Redis实战——数据安全与性能保障
持久化选项#
Redis是一个内存数据库,但为了避免数据丢失,也提供了两种将数据持久化到磁盘的方式:快照方式和AOF方式(只追加文件)。这两种方式各有各的好处,主要看应用场景,而且它俩并不是非此即彼的,它们可以共同使用。
快照持久化#
快照持久化保存redis内存数据在某一时刻的副本,可以通过BGSAVE和SAVE指令来保存快照,BGSAVE在一个后台进程中将快照写入硬盘,SAVE则在Redis服务器的进程中写入,这导致Redis将不能服务新请求。
在redis配置文件中,配置快照的选项有这几个:
save 60 1000
stop-writes-on-bgsave-error on
rdbcompression yes
dbfilename dump.rdb
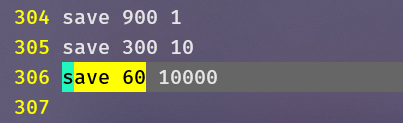
save 60 1000指定了从上一次保存快照开始,如果60秒内redis接收到了1000次写入,那么就自动触发BGSAVE来保存快照。下图中,redis使用了三个save:
- 60秒内收到10000次写入
- 300秒内收到10次写入
- 900秒内收到1次写入
stop-writes-on-bgsave-error on指定了在快照创建失败的情况下仍然继续执行写命令,rdbcompression yes指定了将快照文件进行压缩,dbfilename指定了快照文件的位置,在我这里是src/dump.rdb

更新丢失#
如果某些原因使得Redis异常退出,那么自从上一次更新快照之后的所有更新将丢失。
创建快照的办法#
- BGSAVE
- SAVE
- 配置文件中指定的自动save
- Redis正常退出(接收到关闭服务器的命令或标准的TERM信号),执行一个SAVE命令,阻塞客户端,不再接受任何请求,SAVE执行完毕关闭服务器
- 主从复制时,从服务器连接到主服务器后会执行SYNC命令同步数据,此时主服务器需要执行BGSAVE
AOF持久化#
当你的应用不能忍受快照持久化的数据丢失,可以使用AOF持久化。
AOF维护一个只追加的文件,当收到写入请求时,将这个命令追加到AOF文件的尾部。Redis只需要执行AOF中记录的所有内容便可以恢复文件中所记录的数据集。
AOF的相关配置如下
appendonly no
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
appendonly是是否开启AOF,appendfsync是何时将写入的文件flush到磁盘,可以选择always每条写指令、everysec每秒钟、no永远不显式同步。always不会丢失更新,但是它会产生大量的磁盘IO,影响Redis的速度,everysec会丢失一秒钟之间的数据,但它不会造成太大的性能下降,no不建议使用,因为何时将指令刷到AOF文件在这种情况下由操作系统决定,我们没法控制。
