beanFactory.addEmbeddedValueResolver(strVal -> getEnvironment().resolvePlaceholders(strVal));
}
String[] weaverAwareNames = beanFactory.getBeanNamesForType(LoadTimeWeaverAware.class, false, false);
for (String weaverAwareName : weaverAwareNames) {
getBean(weaverAwareName);
}
beanFactory.setTempClassLoader(null);
beanFactory.freezeConfiguration();
beanFactory.preInstantiateSingletons();
}
refresh方法总结
refresh方法,其作用就是加载或刷新配置。它的工作是设置context的状态,对子类返回的beanfactory进行一些context自定义的填充,包括添加post-processor进行功能扩展,添加context自定义的一些Bean等。最后,它冻结了BeanFactory的配置,预实例化的所有的singleton(并不需要getBean时再实例化了)。
这是我第一次尝试自底向上读源码(从底层接口到抽象类到具体实现类)。我觉得,阅读源码时,自底向上的阅读方式确实能让我在一开始对于整个源码中组件的架构、职责了解的更多,但是,太难了!!!!!!!!所以,对于
AbstractApplicationContext,我们先了解到这,进入到具体的,业务中实际使用的ApplicationContext,转换为自顶向下的阅读模式。
ClassPathXmlApplicationContext
Spring的用户对它一定不陌生,它通过读取类路径下的xml配置文件来构建ApplicationContext。
下面编写一个基础用例:
public class ClassPathXmlApplicationContextTest {
public static void main(String[] args) {
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("spring-config.xml");
Workbench workbench = applicationContext.getBean(Workbench.class);
System.out.println(workbench);
}
}
在resources下建立spring-config.xml:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="person" class="top.yudoge.springserials.basic.beans.Person">
<property name="name" value="Yudoge"/>
</bean>
<bean id="workbench" class="top.yudoge.springserials.basic.beans.Workbench">
<property name="operator" ref="person"/>
</bean>
</beans>
很简单的代码,我们向context中注册了两个bean,person具有一个属性name,值是Yudoge,workbench具有属性operator,值是前面定义的person引用。所以,运行程序,结果是这样的:

下面通过源码分析整个过程:
ClassPathXmlApplicationContext的创建
如下是我们调用的构造器,传入了一个配置文件路径,它调用了另一个构造方法:
public ClassPathXmlApplicationContext(String configLocation) throws BeansException {
this(new String[] {configLocation}, true, null);
}
另一个构造方法上来就调了个super,这个super最终调用到了AbstractApplicationContext,只设置了一下父context而已,所以我们不深入了:
public ClassPathXmlApplicationContext(
String[] configLocations, boolean refresh, @Nullable ApplicationContext parent)
throws BeansException {
super(parent);
setConfigLocations(configLocations);
if (refresh) {
refresh();
}
}
再然后,关键的地方就是调用了一下refresh。通过上面的分析,我们已经知道了refresh在AbstractApplicationContext中提供,refresh也会调用子类的相关方法以模板模式来完成整个刷新功能,刷新的最终结果就是beanfactory中被塞了一些context需要的bean和postprocessor,并且beandefinition被冻结,所有singleton被预实例化。这里主要关注refresh中的模板方法调用与各个子类之间完成刷新动作的协作。
refresh会通过obtainFreshBeanFactory调用子类的refreshBeanFactory和getBeanFactory:
@Override
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
prepareRefresh();
// obtainFreshBeanFactory会调用子类的refreshBeanFactory和getBeanFactory
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// ...
}
refreshBeanFactory
那么refreshBeanFactory到底调用到了哪个类上呢?首先肯定不是ClassPathXmlApplicationContext类,因为对于各种ApplicationContext,刷新BeanFactory是基本操作,不可能每一个边缘实现类中都定义一份,这些边缘实现类应该实现的方法只有它们之间不同的部分,比如ClassPathXml需要实现从classpath中加载xml文件,FileSystemXml需要实现从文件系统中加载xml文件,这是它们不同的地方。
通过打断点,最终,该方法调用到了AbstractRefreshableApplicationContext上。
@Override
protected final void refreshBeanFactory() throws BeansException {
// 如果已经有了BeanFactory
if (hasBeanFactory()) {
// 销毁并关闭BeanFactory
destroyBeans();
closeBeanFactory();
}
try {
// 新建一个DefaultListableBeanFactory
DefaultListableBeanFactory beanFactory = createBeanFactory();
beanFactory.setSerializationId(getId());
// 对beanfactory进行自定义
customizeBeanFactory(beanFactory);
// 加载bean定义
loadBeanDefinitions(beanFactory);
this.beanFactory = beanFactory;
}
catch (IOException ex) {
