GoF设计模式——行为型设计模式
职责链模式(Chain Of Responsibility)
如果你的类为了实现某种功能,需要调用一批组件中的一个(或多个),并且它不知道在什么情况下调用什么组件,这时不妨让组件串成一个链,链中的每个组件按顺序自己检测自己能否提供这个功能,这就是职责链模式。
动机
Web服务器往往提供某种对请求进行拦截、检查、处理的机制,Web服务器往往提供一种名为Filter或Interceptor组件来实现拦截。但Web服务器设计之初,并不知道在什么情况下使用哪个Filter进行拦截,这是特定于你的业务需求的,这种代码不可能内化在Web服务器的逻辑中。
Servlet API中的Filter就是用来将Web服务器和具体拦截逻辑解耦的组件,多个Filter组成一个链,对于每一个到来的请求,Web服务器只需要将请求送到Filter链上,每一个Filter自己检测对于该请求是否拦截、拦截后做什么、是否让请求在Filter中继续向后传播。
如果你的类为了实现某种功能,需要调用一批组件中的一个(或多个),并且它不知道在什么情况下调用什么组件,这时不妨让组件串成一个链,链中的每个组件按顺序自己检测自己能否提供这个功能,这就是职责链模式。职责链模式的主要优点在于,解耦了功能的调用者和提供者。
适用性
- 有多个的对象可以处理一个请求,哪个对象处理该请求运行时刻自动确定。
- 你想在不明确指定接收者的情况下,向多个对象中的一个提交一个请求。
- 可处理一个请求的对象集合应被动态指定。
结构
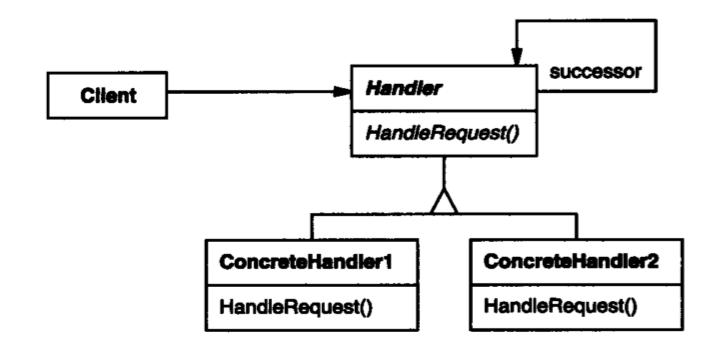
参与者
Handler:用于处理请求的组件的接口,代表职责链中的一个处理单元。ConcreteHandler:具体的处理组件。- 可以访问后继处理器
- 需要能够判断自己是否能处理请求
- 在能处理请求并已经处理的情况下,它可以自己决定是否将请求传递给后继处理器
Client:职责链的调用者,它接收请求,发送给职责链,它无需知道谁会实际处理请求
命令模式(Command)
当一个需要被复用的组件在某些时刻需要做一些事,但它不知道要做的事的任何细节,可以使用命令模式,将这些要做的事抽象成命令,由系统中的其它部分来实现,组件只发送一个请求到这个命令即可。
动机
考虑一个GUI程序的菜单栏。
你使用的GUI库将每一个菜单栏上的项目抽象为一个MenuItem,GUI库肯定不知道MenuItem被选中时应该做什么操作,这是特定的应用来决定的,而你的应用又不知道MenuItem什么时候被选中,这是GUI库才知道的。
GUI库可以提供一种Command接口,它代GUI库中某些事件触发(比如按钮按下、菜单项被选中)时该执行什么操作,GUI库的使用者来创建实现Command接口的类并传递给GUI组件。
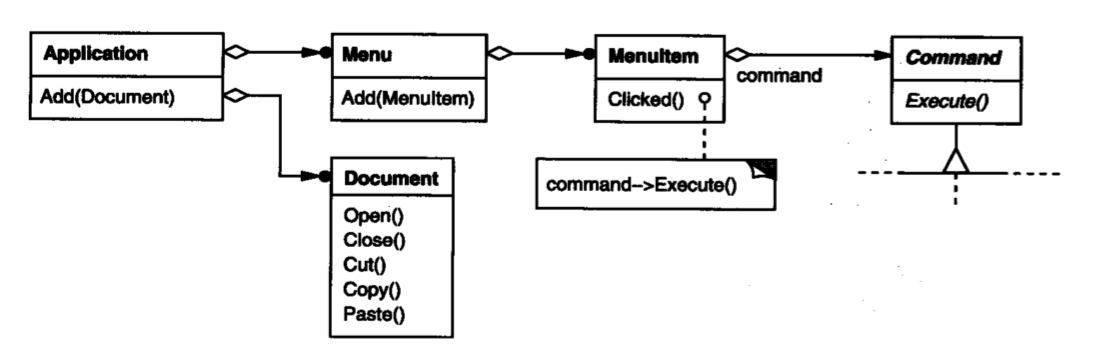
如下图,GUI组件MenuItem持有一个我们创建的Command,在它被点击时,MenuItem会调用我们的Command的Execute方法,来执行我们期望的命令。
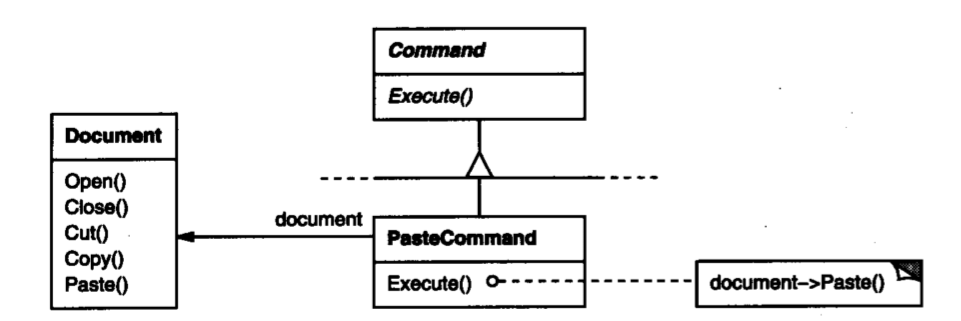
Command可以持有应用中的任何用于实现功能的组件,比如下面的PasteCommand,它的功能是将剪贴板上的内容粘贴到文档中,所以它必须持有Document组件。
下面的图片比较有意思,某些MenuItem被点击后需要执行的命令可能比较复杂,可以由多个Command对象复合而成,我们完全可以建立一个MacroCommand,它持有多个Command对象,并顺序执行它们,这是不是结构型设计模式中的“组合模式”?
