MySQL ICP(索引条件推送)和延迟加载
什么是ICP(Index Condition Pushdown)
考虑下面的查询:
SELECT * FROM people
WHERE zipcode='95054'
AND lastname LIKE '%etrunia%'
AND address LIKE '%Main Street%';
假设表中有(zipcode, lastname, address)这个索引,但,对于BTree(或者B+Tree,下文统称BTree),它还是无法使用到lastname、address来进行快速检索,这是底层存储结构的限制,B+Tree只能匹配最左前缀,对于这种非前缀的模糊查询,它无能为力。
所以,在MySQL的早期版本中(5.6之前),它简单地选择只使用索引进行zipcode的等值匹配,存储引擎取出下一个匹配的索引元组,然后利用该元组取出整行数据,然后,服务器层再使用WHERE对这个整行数据进行过滤。这...无形中增加了MySQL服务器层与存储引擎层的数据交换,以及IO的读取次数。
考虑InnoDB工作的情景:
- InnoDB找到下一个匹配的索引元组,如
(95054, 432),95054是zipcode,432是主键 - InnoDB二次查找聚集索引,查找到主键是432的行,返回给MySQL服务器层
- 服务器对返回的整行应用WHERE条件进行匹配,如果匹配,添加到结果集中
对于那些索引本身就能覆盖WHERE条件中所有列的情况,上面的工作步骤无疑是有一些脱裤子放屁的嫌疑了,我们明明可以在索引中就完成WHERE匹配,这样第2步中的查找就没了,第3步中的服务器进行WHERE匹配也没了。
ICP技术在索引能够覆盖WHERE条件,并且查询需要去原表中fetch行的情况下,将条件下放到存储引擎层,在存储引擎层面提前过滤掉那些不需要的行。
相关文档:MySQL5.6 Reference Manual / 8.2.1.5 Index Condition Pushdown Optimization
究其原因就是在使用索引进行查询时,存储引擎没有足够的权力决定一个行(或者说索引项)是否被过滤掉,所有的权力都在MySQL服务器层的手中,它来应用WHERE条件。但服务器层又没有存储引擎了解谁该被过滤掉。下面看一个更扯的问题
当索引不能覆盖查询列时
存储引擎层没有权利过滤行(索引项)的另一个问题:
MySQL5.6版本之前的另一个限制是,虽然索引覆盖了WHERE条件中的所有列,但如果索引不能覆盖SELECT子句中的所有查询列时,尽管WHERE条件为假,该列还是要被存储引擎完整的拿出来,传到服务器层进行WHERE条件过滤。
我们使用Docker来测试,尽量找一个低版本的MySQL
docker pull mysql:5.5
docker run --name mysql55 -e MYSQL_ROOT_PASSWORD=root -d
mysql:5.5
docker exec -it mysql55 /bin/bash
mysql -uroot -proot
执行如下SQL:
CREATE DATABASE test;
USE test;
create table product(
id int primary key auto_increment,
name varchar(30) not null,