throw new ApplicationContextException("I/O error parsing bean definition source for " + getDisplayName(), ex);
}
}
我们先忽略掉对于已经有BeanFactory时销毁重建的情况,直接考虑try-catch里面的内容,先看看createBeanFactory方法:
protected DefaultListableBeanFactory createBeanFactory() {
return new DefaultListableBeanFactory(getInternalParentBeanFactory());
}
方法很简单,就是创建一个DefaultListableBeanFactory,由于DefaultListableBeanFactory是有层次结构的,所以,getInternalParentBeanFactory用于获取父context的BeanFactory(或者直接是父ApplicationContext),并设置给DefaultListableBeanFactory作为父Bean工厂。
然后是customizeBeanFactory
protected void customizeBeanFactory(DefaultListableBeanFactory beanFactory) {
if (this.allowBeanDefinitionOverriding != null) {
beanFactory.setAllowBeanDefinitionOverriding(this.allowBeanDefinitionOverriding);
}
if (this.allowCircularReferences != null) {
beanFactory.setAllowCircularReferences(this.allowCircularReferences);
}
}
只是将内置的两个属性设置给BeanFactory,实际上,ApplicationContext由于采用了组合而非继承的方式,实际上它们都是持有BeanFactory实例的,并且ApplicationContext中都有大量的把自身的设置传递给它持有的BeanFactory以及将调用转发到BeanFactory上的代码。
loadBeanDefinition
下面就是loadBeanDefinition,它比较核心,它是ApplicationContext用于加载BeanDefinition到内部BeanFactory的方法,由于AbstractRefreshableApplicationContext并没定义配置文件的存储方式,所以它不知道从哪加载Bean定义,该方法一定不是它的职责。同时它也不应该是ClassPathXmlApplicationContext的职责,因为一定有某个抽象类为所有基于Xml配置的ApplicationContext提供公共的加载BeanDefinition的方式。
果然,通过断点,我们找到了该方法实际走到了AbstractXmlApplicationContext类,它是所有基于Xml配置的ApplicationContext的公共抽象父类,读取Xml,定义Bean啥的都是它来做,子类只需要做从哪里加载Xml这一决策(可能还有别的决策要做)。
下面是loadBeanDefinitions的代码:
@Override
protected void loadBeanDefinitions(DefaultListableBeanFactory beanFactory) throws BeansException, IOException {
// 为给定beanFactory创建一个XmlBeanDefinitionReader
XmlBeanDefinitionReader beanDefinitionReader = new XmlBeanDefinitionReader(beanFactory);
// 使用当前context配置BeanDefinition Reader
beanDefinitionReader.setEnvironment(this.getEnvironment());
beanDefinitionReader.setResourceLoader(this);
beanDefinitionReader.setEntityResolver(new ResourceEntityResolver(this));
// 允许子类提供reader的自定义初始化(子类可以通过重写`initBeanDefinitionReader`对reader进行任意自定义的配置)
initBeanDefinitionReader(beanDefinitionReader);
// 然后执行实际的加载BeanDefinition操作
loadBeanDefinitions(beanDefinitionReader);
}
下面看看上面代码最终调用的重载的loadBeanDefinitions:
protected void loadBeanDefinitions(XmlBeanDefinitionReader reader) throws BeansException, IOException {
Resource[] configResources = getConfigResources();
if (configResources != null) {
reader.loadBeanDefinitions(configResources);
}
String[] configLocations = getConfigLocations();
if (configLocations != null) {
reader.loadBeanDefinitions(configLocations);
}
}
它通过getConfigResources或getConfigLocations获取Xml文件资源或者位置,然后通过reader来执行实际的BeanDefinition加载操作。
这两个方法就应该是由子类实现的,因为具体去哪来寻找Xml文件是子类来定义的。
在ClassPathXmlApplicationContext的构造方法中,我们传入了configLocation,构造方法调用了setConfigLocations方法去设置configLocation,这个方法是在AbstractRefreshableConfigApplicationContext中定义的,这个类是专门为基于Xml配置的ApplicationContext定义的一个公共父类,为的是不让每一个实现类自己维护configLocations和configResources。
setConfigLocations(configLocations);
总之,就这样,配置文件的路径被拿到了。关于XmlBeanDefinitionReader,没什么深入进去的意义,因为它只是读取Xml文档,将里面的文档结构转换为BeanDefinition。
现在obtainFreshBeanFactory步骤就已经可以被认为是完成了,完成后,返回的beanFactory中已经有了workbench和person两个BeanDefinition。
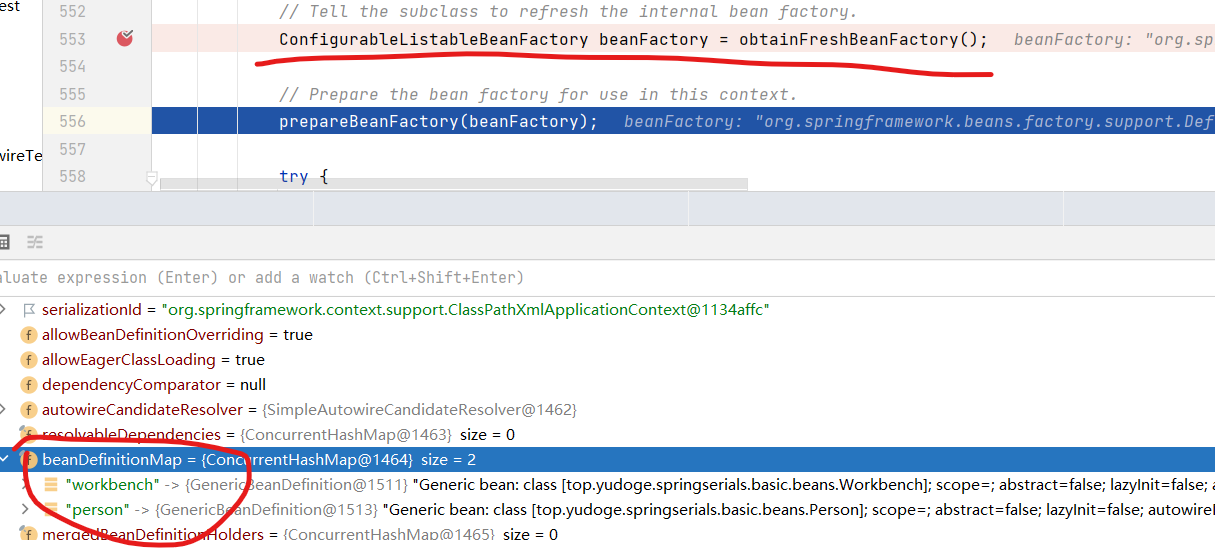
ClassPathXmlApplicationContext如何处理Xml中的其它命名空间
默认情况下,ClassPathXmlApplicationContext没有自动扫描组件、自动装配属性的功能,但我们可以在xml中通过context命名空间的component-scan来进行组件的自动扫描,并且这样就可以通过@Autowire注解进行自动装配。
那它是怎么实现的呢?
