CSAPP(六)——存储器层次结构
分层概述
不同层次的存储器的常见访问时钟周期
| 存储器 | 时钟周期 |
|---|---|
| CPU寄存器 | 0 |
| 高速缓存 | 4~75 |
| 主存 | 上百 |
| 磁盘 | 几千万 |
除非设计非常失败,计算机程序大多数都会在一段时间内持续的访问某个局部的数据,这称为局部性原理。所以存储空间更小,性能更高的存储器通常作为存储空间稍大,性能稍低的存储器的缓存,用于缓存目前正在被频繁访问的局部数据。
存储技术
SRAM(静态RAM)
SRAM是一个将位存储在由6个晶体管的电路来实现的具有双稳态的存储器单元中。左稳态和右稳态代表位的两种状态。
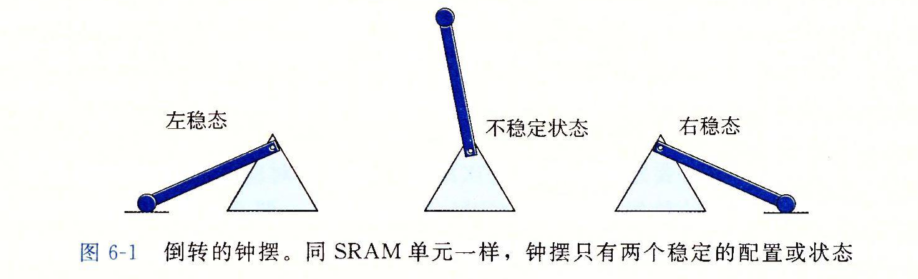
SRAM是稳定的,只要有电,它就会倾斜到一边。下面是SRAM和DRAM的特性对比。

SRAM造价高昂,速度快,用在高速缓存上,DRAM相对低廉,速度稍慢,用在主存上。
DRAM(动态RAM)
如下,是一个16x8的DRAM芯片:
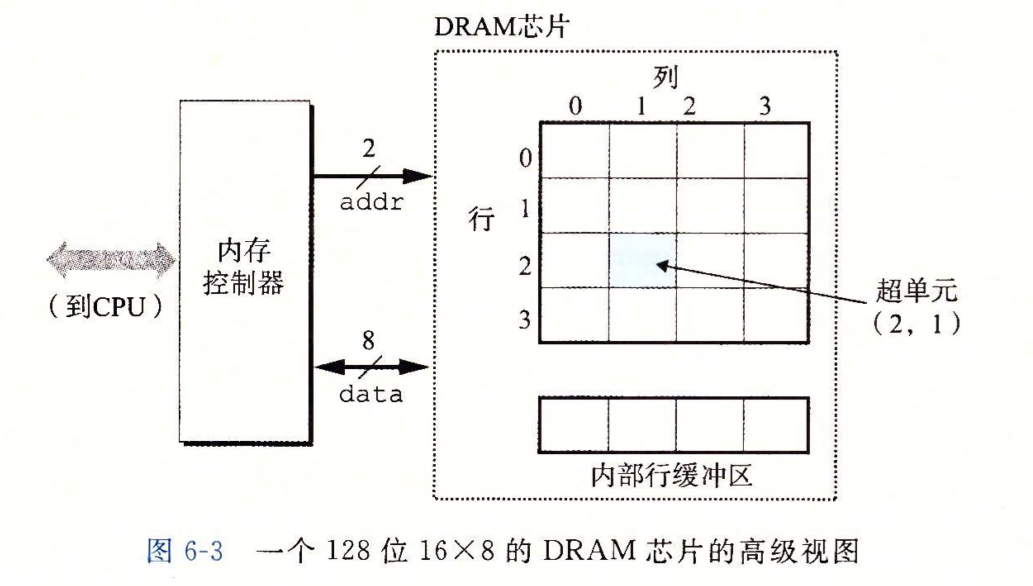
一个DRAM芯片由\(d\)个超单元(supercell)组成,图中就是16个超单元。超单元被组成\(r\)行\(c\)列的长方形阵列,图中是4行4列。每个超单元中包含\(w\)个DRAM的基本单元,每个单元可存储一位数据。一个\(d\times w\)的DRAM芯片能存储\(dw\)个位。
内存控制器是一组电路,它通过引脚(pin)连接到DRAM芯片(内存控制器可能连接很多个DRAM芯片,稍后会看到),每个引脚传输一位数据,图中有两个\(addr\)引脚用来控制读写的超单元所在的行列(所以行列是共用一组引脚的),有八个\(data\)引脚用来传输一个超单元中所存储的\(w\)个位(这里是8个)。所以,\(w\)是DRAM芯片读取的基本单位。下图是从一个16x8的DRAM芯片中读取超单元(2,1)的内容的图示。
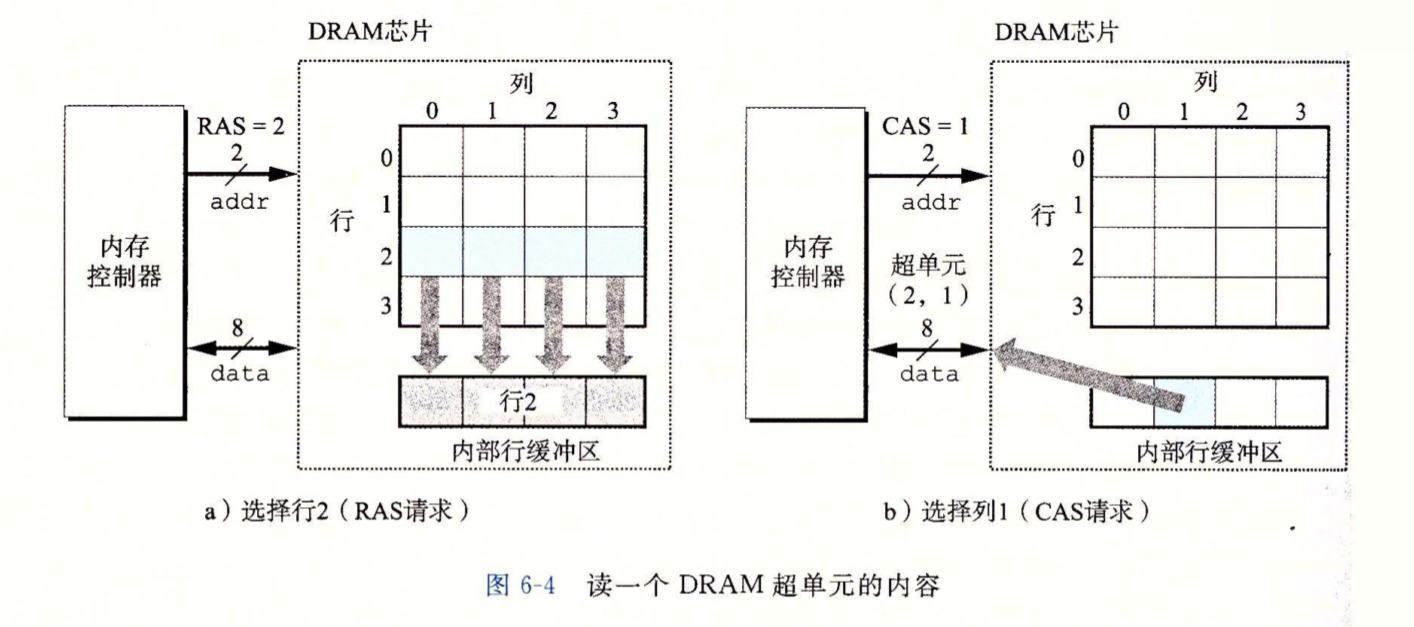
先通过\(addr\)引脚发送RAS(行访问选通脉冲),然后DRAM会将行2的所有内容都复制到内部行缓冲区,然后发送CAS(列访问选通脉冲),DRAM会从内部行缓冲区中读出列1返回给内存控制器。
二维地址可以缩小地址引脚数量,但由于必须发送两次才能确定一个超单元,所以增加了读写延时。
