Nginx负载均衡
跨web或应用服务器组间的HTTP流量负载均衡,具有多种算法和如慢速启动(slow-start)和会话持久化的高级特性。
概览
跨多个应用实例间负载均衡是一个通用技术,用于优化资源利用率、最大化吞吐量、降低延迟以及确保容错配置。
Watch the NGINX Plus for Load Balancing and Scaling webinar on demand for a deep dive on techniques that NGINX users employ to build large‑scale, highly available web services.
Nginx和Nginx Plus可以作为一个非常高效的HTTP负载均衡器,在不同的部署场景中使用。
代理HTTP流量到一组服务器
为了使用NginxPlus或Nginx进行一组服务器间的HTTP流量负载均衡,首先你需要使用upstream指令定义组。这个指令被放在http上下文中。
组中的服务器使用server指令配置(不要与定义运行在Nginx中的虚拟服务器混淆)。举个例子,下面的配置定义了一组名为backend并且包含了三个服务器的配置:
http {
upstream backcend {
server backend1.example.com weight=5;
server backend2.example.com;
server 192.0.0.1 backup;
}
}
为了穿钉请求到一个server组中,你需要在proxy_pass指令中指定改组的名字(或者fastcgi_pass、memcached_pass、scgi_pass或uwsgi_pass指令)。在下一个示例中,一个在Nginx中运行的虚拟服务器传递了所有的请求到上个示例中定义的backend上游组(upstream group):
server {
location / {
proxy_pass http://backend;
}
}
下面的示例组合了上面的两个代码片段,并且展示了如何代理HTTP请求到backend服务器组。这个组中包含三个服务器,其中的两个运行相同的应用实例,而第三个是一个备用服务器,因为在upstream块中并没有指定负载均衡算法,Nginx使用默认的算法,round-robin。
http {
upstream backend {
server backend1.example.com;
server backend2.example.com;
server 192.0.0.1 backup;
}
server {
location / {
proxy_pass http://backend;
}
}
}
选择一个负载均衡算法
Nginx支持四种负载均衡算法,Nginx Plus添加了两种额外的算法:
-
Round Robin - 请求公平的被分布到server中,使用server weight设置权重。这个方法是被默认使用的:
upstream backend { # no load balancing method is specified for Round Robin server backend1.example.com; server backend2.example.com; } -
最少连接 - 请求被发送到具有最少活动连接数的服务器上,依然可以设置权重:
upstream backend { least_conn server backend1.example.com; server backend2.example.com; } -
IP Hash - 请求被发送到哪个Server取决于客户端的IP地址。在这个示例中,IPv4地址中的前三段或者整个IPv6地址被用于计算hash值。这个算法保证同一个地址被映射到同一个服务器上,除非它不可用:
upstream backend { ip_hash; server backend1.example.com; server backend2.example.com; }如果一个服务器需要从负载均衡轮转(load-balancing rotation)中暂时移出,它可以被标记上
down参数,这样就可以保持当前映射到它的客户端的IP地址(依然能正常访问)。本来由这个server处理的请求将自动的发送到组中的下一个server上。 -
Generic Hash - 请求将被发送到哪个服务器上取决于用户自定义的键,它可以是一个文本值、变量或一个组合。比如,key可以是一个成对出现的源IP地址或端口,或者是下面示例中的URI:
upstream backend { hash $request_uri consistent; server backend1.example.com; server backend2.example.com; }hash指令的可选项参数consistent开启了ketama一致性hash负载均衡。请求在所有上游服务器间,基于用户自定义的键值被均匀的分布。如果一个上游server被加入组中或被移除,只有一少部分键将重新映射。在负载均衡的缓存服务器或其它积累状态的应用程序中,这能最小化缓存丢失。 -
Least Time (Nginx Plus Only)- 对于每一个请求,Nginx Plus选择具有最小平均延迟以及最小活跃连接的服务器,其中最小平均延迟是根据
least_time指令的参数计算的,它的参数包括以下几种:header- 从服务器中接到第一个字节的时间last_byte- 从服务器中接收到完整响应的时间last_byte inflight- 从服务器中接收到完整响应的时间,同时考虑不完整请求
upstream backend { least_time header; server backend1.example.com; server backend2.example.com; } -
Random - 每一个请求将被传递到一个随机选择的服务器上。如果指定了参数
two,首先Nginx在考虑权重的情况下随机算则两个服务器,然后选择其中的一个,可以指定如下选择算法:least_connleast_time=header(Nginx Plus)least_time=last_byte(Nginx Plus)
upstream backend { random two least_time=last_byte; server backend1.example.com; server backend2.example.com; server backend3.example.com; server backend4.example.com; }随机负载均衡算法应该用在多个负载均衡器传递请求到同一组后端的情况下。对于负载均衡器具有所有请求的完整视图的情况下,使用其它的负载均衡方法,比如round robin、least connections和least time。
注意:当你配置Round Robin外的任何算法是,在upstream {}块的server列表指令上面放置对应的指令(hash、ip_hash、least_conn、least_time、random)
负载均衡示例
下面我们使用docker compose来搭建一个负载均衡的实例
下面的yaml配置文件中,启动了三个基于nodejs+express的后端实例,并且,第一个实例的端口是3000,映射到本地的3000端口,第二个是3001,映射到本地的3001端口,第三个是3002,映射到本地的3002端口。
version: '1.0.0'
services:
bk1:
image: "yudoge/express"
restart: always
environment:
- EXPRESS_APPLICATION_PORT=3000
ports:
- 3000:3000
volumes:
- ./app.js:/root/app/app.js
bk2:
image: "yudoge/express"
restart: always
environment:
- EXPRESS_APPLICATION_PORT=3001
ports:
- 3001:3001
volumes:
- ./app.js:/root/app/app.js
bk3:
image: "yudoge/express"
restart: always
environment:
- EXPRESS_APPLICATION_PORT=3002
ports:
- 3002:3002
volumes:
- ./app.js:/root/app/app.js
nginx:
image: "nginx"
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf
ports:
- 8080:8080
app.js的内容如下:
const express = require('express')
const app = express()
const port = process.env.EXPRESS_APPLICATION_PORT
app.get('/port', (req, resp) => {
resp.send('Hi, my port is => ' + port);
})
app.listen(port, () => {
console.log(`Express app listening on port ${port}`)
})