在上上篇文章中,我们知道了如果你只使用BeanFactory,那么
@Autowired注解并起不了什么作用。即使你使用AutowireCapableBeanFactory,@Autowired注解也不会称为属性注入的依据,事实是任何未满足的非简单属性都会被自动装载,即使它没有@Autowired注解。所以,我所好奇的就是,ApplicationContext如何将@Autowired注解作为自动装载的依据,并且让其未标注@Autowired的未满足非简单属性不被装载的呢?
示例
下面修改我们之前的代码,使用context:component-scan
修改xml:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd">
<!-- 使用`context:component-scan -->
<context:component-scan base-package="top.yudoge.springserials.basic.beans"/>
</beans>
修改Bean:
@Data
@NoArgsConstructor
@AllArgsConstructor
// 添加@Component注解让它能被自动扫描注意到
@Component
public class Person {
// 添加@Value注解给这个属性设置默认值
@Value("Yudoge")
private String name;
}
@Data
// 添加@Component注解让它能被自动扫描注意到
@Component
public class Workbench {
// 添加@Autowired注解让它被自动装载
@Autowired
private Person operator;
// 提供一个没有@Autowired注解的Person类属性,从定义上,它应该符合未满足非简单属性的定义,但它不会被自动装载
private Person noAutowiredAnnotation;
}
结果

回到XmlBeanDefinitionReader
自动扫描和自动装配的功能都是context命名空间提供的,在XmlBeanDefinitionReader中,我们注意到这样的代码:
public NamespaceHandlerResolver getNamespaceHandlerResolver() {
if (this.namespaceHandlerResolver == null) {
this.namespaceHandlerResolver = createDefaultNamespaceHandlerResolver();
}
return this.namespaceHandlerResolver;
}
protected NamespaceHandlerResolver createDefaultNamespaceHandlerResolver() {
ClassLoader cl = (getResourceLoader() != null ? getResourceLoader().getClassLoader() : getBeanClassLoader());
return new DefaultNamespaceHandlerResolver(cl);
}
NamespaceHandlerResolver的作用是根据一个特定的命名空间uri(也就是xml文件头中指定的)来解析出一个NamespaceHandler组件,而NamespaceHandler才是用来实际处理对应的命名空间标签,实现对应功能的。
getNamespaceHandlerResolver可以获取一个命名空间处理器解析器,它在当前解析器未被创建的情况下,先调用createDefaultNamespaceHandlerResolver来创建一个DefaultNamespaceHandlerResolver。我们来看看DefaultNamespaceHandlerResolver做了什么。
DefaultNamespaceHandlerResolver默认情况下读取META-INF/spring.handlers下的文件来提供解析功能,而我们看spring-context的jar包下确实有这个文件:
内容是:
http\://www.springframework.org/schema/context=org.springframework.context.config.ContextNamespaceHandler
http\://www.springframework.org/schema/jee=org.springframework.ejb.config.JeeNamespaceHandler
http\://www.springframework.org/schema/lang=org.springframework.scripting.config.LangNamespaceHandler
http\://www.springframework.org/schema/task=org.springframework.scheduling.config.TaskNamespaceHandler
http\://www.springframework.org/schema/cache=org.springframework.cache.config.CacheNamespaceHandler
也就是说该包默认情况下提供了四个NamespaceHandler,其中就包含了ContextNamespaceHandler。这也是SPI设计思想的一次应用。
ContextNamespaceHandler
ContextNamespaceHandler的代码如下:
public class ContextNamespaceHandler extends NamespaceHandlerSupport {
@Override
public void init() {
registerBeanDefinitionParser("property-placeholder", new PropertyPlaceholderBeanDefinitionParser());
registerBeanDefinitionParser("property-override", new PropertyOverrideBeanDefinitionParser());
registerBeanDefinitionParser("annotation-config", new AnnotationConfigBeanDefinitionParser());
registerBeanDefinitionParser("component-scan", new ComponentScanBeanDefinitionParser());
registerBeanDefinitionParser("load-time-weaver", new LoadTimeWeaverBeanDefinitionParser());
registerBeanDefinitionParser("spring-configured", new SpringConfiguredBeanDefinitionParser());