Core i7使用240个引脚的双列直插内存模块,以64位大小从内存控制器和内存间传递数据。
内存模块
内存模块可能由多个DRAM芯片组成,下面是一个具有8个大小为64Mbit的DRAM芯片的内存模块,每个DRAM芯片是\(8M\times 8\)的,也就是每个内存芯片中有\(8M\)个超单元,每个超单元有\(8\)位数据,总共就是\((8M \times 8bit)\times 8 = 64MB\)的大小。
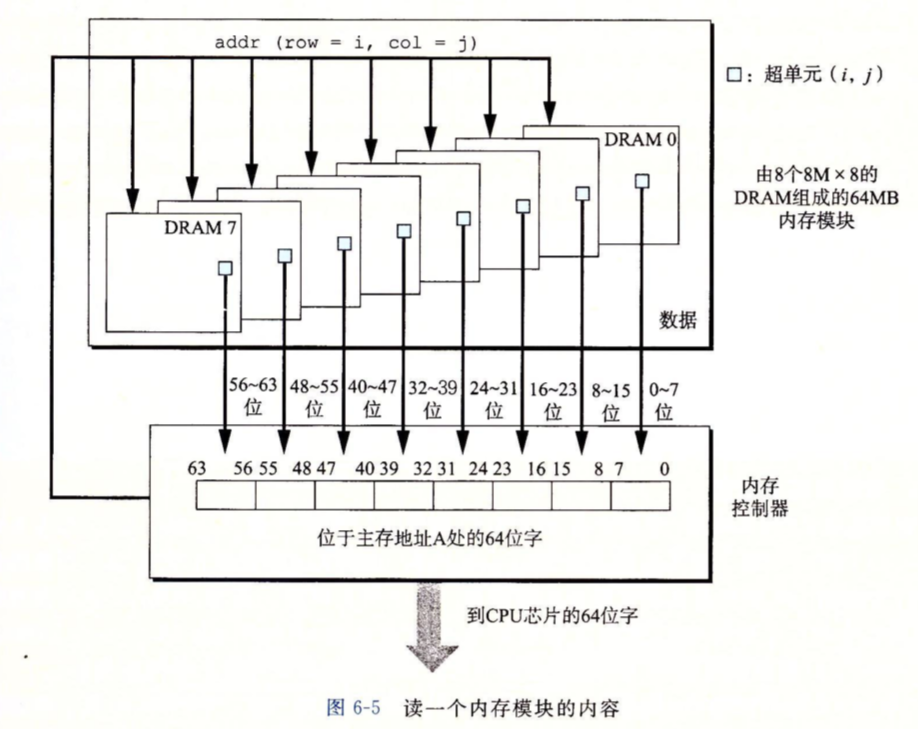
上图中,每个DRAM芯片的每个超单元\((i, j)\)存储主存的一个字节,然后每个DRAM芯片的超单元\((i, j)\)连接起来,就组成了一个64位字。
所以:
- 内存控制器接收到读取地址A处的64位字
- 内存控制器将地址A转换成包含数据的内存模块k以及超单元地址\((i, j)\),将其发送给内存模块k
- 内存模块将\((i, j)\)广播到每个DRAM芯片,DRAM芯片输出它们的8位数据
- 内存模块将每个DRAM芯片的8位数据聚合成64位数据,返回给内存控制器
对于CPU来说,内存是一个巨大的一维数组,而对于内存控制器来说,它是二维数组。(实际上如果算\((k,i,j)\)的话应该是三维数组)
增强的DRAM
- 快页模式:传统DRAM的行缓冲区用完即扔,下次再复制。快页模式不会直接扔,这是为了在连续访问相同行时使用之前的行缓冲。并且,可以通过不传RAS只传CAS来表示读取和之前相同的行。
- ...
访问主存
CPU和主存之间通过总线来传输数据,读写的步骤称为总线事务。总线只是一组并行的导线,具体的细节取决于设计,但不论怎么设计,它们都是用来传递地址、数据和控制信号的。不同类型的信号可以用不同的总线,不同的设备也可以用相同的总线。下图中CPU和IO桥通过系统总线连接,IO桥和主存通过内存总线连接。
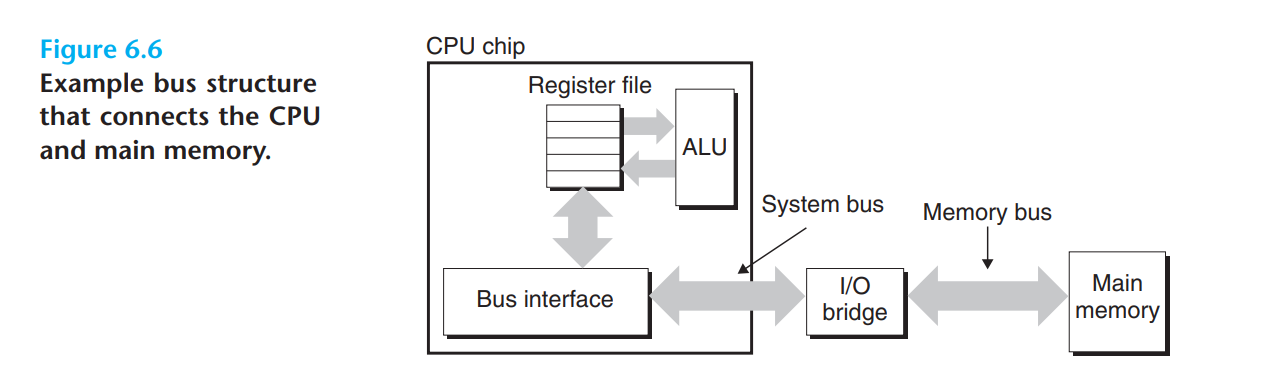
由于中文版PDF是扫描的,所以图片上的总线已经模糊到无法分辨,这里只能放上原书的图
下面是一条从内存地址A读数据到%rax中的指令movq A, %rax的执行过程:
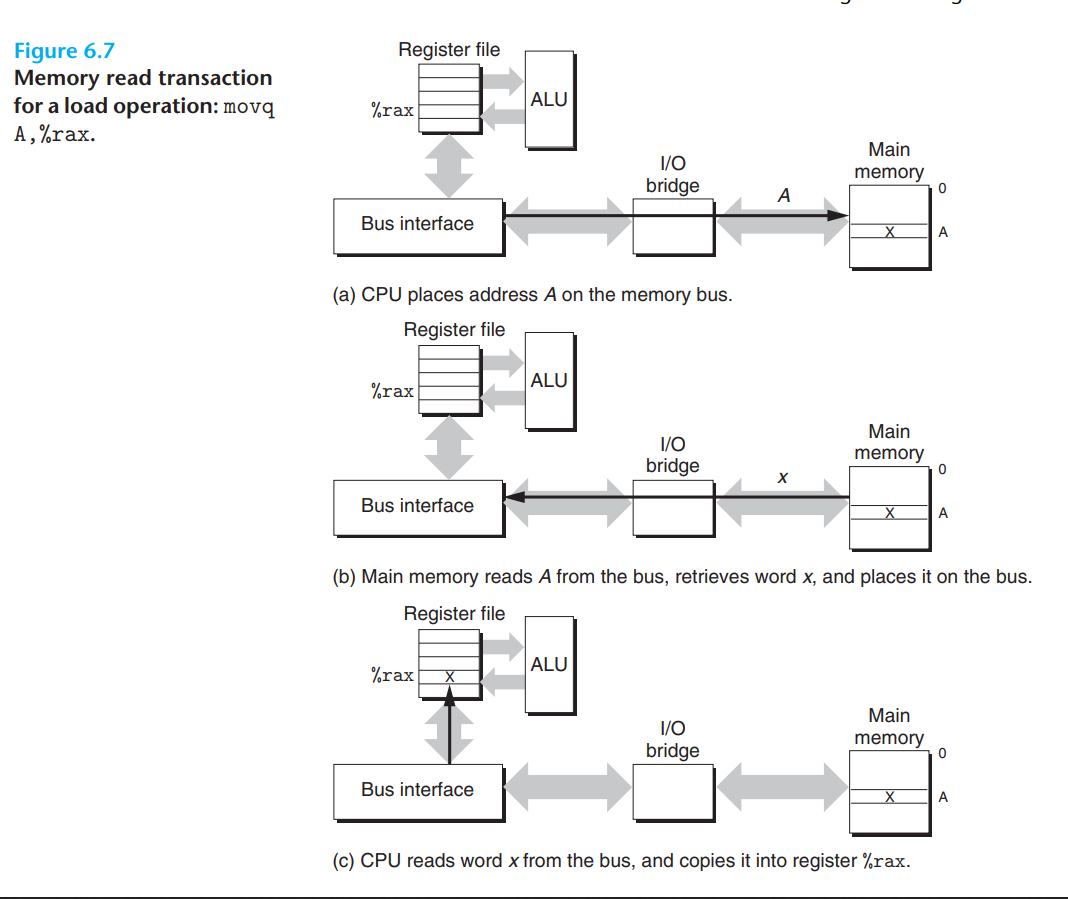
