CSAPP(四)上——Y86-64指令集和顺序CPU实现——SEQ 处理器体系架构
指令集在CPU和程序员(编译器)之间提供了一个抽象层,看起来,CPU在一条接着一条的顺序执行编译后的指令,但出于性能考虑实际情况却远比这个“看起来”要复杂。现代CPU使用一种称作“流水线”的技术来执行每一条指令。
本章基于一种具有简单指令集“Y86-64”的CPU架构进行研究,旨在对处理器的整个体系架构的了解更进一步。
Y86-64指令集体系结构#
程序员可见的状态#
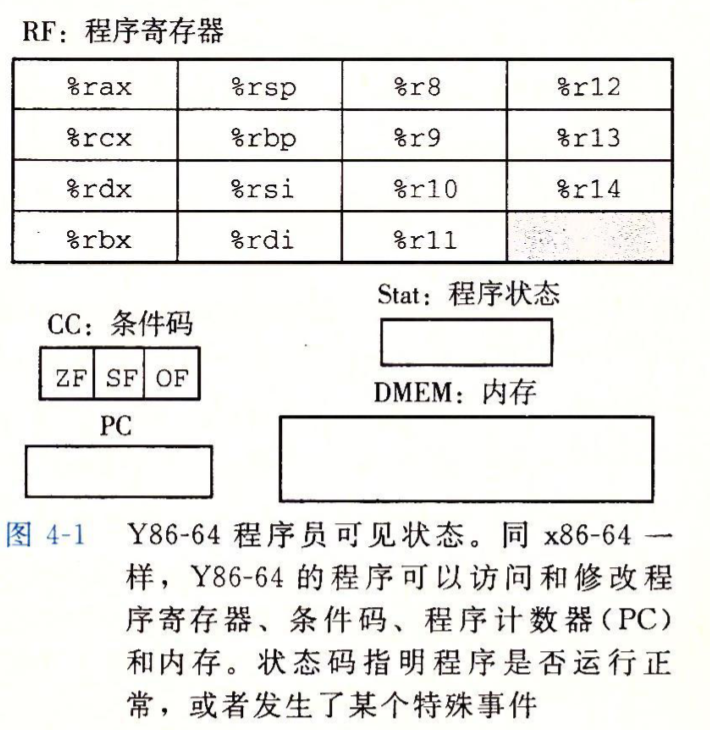
Y86-64指令#

和x86-64不同的几点:
- mov类命令,它的操作数类型必须由特定的前缀指定,比如
rrmoveq代表该mov指令的第一个操作数是一个寄存器,第二个也是一个寄存器。这使得我们对指令进行二进制编码时更加方便。mov类指令不允许mm和im/mi操作,即内存到内存,内存和寄存器的直接移动。 - OPq类命令,即计算类命令,只有
addq、subq、andq和xorq,它们只对寄存器数进行操作,x86-64则允许对内存数据进行操作。这四个指令会设置条件码 - halt指令导致处理器停止,并将状态码设置成HLT
指令由一个字节进行编码,高四位代表指令类型,低四位代表指令类型下细致的操作类型,比如jXX这种跳转指令,它有jmp、jle、jne等等。一些需要指定寄存器的指令需要一个字节来指定使用哪个寄存器。同样,高四位代表寄存器rA(第一个操作数),低四位代表寄存器rB(第二个操作数)。有些指令只需要一个寄存器,比如irmovq,所以它的rB可以传入,rA固定为F。dest代表64位的目的地址,因为有的命令需要读取内存地址。

如上是一些同类操作指令的细致分类。
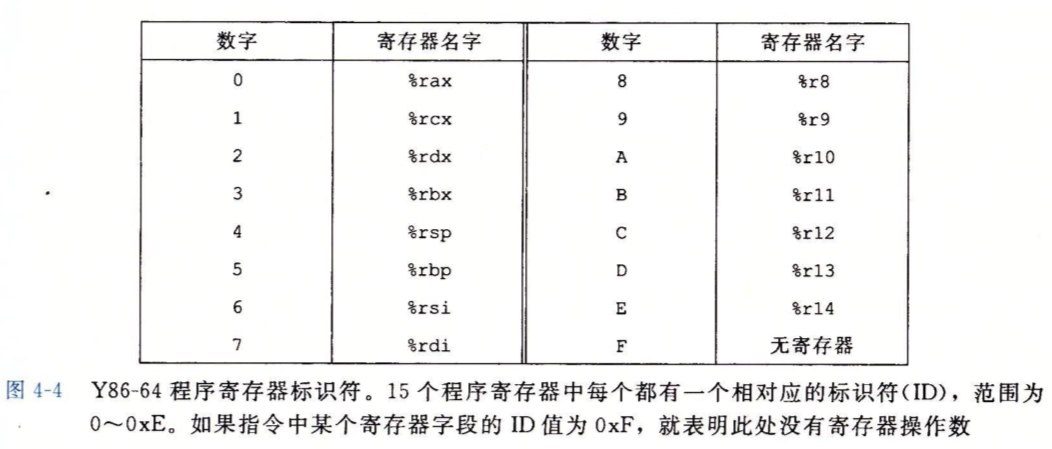
如上是Y86-64中包含的寄存器标识符,它们被编码为0~E,F表示没有寄存器操作数。
练习题4.1#

A:
irmovq $15, %rbx
30f3f000000000000000
B:
rrmovq %rbx, %rcx
2031
C:
rmmovq %rcx, -3(%rbx)
4013fdffffffffffffff
D:
addq %rbx, %rcx
6031
E:
jmp loop
700c01000000000000
练习题4.2#