registerBeanDefinitionParser("mbean-export", new MBeanExportBeanDefinitionParser());
registerBeanDefinitionParser("mbean-server", new MBeanServerBeanDefinitionParser());
}
}
它继承了NamespaceHandlerSupport,并且在init方法了调用了一批registerBeanDefinitionParser,看起来,是注册一些xml元素名到BeanDefinitionParser的映射,其中就有组件自动扫描需要用到的component-scan元素。
NamespaceHandlerSupport
该类是NamespaceHandler的支持类,将对应xml节点通过它对应的BeanDefinitionParser和BeanDefinitionDecorator策略接口进行处理。所以,这里用到了策略设计模式。
NamespaceHandlerSupport维护了一些map,用于保存元素到BeanDefinitionParser/Decorator的映射:
// 本地Element名 -> BeanDefinitionParser
private final Map<String, BeanDefinitionParser> parsers = new HashMap<>();
// 本地Element名 -> BeanDefinitionDecorator
private final Map<String, BeanDefinitionDecorator> decorators = new HashMap<>();
// 本地Attr名 -> BeanDefinitionDecorator
private final Map<String, BeanDefinitionDecorator> attributeDecorators = new HashMap<>();
同时实现了NamespaceHandler的两个方法:
// 将parse方法移交给对应的BeanDefinitionParser处理
/**
* 解析指定的Element并且向BeanDefinitionRegistry中注册任何该元素的执行结果中包含的`BeanDefinition`
*
* 如果实现希望嵌套在`<property>`标记内使用,则应返回解析阶段产生的主BeanDefinition
*/
@Override
@Nullable
public BeanDefinition parse(Element element, ParserContext parserContext) {
BeanDefinitionParser parser = findParserForElement(element, parserContext);
return (parser != null ? parser.parse(element, parserContext) : null);
}
// 将decorate方法移交给对应的BeanDefinitionDecorator处理
/*
* 解析特定的Node,并装饰提供的BeanDefinitionHolder,返回
* 我也不知道这是啥玩意儿
*/
@Override
@Nullable
public BeanDefinitionHolder decorate(
Node node, BeanDefinitionHolder definition, ParserContext parserContext) {
BeanDefinitionDecorator decorator = findDecoratorForNode(node, parserContext);
return (decorator != null ? decorator.decorate(node, definition, parserContext) : null);
}
特别需要注意的是,对于findDecoratorForNode的处理方式,因为Attrs和Element都是Node,所以该方法可能从decorator或attributeDecorators中返回:
private BeanDefinitionDecorator findDecoratorForNode(Node node, ParserContext parserContext) {
BeanDefinitionDecorator decorator = null;
String localName = parserContext.getDelegate().getLocalName(node);
if (node instanceof Element) {
decorator = this.decorators.get(localName);
}
else if (node instanceof Attr) {
decorator = this.attributeDecorators.get(localName);
}
else {
parserContext.getReaderContext().fatal(
"Cannot decorate based on Nodes of type [" + node.getClass().getName() + "]", node);
}
if (decorator == null) {
parserContext.getReaderContext().fatal("Cannot locate BeanDefinitionDecorator for " +
(node instanceof Element ? "element" : "attribute") + " [" + localName + "]", node);
}
return decorator;
}
总结一下就是,如果NamespaceHolder继承了NamespaceHolderSupport,就可以通过注册BeanDefinitionParser和BeanDefinitionDecorator来解析对应的XML节点,执行需要的功能,注册该功能返回的BeanDefinition。
BeanDefinitionParser
/**
* 实现可以自用的将自定义标签中的元数据转换成所需的任意数量的BeanDefinition
*/
public interface BeanDefinitionParser {
@Nullable
BeanDefinition parse(Element element, ParserContext parserContext);
}
ComponentScanBeanDefinitionParser
下面我们主要看对标component-scan元素的ComponentScanBeanDefinitionParser
它定义了这些静态常量,无非是component-scan标签中可以包含的属性名和元素名,我们注意到常用的base-package和exclude-filter都在其中:
private static final String BASE_PACKAGE_ATTRIBUTE = "base-package";