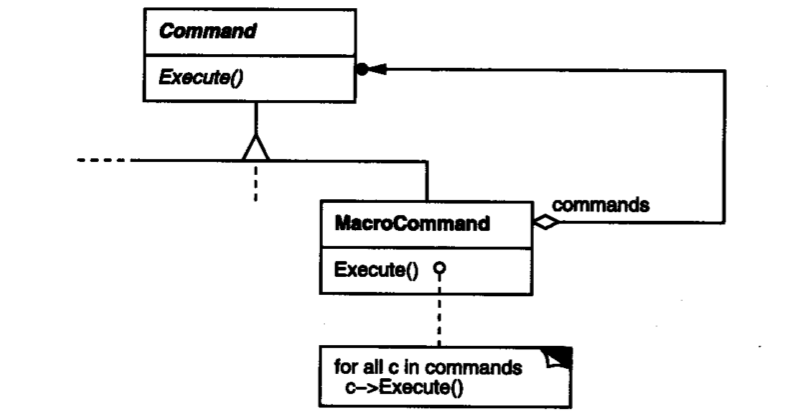
其实上面的图片向我们揭示了命令模式的另一个好处,即将要执行的操作抽象成命令,我们可以在任何需要它的地方复用它。
考虑下,AWT、Swing和Android开发中哪里用到了命令模式呢?有很多地方哦
当一个需要被复用的组件在某些时刻需要做一些事,但它不知道要做的事的任何细节,可以使用命令模式,将这些要做的事抽象成命令,由系统中的其它部分来实现,组件只发送一个请求到这个命令即可。
适用性
- 像上面讨论的MenuItem对象那样,抽象出待执行的动作以参数化某对象。
- 在不同的时刻指定、排列和执行请求。
- 支持取消操作。
- Command可以在执行操作前记录下当前状态,并提供
UnExecute方法,恢复到之前的状态 - 支持修改日志,这样当系统崩溃时,这些修改可以被重做一遍。
结构
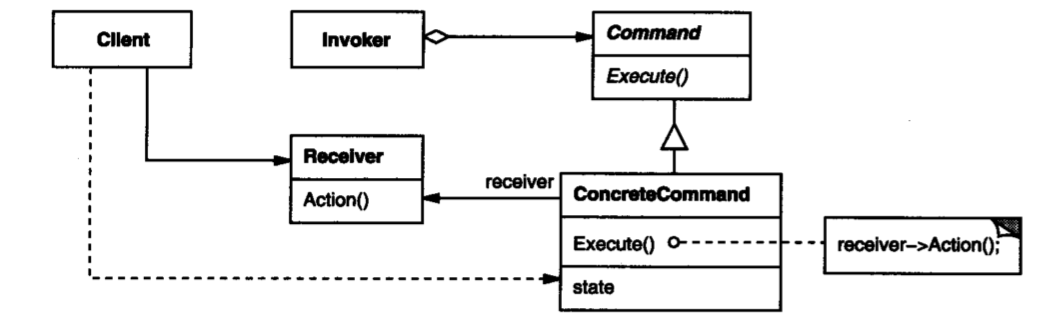
参与者
在此部分,给出该设计模式中的关键组件,为了便于练习,我不会将这里所述的组件与上面示例中的组件一一对应,你需要自己思考并对号入座。如果不确定,再往下一点就是答案。
Command:命令接口- 声明执行操作的方法
- 定义是否支持取消
- 定义是否进行持久化
ConcreteCommand:具体的命令实现Invoker:Command的调用者Receiver:被Command所持有,是执行Command中操作必要组件,也可以看作操作的最终接收者Client:负责创建命令,给命令设定接收者和调用者
Command: Command
ConcreteCommand: PasteCommand、MarcoCommand
Invoker: MenuItem
Receiver: Document
Client: Application
解释器模式(Interpreter)
所以,解释器模式就是把对象组织成一颗抽象语法树,每一个节点都有一个
interpret方法来对自己进行解释,你只需要调用根节点的interpret就能递归解释整个语法树。
准备一下,这可能是这个系列里篇幅最长且唯一一个有具体用例代码的设计模式。
动机
解释器模式用于对一种语法进行解释执行。在这一节,我将使用Java语言完善书中只给出了定义的简单正则表达式解释器以展示解释器模式的用法。
考虑如下定义的一种简单正则表达式:
expression ::= literal | alternation | sequence | repetition | '(' expression ')'
alternation ::= expression '|' expression
sequence ::= expression '&' expression
repetition ::= expression '*'
literal ::= 任意普通字符
expression:正则表达式,可以是或关系表达式,与关系表达式,重复任意次表达式,字面量表达式或者带括号的表达式alternation:或关系正则表达式,由|隔开的两个子表达式嵌套而成,两个子表达式中有一个匹配成功即可sequence:与关系表达式(原书中并没说明该表达式的作用,作者的原意应该不是与关系,但我把它当成与关系了),由&隔开的两个子表达式嵌套而成,两个子表达式必须同时匹配成功repetition:重复任意次表达式,由一个被*跟随的子表达式组成,子表达式匹配0次到任意多次literal:字面量表达式,是由任意普通字符组成的,要求和待匹配字符完全一对一匹配。
下面是我们最终设计的正则表达式解释器的一个用例:
123 & (123 | 456) *
它匹配以123或456组成的序列1到任意多次,其中开头必须是123。
转换成我们上面的定义,就是如下结构:
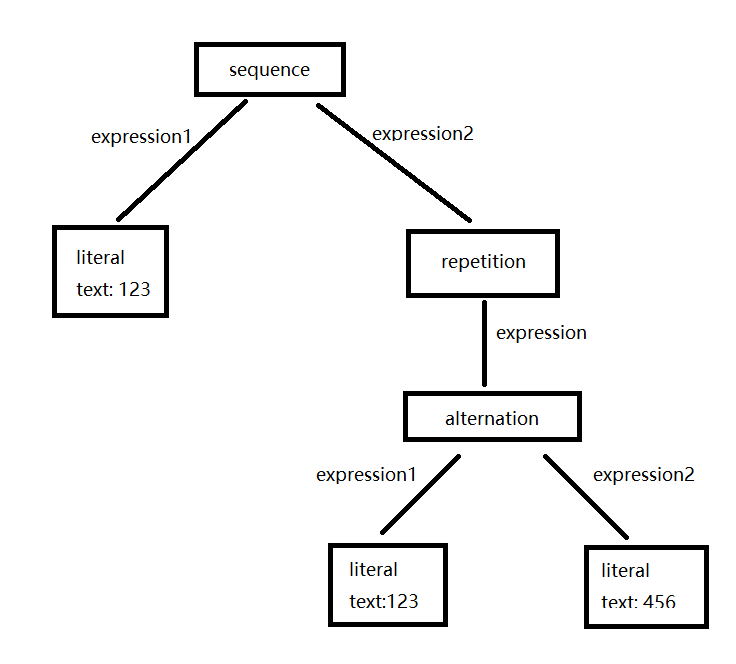
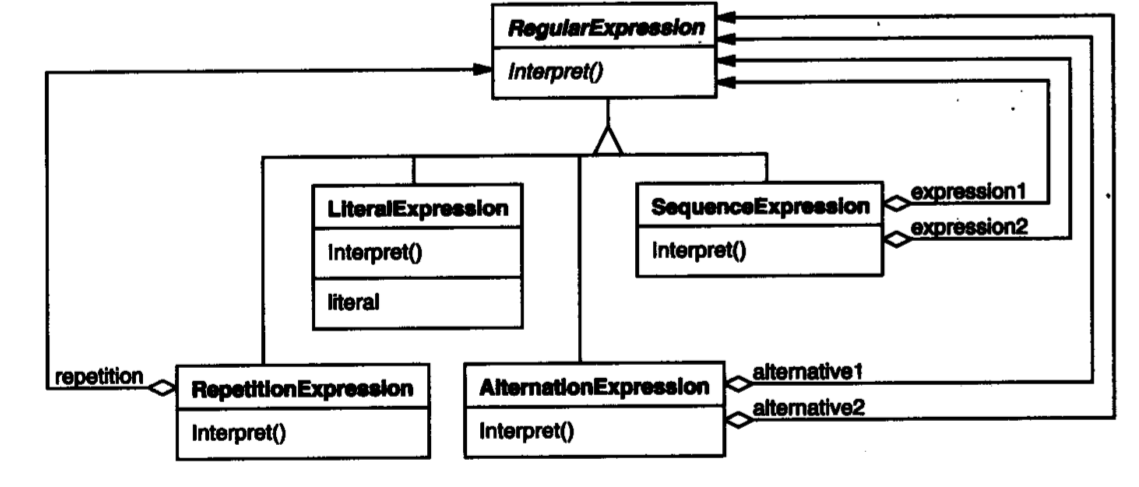
在Java中,我们可以利用解释器模式建立如下的类与之对应
所以,解释器模式就是把对象组织成一颗抽象语法树,每一个节点都有一个interpret方法来对自己进行解释,你只需要调用根节点的interpret就能递归解释整个语法树。
代码
下面给出正则表达式解释器的Java实现,不确定它是否在所有状态下工作正常,大家只需要学习其中的设计思想即可:
public abstract class RegularExpression {
/**
* 外界使用正则表达式都是用来匹配字符串,这时虽然`interpret`也能完成工作,但是从语义上会让调用者产生疑惑,调用者不知道解释是什么意思以及MatchContext如何构造
* @param input 待匹配字符
* @return 是否匹配
*/
public boolean match(String input) {
MatchContext context = new MatchContext(input);