A:
irmovq $-4, %rbx
rmmovq %rsi, $0x800(%rbx)
B:
pushq %rsi
call 0x20C #假设过程叫proc
proc:
irmoveq $10, rbx
ret
C:
mrmovq 0x7(%rbp), %rsp
nop
f0 # 非法的一个指令
popq %rcx
D:
loop:
subq %rcx, %rbx
je loop # je 0x400
nop
E:
xorq %rsi, %rds
pushq f0 # 这里错了, pushq 要求一个寄存器和,所以应该是[0~e]f
Y86-64异常#

对于Y86-64,当遇到错误时直接停止执行指令,在更完善的设计中,处理器会调用一个异常处理程序来处理某种类型的异常。
Y86-64程序#

上图给出了同样一段程序使用x86-64和Y86-64的对比。
- 由于Y86-64的运算指令只允许操作寄存器,不能操作立即数,所以,先使用
irmovq将用于更新long指针和long数据的立即数$8和$1保存到寄存器%r8和%r9中。同样。第8~9行中由于运算指令只能操作寄存器,所以先将内存数据移到了寄存器中。 - 由于没有
testq指令,这里使用了andq指令。Y86-64中andq也会设置条件码,同样的subq也会,所有运算操作都会。所以我们无需在test块中引入判断命令。
下图是完整的程序文件,包含初始化,程序结束等操作。

习题4.4#

如下是x86-64版本,阅读该代码。
rsum:
testq %rsi, %rsi
jle .L3
pushq %rbx
movq (%rdi), %rbx
subq $1, %rsi
addq $8, %rdi
call rsum
addq %rbx, %rax
popq %rbx
ret
.L3:
movl $0, %eax
ret
我们可以断定%rsi保存的是count,如果count为0了,就跳到.L3,返回0。
然后,就是常规操作,保存%rbx到栈帧
%rdi我们可以断定是start,那么(%rdi)就是*start,=
把start中起始元素存到%rbx
然后增加start,减少count
再次调用rsum
然后将结果与%rbx中之前的数据相加,放到返回值中
弹出栈数据,返回
翻译成Y86-64
rsum:
xor %rax, %rax
andq %rsi, %rsi
jle .L3
pushq %rbx
mrmovq (%rdi), %rbx
irmovq $8, %r8
irmovq $1, %r9
subq %r9, %rsi
addq %r8, %rdi
call rsum
addq %rbx, %rax
popq %rbx
ret
.L3:
ret
习题4.4/4.5#

对我来说有点难啊
原始代码
sum:
irmovq $8, %r8
irmovq $1, %r9
xorq %rax, %rax
andq %rsi, %rsi
jmp test
loop:
mrmovq (%rdi), %r10 # 这里%r10就是当前要加的数组元素
addq %r10, %rax
addq %r8, %rdi
subq %r9, %rsi
test:
jne loop
ret
4.4 使用条件跳转实现absSum
absSum:
irmovq $8, %r8
irmovq $1, %r9
xorq %rax, %rax
andq %rsi, %rsi
jmp test
loop:
mrmovq (%rdi), %r10
xorq %r11, %r11 # 将寄存器%r11置0
subq %r10, %r11 # 将%r10减去%r11放到%r11中
jle add # 如果是正数,也就是-x<=0 x>0,就直接相加
rrmovq %r11, %r10 # 如果是负数,将它的相反数保存到%r10
add:
addq %r10, %rax
addq %r8, %rdi
subq %r9, %rsi
test:
jne loop
ret
4.5 使用条件控制实现absSum
absSum:
irmovq $8, %r8
irmovq $1, %r9
xorq %rax, %rax
andq %rsi, %rsi
jmp test
loop:
mrmovq (%rdi), %r10
xorq %r11, %r11 # 将寄存器%r11置0
subq %r10, %r11 # 将%r10减去%r11放到%r11中
cmovg %r11, %r10 # 如果 -x > 0,x = -x
addq %r10, %rax
addq %r8, %rdi
subq %r9, %rsi
test:
jne loop
ret
不管是哪种方式,思路就是
subq取相反数,然后适当时候替换%r10。
逻辑设计和硬件控制语言HCL#
上面是对Y86-64指令集部分的描述,想要构建出一款支持Y86-64指令集的CPU,我们还要对硬件进行研究,包括比较功能是怎么完成的;逻辑和算数运算如何完成;寄存器的存储功能是如何实现的等一系列问题。这些问题的细节需要对数字电路有很深的认识才能完全了解,这里我们对相关知识的学习,就...emmmm...浅尝辄止好了,然后利用老天爷赏给我们的抽象能力来学习后面的知识。
抽象在计算机专业里简直太重要了,它允许我们在不了解你正在学习的知识的底层原理的情况下也能应用并从更高的层面了解该知识。人生苦短,我们没办法把每一个细节都学的十分明白,并且就算学明白了,你的理解也会被时间冲淡,所以,遇到问题大胆的抽象就好了。
逻辑门#
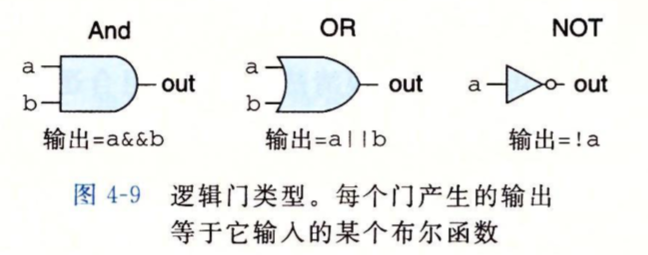
HCL中的逻辑门表达和C语言中的逻辑运算符一致,And的符号是&&,OR的符号是||,Not的符号是!。因为逻辑门是针对单个位来进行逻辑操作的,而不是对整个字进行逻辑比较,所以没有使用C语言中的&|~这三个运算符。
组合电路和HCL布尔表达式#
组合电路(Combinational Circuits)就是将很多逻辑门组合成一个用来计算的网。下图就是一个组合电路,它用来判断a和b是否相等。
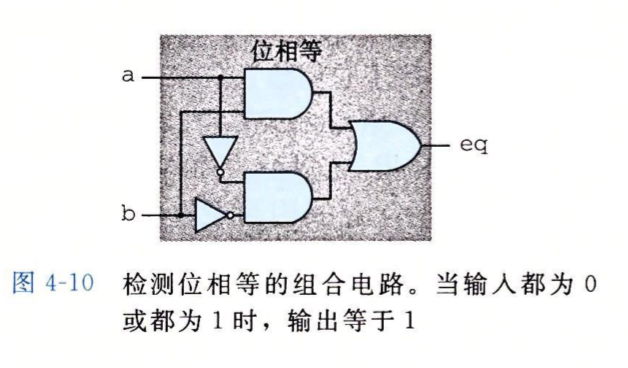
使用HCL布尔表达式来描述这个组合电路就是:
bool eq = (a && b) || (!a && !b)
组合电路的输出持续的响应输入的变化,不过输出会有一定的延迟。
下图是一个多路复用器,它的作用是从输入的a和b中选择一个作为输出,具体选择哪个由输入s控制。
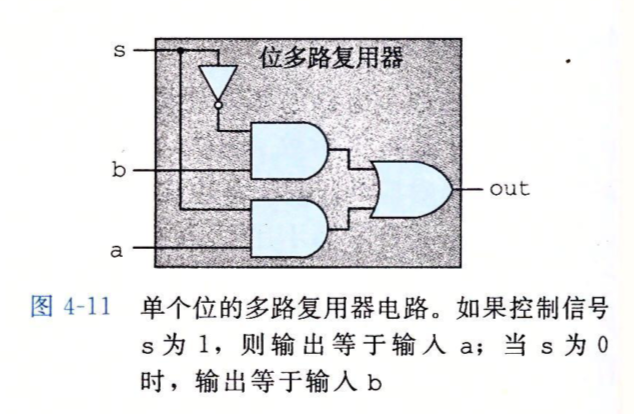
它的HCL表达式是:
bool mux = (s && a) || (!s && b);
练习题4.9#