private static final String RESOURCE_PATTERN_ATTRIBUTE = "resource-pattern";
private static final String USE_DEFAULT_FILTERS_ATTRIBUTE = "use-default-filters";
private static final String ANNOTATION_CONFIG_ATTRIBUTE = "annotation-config";
private static final String NAME_GENERATOR_ATTRIBUTE = "name-generator";
private static final String SCOPE_RESOLVER_ATTRIBUTE = "scope-resolver";
private static final String SCOPED_PROXY_ATTRIBUTE = "scoped-proxy";
private static final String EXCLUDE_FILTER_ELEMENT = "exclude-filter";
private static final String INCLUDE_FILTER_ELEMENT = "include-filter";
private static final String FILTER_TYPE_ATTRIBUTE = "type";
private static final String FILTER_EXPRESSION_ATTRIBUTE = "expression";
看看parse方法
@Override
@Nullable
public BeanDefinition parse(Element element, ParserContext parserContext) {
// 获取`basePackage`属性
String basePackage = element.getAttribute(BASE_PACKAGE_ATTRIBUTE);
// 如果其中有`${}`,解析实际属性(Environment接口也是一个`PropertyResolver`),具有`resolvePlaceholders`方法
basePackage = parserContext.getReaderContext().getEnvironment().resolvePlaceholders(basePackage);
// 将basePackage按照ConfigurableApplicationContext中指定的分隔符进行分割(如果使用分隔符指定了多个的话)
String[] basePackages = StringUtils.tokenizeToStringArray(basePackage,
ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
// 真正扫描,注册BeanDefinition
ClassPathBeanDefinitionScanner scanner = configureScanner(parserContext, element);
Set<BeanDefinitionHolder> beanDefinitions = scanner.doScan(basePackages);
registerComponents(parserContext.getReaderContext(), beanDefinitions, element);
// `component-scan`和`property`没啥关系,所以这里直接返回null就行,外面不会依赖自己注册的bean中的一个的
return null;
}
parse方法分三步走,配置Scanner、使用scanner扫描所有BeanDefinition、根据返回的BeanDefinition注册组件到context。
parse三部曲 configureScanner
该方法根据element和parseContext创建ClassPathBeanDefinitionScanner,并进行一些配置
protected ClassPathBeanDefinitionScanner configureScanner(ParserContext parserContext, Element element) {
// 解析use-default-filters标签,并按其中的内容进行设置,默认为true
boolean useDefaultFilters = true;
if (element.hasAttribute(USE_DEFAULT_FILTERS_ATTRIBUTE)) {
useDefaultFilters = Boolean.parseBoolean(element.getAttribute(USE_DEFAULT_FILTERS_ATTRIBUTE));
}
// 创建Scanner,将BeanDefinition的注册委托给Scanner类,并使用默认的Filter
// 默认有一个用于拦截`@Component`注解的`AnnotationTypeFilter`,稍后会说
ClassPathBeanDefinitionScanner scanner = createScanner(parserContext.getReaderContext(), useDefaultFilters);
/*
进行默认的BeanDefinition设置
1. 设置是否lazyInit
2. 设置autowireMode
3. 设置默认initMethodName
4. 设置默认destroyMethodName
我不知道这个设置的依据来自于哪里,但是打断点之后,得到了如下默认设置:
1. lazyInit=false
2. autowireMode=AUTOWIRE_NO
3. dependencyCheck=DEPENDENCY_CHECK_NONE
4. init/destroyMethodName=null
所以,默认情况下是完全没有开启自动装配的
*/
scanner.setBeanDefinitionDefaults(parserContext.getDelegate().getBeanDefinitionDefaults());
// 进行AutowireCandidatePattern的设置,同样不知道是啥,但打断点发现执行完之后autowireCandidatePattern=null
scanner.setAutowireCandidatePatterns(parserContext.getDelegate().getAutowireCandidatePatterns());
// 检查是否有resource-pattern属性,并进行设置
if (element.hasAttribute(RESOURCE_PATTERN_ATTRIBUTE)) {
scanner.setResourcePattern(element.getAttribute(RESOURCE_PATTERN_ATTRIBUTE));
}
// 如果设置了name-generator属性,就解析生成器类并设置进去
try {
parseBeanNameGenerator(element, scanner);
}
