MySQL——Explain中的部分字段含义
EXPLAIN可能返回多行,每一行揭示了在一个关联查询中,MySQL读取的一个表的细节。所以单表查询可以看成一个只有一个表的关联查询,EXPLAIN只返回一行。
本篇虽然参考了MySQL的官方文档,但官方文档中给的细节太少了,所以有很多我根据测试所意淫出来的理论,我不敢保证这些理论的正确性,我也找不到证据证明它们完全正确。所以理性参考,如果您有其它见解欢迎留言评论!
EXPLAIN Join Types
Explain返回值中的type字段的含义,它揭示了表是如何被连接的(在MySQL中即使是单表查询也被抽象成关联查询)。
下面是该字段可能的值,从情况好到坏排序:
system
官方的说法是在表只有一行时它会被看作“系统表”,这时查询就是system类型,不过我构建了一行的表,也查询了MySQL中的只有一行的系统表,结果都没有显示type=system。

const
当一个表最多有一个行是匹配的,并且是在查询开始时读取,这时type=const。当你比较主键和唯一索引的全部部分时,就是const,因为最多出现一条数据。
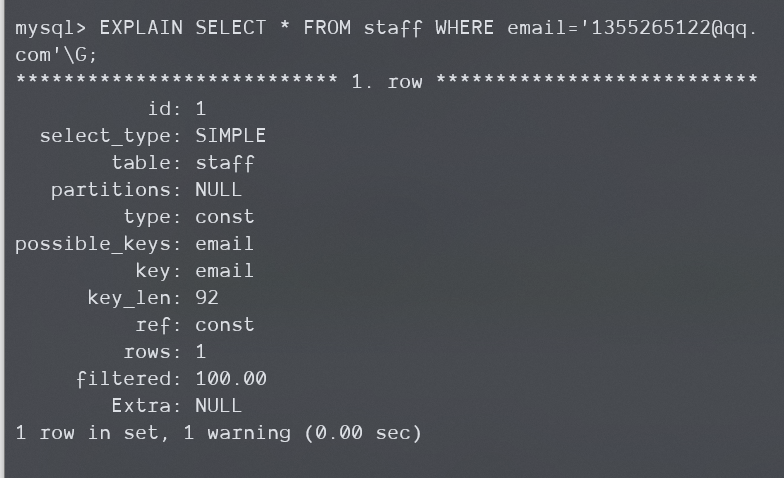