return interpret(context) && context.atEOL();
}
/**
* interpret方法用来评估表达式是否与用户输入匹配,一个`MatchContext`在表达式AST之间传递
* `MatchContext`中记录了用户输入和当前位置,`interpret`有责任在它匹配失败的情况下将`MatchContext`中的位置复原
* 在非叶子Expression中,可能需要调用其它子Expression的`interpret`,请记住子Expression在失败时不会对位置产生副作用。
*
* @param context 匹配上下文
* @return 是否匹配
*/
protected abstract boolean interpret(MatchContext context);
}
我们可以看到interpret方法是包可见的,这意味着我们对解释器的调用者隐藏了interpret方法,因为用户调用正则表达式工具是需要对字符串进行匹配,而“解释”这个词会让用户摸不到头脑。
同时,interpret方法具有一个MatchContext类型的参数,这个参数是匹配上下文,它贯穿整个语法树,目的就是在语法树中的组件进行解释时共享一些公有状态,比如MatchContext中保存了待匹配字符串和当前匹配到的字符串位置。一般的解释器模式中都会有这么一个上下文。
/**
* 普通字面量,当用户输入和字面量完全一致时匹配
*/
public class LiteralExpression extends RegularExpression {
private char[] literal;
public LiteralExpression(String literal) {
this.literal = literal.toCharArray();
}
@Override
public boolean interpret(MatchContext context) {
// 记录旧位置
int oldPosition = context.getPosition();
for (int i=0; i < literal.length; i++) {
if (literal[i] != context.currentChar()) {
// 在匹配失败时,恢复旧位置
context.setPosition(oldPosition);
return false;
}
// 跳到下一个字符
context.skip();
}
return true;
}
}
上面是理解起来最简单但写起来最复杂的LiteralExpression,它所做的就是一个一个的将用户输入字符和正则表达式字面量进行匹配。
/**
* expression & expression
* 当两个expression都匹配时匹配
*/
public class SequenceExpression extends RegularExpression {
private RegularExpression expression1;
private RegularExpression expression2;
public SequenceExpression(RegularExpression expression1, RegularExpression expression2) {
this.expression1 = expression1;
this.expression2 = expression2;
}
@Override
public boolean interpret(MatchContext context) {
int oldPos = context.getPosition();
// 如果第一个表达式匹配失败,整个匹配宣告失败
// 这里不用进行位置恢复,因为`expression1`失败的时候已经恢复了位置,这是在`RegularExpression`类中定义的规约
if (!expression1.interpret(context)){
return false;
}
// 第一个匹配成功,恢复老位置,并且开始匹配第二个
context.setPosition(oldPos);
if (!expression2.interpret(context)) {
return false;
}
return true;
}
}
SequenceExpression维护两个子expression,分别调用interpret方法,并根据它们的返回状态决定自己的返回状态。
此时此刻,我突然明白了书中的
SequenceExpression的含义,因为树上的简单正则表达式定义并不能处理两个连续的正则表达式,比如123*456,我们能够一眼看出来这是先匹配1230到多次,再匹配456,但这个表达式在定义中却是没有定义的。所以&的目的是用来连接两个正则表达式,所以叫“序列表达式”。而且作者使用&符号来标识序列表达式也很巧妙,因为这种序列关系正是与关系,它们是等价的,所以我们的代码也不用改。