catch (Exception ex) {
parserContext.getReaderContext().error(ex.getMessage(), parserContext.extractSource(element), ex.getCause());
}
// 下面都是,如果设置了xx属性,解析并按照设置来配置scanner
try {
parseScope(element, scanner);
}
catch (Exception ex) {
parserContext.getReaderContext().error(ex.getMessage(), parserContext.extractSource(element), ex.getCause());
}
parseTypeFilters(element, scanner, parserContext);
return scanner;
}
configureScanner就是根据XML中的属性创建Scanner并对它进行一些初始配置,我觉得这里面最关键的是设置了BeanDefinitionDefaults并关闭了自动装配。
parse三部曲 scanner.doScan
根据parse代码中的这一步就可以看出,doScan之后要扫描的所有BeanDefinition已经扫描完毕,等待注册到Context中:
ClassPathBeanDefinitionScanner scanner = configureScanner(parserContext, element);
Set<BeanDefinitionHolder> beanDefinitions = scanner.doScan(basePackages);
看看doScan怎么完成的扫描
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
// 初始化BeanDefinition集合
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
// 扫描所有basePackage
for (String basePackage : basePackages) {
// 获取所有候选组件
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
// ...省略下面的代码...
}
return beanDefinitions;
}
这里我们看到,它遍历了所有的basePackage,然后对每一个调用findCandidateComponents来寻找候选组件。
findCandidateComponents首先检查了类中有没有一个组件索引,如果有就怎样怎样,这个分支咱先不管,看下一个分支,调用了scanCandidateComponents
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
}
else {
return scanCandidateComponents(basePackage);
}
}
scanCandidateComponents的代码:
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
// 这里最终组合成classpath*:basepackage/**/*.calss
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
// 获取等待扫描的路径下的所有Resource(也就是所有类被)
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
for (Resource resource : resources) {
try {
// 读取类的元数据
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
// 如果是候选组件
if (isCandidateComponent(metadataReader)) {
// 创建ScannedGenericBeanDefinition
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(resource);
// 这里又对sbd进行了一个判断,这个判断好像判断的BeanDefinition中定义的Bean类是否是一个具体的顶级类,只有是的时候才添加到候选中(或者是顶级抽象类但有Lookup注解)
if (isCandidateComponent(sbd)) {
candidates.add(sbd);
}
}
}
catch (ex) {}
}
}
catch (IOException ex) {}
return candidates;
}
这个方法的主要目的就是对指定包下的所有类进行遍历,并判断它们是否是一个候选组件,如果是就创建BeanDefinition并添加进去,如何判断?:
protected boolean isCandidateComponent(MetadataReader metadataReader) throws IOException {
// 对于所有的`excludeFilters`,如果该类的元信息与filter所定义的匹配,它就不是候选组件
for (TypeFilter tf : this.excludeFilters) {
if (tf.match(metadataReader, getMetadataReaderFactory())) {
return false;
}
}
// 对于所有的`includeFilters`,如果该类的元信息与filter所定义的不匹配,它就不是候选组件,如果匹配,再看看有没有`@Conditional`注解
for (TypeFilter tf : this.includeFilters) {
if (tf.match(metadataReader, getMetadataReaderFactory())) {
// 如果具有Conditional注解,再判断Conditional注解中的内容是否满足
return isConditionMatch(metadataReader);
}
}
return false;
}
所以,最终一个类是否能作为组件,主要是通过excludeFilters和includeFilters来决定的,而在上面的configureScanner阶段,我们注意到一个默认的AnnotationTypeFilter被注册到includeFilters中,它检测@Componet注解:
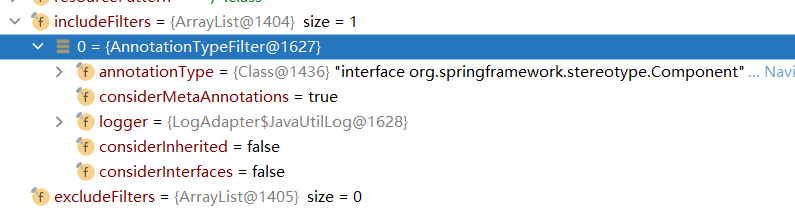
这个东西我们就不深入探讨了,也稍有点复杂,你就需要知道,AnnotationTypeFilter用于匹配类上是否有指定注解,它匹配该类本身,并且可以配置是否考虑父类和接口上是否有指定主键,如果考虑,它还会对该类的父类,该类的接口进行匹配。在这里是不考虑继承和接口的。
所以,到这里findCandidateComponet方法获取候选组件完成了,它的原理就是使用自带的默认AnnotationTypeFilter来过滤basePackage指定的所有包下具有@Component注解的组件。