异或的效果是当两个值不一样时才为1,否则为0,那么表达式可以写成
bool xor = (a && !b) || (!a && b)
它和eq是相反的,所以它也可以写成:
bool xor1 = !eq = !((a && b) || (!a && !b))
真值表
| a | b | xor | xor1 |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 0 | 1 | 1 | 1 |
| 1 | 0 | 1 | 1 |
| 1 | 1 | 0 | 0 |
字级组合电路和HCL整数表达式#
上面的所有数字电路的讨论都还停留在位级,下面我们来看看如何扩展到字级,否则我们连一个简单的数字运算都做不了。下图是一个判断两个64位数是否相等的电路,左面是该电路的实际实现,右面是该电路的抽象,它的输入端A和B已经是具有64位的整数了。
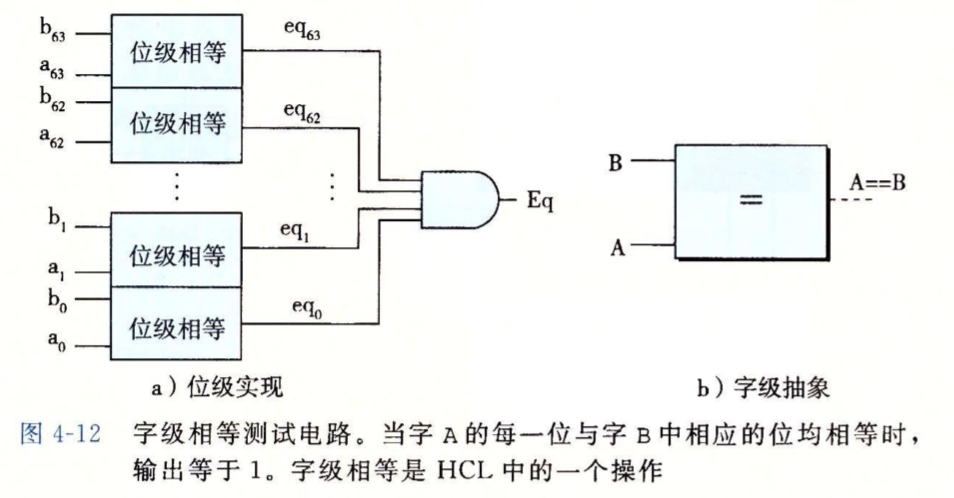
上面的电路也很好理解吧,数字相等的前提条件是它们的每一位都相等,所以只需要将每一位都使用之前的eq组合电路来判断并将得到的64个结果放到一个与门中即可得到最终的结果。这里又有两个抽象,我们省略了位级eq组合电路的实现细节,放心的将每一位输入传给它并期待得到预期的输出,还有最后的与门,这里我们给了这个与门64个输入端,而非我们最初学习的那样只有两个输入端。后面还会有好多这样的抽象,习惯它。
在HCL中,可以使用运算符==来比较字是否相等:
bool Eq = (A == B);
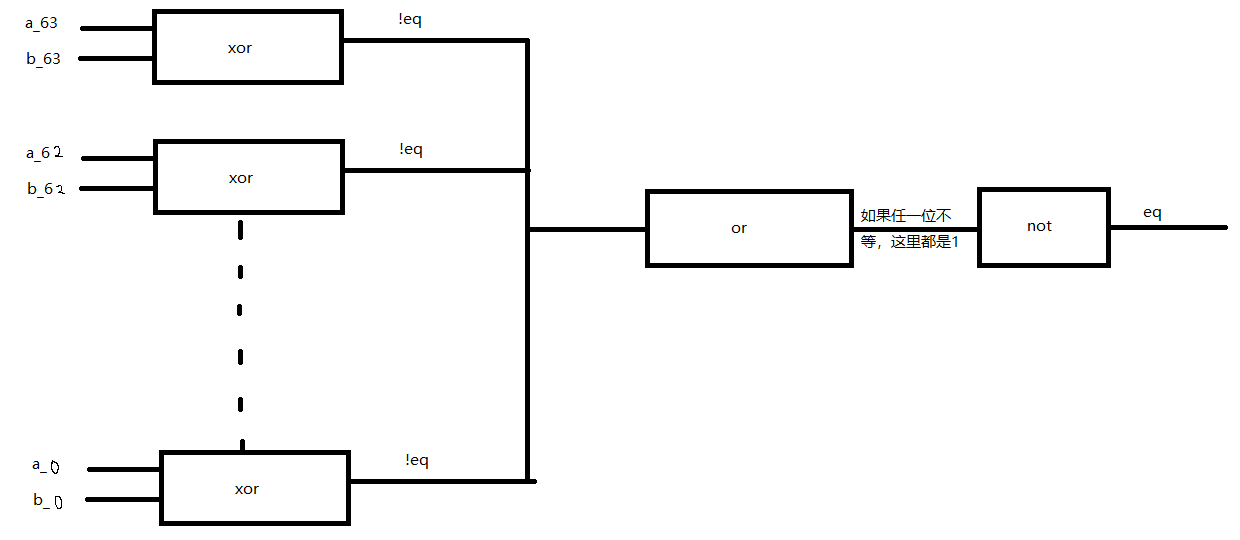
练习题4.10#