对于CPU来说,它只是将地址放到系统总线上并从系统总线读出字作为读取的结果。而对于IO桥来说,它将来自系统总线的信号翻译成内存总线的信号并放到内存总线上,并从内存总线中读出字,翻译成系统总线的信号并放到系统总线上。对于主存来说,它从内存总线读出数据,操作DRAM芯片,读出字并将数据放回内存总线。
磁盘存储
磁盘的物理结构我记得好像在以往的某些笔记中记录过,这里只是简单记记。
操作时间
- 寻道时间:因为读取磁盘时,磁盘臂可能不在包含数据的扇区所在的磁道上,所以要先将磁盘臂移动道对应的磁道上。这个时间的平均值通常为3到9ms,最大时间可高达20ms。
- 旋转时间:寻道之后,磁盘臂所在的磁道已经包含要操作的扇区了,但是这个扇区并不一定在磁头下面,所以要将磁盘旋转,将要操作的扇区移动到磁头下。
- 传送时间:实际用来传送数据的时间。
逻辑磁盘块
磁盘作为一种精密的机械装置,它的原理十分复杂,在操作系统层面,没有人愿意处理盘片、磁道、扇区、柱面这种概念,所以磁盘被抽象成了若干个块,每个块都是一个扇区的大小。磁盘中的一个硬件设备——磁盘控制器——维护着块和实际物理存储的三元组——(盘面, 磁道, 扇区)——之间的关系。
所以内存控制器提供复杂的内存模块和其中的DRAM芯片的一个抽象,它对CPU提供一个内存是一维线性数组的视图;磁盘控制器提供磁盘复杂的机械结构的一个抽象,它对操作系统提供一个磁盘就是由若干个大小相等的块组成的线性序列的视图。
IO总线
IO总线用来将一切IO设备连接到CPU和主存,不像内存总线,一些IO总线被设计成CPU无关的,如PCI总线,这给IO总线带来了更多通用性。
IO总线可以容纳种类繁多的IO设备,如下图,有三种不同的IO设备连接到IO总线,分别是USB、图形适配器和主机总线适配器(用于连接磁盘):
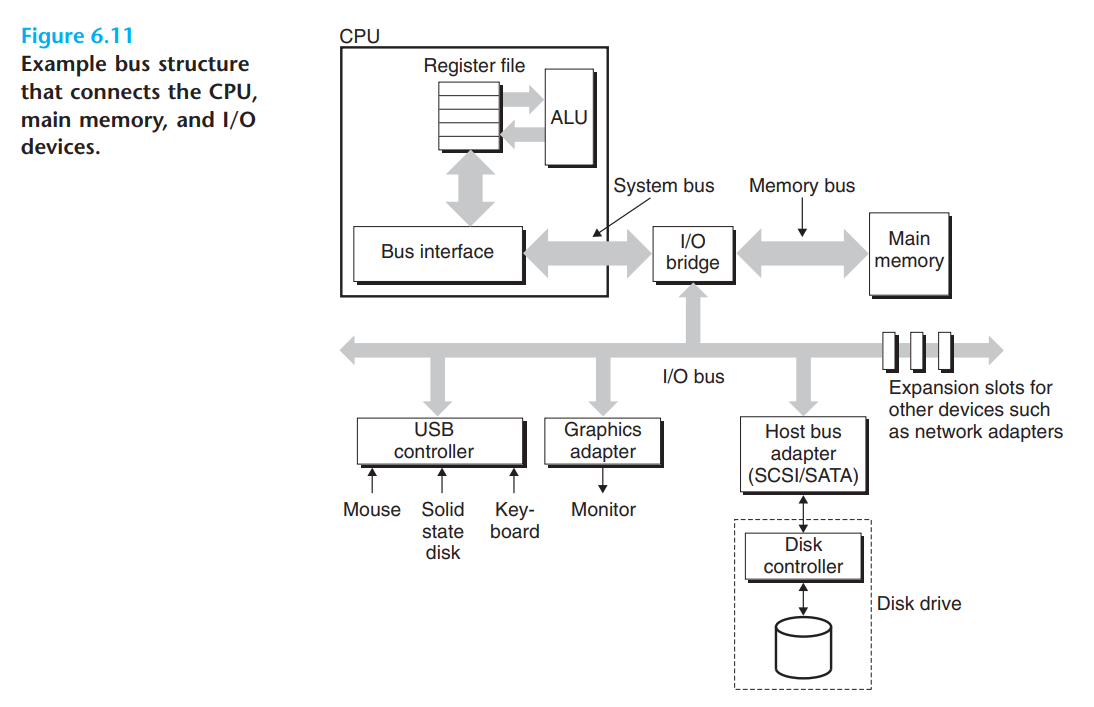
访问磁盘
CPU使用一种被称作内存映射IO的技术来向IO设备发送命令。
就像Linux中把一切设备都抽象成文件一样,内存映射IO技术将一切IO设备抽象成一个内存地址,这使得CPU能以与读写内存一致的方式来操作IO设备。地址空间中专门预留出一部分这样的地址,每一个地址称为一个IO端口,一个设备与一个或多个IO端口相关联。
假设磁盘控制器映射到端口0xa0,CPU可能会分三次向这个地址写入来进行一个磁盘读取,第一次写入一个命令字,告诉磁盘发起一个读以及一些其它参数,第二次指定要读的逻辑块号,第三次指定读到的内存地址,如下图:
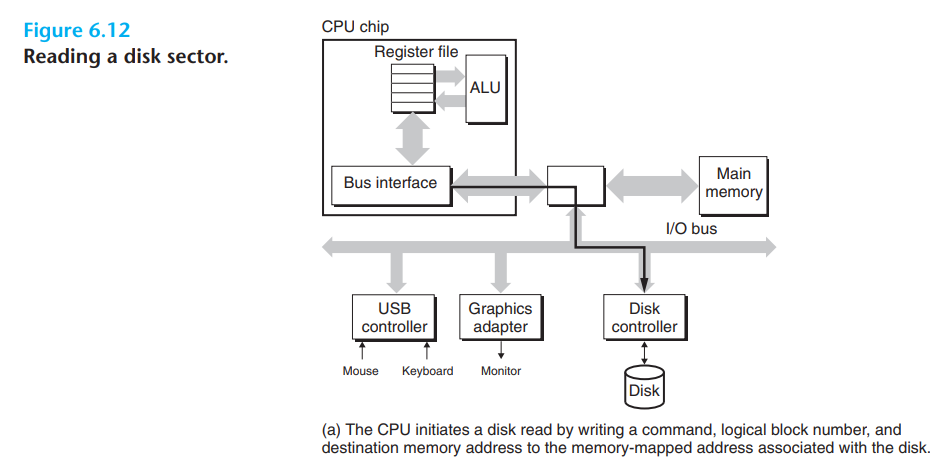
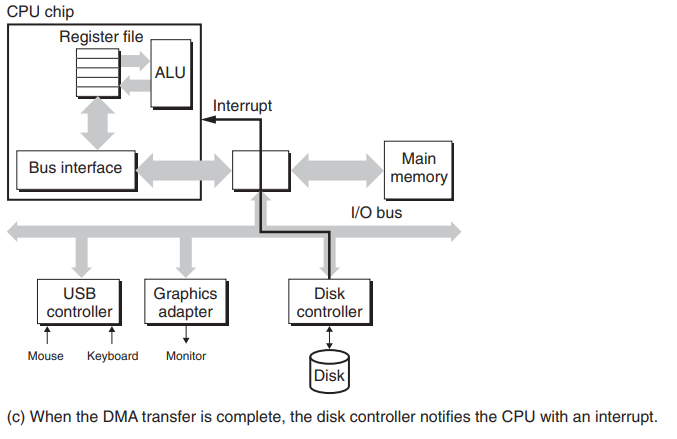
CPU发起后,磁盘进行处理,在这期间CPU通常会去执行些其他任务以免数千万个时钟周期被浪费。然后磁盘会将逻辑块号转换成扇区地址,读该扇区并将内容制品传送到主存,如下图所示。这种数据传输叫DMA(直接内存访问),如果不使用DMA,则需要CPU来干涉,这就造成数据在系统总线和内存总线中进行多次转发
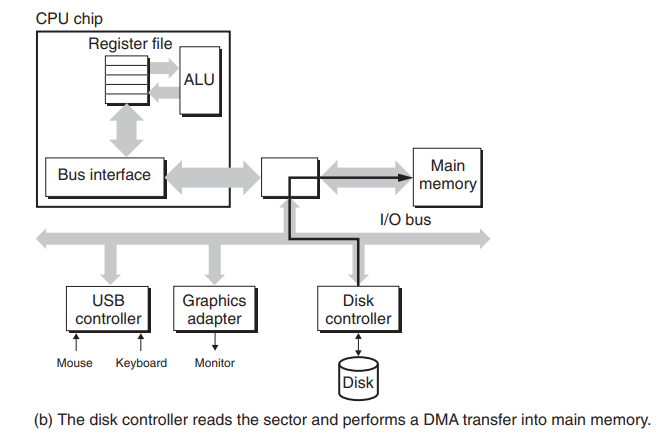
当DMA传送完成,磁盘控制器给CPU发送一个中断,因为CPU现在可能在干其他工作,它必须中断CPU手中的工作告诉它某个程序请求的磁盘读取完成了,你看看接下来该怎么搞。如下图:
固态硬盘
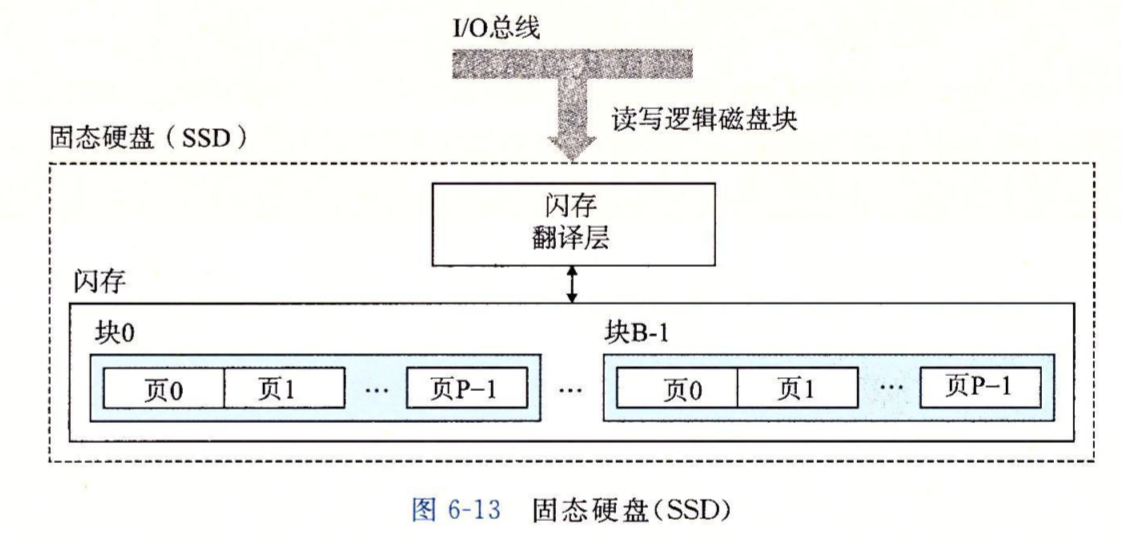
固态硬盘与机械硬盘有着完全不一样的原理和物理结构,但和机械硬盘具有一样的行为,它接收逻辑磁盘块号,并通过闪存翻译层将其翻译为底层闪存块的访问。闪存翻译层就相当于机械硬盘中的磁盘控制器。
一个固态硬盘由一系列闪存块组成,闪存块中又包含一系列页。数据以页为单位读写,页的常见大小为512Bytes~4KB,块的常见大小为16KB~512KB。
固态硬盘很容易被磨损,一个块大约在被重复写100000次后,块就不能再使用了。而在写页时,只有该页所属的块被整个擦除才能写,擦除后,块中的每个页可以不需要擦除再写一次。
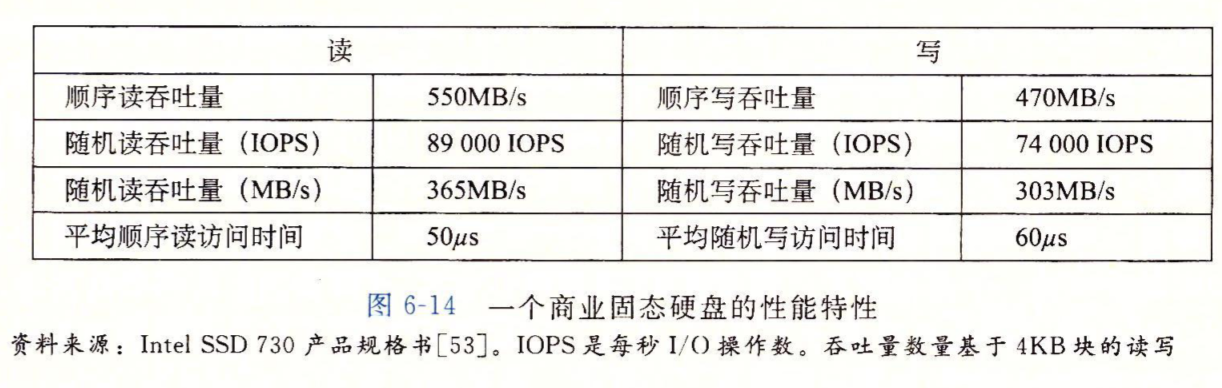
固态硬盘的写操作比较复杂,所以写操作性能往往比读低。固态硬盘的闪存翻译层中的平均磨损逻辑会将写操作均匀的分布在所有块上,以延长固态硬盘的寿命。
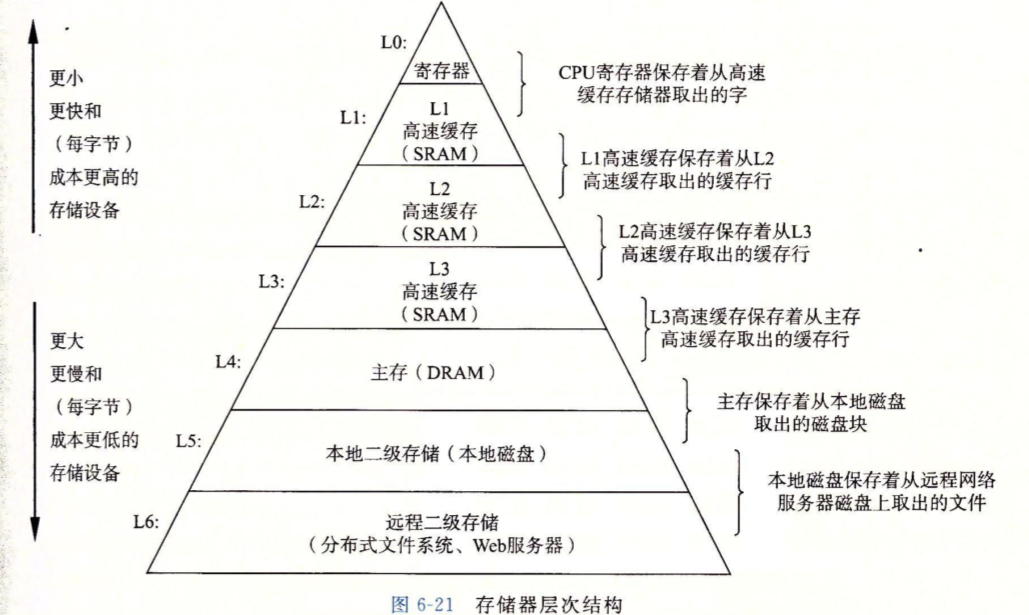
存储器层次结构
k层作为k+1层的缓存,k层缓存着k+1层中所有块的一个子集。数据总是以块位单位在不同层之间传送,但不同层之间的块大小不同,比如L0到L1之间通常使用一个字大小的块,而L1和L2之间通常是几十个字节,L4和L5之间通常是几百或几千字节。这是因为越底层设备的访问时间就越长,所以倾向于选择较大的块。
高速缓存
通用高速缓存存储器组织结构