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
for (String basePackage : basePackages) {
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
// 对于每一个候选BeanDefinition
for (BeanDefinition candidate : candidates) {
// 设置作用域
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
// 生成bean名字
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
// 如果是AbstractBeanDefinition
// 对BeanDefinition做post-processing
// 主要是应用那个BeanDefinitionDefaults
// 然后如果autowireCandidatePatterns不为null,调用setAutowireCandidate
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
// 如果是AnnotatedBeanDefinition,这是一种无需加载Bean就能公开Bean类中注解信息的BeanDefinition
// 就对它进行处理,该处理中主要检测是否具有@Lazy、@Primary、@DependsOn、@Role、@Description注解,如果有就向BeanDefinition中设置对应的配置
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
// 检测该候选是否需要注册,true是需要,false是跳过
// 在候选beanName与已有bean冲突时无需注册,checkCandidate会抛出冲突异常
if (checkCandidate(beanName, candidate)) {
// 将BeanDefinition以及生成的beanName包装到BeanDefinitionHolder中
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
// 应该是给一个返回代理的机会,但我们的示例里实际没有用到
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
// 向registry中注册BeanDefinition
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
到这,scanner.doScan方法解析完成,它会给basePackage包下所有@Component标注的类创建BeanDefinition,应用默认BeanDefinition设置,并且检查Bean类上的一些注解,对BeanDefinition进行对应设置,如@Lazy注解。最后,它会将BeanDefinition包装成BeanDefinitionHolder,并返回Holder列表。而且,该方法已经向BeanFactoryRegistry注册了BeanDefinition,也就是说parse中的最后一步registerComponents中不会重复这个工作,而是另有其它工作。
下图可以说明,在scanner.doScan这一步中,BeanDefinition确实已经被注册到context了:
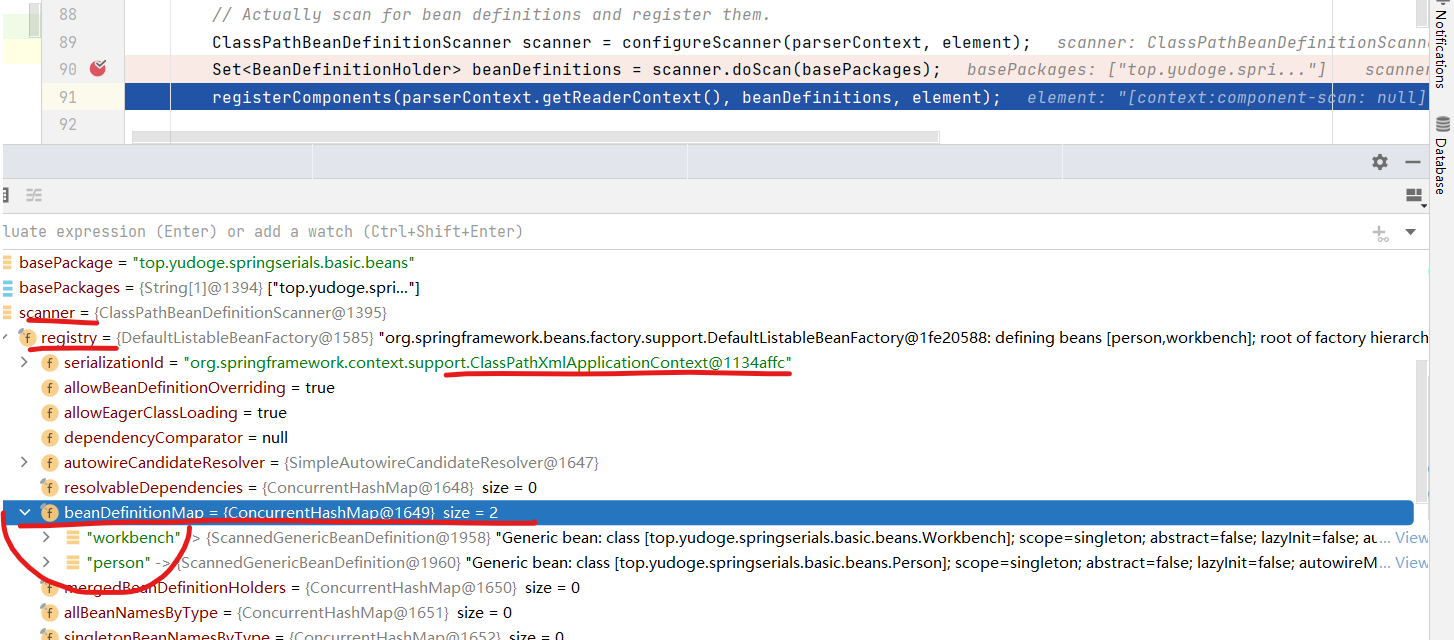
BeanDefinitionHolder中封装了BeanDefinition和它的BeanName、别名等信息
parse三部曲 registerComponents
这是ComponentScanBeanDefinitionParser中的parse方法的最后一步,从名字上来看是将扫描出的BeanDefinition注册到context中,但这在第二步的最后已经做了。
protected void registerComponents(
XmlReaderContext readerContext, Set<BeanDefinitionHolder> beanDefinitions, Element element) {
// 不到是啥
Object source = readerContext.extractSource(element);
// 这也不管它是啥
CompositeComponentDefinition compositeDef = new CompositeComponentDefinition(element.getTagName(), source);
// 将传入的beanDefinitions添加到这个compositeDef中
for (BeanDefinitionHolder beanDefHolder : beanDefinitions) {
compositeDef.addNestedComponent(new BeanComponentDefinition(beanDefHolder));
}
boolean annotationConfig = true;
if (element.hasAttribute(ANNOTATION_CONFIG_ATTRIBUTE)) {
annotationConfig = Boolean.parseBoolean(element.getAttribute(ANNOTATION_CONFIG_ATTRIBUTE));
}
// 如果XML中开启了注解配置(默认开启),注册注解配置处理器
if (annotationConfig) {
Set<BeanDefinitionHolder> processorDefinitions =
AnnotationConfigUtils.registerAnnotationConfigProcessors(readerContext.getRegistry(), source);
// 将注解处理器也添加到compositeDef中
for (BeanDefinitionHolder processorDefinition : processorDefinitions) {
compositeDef.addNestedComponent(new BeanComponentDefinition(processorDefinition));
}
}
// 发布ComponentRegistered事件
readerContext.fireComponentRegistered(compositeDef);
}
关键就在于这个registerAnnotationConfigProcessors,这个方法调用完之后,我们的registry,也就是ApplicationContext中多了五个Bean。
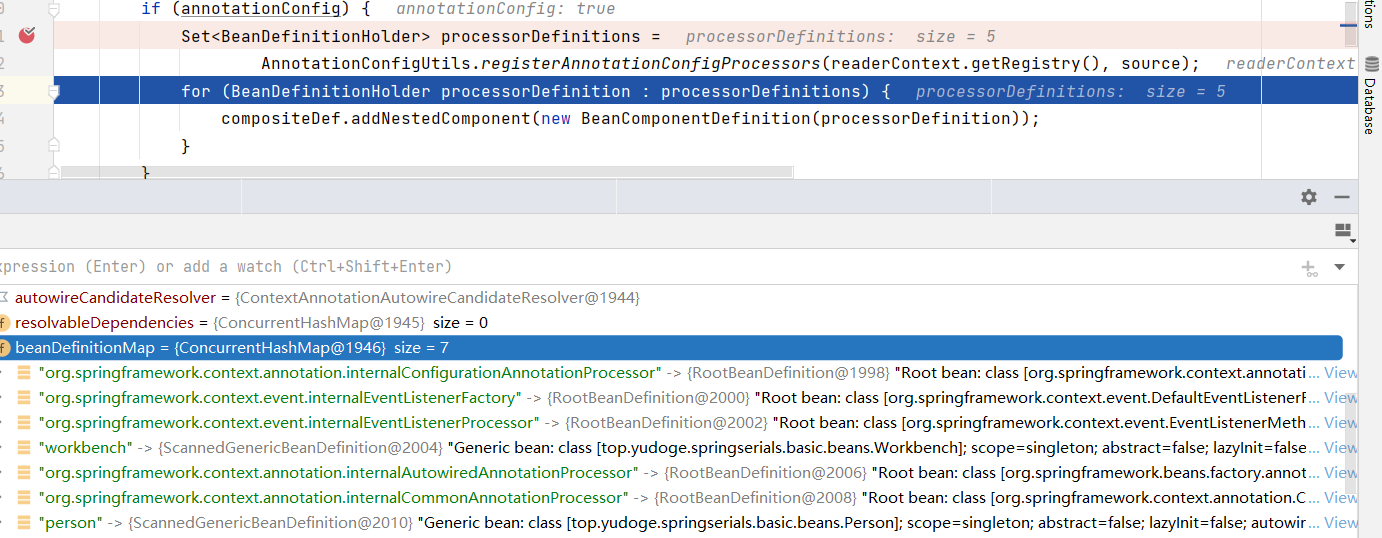
它们是一些BeanPostProcessor。通过上面的代码分析,我们知道,如果你想让一个BeanPostProcessor为ApplicationContext所用,那么,你需要将它作为Bean注册到ApplicationContext中,AbstractApplicationContext保证了这些BeanPostProcessor类型的Bean会被设置到内部持有的BeanFactory中,稍后在创建Bean时,作用于Bean的生命周期。