对标的就是上面这种普通的主键或唯一键等值查询,很好理解。
我脑袋里突然想到,假设我们在做一对一的多表连接,也就是在另一个表中的外键也具有UNIQUE约束,这时,被连接的表也只有一条对应的数据,此时该表的type是否是const?
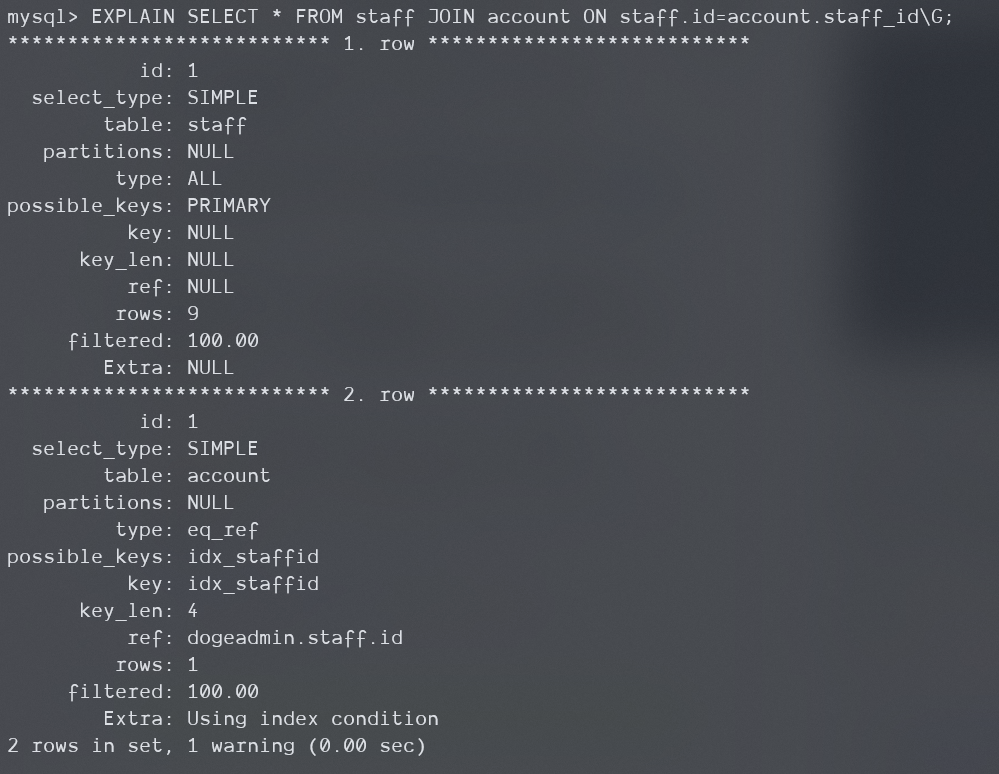
下面,staff代表一个员工,员工有一个账号account,它们是一对一的,staff.id对应account.staff_id,并且在这个account.staff_id上有唯一约束:
EXPLAIN SELECT * FROM staff
JOIN account ON staff.id=account.staff_id\G;
可以看到account表的type并非const,即使对应的确实只有一行。
但当我们把上面的查询加一个限定条件:
EXPLAIN SELECT * FROM staff
JOIN account ON staff.id=account.staff_id
WHERE staff.id = 1\G;
两个表又都会用上const:
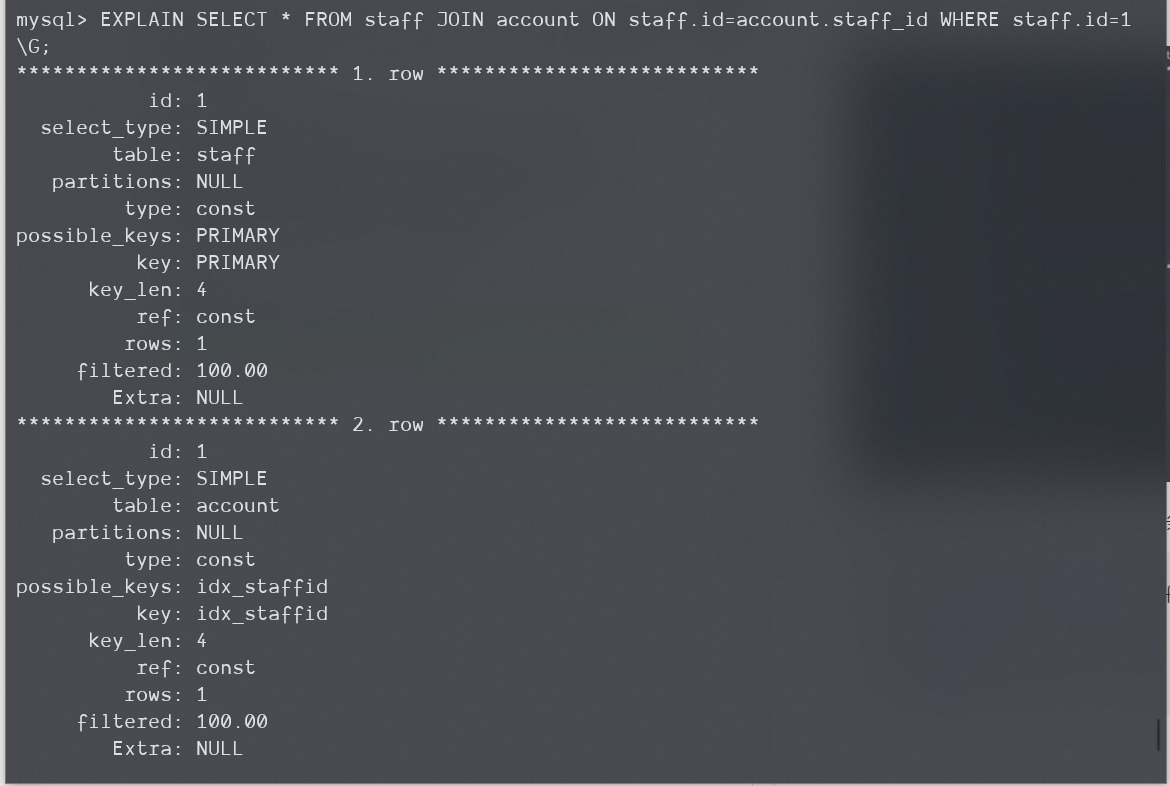
WTF????Excuse me????