高速缓存用于缓存主存中的数据,由于CPU将主存看作一个线性的字节数组,所以每个字节具有一个地址。CPU它会将想要访问的字节地址A发送给高速缓存,高速缓存中如果有这个字节数据就直接返回给CPU。高速缓存完全由硬件控制,这意味着我们必须提供一种简单的方式在具有\(m\)位地址长度的计算机上将地址简单快速的映射到高速缓存的一个位置。
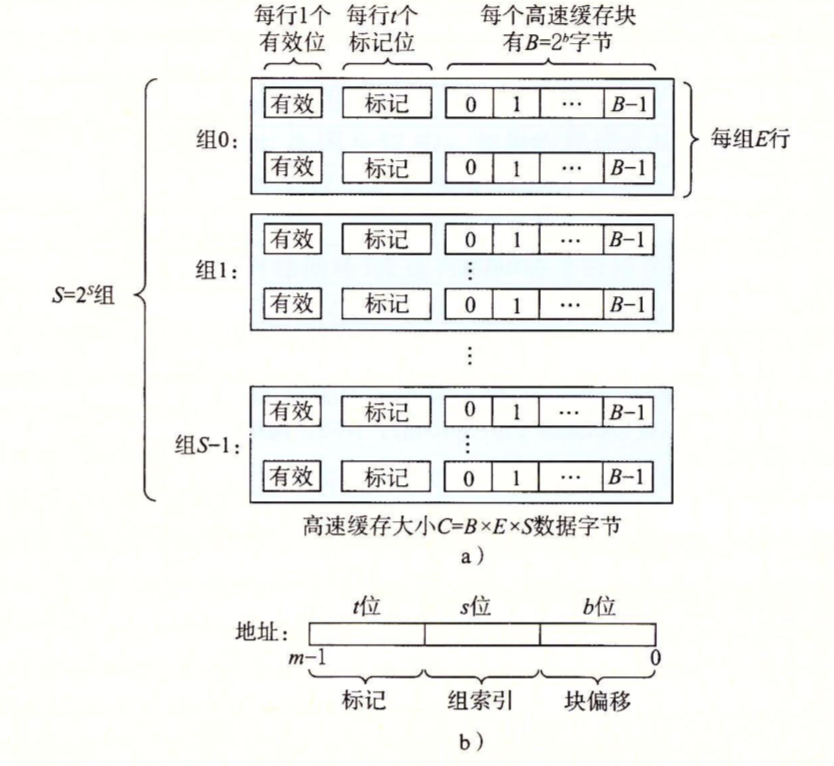
如上图a,在一台存储器地址有\(m\)位的计算机上,高速存储器被分成了\(S\)个组,每个组被分了\(E\)个高速缓存行,每个缓存行中保存有\(B\)字节的数据。所以整个高速缓存的容量\(C=S\times E\times B\)字节,每个字节称为一个高速缓存块(\(SEB\)都必须是2的幂次的大小,所以\(C\)也是)。然后,高速缓存行中还有一个有效位和\(t\)个标记位。
这样划分高速缓存是因为为了方便将存储器地址映射到高速缓存中,如上图b,\(m\)位存储器地址被分成了三份:
- 组索引具有\(s\)位,它被看作一个无符号整数,它将地址映射到\(S\)个高速缓存组中的一个上,所以\(S=2^s\)
- 标记具有\(t\)位,它也被看作一个无符号整数,它将地址映射到\(E\)个高速缓存行中的一个上。不过和\(s\)不一样的是,\(t\)的长度并不取决于高速缓存行的个数,它的长度常常远远大于能够容纳\(E\)个高速缓存行的二进制数的最小位数。相反,\(t=m-(s+b)\),也就是说,\(t\)的长度完全看去掉\(s\)和\(b\)后还剩多少。不同于组索引的一一映射,这里\(E\)个缓存行肯定容纳不下那么多的数据,所以缓存行中就有一个标记位用来记录当前行容纳的是什么数据,只有当一个行设置了有效位并且它的标记位和地址中的标记位匹配时才认为这一行包含想要读取的数据。
- 块偏移具有\(b\)位,它代表当前地址所代表的内存字节数据缓存在缓存行的数据部分的偏移量。换句话说,它代表当前这个数据存在缓存行的第几个字节上。
这样,通过将一个地址分成三部分,然后将每部分映射到一个高速缓存组->高速缓存行->字节偏移量上,这个地址很轻松并且快速的被保存到了高速缓存中。
l
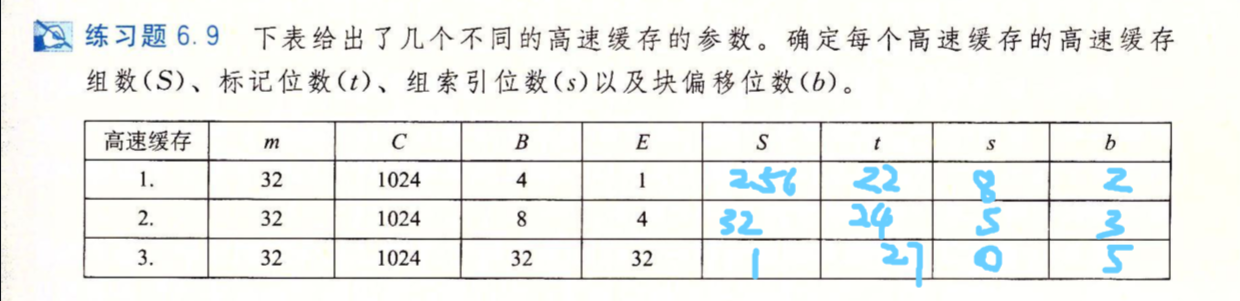
习题6.9
直接映射高速缓存
每组只有1个缓存行的高速缓存。
当CPU读取地址m的字时:
- 从m中取出组索引,用于选择高速缓存中的一组
- 从m中取出标记,用于选择组中标记匹配的一行