思考下,如果给你一个ApplicationContext,让你实现AOP,你怎么实现?无非也是向其中添加BeanPostProcessor。同时,你也可以提供相关的NamespaceHandler来处理xml中的aop元素。
所以,现在我们可以猜测,使用component-scan时的自动装配功能并不是BeanFactory实现的,它通过为BeanDefinition设置默认值,完全禁用了每一个Bean的自动装配功能,取而代之的是,它通过BeanPostProcessor拦截Bean的生命周期实现仅对具有@Autowired注解的属性注入。这也解释了为什么默认情况下的未满足普通属性也没有被自动装载,因为每个Bean的自动装载功能都没开。
AutowiredAnnotationBeanPostProcessor
下面来看看被自动注册到ApplicationContext中的这个自动装配相关的BeanPostProcessor:
public class AutowiredAnnotationBeanPostProcessor implements SmartInstantiationAwareBeanPostProcessor,
MergedBeanDefinitionPostProcessor, PriorityOrdered, BeanFactoryAware
- 它关心的是Bean的实例化阶段
- 它关心它所在的BeanFactory(因为它也被作为Bean放到了BeanFactory中)
- 它是一个优先对象,这种BeanPostProcessor会在其它普通BeanPostProcessor之前初始化(PriorityOrdered接口在我们之前的源码分析文章中被残忍的忽略了)
在它的构造方法中,它添加了三种可以被认为是需要自动装配行为的注解,同时这个列表可以被覆盖:
// @Autowired、@Value、@Inject
this.autowiredAnnotationTypes.add(Autowired.class);
this.autowiredAnnotationTypes.add(Value.class);
this.autowiredAnnotationTypes.add((Class<? extends Annotation>)ClassUtils.forName("javax.inject.Inject", AutowiredAnnotationBeanPostProcessor.class.getClassLoader()));
它重写了InstantiationAwareBeanPostProcessor中属性相关的两个回调方法:
@Override
public PropertyValues postProcessProperties(PropertyValues pvs, Object bean, String beanName) {
// 获取自动装配元数据
InjectionMetadata metadata = findAutowiringMetadata(beanName, bean.getClass(), pvs);
try {
// 向pvs中注入
metadata.inject(bean, beanName, pvs);
}
catch (BeanCreationException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanCreationException(beanName, "Injection of autowired dependencies failed", ex);
}
return pvs;
}
@Deprecated
@Override
public PropertyValues postProcessPropertyValues(
PropertyValues pvs, PropertyDescriptor[] pds, Object bean, String beanName) {
// 调用上面那个方法
return postProcessProperties(pvs, bean, beanName);
}
我没力气分析这个类的整个结构了,而且这个文章已经很长了,所以,我们只看看findAutowireingMetadata返回的结果:
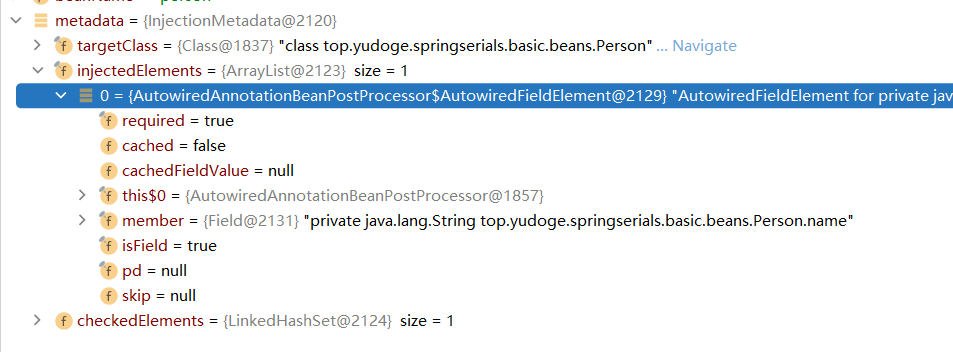
上图中可以看出,我们正在处理的Bean是Person,它使用@Value注解向name属性中注入了一个值,这些都被反映在返回的metadata中了。
而metadata.inject方法会调用resolveFieldValue方法,将metadata中的每个待注入属性都注入进去,注入的方式就是通过beanFactory.resolveDependency方法,手动传入需要被自动装载的依赖描述——DependencyDescriptor,metadata自然能够很简单的构建出这个东西,因为它本身所保存的就是待注入的属性信息:
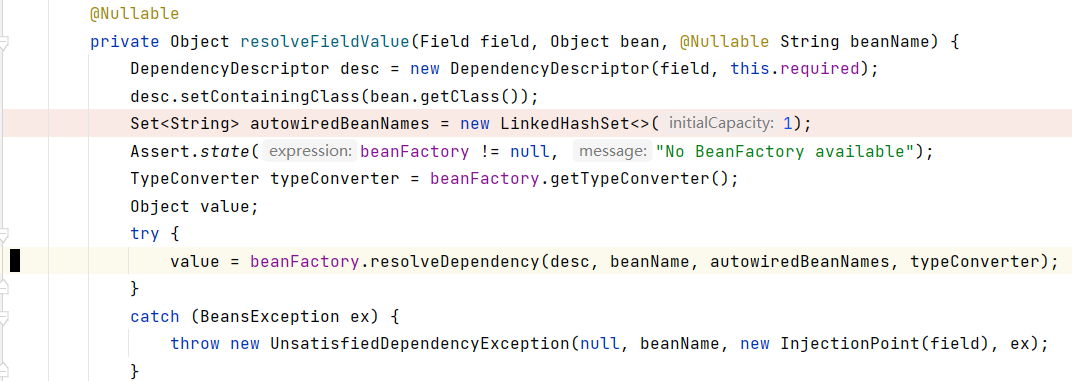
beanFactory.resolveDependency会处理好表达式值(通过@Value注入)或其它Bean的解析,并返回要注入的东西(在这个示例中就是字符串类型的"Yudoge",由@Value注解在Person类的name属性上标注)。
Spring BeanFactory接口分析&源码解读#自动装载流程一文中有这个resolveDependency方法的分析。
总结
ClassPathXmlApplicationContext默认并不带自动装配功能,它只通过XML中定义的结构去解析并生成BeanDefinition- 自动装配功能由
context命名空间提供 context命名空间的组件扫描功能为每一个扫描到的组件都定义了它BeanDefinition的默认值,并在关闭了它的自动装配功能- 自动装配功能一旦关闭,
beanFactory.getBean时不再会扫描未满足普通属性,并自动装配它们。 context命名空间通过向ApplicationContext中添加BeanPostProcessorBean来向底层BeanFactory中注册一批BeanPostProcessor,这其中包括用于实现自动装配的AutowiredAnnotationBeanPostProcessorAutowiredAnnotationBeanPostProcessor是一个实例化感知BeanPostProcessor,它重写postProcessProperties方法和postProcessPropertyValues方法,拦截了Bean初始化阶段的属性设置post-processing- 在这里,它对于每一个包含
@Value、@Autowired、@Inject注解的属性,通过调用BeanFactory中的resolveDependency来获得需要被注入的Bean或值,并注入进被拦截的Bean中。 - 其它的想起来再添吧

 浙公网安备 33010602011771号
浙公网安备 33010602011771号