字级多路复用器与HCL表示#
无需解释,只是把64个位级的放在一起了,它的输入A,B和输出Out都是64位的字,输入s是位。
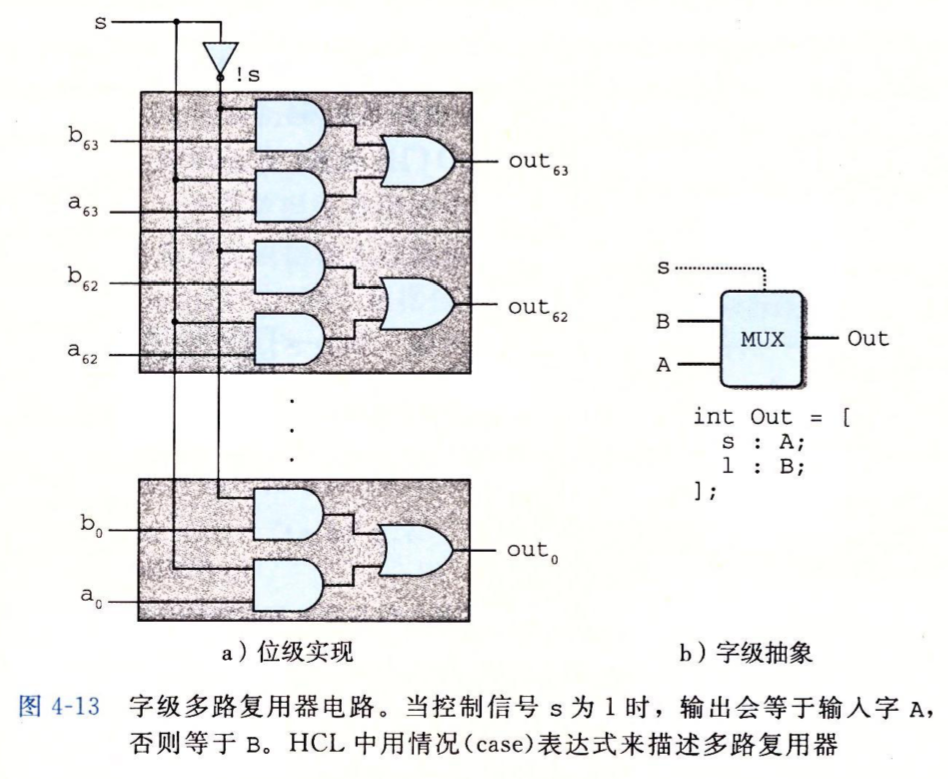
在HCL中,多路复用器使用情况表达式来表示:
[
select1 : expr1;
select2 : expr2;
select3 : expr3;
...
selectn : exprn;
]
情况表达式中不要求选择表达式之间互斥,这些表达式顺序求值,第一个求值为1的会被选中。下面是用HCL的情况表达式描述一个从三个数字中求最小值的逻辑电路:
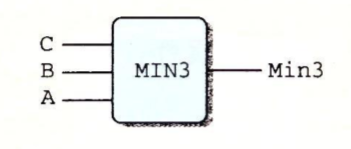
word Min3 = [
A <= B && A <= C : A;
B <= A && B <= C : B;
1 : C;
];
练习题4.11#