/**
* expression | expression
*
* 当两个表达式中有一个匹配即匹配
*/
public class AlternationExpression extends RegularExpression {
private RegularExpression expression1;
private RegularExpression expression2;
public AlternationExpression(RegularExpression expression1, RegularExpression expression2) {
this.expression1 = expression1;
this.expression2 = expression2;
}
@Override
public boolean interpret(MatchContext context) {
int oldPosition = context.getPosition();
if (expression1.interpret(context)) return true;
context.setPosition(oldPosition);
if (expression2.interpret(context)) return true;
context.setPosition(oldPosition);
return false;
}
}
和与关系差不多,不多说。
/**
* expression*
* 当expression匹配用户输入0次到1次时匹配成功,该表达式是永真式
*/
public class RepetitionExpression extends RegularExpression {
private RegularExpression expression;
public RepetitionExpression(RegularExpression expression) {
this.expression = expression;
}
@Override
public boolean interpret(MatchContext context) {
// match the input 0 to n times
while (expression.interpret(context) && !context.atEOL()) {}
return true;
}
}
重复表达式的实现很简单,匹配0次到任意次的定义导致它是一个永真式,所以我们无需维护什么状态,无需考虑返回值。while循环尽可能多的调用子表达式来匹配用户输入,并且它还需要一个额外的判断,如果当前匹配已经到了行末尾,就无需再匹配了。
你无需考虑第n次失败后的位置状态恢复,和之前一样,这是子表达式要考虑的,方法返回时,位置处于最后一次匹配成功的下一个字符的位置。
public class MatchContext {
private int position;
private final char[] input;
public MatchContext(String input) {
this(0, input.toCharArray());
}
private MatchContext(int position, char[] input) {
this.position = position;
this.input = input;
}
public void setPosition(int position) {
if (position < 0 || position >= input.length)
throw new IndexOutOfBoundsException("position cannot bigger than input length.");
this.position = position;
}
public int getPosition() {
return position;
}
public char currentChar() {
return input[position];
}
public boolean atEOL() {
return position == input.length;
}
public void skip() {
skip(1);
}
public void skip(int n) {
this.position += n;
}
}
上面是MatchContext的实现,下面就是重头戏,我们通过构建语法树来构建一个特定的正则表达式,并对字符串进行匹配:
public class Client {
public static void main(String[] args) {
RegularExpression regularExpression = new SequenceExpression(