我猜应该是这样的,
const只对应WHERE中把条件给出来,并且能直接应用到当前MySQL正在检索的表上从而直接得出一行的情况,而第一个例子里没有WHERE,第二个例子虽然WHERE只针对staff表,但《高性能MySQL》一书中说,这个条件实际会被MySQL优化器也传递给被连接的表,所以这里也用到了const。
eq_ref
对于前面表中的每一个组合,读取该表中的一行。当连接使用索引的所有部分,并且这个索引是主索引或唯一索引。
也就是前面const中第一个例子的account表。
要注意的是,
const和eq_ref中说的取一行,不等价于结果中只有一行,一个查询在特定的参数下可能只返回一行结果,但换一个参数可能就返回多行了,这里的一行的意思是具有某些索引约束,在任何情况下都只可能返回一行。
ref
对于前面表中的每一个组合,读取该表中所有匹配的行。这在索引使用最左前缀或者键不是主键或唯一键的情况下。如果只匹配少数行,那么ref或许不错。
一对多查询是一个很好的例子,下面是查找指定国家的所有城市的例子:
EXPLAIN SELECT country, city
FROM country JOIN city
USING(country_id) WHERE country_id = 1\G;
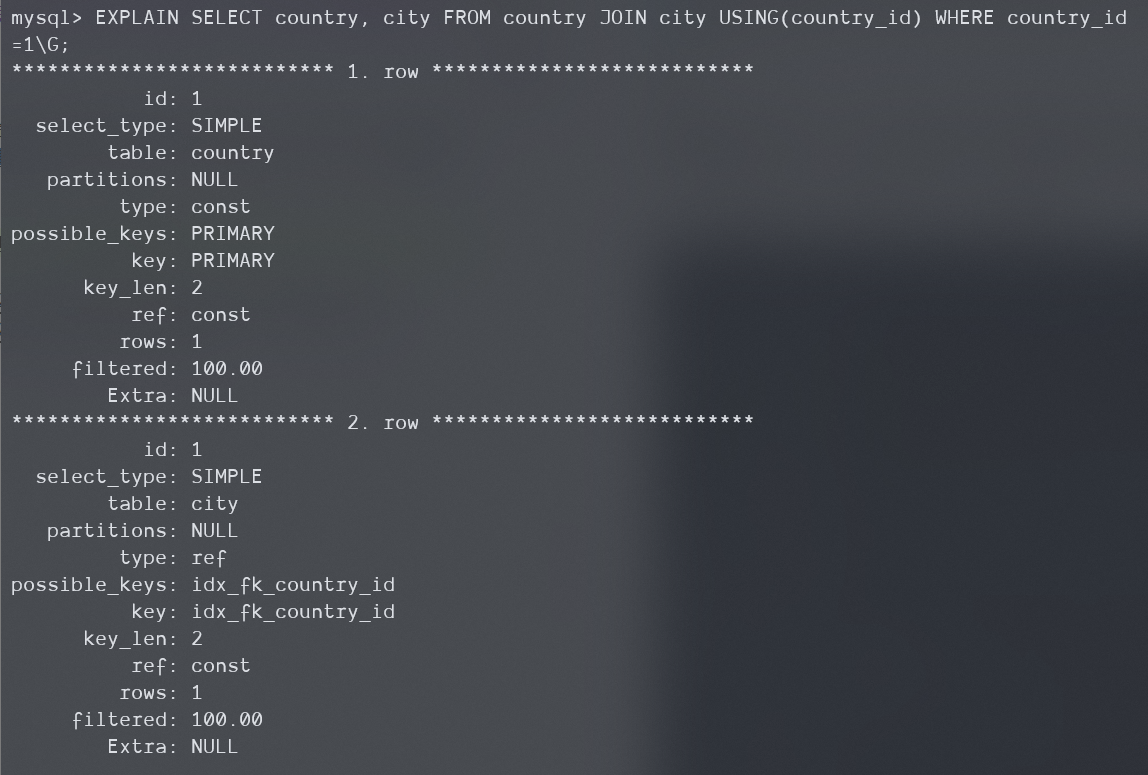
城市表的type=ref。
fulltext
使用全文索引执行时
ref_or_null
除了额外的搜索NULL值的行以外,符合ref的条件。
SELECT * FROM ref_table
WHERE key_column=expr OR key_column IS NULL;
index merge
该连接类型指示了索引合并优化被使用了。好像也就是MRR优化。就是在查询条件中有针对一个索引的多个范围查询,MySQL会将它们拆成单独的范围,分别进行查询,再将结果进行合并。