- 由于直接映射高速缓存的每组只有一行,所以这个选择的过程相当于没有,直接对比地址中的标记和唯一一个缓存行的标记是否匹配即可
- 匹配则缓存命中,根据偏移量读取指定的字长
- 否则缓存未命中,需要从内存加载并替换掉原来的缓存行,此时这个缓存行的标志位更新了
为什么不使用最高位做组索引
因为采用最高位的话,连续的内存块会映射到同一个高速缓存组中。这样就导致具有空间局部性的一些数据可能无法完全被高速缓存存起来。所以使用中间的位来做组索引会让连续数据分布到不同的组中。
组相联高速缓存
一个\(1<E<C/B\)的高速缓存称为组相联高速缓存,即一个组内必须有大于1个小于总容量除以每行容量个行。
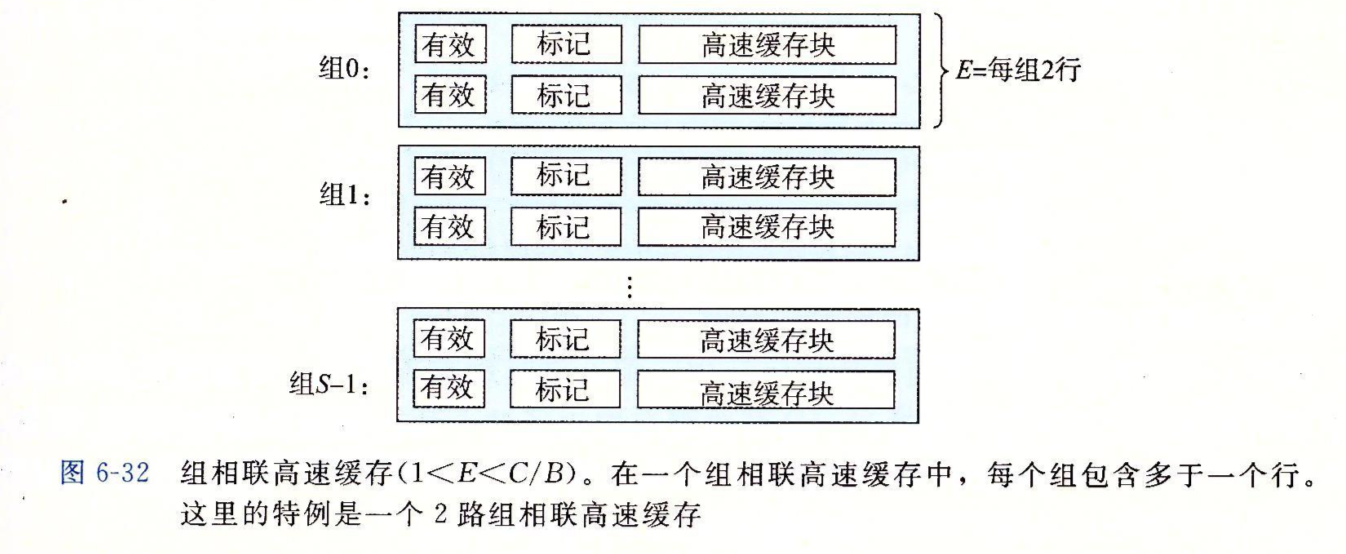
对于这样的高速缓存,在进行完组匹配后必须搜索组中的每一行进行匹配,我们可以将行看成一个相联的存储器,它保存了\(E\)个(key, value)对,key就是有效位和标记,value就是块内容。
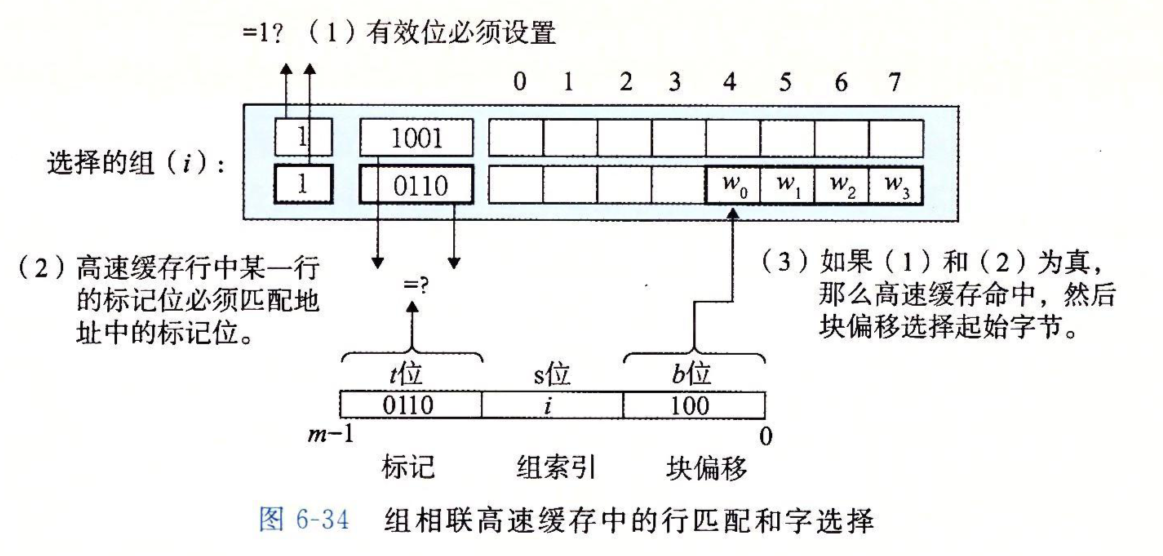
当这种高速缓存不命中时,如果该组中有空行,就直接放到空行中就行,否则需要采用指定策略来替换一个行,策略包括LRU、随机等。
全相联高速缓存
全相联即\(E=C/B\)的情况,因为\(C=S\times B\times E\),所以在这种情况下,\(S=1\),也就是说只有一个组,该组包含高速缓存中所有的行。
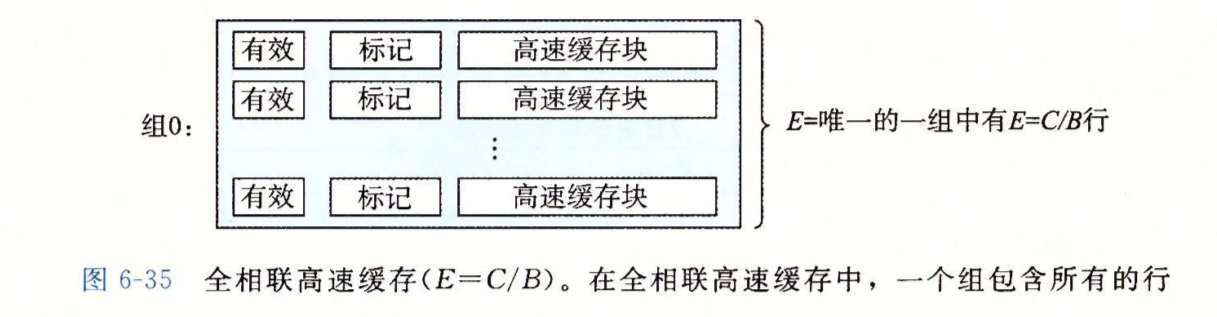
由于没有组,地址仅仅被划分为标记和块偏移两部分而已。
习题6.12


答案

习题6.13
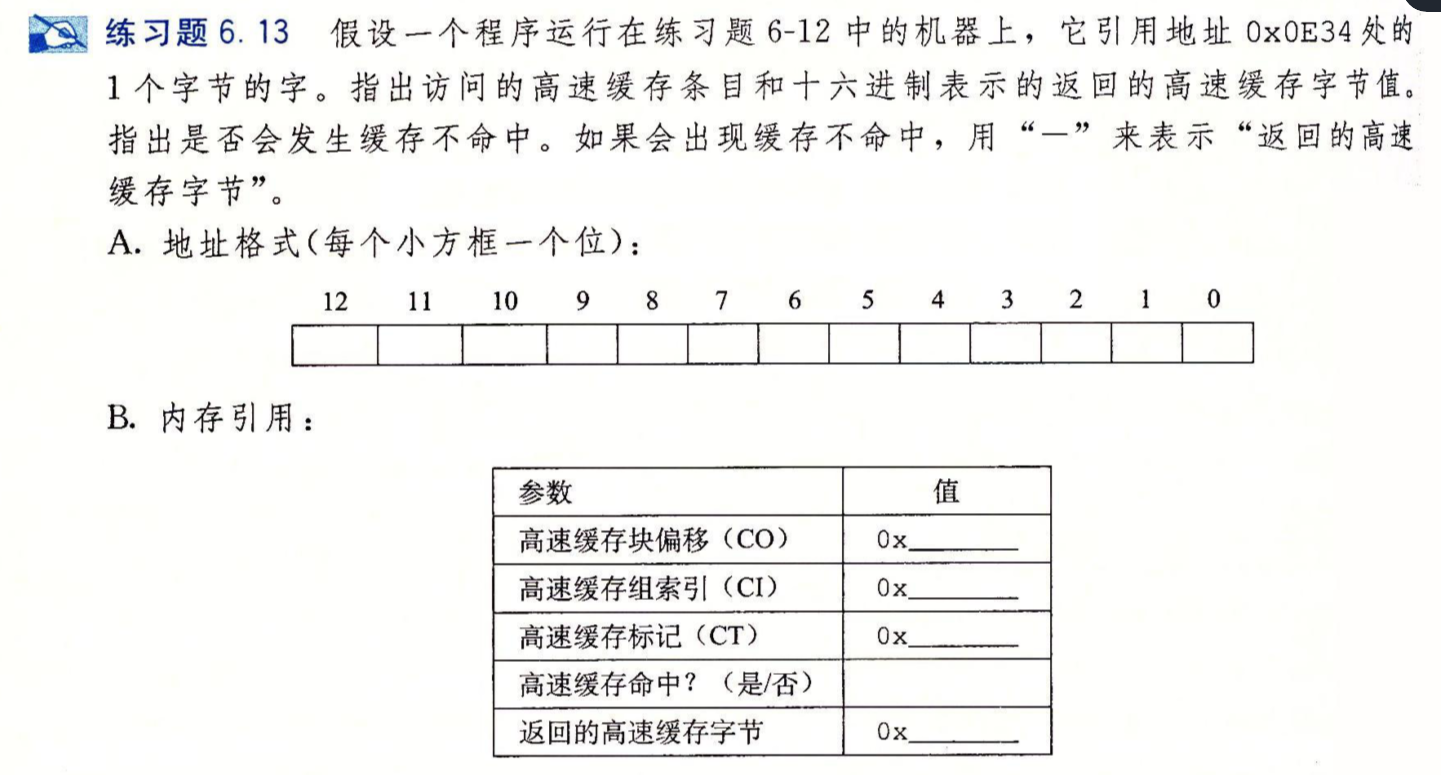
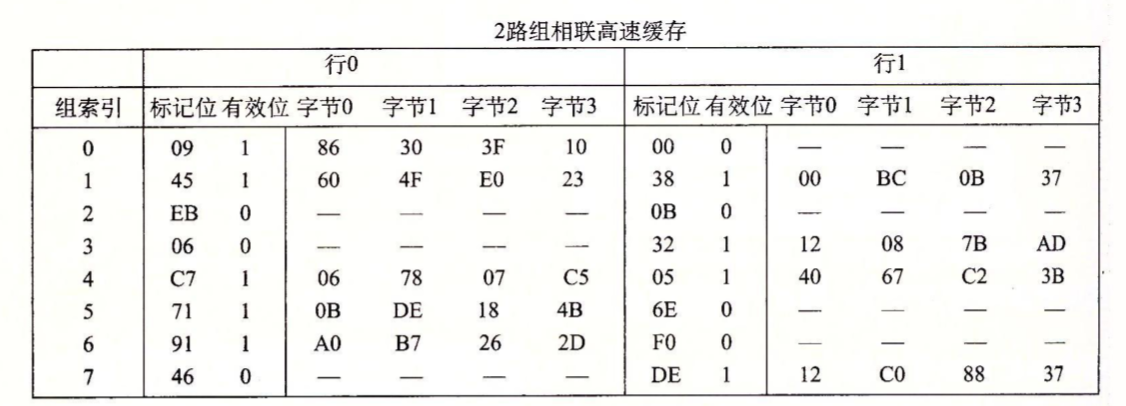
- 地址:0000 1110 0011 0100
- 块偏移:00
- 组索引:\(101_2=5_{16}\)
- 标记:\((000 0111 0001)_2 = 71_{16}\)
- 命中:是
- 返回:0x0B
习题6.14
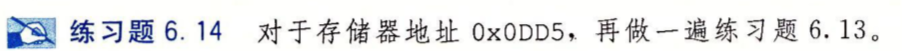
- 地址:0000 1101 1101 0101
- 块偏移:01
- 组索引:5
- 标记:6E
- 命中:否
- 返回:--
有关写的问题
当你更新了高速缓存中的内容某一块,何时写到下一层中?