new LiteralExpression("123"),
new RepetitionExpression(
new AlternationExpression(
new LiteralExpression("123"),
new LiteralExpression("456")
)
)
);
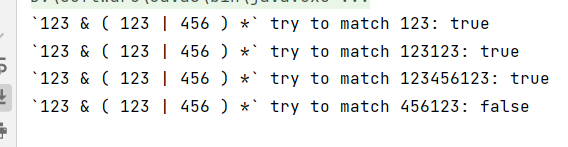
System.out.println("`123 & ( 123 | 456 ) *` try to match 123: " + regularExpression.match("123")); // true
System.out.println("`123 & ( 123 | 456 ) *` try to match 123123: " + regularExpression.match("123123")); // true
System.out.println("`123 & ( 123 | 456 ) *` try to match 123456123: " + regularExpression.match("123456123")); // true
System.out.println("`123 & ( 123 | 456 ) *` try to match 456123: " + regularExpression.match("456123")); // false
}
}
结果:
适用性
- 当有一个语言需要解释执行 , 并且你可将该语言中的句子表示为一个抽象语法树时,可使用解释器模式。
- 文法相对简单,便于构建抽象语法树,并且解释效率不是特别重要时
结构
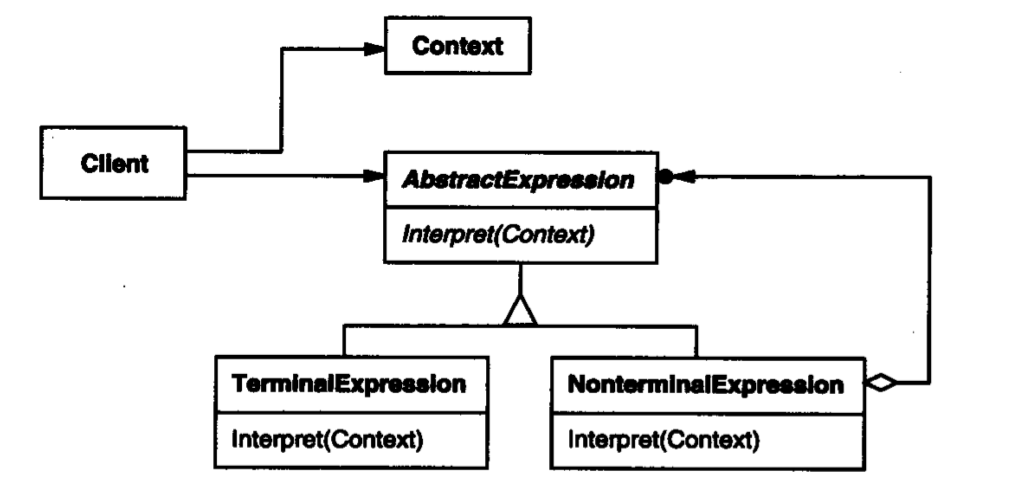
参与者
在此部分,给出该设计模式中的关键组件,为了便于练习,我不会将这里所述的组件与上面示例中的组件一一对应,你需要自己思考并对号入座。如果不确定,再往下一点就是答案。
Client:构建解释器语法树并使用解释功能的客户端Context:在解释器语法树间传递的上下文AbstractExpression:抽象语法,规定语法树种所有具体的组件的行为TerminalExpression:终端语法组件,它代表抽象语法树的叶子节点,叶子节点必须自己解释自己NonterminalExpression:非终端语法组件,它代表抽象语法树的中间节点,中间节点可以利用子节点来递归解释自己
Client: Client
Context: MatchContext
AbstractExpression: RegularExpression
TerminalExpression: LiteralExpression
NonterminalExpression: SequenceExpression, AlternationExpression, RepetitionExpression
迭代器模式(Iterator)
迭代器模式的思路是把遍历操作和聚合结构解耦,创建一种专门用于遍历聚合结构的对象,这种对象就是迭代器。
动机
遍历聚合结构是我们经常会做的操作,如果在聚合结构中提供用于遍历的方法,我们就很难针对不同的遍历需求来扩展。比如你想提供普通的顺序遍历、逆序遍历、带过滤的遍历...这些都要重新修改聚合结构以提供新的API。
迭代器模式的思路是把遍历操作和聚合结构解耦,创建一种专门用于遍历聚合结构的对象,这种对象就是迭代器。如下图是一个列表的迭代器:
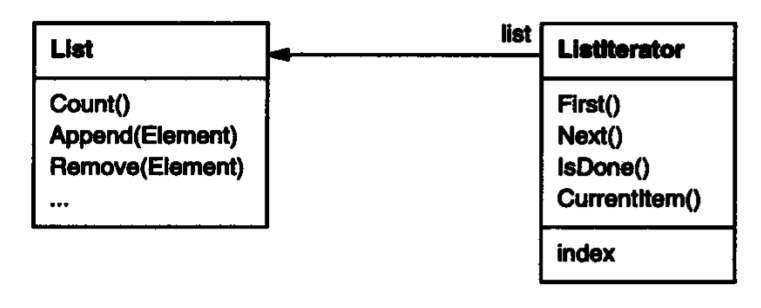
按照上面的实现方式,聚合结构和迭代器之间是耦合的,用户必须知道,对于List,需要使用ListIterator来遍历,对于SkipList要使用SkipList来遍历。
将聚合结构和迭代器抽象化可以解决这个问题:
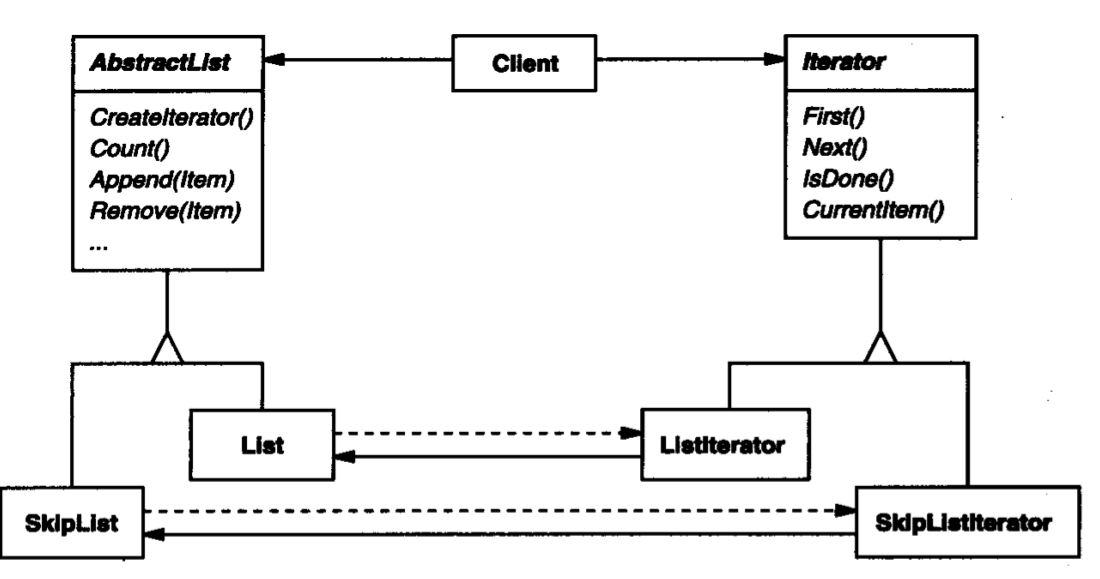
此时,Iterator接口屏蔽了迭代器之间的差异,AbstractList接口屏蔽了聚合类之间的差异,AbstractList.createIterator方法让具体的聚合类创建属于它自己的Iterator,这使得用户无需知道聚合结构需要绑定到一个什么样的迭代器上,无论遍历什么聚合结构,用户只需要知道需要它只是在使用一个Iterator对象即可。
适用性
- 访问一个聚合对象的内容而无需暴露它的内部表示。
- 支持对聚合对象的多种遍历。
- 为遍历不同的聚合结构提供一个统一的接口
结构
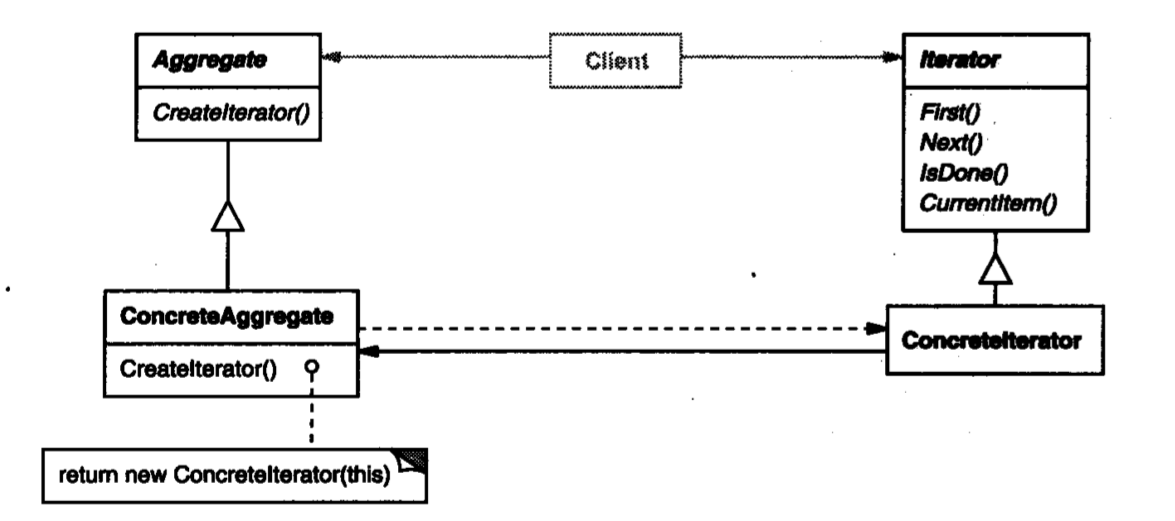
Java中的创建迭代器方法不和聚合类绑定,而是和
Iterable(可迭代对象)绑定,更加灵活。
参与者
在此部分,给出该设计模式中的关键组件,为了便于练习,我不会将这里所述的组件与上面示例中的组件一一对应,你需要自己思考并对号入座。如果不确定,再往下一点就是答案。