app.js中,读取环境变量里指定的端口号,提供了一个/port请求处理器,它会将当前的端口号输出,这样,我们能够在前端鉴别当前是哪个上游服务器在实际处理请求。
下面就是nginx.conf文件
user www-data;
worker_processes auto;
pid /run/nginx.pid;
include /etc/nginx/modules/*.conf;
events {
worker_connections 768;
# multi_accept on;
}
http {
upstream backend {
server bk1:3000;
server bk2:3001;
server bk3:3002;
}
server {
listen 8080;
location / {
proxy_pass http://backend;
}
}
}
这里配置了三个上游服务器,然后反向代理服务器在8080端口开启,将请求转发到上游服务器中的一个。默认情况下使用round robin算法,也就是说,三个服务器会被顺序的访问:
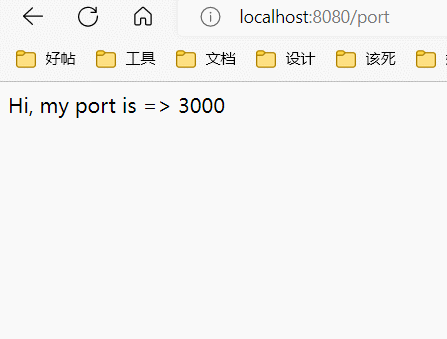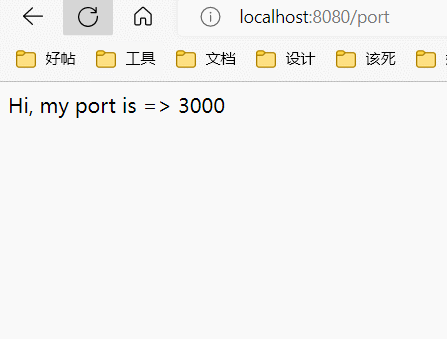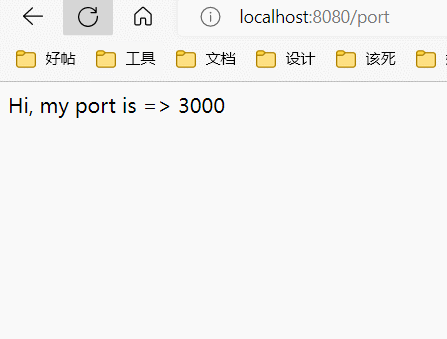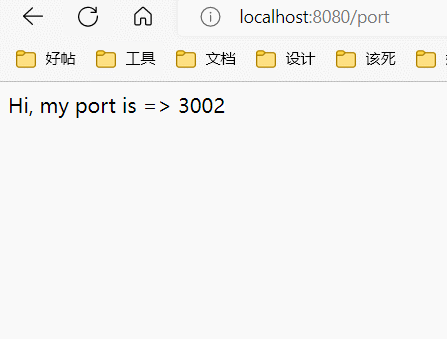
添加权重
将上游服务器bk1的权重设置为5
upstream backend {
server bk1:3000 weight=5;
server bk2:3001;
server bk3:3002;
}
进入nginx容器:
➜ ~ docker exec -it load_balancer_bkserver-nginx-1 /bin/bash
root@d14ab8d92887:/# nginx -s reload
2022/07/15 04:03:34 [notice] 45#45: signal process started
root@d14ab8d92887:/#docker exec -it load_balancer_bkserver-nginx-1 /bin/bash
这样之后,配置并没有生效,所以我后来使用了
docker compose down再docker compose up的方式
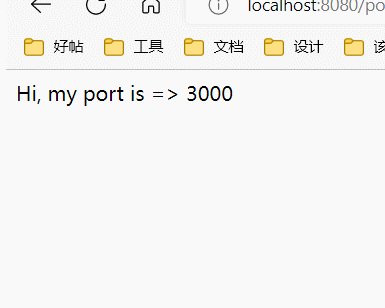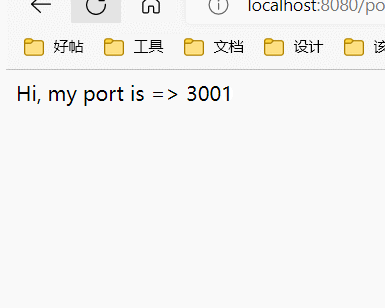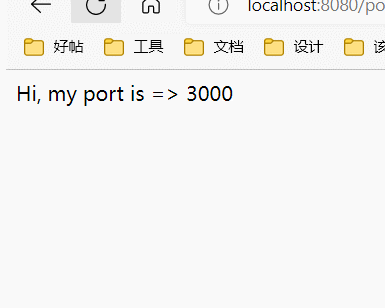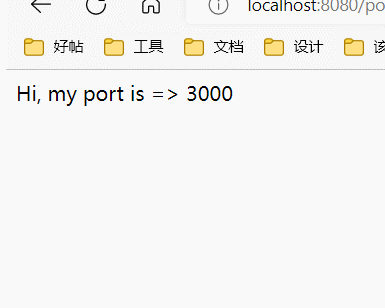
3000端口明显比其它出现的更多,好像是:
3000, 3000, 3000, 3001, 3000, 3002, 3000
IP HASH算法
下面将负载均衡算法改成IP HASH算法
upstream backend {
ip_hash;
server bk1:3000;
server bk2:3001;
server bk3:3002;
}
达到的效果就是我们的访问被固定到某台机器上了,我这里是3000。
服务器权重
默认情况下,Nginx使用Round Robin算法根据服务器的权重将请求分不到组中的服务器上。server指令的weight参数可以设置一个服务器的权重,默认是1。
upstream backend {
server backend1.example.com weight=5;
server backend2.example.com;
server 192.0.0.1 backup;
}
在这个例子中,backend1.example.com具有权重5,其它两个服务器具有默认权重1,但是192.0.0.1被标记为backup服务器,除非其它两个服务器都不可用了,否则它不会接收到任何请求。对于上面的权重设置,任何6个请求中,有5个被发送到backend1.example.com,1个被发送到backend2.example.com。
服务器慢启动(Slow-Start)
服务器慢启动特性可以防止最近被恢复的服务器被连接淹没。这可能导致超时并导致服务器再次被标记为失败。
在Nginx Plus中,慢启动允许一个上游服务器在完成恢复或变得可用时逐渐地从0开始恢复它的权重到它指定的值。这可以通过server指令的slow_start参数完成:
upstream backend {
server backend1.example.com slow_start=30s;
server backend2.example.com;
server 192.0.0.1 backup;
}