在高速缓存命中的情况下,可以有两种办法:
- 直写:更新即写入到地址中,带来高额的总线流量
- 写回:尽量推迟,直到替换算法要驱逐它才写回,增加高速缓存实现的复杂度,高速缓存必须维护一个修改位(dirty bit)来记录该行是否已经变脏。
在高速缓存未命中的情况下,也有两种办法:
- 写分配:先将对应位置的字加载到高速缓存中,然后更新高速缓存中的内容
- 非写分配:直接更新低层的存储设备,高速缓存不参与
一般,直写搭配着非写分配,写回搭配着写分配。
一个真实的高速缓存层次结构的解剖
真实的处理器往往有用于缓存指令的i-cache和用于缓存数据的d-cache。它们采用不同的块大小、相连度和容量。下面是Core i7的高速缓存结构。
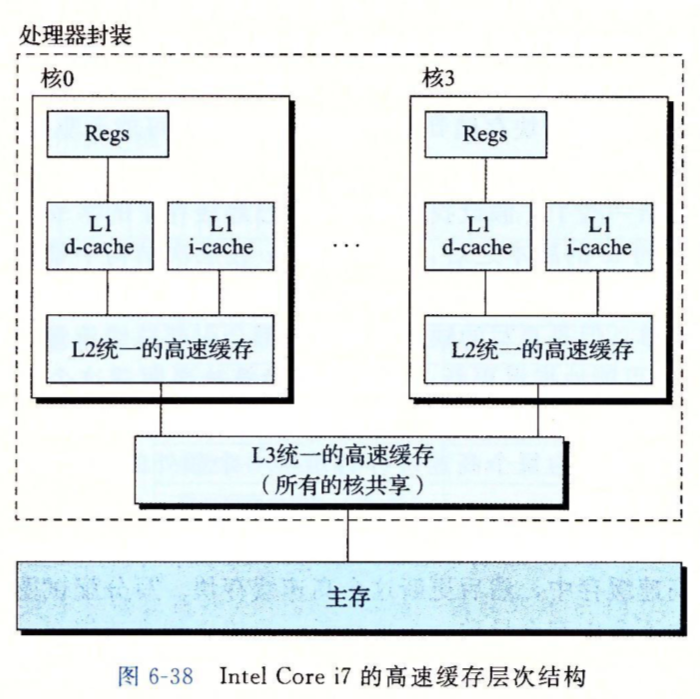
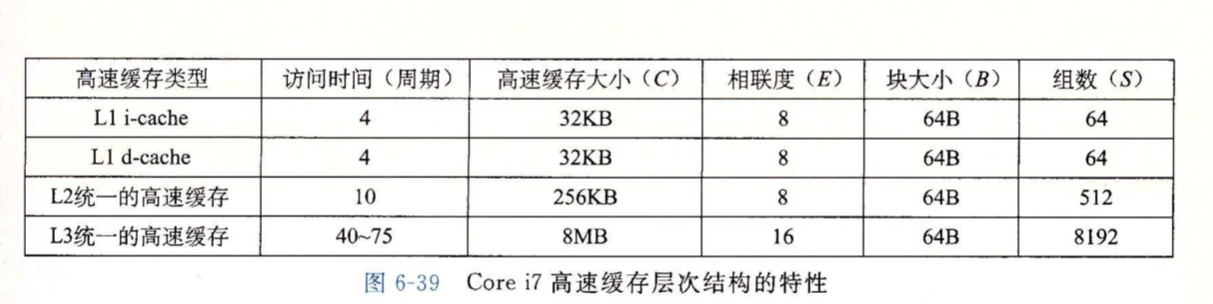
每个核心有独立的i-cache和d-cache,和独立的L2高速缓存,所有核共享L3高速缓存。
编写高速缓存友好的代码

上面的代码,对于sum和i,每次循环都会访问,它们有很好的时间局部性(实际上它们应该都会被存到寄存器中)。对于向量v,以1的步长在每次循环中连续读取,它有很好的空间局部性。对于数组这种在内存中连续的数据进行循环访问,是否高速缓存友好主要看循环的步长。
假设v是块对齐的,字长是4字节,高速缓存块是4个字,也就是高速缓存块中能存\(4*4=16\)字节,如果你像上面一样访问v,那么你会得到如下结果:

第一次,缓存未命中,从内存中加载一个字到缓存块中,这也代表后面三个字节都被缓存了,所以后面三次循环的缓存都是命中的。
在对多维数组进行操作时,以数组的物理存储顺序来访问对高速缓存更加友好。下面是一个按行遍历的图示,由于数组在物理上就是这样存储的,所以和遍历一维数组时差不多

下面是按列遍历的图示,最坏情况下每次缓存都没命中:

最好情况下,数组完全能装到高速缓存中,那么情况会好些。
存储器山
读吞吐量是每秒钟从存储系统中读取的速率。
下面的代码很长但十分简单,test以特定的步长使用4x4循环展开对特定大小的操作集来进行循环遍历。37行的test调用是对缓存进行热身,让缓存中具有数据,38行在缓存中已经有数据的情况下又调用了test函数并计算了一些统计数据。