原始表达式:
word Min3 = [
A <= B && A <= C : A;
B <= A && B <= C : B;
1 : C;
];
简化表达式:
word Min3 = [
A <= B && A <= C : A;
B <= C : B;
1 : C;
];
由于第一行会检测是否A是最小的,走到第二行代表A肯定已经不是最小的了,所以第二行只需要检测B和C谁最小即可。
练习题4.12#

word Mid3 = [
A >= B && A <= C : A
A >= C && A <= B : A
B >= C && B <= A : B
B >= A && B <= C : B
1 : C
];
算数/逻辑单元(ALU)#
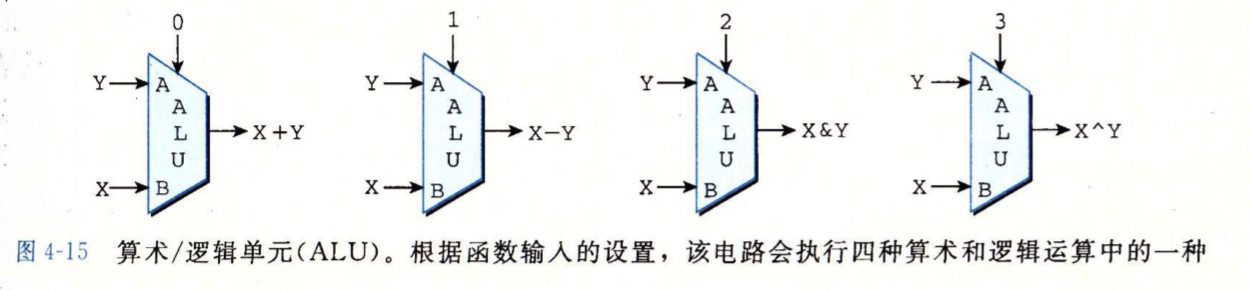
下面我们直接提供CPU中算数/逻辑单元(ALU)的抽象,不讨论其细节。ALU具有两个字输入AB作为数据输入,一个控制输入用于选择做哪种运算,下图四个ALU操作对应Y86-64中的四个算数/逻辑运算,addq,subq,andq和xorq
存储器和时钟#
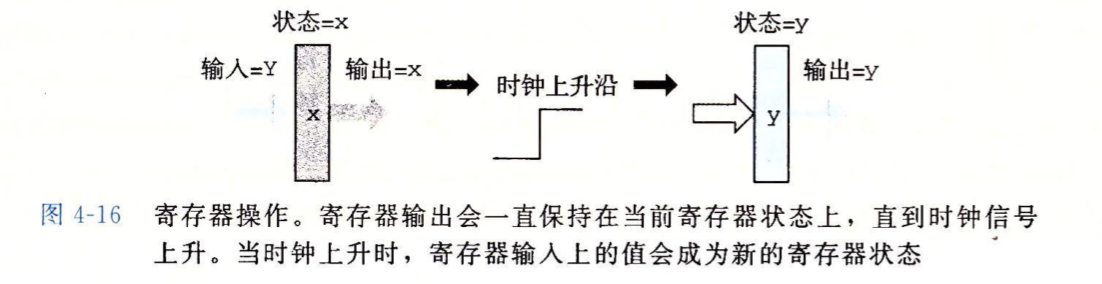
上面的组合电路中,输出端持续的反应输入端的电平变化,当输入端没有电平了,输出端也歇菜了。就是说它们无法起到存储数据的效果,时序逻辑电路(sequential circuit)是一种能够用于存储数据的电路,它们的输入中除了必要的参数外还要有一个额外的时钟参数,时钟是一个位,当时钟为0时,时序逻辑电路的输出端保持之前的输出而不管输入如何变化(这就相当于存储旧值),当时钟为1时,时序逻辑电路的输出端会通过输入端的一些参数产生新值(这就相当于加载新值)。
时序电路的实现细节大概就都是将输出端的状态反馈到输入端来实现存储的,具体的细节我们也不了解了,只需要读懂上面的粗体字,将时序逻辑电路、时钟的概念和用途了解清楚即可。这篇文章——《学习笔记:时序电路基础》是一个很好的时序电路基础入门。
我们把存储器设备分成:
- 时钟寄存器(简称寄存器):存储单个位或字
- 随机访问存储器(简称内存):存储多个字,用地址来选择读写的字
- 处理器的虚拟内存系统
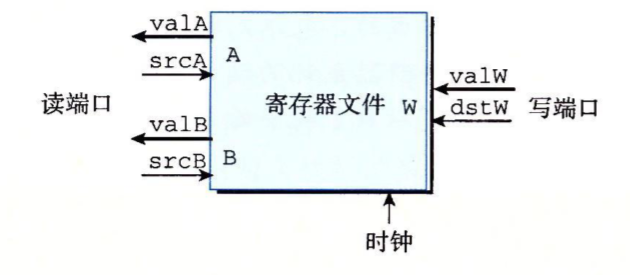
- 寄存器文件(在Y86-64中即从%rax到%r14那一批15个寄存器,物理上它们被放到一起,通过多路选择器来选择该操作哪个寄存器,所以把它们看成一个“文件”,而非我们所熟知的文件。有的资料中也称寄存器堆)
下图是时钟信号对寄存器输入和输出的影响,当时钟处于0时,尽管已经有了新的输入Y,从输出口读取寄存器的值还是之前的X,当时钟处于1时,输出才被更新。
下图是一个寄存器文件的抽象表示,读端口的valA和valB是从寄存器中读出的值,srcA和srcB是要读哪个寄存器,在Y86-64中,它们只需要4位。写端口也是一样,valW代表要写入的数据,dstW代表写到哪个寄存器。注意下面的时钟,存储设备都由同一个时钟控制。
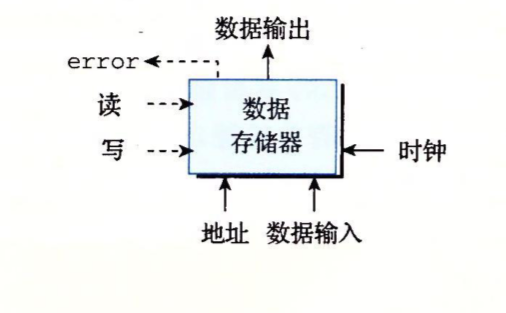
下面是一个内存的图示,内存需要两个读写输入来确定当前操作是读还是写(其实这里一个输入就够表示两种状态),地址输入是要读写的内存地址,数据输入是写操作携带的数据,数据输出是读操作读出的数据,error输出是错误。
Y86-64的顺序实现#
如果从没了解过底层知识,上面的可能有点难以消化,尽管我已经尽量把原书翻译的简单易懂了。如果上面的内容还有没懂的,不妨再看几遍,或者休息几天。
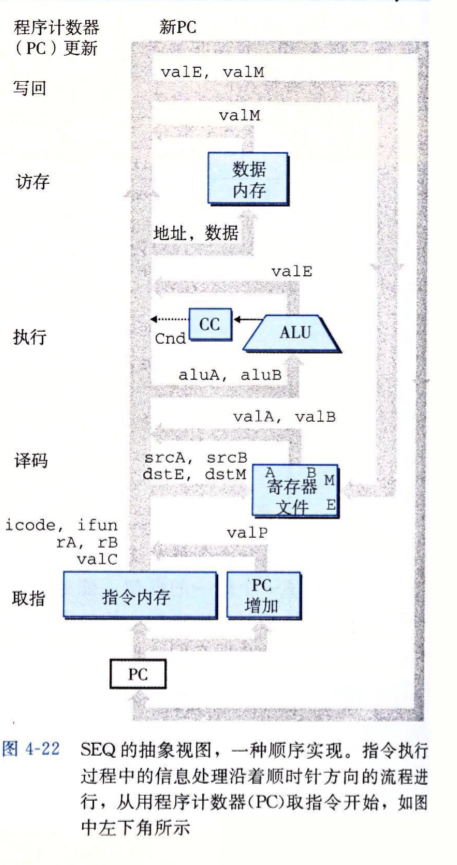
下面实现支持Y86-64指令集CPU的一个顺序实现,我们称之为SEQ处理器,顺序的意思就是每个时钟周期上SEQ执行处理一条语句的完整步骤。一条机器指令的执行需要很多步骤。程序员们通常会产生一种假象就是机器指令已经是指令的最小单元了,不可再分,但实际上对于硬件来说,处理器在一条指令上还有很多要协调的东西,所以,SEQ的顺序实现方式虽然安全,不会导致多条指令执行时数据错乱,但总是显得很慢。在稍后,我们会实现一个使用流水线技术的,性能更好的处理器。
一条机器指令执行的几个阶段#
- 取指:取指阶段需要访问内存,读取两个四位的指令和功能,称为
icode或ifun,然后根据指令和功能的不同,它可能从内存中读出两个寄存器指针rA和rB,有的指令还可能携带一个常数valC。取指阶段会计算按顺序的下一条指令的起始地址valP,它的值为PC计数器的值加上当前指令长度 - 译码:如果指令需要读取寄存器,译码阶段会读取指针
rA和rB所代表的寄存器中的值,得到valA和valB - 执行:算数/逻辑单元ALU执行必要的运算,这里包括执行指明的计算、增加或减少栈顶指针%rsp,这一阶段会得出执行结果的值
valE、该阶段也可能设置条件码 - 访存:该阶段可以将结果写入内存或从内存读出数据,读出的值为
valM - 写回:将最多两个结果写回寄存器文件中
- 更新PC:将PC设置成下一条要执行的地址,在一般情况下是设置成
valP,当当前指令是跳转指令,入call、jXX、ret等,更新PC的操作稍微复杂些
下面是一些顺序执行的Y86-64指令,稍后会把其中的一些指令放到上面的执行框架中来看它们究竟是怎么执行的:

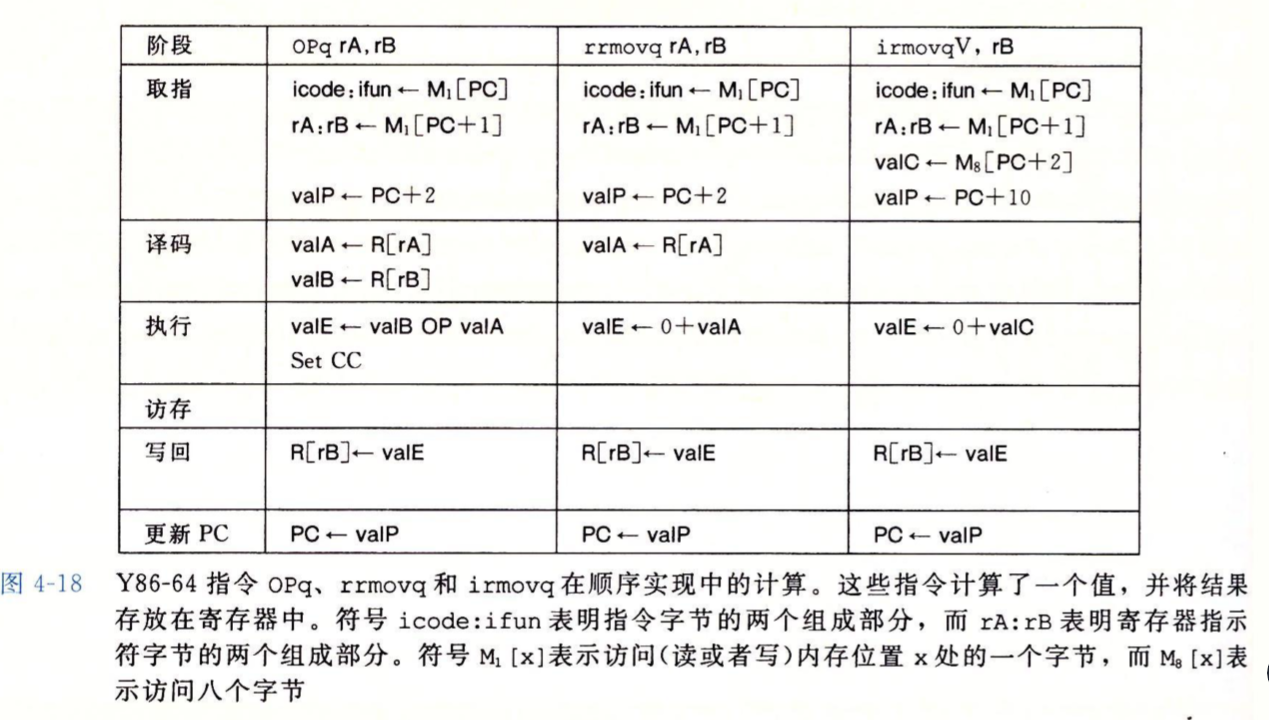
下面是OPq、rrmovq和irmovq的执行过程,我想只要将上面几个阶段搞明白了,下面的执行过程就无需多言,很容易看懂:
下面是跟踪图4-17中第三行代码subq的执行过程:

练习题4.13#
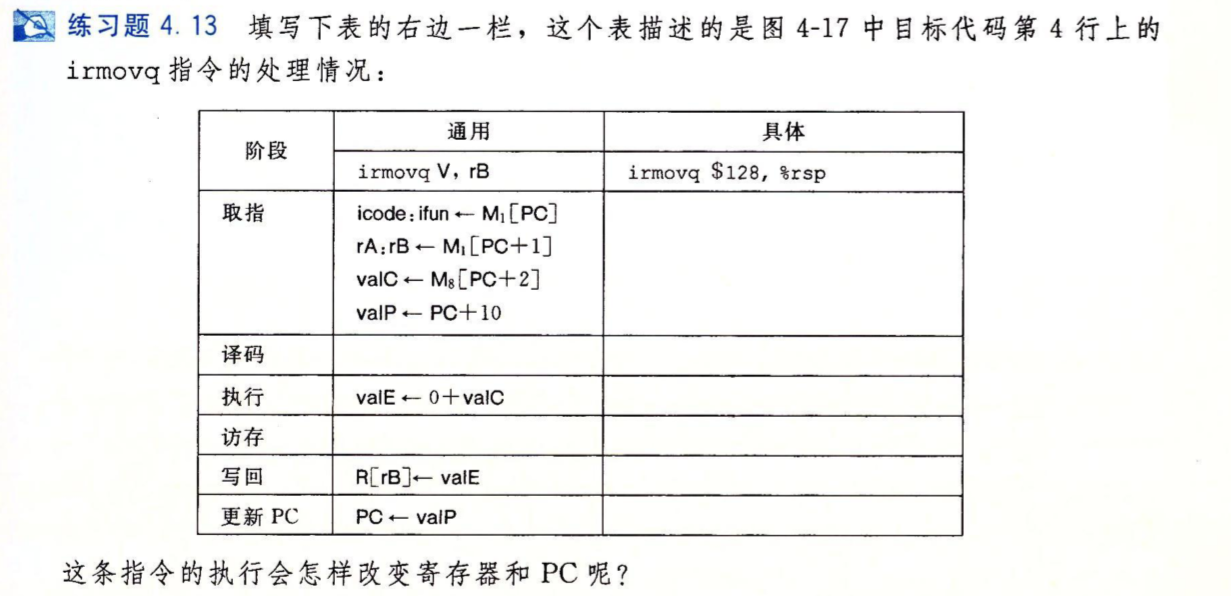

取指:
icode:fun <- M1[0x016] = 3:0
rA:rB <- M1[0x017] = f:4
valC <- M8[0x018] = 128
valP <- 0x016 + 10 = 0x020
译码:
执行:
valE <- 0 + valC = 128
访存:
写回:
R[rB] <- valE = 128
更新PC:
PC <- valP = 0x020
下面是pushq指令的执行过程