unique_subquery
替换了如下形式的子查询中的某些eq_ref,子查询中返回不重复的唯一值:
EXPLAIN SELECT account.username FROM account
WHERE staff_id IN (
SELECT id FROM staff WHERE dept_id = 1
)\G;
但我这里显示的还是eq_ref。
index_subquery
类似unique_subquery,但不要求子查询中返回不重复的唯一值。也就是说替换了ref喽。
value IN (SELECT key_column FROM single_table WHERE some_expr)
range
使用索引检查指定范围的行时。
range can be used when a key column is compared to a constant using any of the =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, LIKE, or IN() operators:
index
index和ALL类似,但index出现在索引被扫描了的情况下,有两种情况:
- 如果索引是查询的一个覆盖索引,在这个情况下,只有索引文件会被扫描。
Extra字段中包含Using index。之所以只扫描索引是因为索引文件比整个表小,所以更快。 - 执行一个索引扫描,并按照索引顺序查找数据行。
Extra中没有Using index
当查询只使用属于单个索引的列时,MySQL可以使用该策略。
ALL
全表扫描。应该使用索引来避免出现ALL的情况。
EXPLAIN Extra Information
包含MySQL如何解析这次查询的额外信息。
只解释该列的一些常用的值
Using filesort
MySQL必须在获取全部数据后,为按照指定顺序获取结果来做额外的操作,这个操作并不一定是使用文件系统来进行排序,其实这个排序也可能在内存中完成,不过MySQL将它们统称为filesort。
也就是说要排序的列不能应用索引的有序性的情况。
Using index
只需要使用索引所带来的信息就能满足查询,而不需要去做额外的读取实际行的操作。
InnoDB表中的聚集索引不会显示Using index
Using index condition
MySQL5.6中为了ICP机制所添加,它是指在查找索引时就可以过滤掉那些不需要的行,而无需在服务器层再使用WHERE过滤。
Using temporary
想要解析这个查询,MySQL必须建立一些temp表。常见于GROUP BY和ORDER BY的时候。
Using where
服务器层通过WHERE子句来过滤哪些行要发送给下一个表或客户端。
Extra的一些示例
首先,Extra字段中可能包含多个值,比如Using index可以和Using where同时出现,因为两个值出现的条件被同时满足,这在MySQL5.6以下的版本中很常见。而且MySQL5.6之后,由于出现了很多针对索引的优化,所以很多以前性能低下的行为不会出现,所以经常会出现同一条语句在MySQL5.6和MySQL5.6以下返回的Extra字段不同。下面,我会使用8.0.29版本和5.5版本分别对同一条SQL进行解释,来揭示它们行为的不同。
Using where和Using index同时出现
下面是MySQL官方的示例数据库sakila中的actor表,这里last_name是一个非唯一索引,存储引擎是InnoDB。
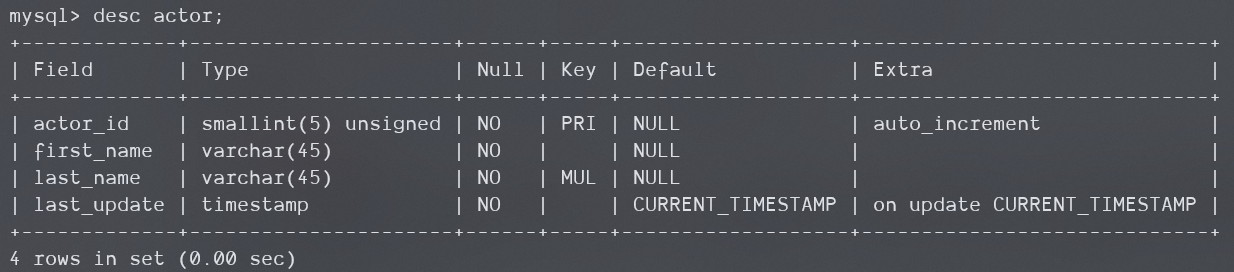
执行下面的语句:
EXPLAIN
SELECT actor_id, last_name FROM actor
WHERE last_name='GUINESS'\G;