我们主要分析在缓存热的情况下,第二次调用test函数,时间局部性和空间局部性、步长和操作集大小、高速缓存大小、高速缓存传输速率等对吞吐量的影响。
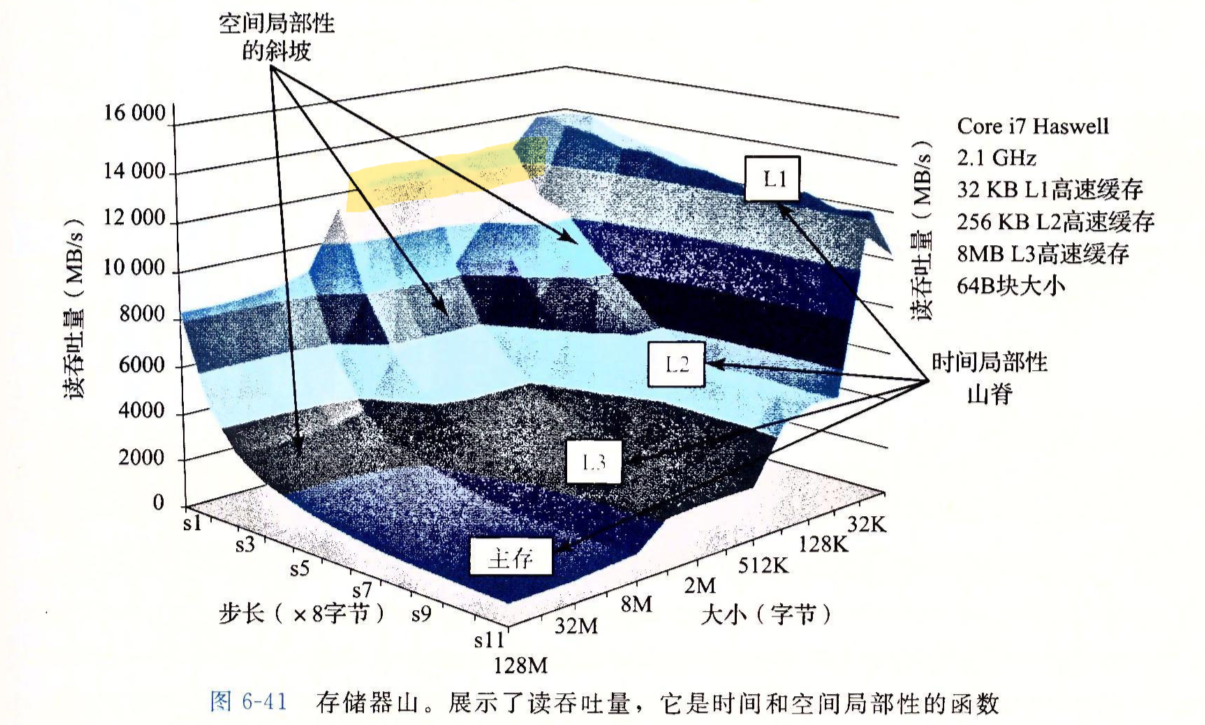
存储器山是读吞吐量关于步长和操作集大小的函数。从上面的例子中,一个非常好的利用了时间和空间局部性的程序能获得14GB/s的吞吐量,而一个很差的程序只能获得900MB/s的吞吐量。
操作集大小主要决定时间局部性,想象当操作集无法完全放到某个高速缓存中时,那么当遍历操作集的后半部分时,前半部分可能已经被刷出高速缓存了。步长主要决定空间局部性,步长越长,访问操作集之中的元素之间的物理间隔越大。
图中L2、L3和主存上的三条斜坡表现了空间局部性下降对吞吐量的影响。同样的,如果将步长固定,只变化操作集大小,也很容易看出高速缓存大小和时间局部性对吞吐量的影响。
当操作集完全能被塞进L1时,所有的访问都可以由L1中已经有的缓存来服务,所以能获得最大吞吐量。否则,必定有些情况下,L1还要去访问L2。对于其它层级,也是这样的道理。
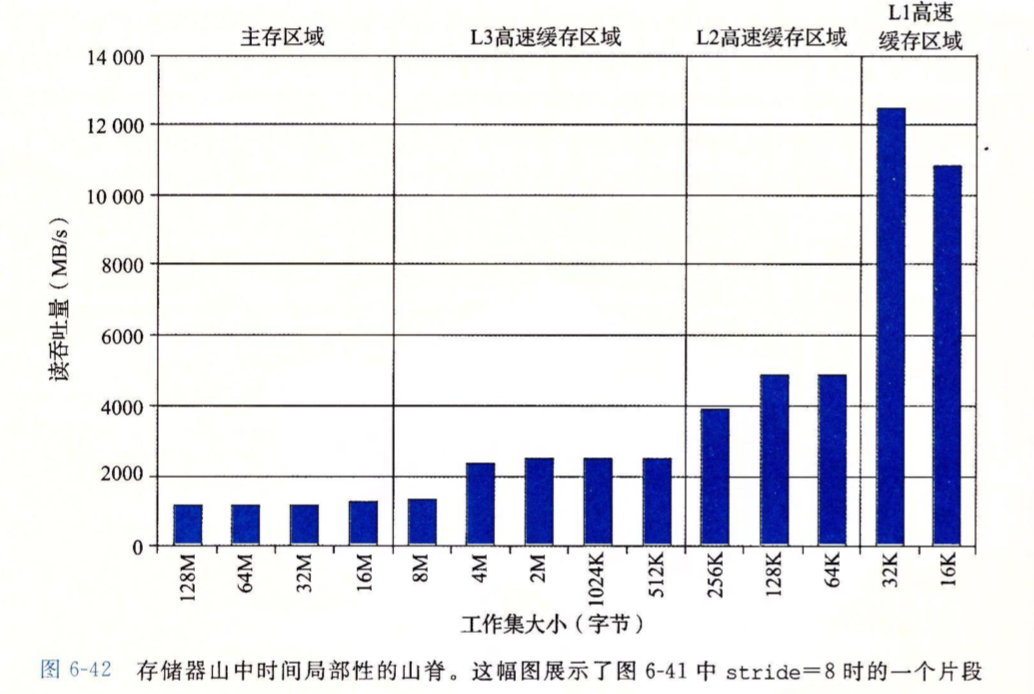
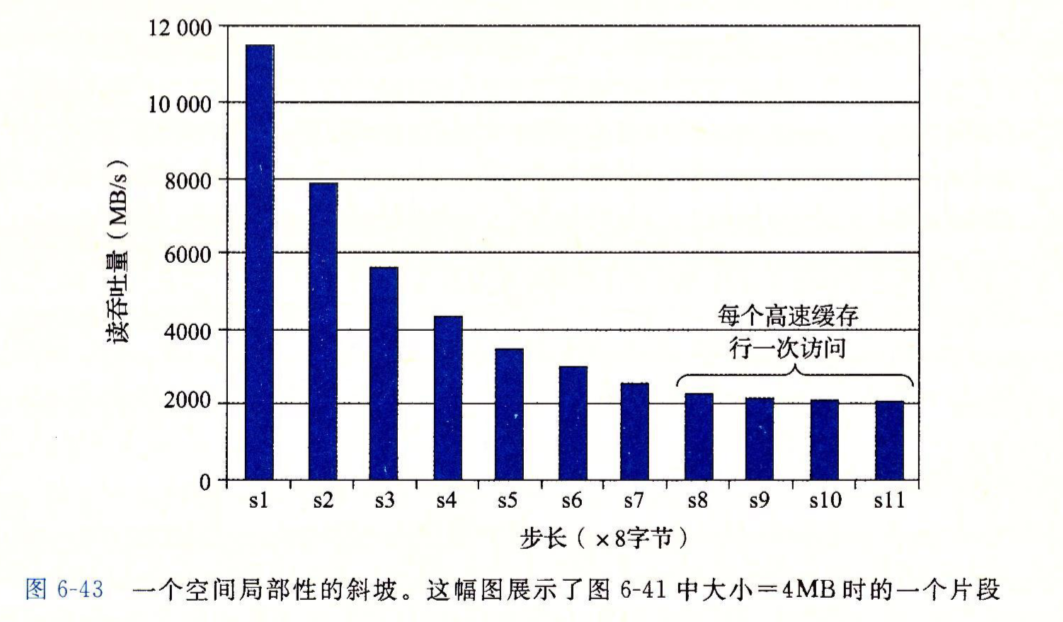
而对于空间局部性来说,当步长为1时得到更好的空间局部性,否则每次进入到高速缓存中的操作集数据总有一部分是没有被遍历到的,但它们还占用了高速缓存的空间。
固定工作集大小,只变化步长,下面是步长变化吞吐量产生的变化:
重新排列循环以提高空间局部性
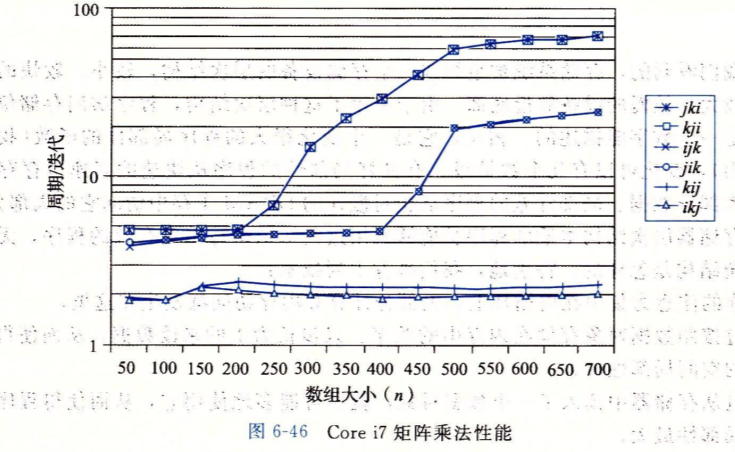
下图是六个矩阵乘法的实现,它们的区别就在于循环变量的次序。

我们主要看内循环中的操作,因为它才是主要的性能瓶颈。
第一行中的两个版本,以1步长操作矩阵A,以n步长操作矩阵B,所以对于矩阵A有最好的空间局部性,对于矩阵B则很差。
第二行中,以步长n操作矩阵C和A,所以不管对于哪个矩阵,空间局部性都很差。
第三行中,以1步长操作C和A和B,所以不管对于哪个矩阵,空间局部性都是最好的。
下图是在Core i7上这六种矩阵乘法随着n增大的性能变化,在n很大时,最快的和最慢的差了40倍。
提高时间局部性的一个思路:分块处理
缓存系统时空局部性的总结


 浙公网安备 33010602011771号
浙公网安备 33010602011771号