Aggregate:聚合类接口,用于声明聚合类的公共API,它的一个职责是声明创建迭代器的方法ConcreteAggregate:具体的聚合类实现类,它需要实现创建迭代器的方法,将自己绑定到一个用于遍历自己的迭代器上。Iterator:迭代器接口,用于声明迭代器的公共API,向用户屏蔽不同聚合类之间迭代器的差异ConcreteIterator:具体的迭代器,对具体聚合类进行迭代
Aggregate: AbstractList
ConcreteAggregate: List, SkipList
Iterator: Iterator
ConcreteIterator: ListIterator, SkipListIterator
中介者模式(Mediator)
所以,中介者模式在依赖关系复杂的组件之间提供中间层,使得依赖关系被转移到中介者身上,组件无需了解这些依赖关系,从而实现组件间解耦。
动机
考虑如下的对话框。
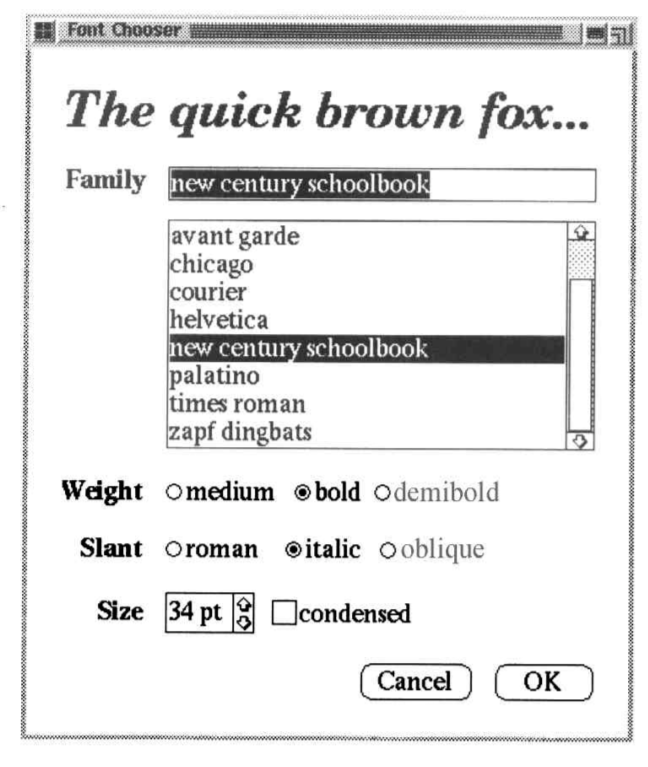
对话框用于显示一个窗口,窗口中的组件间可能有复杂的依赖关系,比如在列表中选择某个字体后,Family输入框中的内容会改变;再比如选择某种字体后,根据该字体安装的版本,字重Weight和斜体中的部分单选按钮可能呈现不可用状态(当选中字体没有安装对应的粗体或斜体版本)。
如果将这些依赖关系内化到UI组件中,UI组件将很难得到复用。Mediator模式在UI组件之间建立了一个媒介,当UI组件的状态改变,UI组件通知Mediator,然后Mediator接到通知后,再去修改跟随该状态产生变化的组件,这样,组件之间就无需了解对应的依赖关系了。如下图:
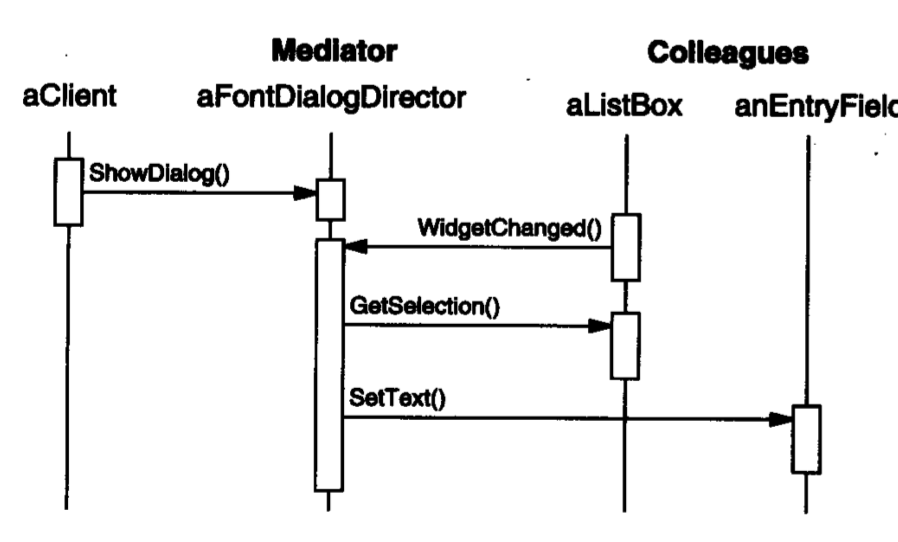
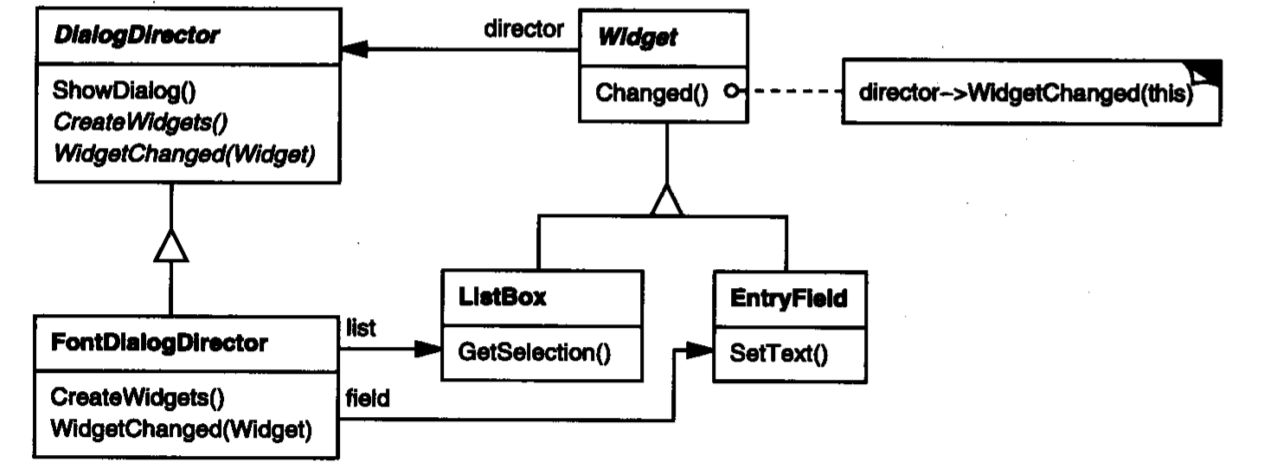
在该图中,客户端直接调用Mediator展示对话框,当列表状态发生变化,也就是项目被选中时,列表通知Mediator,然后Mediator获取列表的选中状态,设置输入框中的文字。下面是UML图:
所以,中介者模式在依赖关系复杂的组件之间提供中间层,使得依赖关系被转移到中介者身上,组件无需了解这些依赖关系,从而实现组件间解耦。
适用性
- 一组对象以定义良好但是复杂的方式进行通信。产生的相互依赖关系结构混乱且难以理解。
- 一个对象引用其他很多对象并且直接与这些对象通信 ,导致难以复用该对象。
- 想定制一个分布在多个类中的行为,而又不想生成太多的子类。
结构
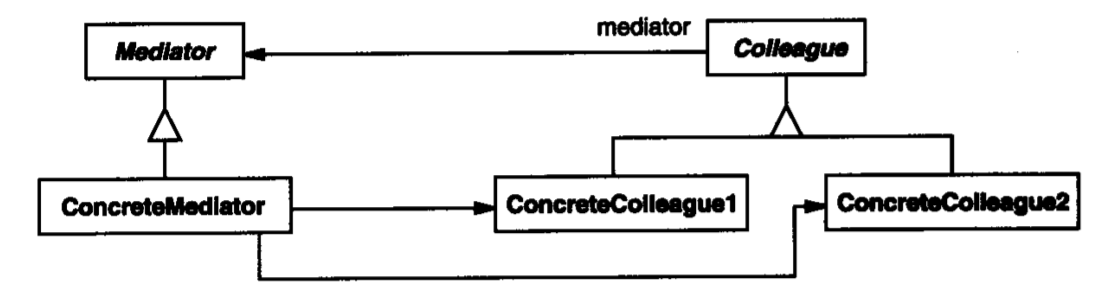
参与者
在此部分,给出该设计模式中的关键组件,为了便于练习,我不会将这里所述的组件与上面示例中的组件一一对应,你需要自己思考并对号入座。如果不确定,再往下一点就是答案。
Mediator:媒介接口,用于定义媒介的基本行为,提供接收组件状态改变的方法ConcreteMediator:具体媒介实现类- 它持有所有参与到依赖关系中的同事(组件)
- 它需要满足同事间的依赖关系,即在接收到某一个同事状态改变时更新依赖它的同事
- 同事之间通过它通信
Colleague:同事接口,它持有媒介,在状态改变时调用媒介的通知方法ConcreteColleague:具体同事实现- 每一个同事在自己状态改变时通知媒介
- 媒介会在当前同事依赖的同事状态改变时通知当前同事
Mediator: DialogDirector
ConcreteMediator: FontDialogDirector
Colleague: Widget
ConcreteColleague: ListBox, EntryField
备忘录模式(Memento)
用于存储一个对象在一瞬间的内部状态,可在稍后用于状态恢复。
动机
用于存储一个对象在一瞬间的内部状态,可在稍后用于状态恢复。被存储的对象称为原发器(Originator),备忘录(Memento)代表被存储的顺时状态,只有原发器能操作(创建,设置,读取)备忘录,备忘录对其它对象不可见。
还有一个组件是Caretaker,它是备忘录的实际保存者,比如撤销机制可能保存了一堆创建好的Memento,每个Memento都是一个Originator在一瞬间的状态。
结构
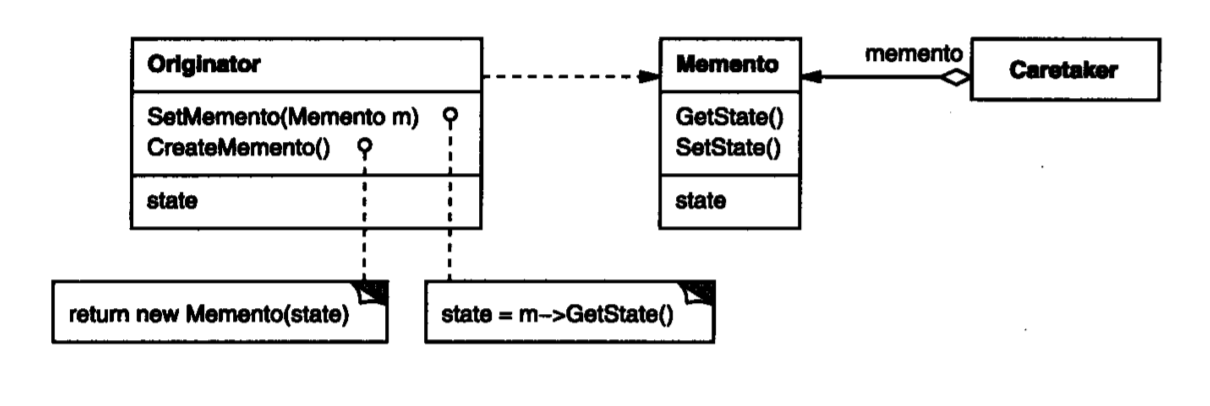
观察者模式(Observer)
观察者模式让一个状态对象和所有依赖这些状态对象的对象之间解耦,它们不需要知道彼此的存在就可以互相沟通,通知/接收状态变更。
动机
如下图,三个图表都依赖同一份数据对象,一个能想到的办法是在这个数据对象中保存这三个图表窗口组件的引用,然后数据更新时分别通知它们。
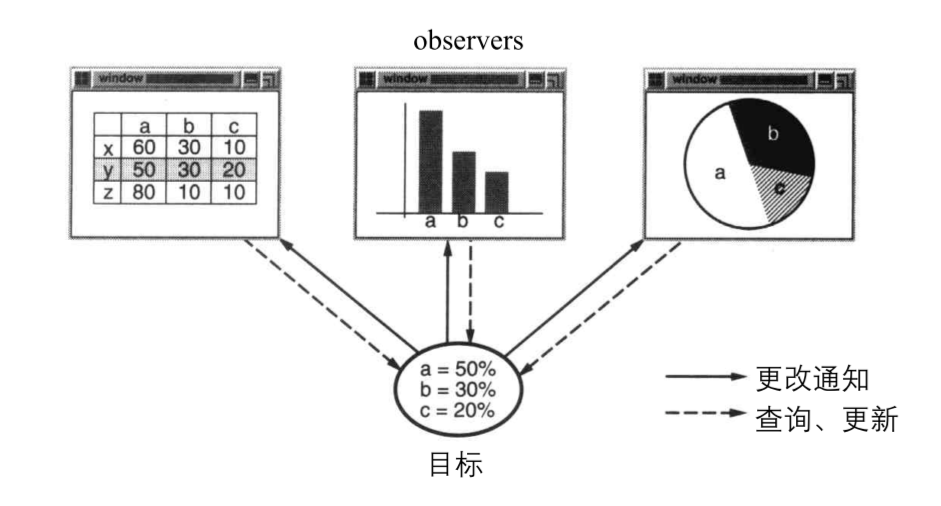
上面说的办法让这个数据对象和图标窗口组件紧耦合,数据对象知道三个图表的存在,它们变得不可复用。不如让这份数据对象提供一种发布/订阅机制。它可以注册任意多个观察者,当它的状态改变时,它通知这些观察者,这些观察者发现状态改变再来查询新的数据。