请注意,这里我们使用了覆盖索引,所以Using index的条件一定能满足,结果中一定有Using index。下面是8.0.29中的结果:
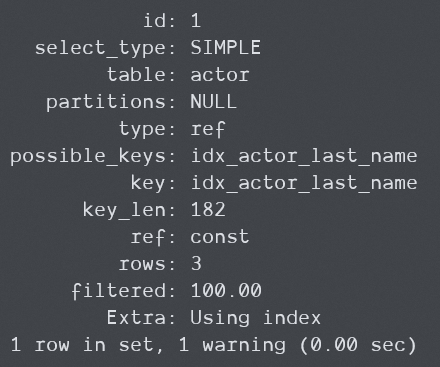
只有Using index,这证明该版本并没有使用WHERE在服务器层进行检查,直接应用了索引返回的值。
下面是5.5中的结果:
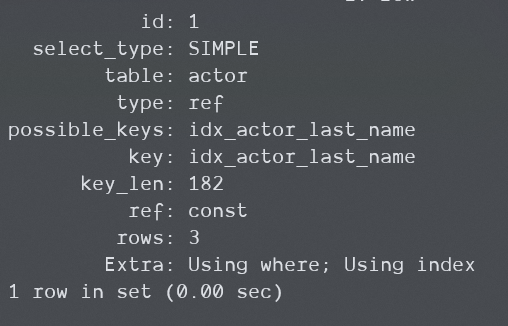
这证明,5.5中虽然使用覆盖索引,但还是会在应用层对WHERE条件进行校验,不过因为Using index的出现,所以没有回表查询,这条语句的性能也不会太差。
有的教程里说Using where出现就是需要回表查询,是性能低下的体现,如果只有单独一个Using where而没有Using index,这句话还比较靠谱,但是很容易让人误解。像上面那种情况,这时根本不用在意这个Using where的出现。
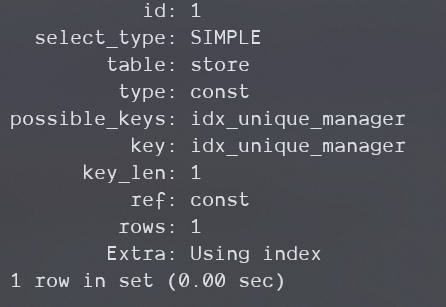
5.5版本在什么情况下会单独出现Using index
据我测试,你需要一个唯一索引,并且进行能够覆盖索引的等值查询。
这是sakila数据库中的另一个表,它有一个唯一非主索引。
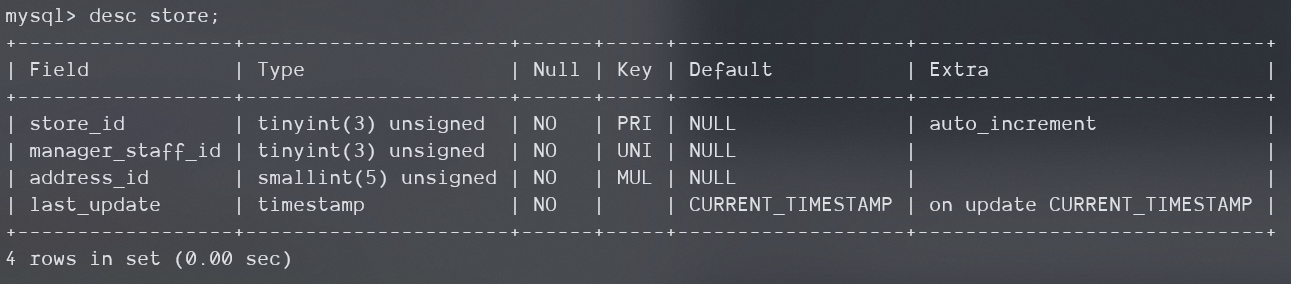
下面我们对它在5.5中进行覆盖等值查询
EXPLAIN
SELECT manager_staff_id, store_id
FROM store WHERE manager_staff_id = 1\G;
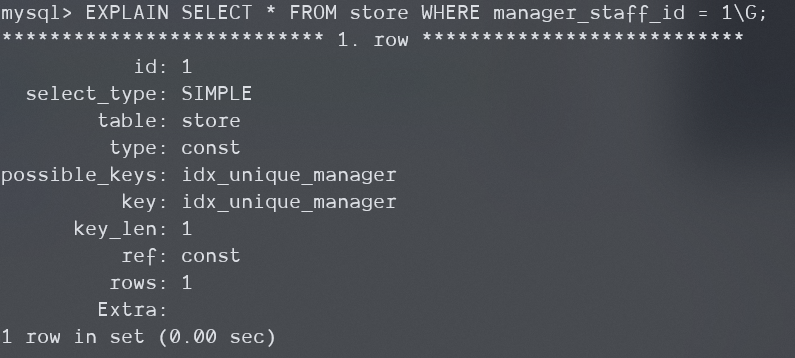
想象我们破坏掉上面的条件,会出现什么效果:
-
破坏索引覆盖性,让索引无法覆盖查询
首先,索引覆盖性被破坏,证明需要回表查询,Using index不会出现。