time值(30)设置了Nginx Plus恢复server的连接数量到满值的时间。
注意,如果group中只有一个server,server指令的max_fails、fail_timeout和slow_start参数将被忽略,并且server将永远不会被认为是不可用的。
题外话,
slow_start是Nginx Plus的功能,FUCK

建立持久化Session
Nginx Plus特有功能 略
限制连接数量
Nginx Plus特有功能 略
配置健康检测
这个这篇文章里没细说,官网给了另一篇文章:HTTP Health Checks,这里将这另一篇文章中的被动式健康检查一节翻译一下,因为另一种是Nginx Plus特有的。
在被动健康检查中(Passive Health Checks),Nginx在事务发生时监控十五,并且尝试恢复失败的连接。如果事务仍然无法被恢复,Nginx以及Nginx Plus将标记这个服务器为不可用的并且临时停止向它发送请求直到它再次被标记为可用。
哪一个上游server被标记为不可用,这通过upstream块中server指令的参数定义在每一个上游server中:
fail_timeout- 定义要将服务标记为不可用,必须发生多次失败尝试的时间以及服务器被标记为不可用的时间(默认为10秒)max_fails- 设置在服务器被标记为不可用的fail_timeout期间必须发生的失败尝试次数(默认为1次)
在下面的例子中,如果Nginx向一个服务器发送请求失败或者没有从服务器接收到响应,在30秒内发生3次,Nginx就会标记这个server为不可用的:
upstream backend {
server backend1.example.com;
server backend2.example.com max_fails=3 fail_timeout=30s;
}
在多个worker进程间分享数据
如果一个upstream块没有包含zone指令,那么每一个worker进程都保留着一份它自己的server组配置并维护自己的相关计数器集合。计数器中包含每一个Server的当前连接数以及传递请求到一个Server上的失败尝试次数。因此,Server组的配置不能动态修改。
当zone指令被upstream块包含,upstream组的配置在内存中维护一块在所有worker进程间共享的区域。这个场景是可动态配置的,因为worker进程访问了相同的组配置的拷贝,并且使用了相同的相关计数器。
对于upstream组的活动健康检查以及动态重配置,zone指令是强制的。然而,upstream组的其它特性也可以从这个指令的使用中受益。
比如,如果一个组的配置不是共享的,每一个worker进程维护它自己的传递请求到server的失败尝试的计数器,在这种情况下,每一个请求只能到达一个worker进程,当一个worker进程被选中处理一个请求,并且在传送请求到server的过程中失败,其它worker进程对其是一无所知的。当一些worker进程认为一个Server不可用时,其它的worker进程可能仍然向这个server上发送请求。在这种(没有设置zone的)情况下,只有fail_timeout设置的时间范围内的失败次数达到max_fails乘以工作进程数量时,server才会被明确地认为已经不可用。另一方面,zone命令却总能保证预期的行为。
类似的,如果没有zone指令,Least Connections负载均衡算法可能无法像预期一样工作,至少在低负载情况下是这样的。这个参数传递一个请求到具有最少活动连接的server上,如果组的配置不是共享的,每一个worker进程使用它自己的计数器,并且可能发送一个请求到刚被另一个worker进程发送到的服务器上,然而,你可以通过增加请求数量来减少这个效果。在高负载情况下,请求被均匀地分布在多个worker进程之间,并且Least Connections算法按照预期工作。
设置zone大小
我不可能推荐出一个理想的内存zone大小,因为具体场景下的变化是很大的。需要的内存量由你都使用了什么功能(session持久化、健康检查or DNS re-resolving)以及上有服务器如何被识别。
举个例子,使用sticky_routesession持久化方法并且一个单独的健康检查开启,256KB的zone可以容纳的指定数量的上游服务器信息:
- 128台服务器(每个都通过IP地址:端口号定义)
- 88台服务器(每个都通过hostname:port定义,hostname可以被解析成一个单独的IP地址)
- 12台服务器(每个都通过hostname:port定义,hostname可以被解析成多个IP地址)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号