actor varchar(30) not null,
title varchar(30) not null,
key idx_actor_title(actor, title)
);
insert into product SELECT 1, 'NAME1', 'SEAN CARREY', 'M APOLLO X';
insert into product SELECT 2, 'NAME2', 'JOE', 'OOXXXXASDF';
insert into product SELECT 3, 'NAME3', 'SEAN CARREY', 'OOOXXX';
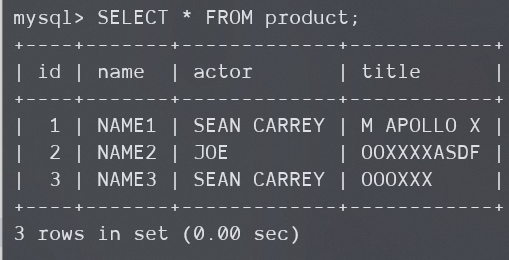
查看创建好的表
下面来查询:
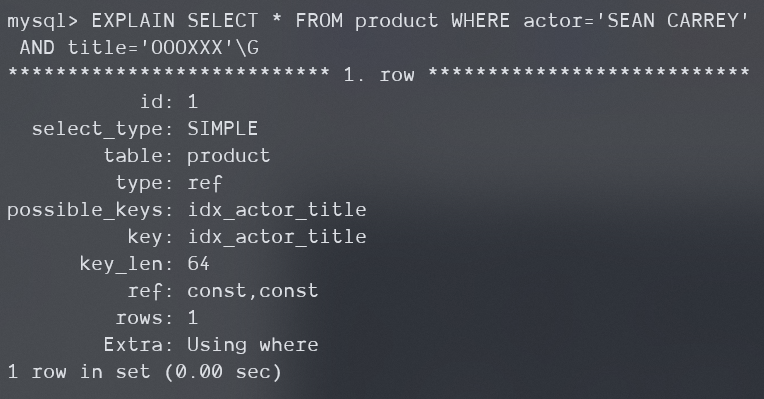
EXPLAIN SELECT * FROM product
WHERE actor='SEAN CARREY'
AND title like '%APOLLO%'\G;
首先,该查询一定是无法从索引中快速查找到需要的数据的,因为title列不符合最左前缀原则。这导致于它要对所有的actor='SEAN CARREY'的索引进行扫描。而结果中的Extra: Using where说明了服务器层将在存储引擎层返回行以后应用WHERE过滤条件。
这是就是因为如上面所说,SELECT * 中返回的列包含索引中无法覆盖到的列,所以该行被取出,传递给服务器层进行WHERE校验,这增加了服务器层到存储引擎层的传输开销。上面的加粗字体是问题的关键,既然MySQL这个憨批分析不出问题所在,选择了一条更加脱裤子放屁的执行路径,那么我们帮它选好该怎么执行好了,这就是延迟关联技术。
延迟关联技术
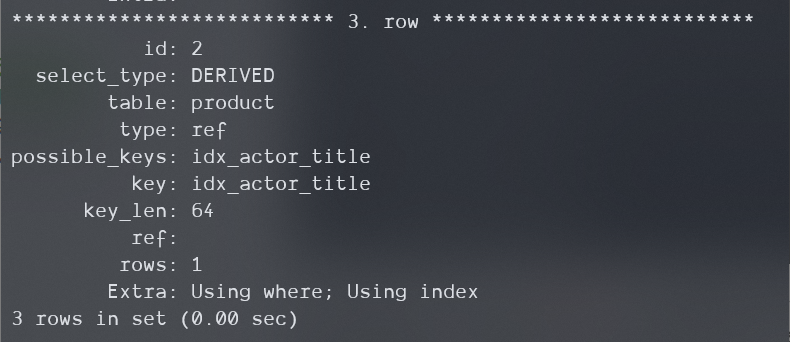
EXPLAIN SELECT * FROM product
JOIN(
SELECT id FROM product
WHERE actor='SEAN CARREY'
AND title='OOOXXX'
) AS t1 ON (t1.id=product.id)\G;
上面的代码的关键部分在于内查询,(actor, title)这个索引在InnoDB存储引擎中完全可以覆盖(actor, title, id)这三个列,这样,服务器便知道它无需对每一行再次进行WHERE校验,索引完全可以完成工作,这样存储引擎就无需将那些不需要的整行传递给服务器了。然后到了外层,外层再对所有内层取出的ID进行匹配查询,这里也可以用IN。
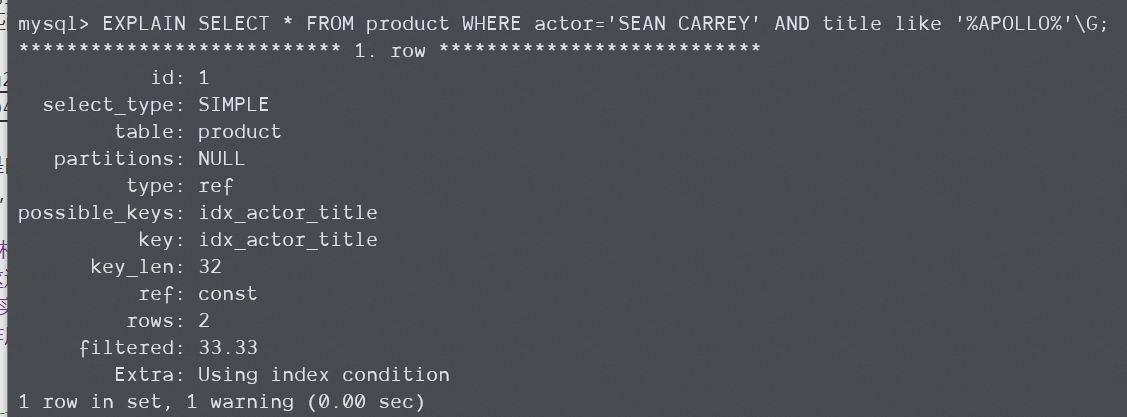
这个问题究其根本也是由于MySQL不能把查询字段下放到存储引擎层面而带来的,所以只要有了ICP,它也就被解决了。下面是高版本MySQL执行同样的查询时的结果,直接使用了ICP在存储引擎层过滤掉不需要的数据。
之所以再次记录ICP相关的笔记,是因为昨天尝试再看《高性能MySQL》时,在延迟关联技术这遇到了一些看着似懂非懂的地方,今早我才发现,原来我一直没把ICP优化的实际目的搞清楚。上面了解了ICP的目的,下面很容易就将延迟关联技术的作用搞懂了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号