其次,等值查询没被破坏,所以Where条件并不需要在服务器层被使用,Using where不会出现。
综上所述,Extra为空
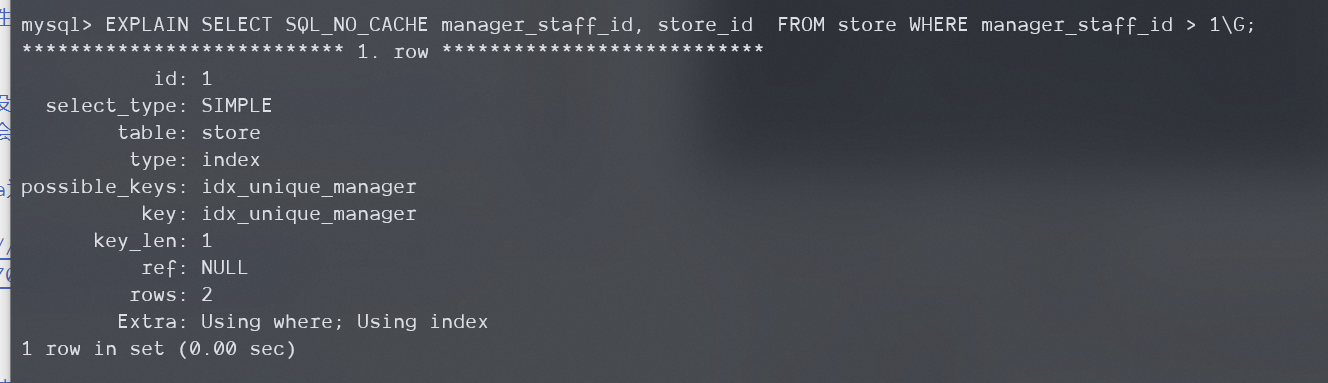
-
破坏等值查询
首先覆盖索引没被破坏,所以Using index会出现。
其次,等值查询被破坏了,MySQL5.6以下的服务器在这种情况下会对索引进行扫描,并且返回到服务器层应用WHERE条件。而在5.6及以上,这种情况会使用ICP。所以Extra字段在MySQL5.5中包含Using Where和Using index,在8.0.29中只出现Using index condition
下面是5.5的:
下面是8.0.29的,可惜我猜错了,8.0.29中也是Using where+Using index,这证明没有应用ICP机制,但是注意
type字段已经从index变成了range,这证明存储引擎层没有返回没用的数据让服务器层过滤,这比5.5中好了:
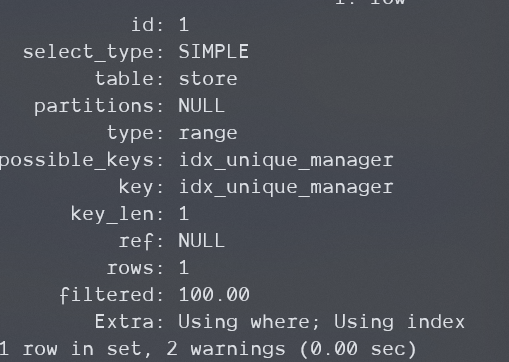
官方文档中有何时会应用ICP机制的列表,可以查看,另外提一嘴,上面没应用ICP是因为该扫描中存储引擎无需回原表
-
一同破坏覆盖性和等值查询
首先,Using index肯定没了,不管是什么版本,而5.5版本只会出现Using where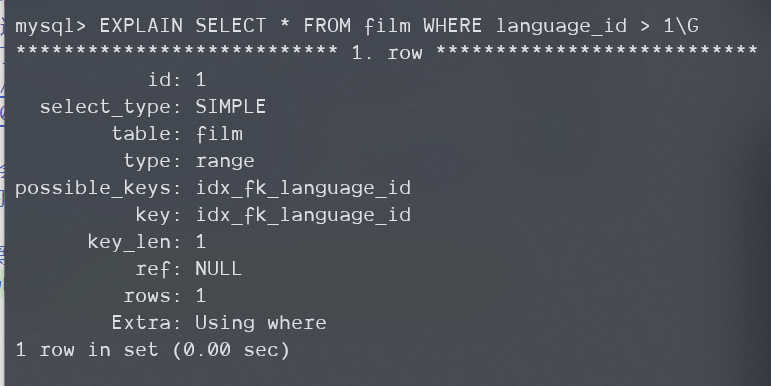
在8.0.29版本使用了ICP:
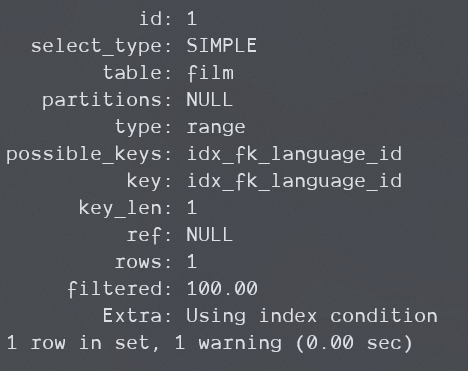
什么时候单独出现Using where
关键在于我们要构造一个查询,这个查询不能用到索引,并且让服务器应用WHERE条件,那很简单啊,在一个没索引的列上应用条件就好了啊。
下面这个查询无论在5.5还是8.0.29都会显示Using where.