观察者模式让一个状态对象和所有依赖这些状态对象的对象之间解耦,它们不需要知道彼此的存在就可以互相沟通,通知/接收状态变更。
适用性
- 当一个抽象模型有两个方面 , 其中一个方面依赖于另一方面。将这二者封装在独立的对象中以使它们可以各自独立地改变和复用。
- 当对一个对象的改变需要同时改变其它对象 , 而不知道具体有多少对象有待改变
- 当一个对象必须通知其它对象,而它又不能假定其它对象是谁。换言之 , 你不希望这些对象是紧密耦合的。
结构
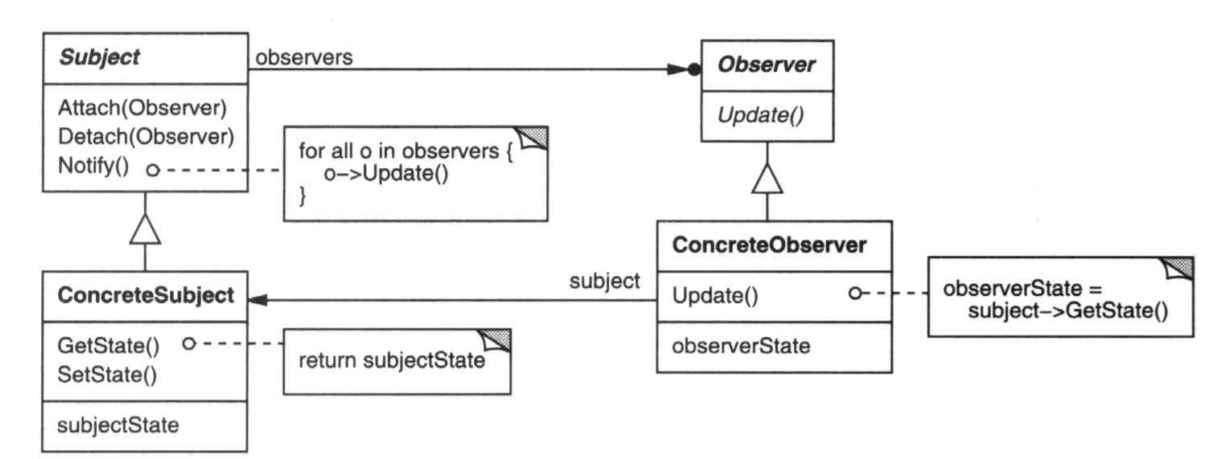
参与者
Subject:主体接口,代表一个被观察的对象- 它需要维护添加观察者,移除观察者的功能
- 它需要在内部状态改变时通知所有观察者
ConcreteSubject:主体接口的一个实现,代表实际被观察的对象Observer:观察者- 它需要有一个方法来给
Subject调用,接收Subject状态改变的通知
- 它需要有一个方法来给
ConcreteSubject:具体观察者- 需要在接到状态改变的通知时重新获取主体状态
观察者模式像不像一对多的命令模式。好吧我承认在本书的例子中不太像,思考一个组件库的选择框组件的
OnStateChangeListener显然是命令模式,那么如果有一种控件提供了addOnStateChangeListener来添加多个选择状态改变事件,并在控件的选择状态改变时调用所有添加进来的监听器,那么这不就是观察者模式吗,被观察的状态是控件的选择状态。选择框就是Subject,所有StateChangeListener是Observer。
状态模式(State)
一个具有不同状态的对象,它的行为根据状态不同有不同的表现。此时可以建立状态接口,为每个状态建立实现类,并让该对象委托每个状态的实现类来实现行为。
动机
一个具有不同状态的对象,它的行为根据状态不同有不同的表现。此时可以建立状态接口,为每个状态建立实现类,并让该对象委托每个状态的实现类来实现行为。下面是一个具有不同连接状态的TCPConnection对象使用State模式的实现。
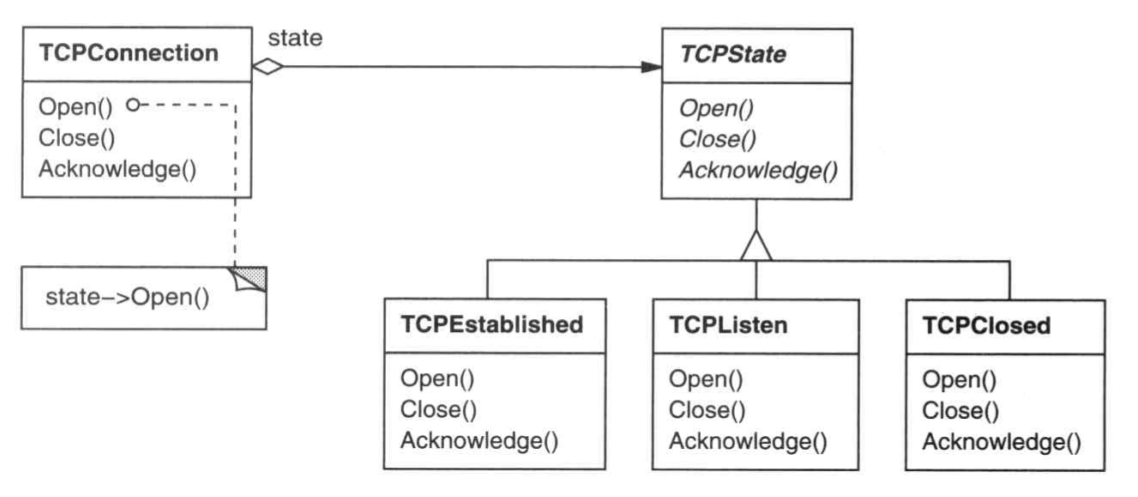
适用性
- 一个对象的行为取决于它的状态 , 并且它必须在运行时刻根据状态改变它的行为。
- 一个操作中含有庞大的多分支的条件语句,且这些分支依赖于该对象的状态。这个状态通常用一个或多个枚举常量表示。通常, 有多个操作包含这一相同的条件结构。State模式将每一个条件分支放入一个独立的类中。这使得你可以根据对象自身的情况将对象的状态作为一个对象,这一对象可以不依赖于其他对象而独立变化。
结构
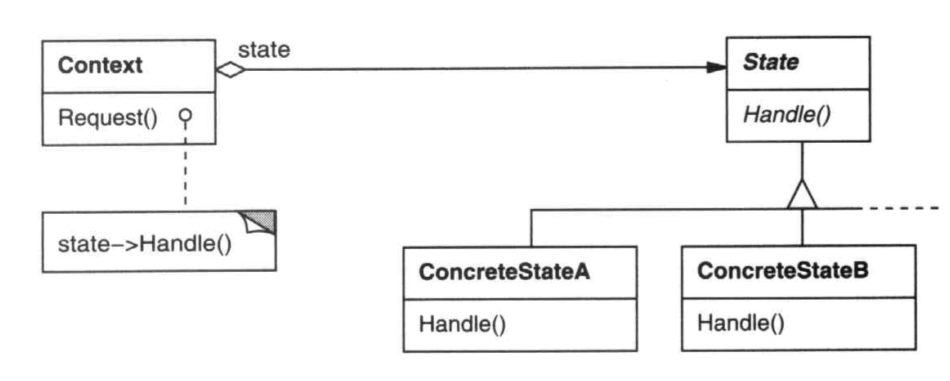
参与者
Context:客户端感兴趣的接口State:状态接口,定义Context在不同状态下不同的行为ConcreteState:具体的状态实现
策略模式(Strategy)
策略模式是在某个功能需要根据情况选择不同的执行方式时,将每种情况抽取出来,单独形成一个执行策略。
动机
程序中的某一个功能可能需要提供多种类别的支持,比如一个将内存中的某种位图对象转换成固定格式的图片字节码时,可能需要提供JPG、PNG、GIF、BMP等等转换格式的支持,具体采用怎样的转换方式取决于用户如何选择。
如果把这些功能都塞进ImageConverter类中,类中会充斥着大量的if-else语句来根据用户指定的格式不同来使用不同的转换代码,而且ImageConverter类会变得很臃肿,不利于维护,不利于新添加格式。
策略模式是在某个功能需要根据情况选择不同的执行方式时,将每种情况抽取出来,单独形成一个执行策略。在上面的例子中,可能就会存在JPEGConvertStrategy、PNGConvertStrategy等类,用于完成指定的格式转换功能。
适用性
- 许多相关的类仅仅是行为有异。“策略”提供了一种用多个行为中的一个行为来配置一个类的方法。
- 需要使用一个算法的不同变体。例如,你可能会定义一些反映不同的空间/时间权衡的算法。当这些变体实现为一个算法的类层次时[HO87] ,可以使用策略模式。
- 算法使用客户不应该知道的数据。可使用策略模式以避免暴露复杂的、与算法相关的数据结构。
应该是说
ImageConverter不应该了解具体的转换算法的细节,不应该维护它们所需要的数据结构。
结构
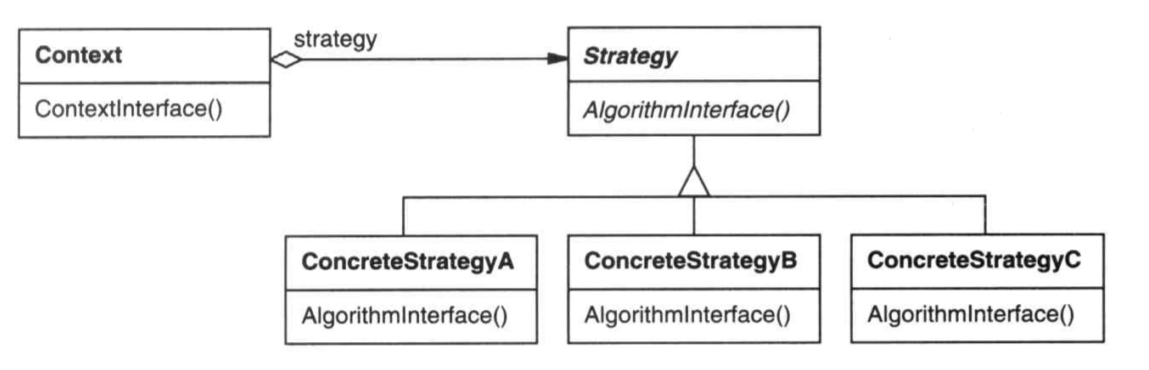
参与者
在此部分,给出该设计模式中的关键组件,为了便于练习,我不会将这里所述的组件与上面示例中的组件一一对应,你需要自己思考并对号入座。如果不确定,再往下一点就是答案。
Context:某个行为需要提供多种版本支持的对象- 维护一个当前使用的策略对象
- 可以给策略暴露能够访问内部数据结构的API