练习题4.14#
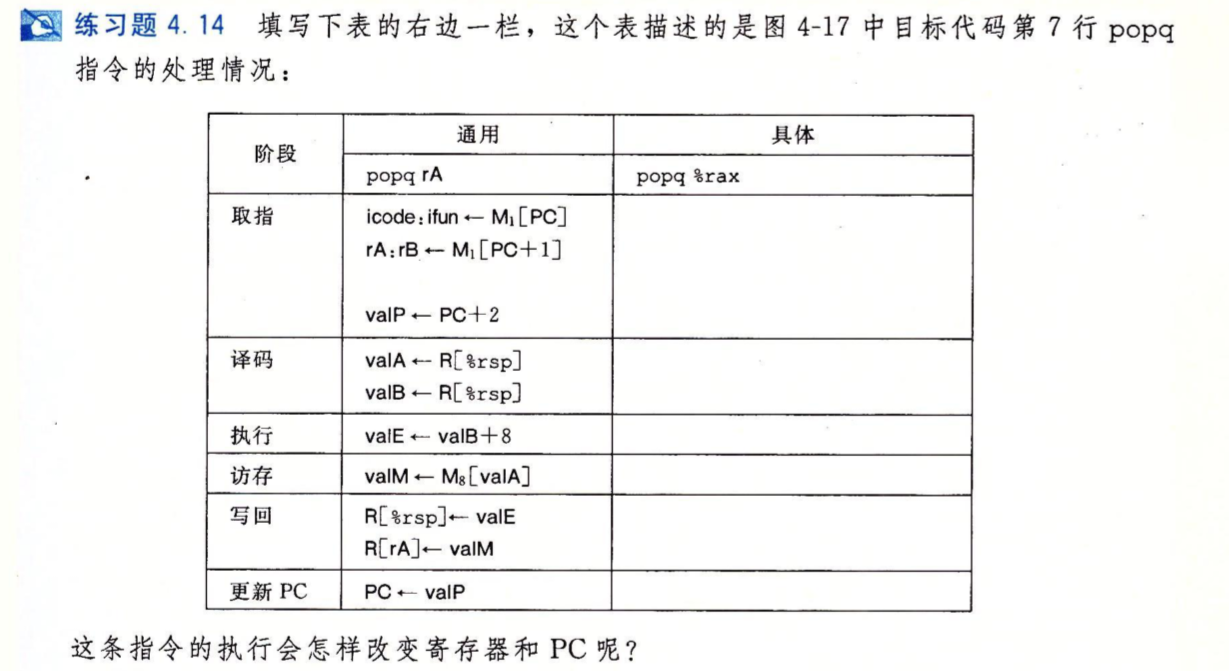
取指:
icode:ifun <- M1[0x2c] = b:0
rA:rB <- M1[0x2d] = 0:f
valP <- 0x2f
译码:
valA <- R[%rsp] = 120
valB <- R[%rsp] = 120
执行:
valE <- valB + 8 = 128 # 计算出栈弹出后的位置
访存:
valM <- M8[120] = 9 # 读取内存,拿出栈中数据
写回:
R[%rsp] = valE = 128 # 将%rsp设置到正确位置
R[rA] = valM = 9
更新PC:
PC <- valP = 0x2f
书中几乎跟踪了每一条指令的执行过程,这里我就不全放上了,其实都差不多,而且感兴趣的朋友自己将这些过程写出来是一件很有趣的事。
SEQ硬件结构#
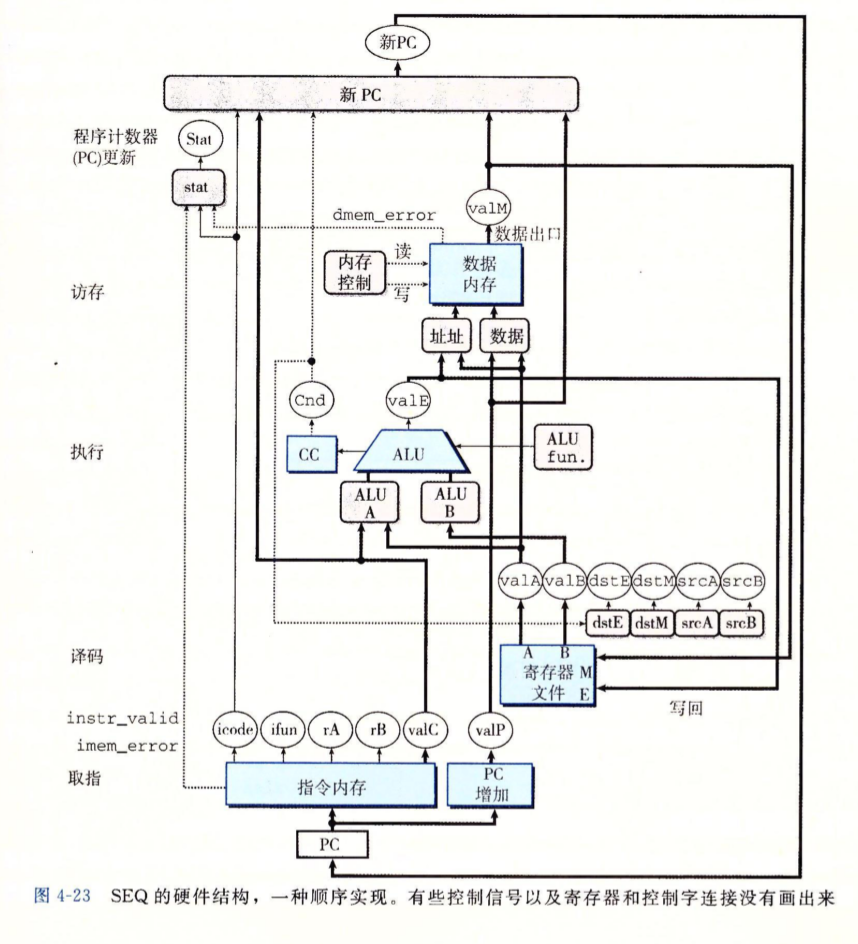
SEQ的时序#
我们还有一些疑问。
即,时钟上升沿时会将写入的数据更新,那如果我们一个指令的执行过程中中需要先写入一个寄存器数据,然后稍后我们还要依赖该寄存器的新状态时,这样的指令怎么在一个时钟周期内完成?(因为一个时钟周期中只有一个上升沿,指令更新的状态不会被当前指令再次读取时所发现)
不过当你仔细审视上面的那些指令执行过程时,你会发现Y86-64指令集中并没有这种指令。因为Y86-64指令集的设计遵循如下原则组织计算:
从不回读:处理器从来不需要为了完成一条指令的执行而去读由该指令更新了的状态
比如pushq指令没有选择先将%rsp减8然后再基于这个新的%rsp写入栈顶数据,因为它更新的%rsp在当前指令的时钟周期内不可见。push选择了将%rsp减8的值放到信号valE中,然后再用valE更新%rsp和写入内存。在下一个时钟周期上升沿,也就是下一个指令的时钟周期里,这两个更新将都会转化成可见。
作者:Yudoge
出处:https://www.cnblogs.com/lilpig/p/16262760.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
欢迎按协议规定转载,方便的话,发个站内信给我嗷~




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)