EXPLAIN
SELECT * FROM actor WHERE first_name='SSSS'\G;
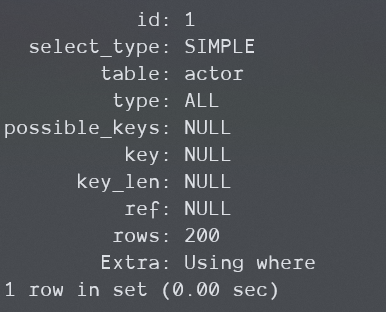
Using filesort
-
当你在没索引的列上排序
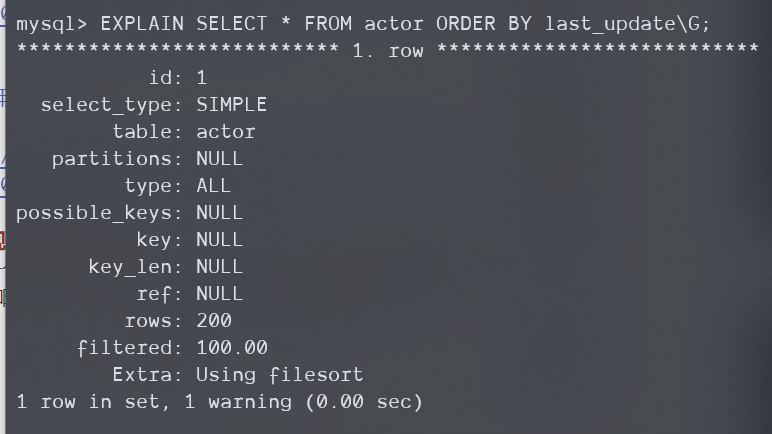
-
当你在有索引的列上排序,但是还是索引还是无法覆盖该查询,还要搜索原表来获取行,MySQL决定为了避免太多的随机IO而选择进行全表扫描时。当然这种情况下有时会进行MRR优化
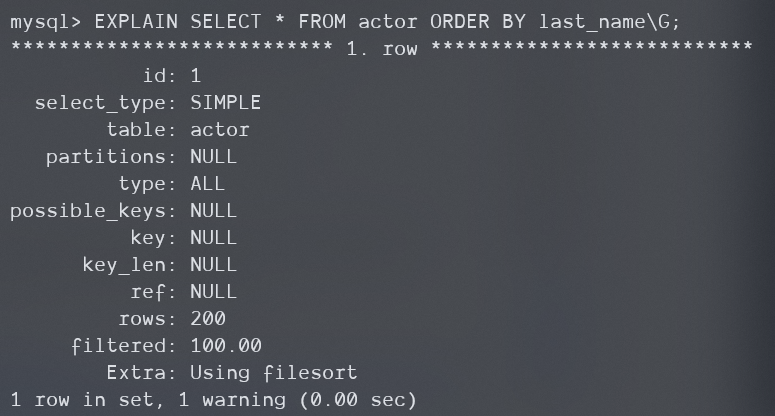
-
当你在没有索引的列上GroupBy时,该操作需要先进行排序
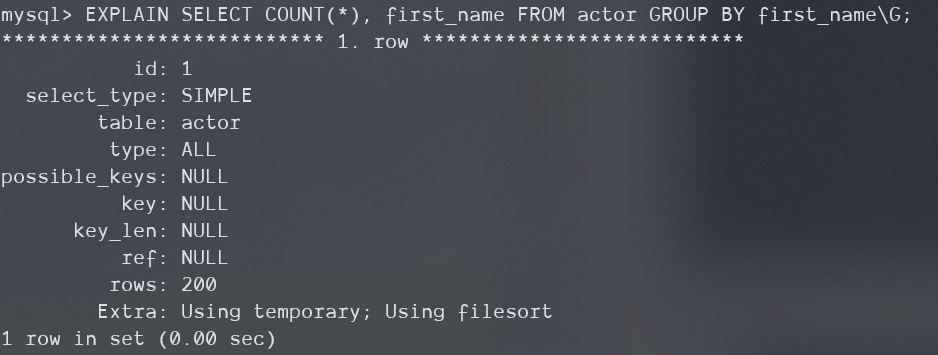

 浙公网安备 33010602011771号
浙公网安备 33010602011771号