Strategy:策略接口,定义每一个策略的公共行为ConcreteStrategy:具体策略实现
Context: ImageConverter
Strategy: Strategy
ConcreteStrategy: JPEGConverter, PNGConverter
模板模式(Template)
模板模式用于,父类不知道某些功能具体该怎么实现,这些功能的实现方式特定于子类时,提供抽象方法,把这部分功能的实现委托给子类。
动机
考虑一个Web应用开发框架可能提供一个Controller抽象类,该抽象类匹配到一个URL上,你需要继承Controller来接收用户的请求,处理并返回。Controller中定义了serve方法,用于对用户的请求服务。
Controller接口能做的是,请求到达serve方法时解析HTTP数据包,拿到请求URL、header和body等内容,对请求参数、请求method进行解析,处理Cookie,并把所有这些内容转换成对应的Java对象。但是,Contoller类并不知道接到这个请求后该如何处理,这一部分应该是你编写的子类的逻辑。
所以Controller可能提供一个抽象方法doServe,这部分由你的子类实现,由于Controller已经在serve中做了一些基本工作了,所以这部分工作在你的doServe中无需再做,你只需要利用这些成果,编写你的服务逻辑。
更进一步的话,Controller可能解析出请求对应的http method,然后根据不同的请求方法,调用doGet、doPost、doPut等方法,这样,你的子类可以去重写这些方法而不是doServe,这样你的请求方法不用再判断请求方法了,而且Controller抽象类可以提供这些方法的默认实现,在子类未指定行为时,返回404给前端。
模板模式用于,父类不知道某些功能具体该怎么实现,这些功能的实现方式特定于子类时,提供抽象方法,把这部分功能的实现委托给子类。
适用性
- 一次性实现一个算法的不变的部分,并将可变的行为留给子类来实现。
- 各子类中公共的行为应被提取出来并集中到一个公共父类中以避免代码重复。
- 控制子类扩展。模板方法只在特定点调用“hook”操作(参见效果一节),这样就只允 许在这些点进行扩展。
结构
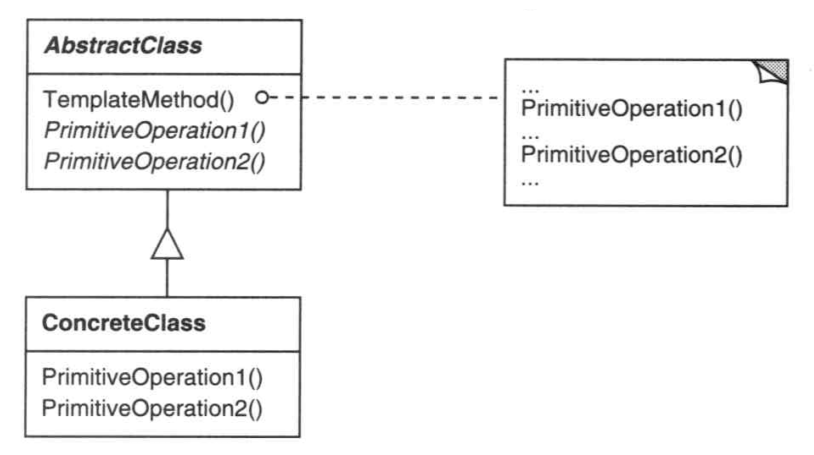
参与者
AbstractClass(Controller):某些行为需要子类确定的抽象类- 它有责任将在所有子类中都需要的公共部分实现
ConcreteClass(你实现的Controller):具体的子类,实现模板方法,提供特定于该子类的最小功能
访问者模式(Visitor)
访问者模式利用
Visitor将一个对象与不属于它的职责但需要获取它提供帮助的功能解耦,将功能转移到外部的Visitor身上,减轻对象的职责,方便添加新功能。
动机
考虑你在实现一个静态的程序语言分析软件,它将针对源代码构建抽象语法树,你可以实现类型检查、变量在使用前是否都被正确赋值、格式化输出代码等功能。
于是你给语法树中的节点定义了如下方法:
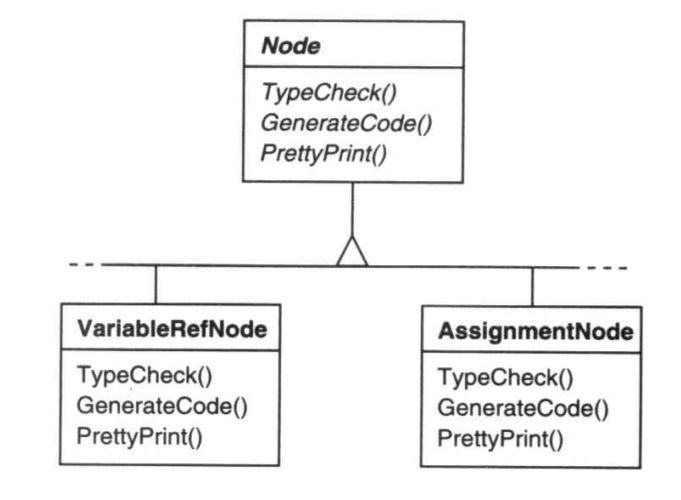
你需要调用顶层Node的某种方法用于实现特定功能,比如TypeCheck用于实现类型检查,然后Node本身来对自己执行检查操作,再调用子节点的对应功能。
可是,这些功能不应该是节点实现的,节点承受了太多的职责,而且你想添加新功能时就要改变所有节点。
你可以转换思路,通过创建Visitor对象来访问节点,节点可以“接受”(Accept)一次访问,一旦它接受了访问,它会根据自己的节点类型调用Visitor的对应方法,并将自己传入。这样,我们可以针对不同的功能建立不同的Visitor,比如TypeCheckVisitor、CodeGeneratingVisitor,这样就将这些要实现的功能通过访问者和节点解耦。
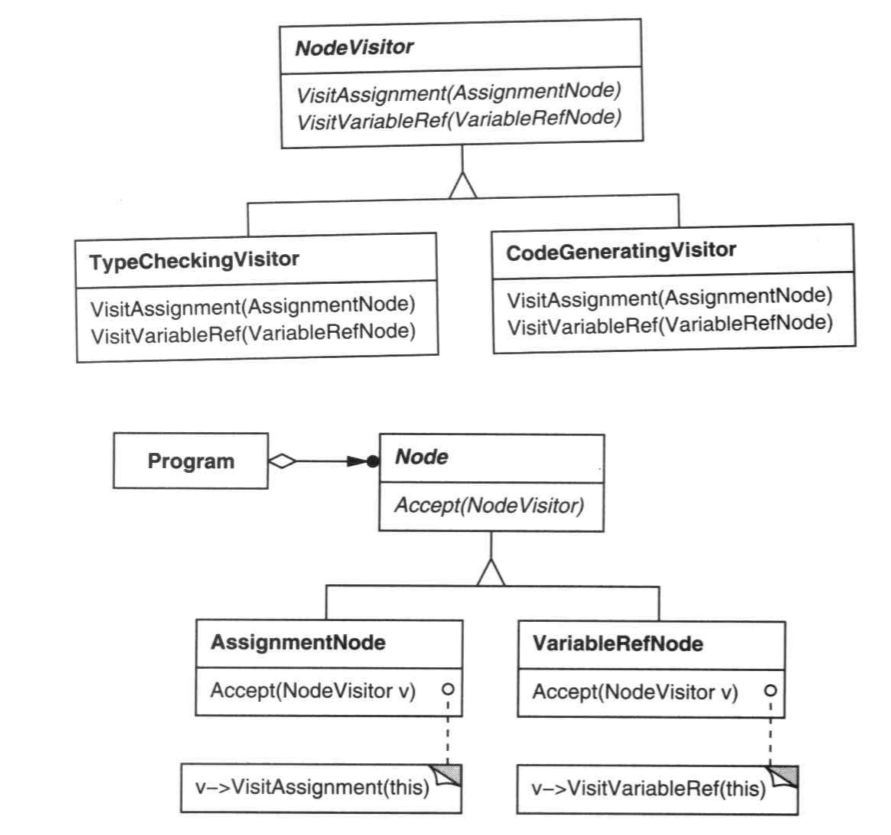
访问者模式利用Visitor将一个对象与不属于它的职责但需要获取它提供帮助的功能解耦,将功能转移到外部的Visitor身上,减轻对象的职责,方便添加新功能。
适用性
- 一个对象结构包含很多类对象,它们有不同的接口,而你想对这些对象实施一些依赖于其具体类的操作
- 需要对一个对象结构中的对象进行很多不同的并且不相关的操作,而你想避免让这些操作“污染”这些对象的类。
- 定义对象结构的类很少改变,但经常需要在此结构上定义新的操作。
结构
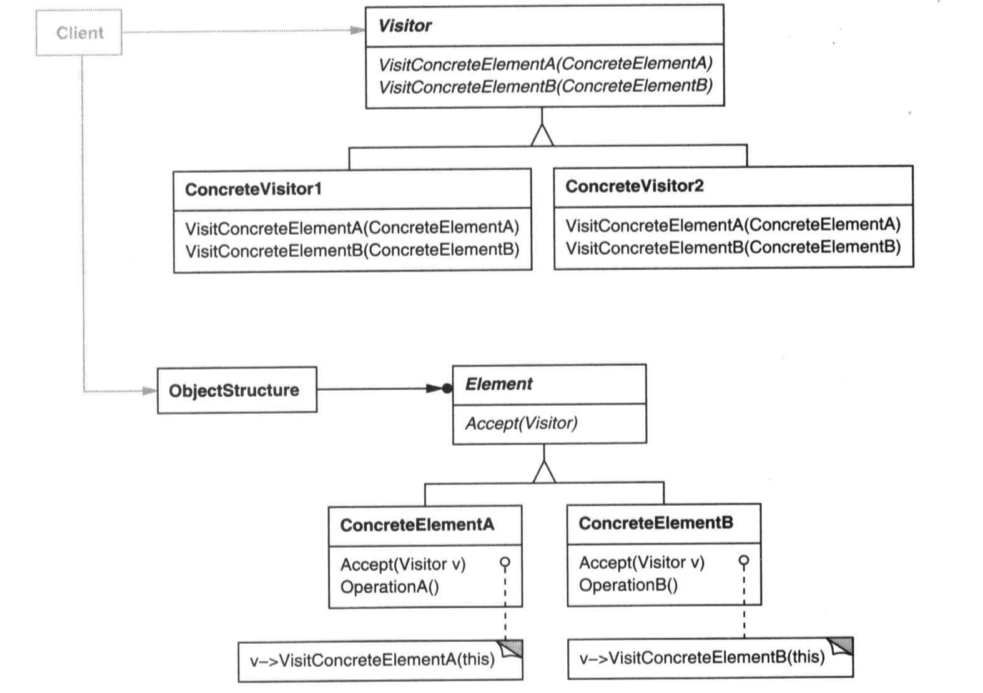
参与者
Visitor:某种对象的访问者,它会请求访问对象信息,并提供某种功能ConcreteVisitor:具体的访问者,提供具体的功能Element:被访问的元素ConcreteElement:被访问的具体元素ObjectStructure:高层对象结构

 浙公网安备 33010602011771号
浙公网安备 33010602011771号