重写AOF文件#
AOF文件的体积会随着系统运行不断增大,重写(rewrite)操作创建一个子进程将AOF文件中冗余的指令去掉,将文件瘦身。
no-appendfsync-on-rewrite指定在重写AOF文件时是否可以向其中追加命令,官方推荐除了你有延迟问题之外,其它情况下都设置为no。auto-aof-rewrite-percentage指定了当AOF文件增长了多少百分比时进行rewrite,auto-aof-rewrite-min-size指定了要对AOF文件进行瘦身,它必须大于多少M,这两个是and关系。
主从复制#
Redis支持传统的主从复制
一台Redis服务器默认运行在master模式下,该模式是可读可写的。可以通过slaveof host port来连接一个主服务器,连接后,该台服务器变成slave模式,slave模式只读。可以使用slaveof no one来让当前服务器取消与主服务器的连接,重新运行回master模式。
当从服务器连接主服务器后,主服务器执行BGSAVE操作,即后台保存当前数据库的镜像,当这个保存操作完成后,主服务器会通过网络向从服务器发送这个镜像,并且在这期间,主服务器尽量接收并在缓存中处理新来的请求,等待传输结束,主服务器再将这些传输期间接受的命令发给从服务器。
当有新的写命令在主服务器执行,主服务器会向从服务器提交相同的命令。

使用Docker搭建Redis主从复制#
拉取redis容器
docker pull redis
运行两个redis实例,一个绑定在本地的20001端口,一个在20002端口
docker run --name redis-20001 -p 20001:6379 -d redis redis-server
docker run --name redis-20002 -p 20002:6379 -d redis redis-server
使用redis-cli连接这两个服务器
redis-cli -h localhost -p 20001
redis-cli -h localhost -p 20002
一会儿,我们使用redis-20001作为主服务器,现在查看主的ip地址
docker inspect redis-20001 | grep IPAddress
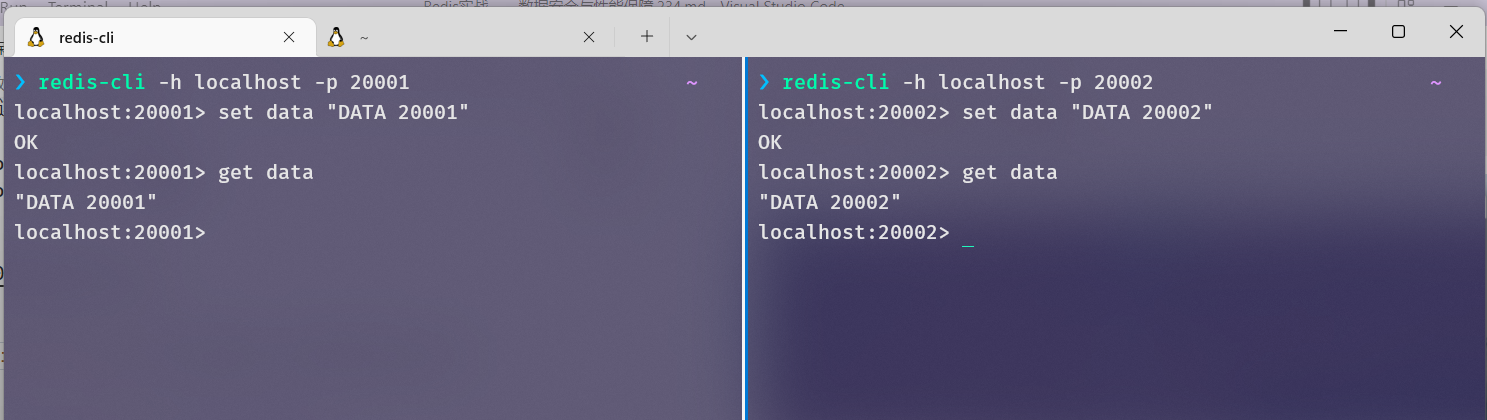
现在,我们分别在两台服务器中写入data
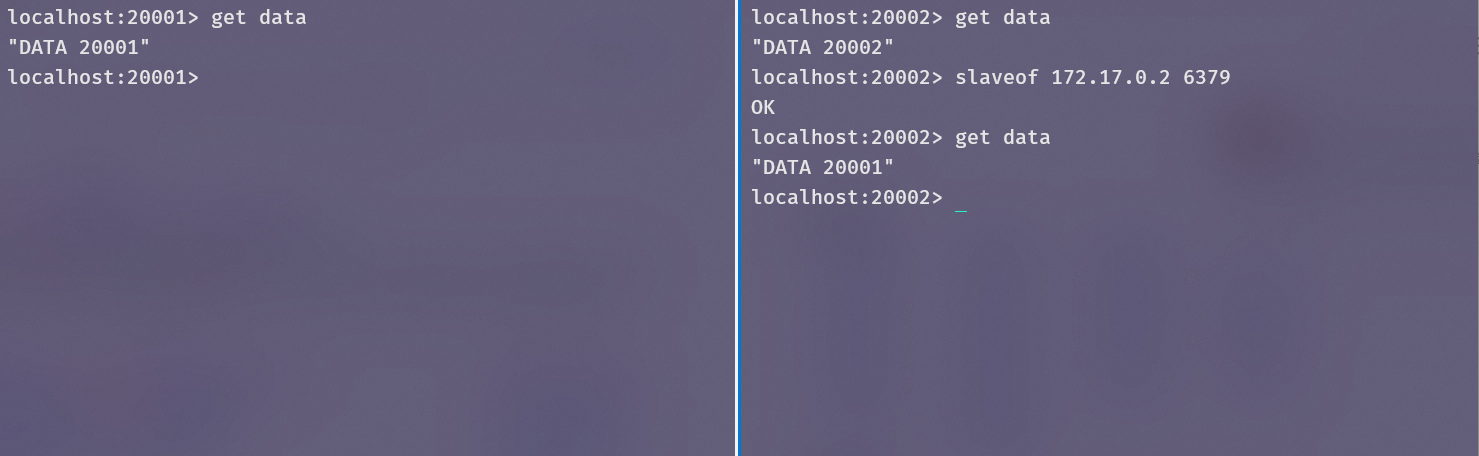
现在把redis-20002作为redis-20001的从服务器,再次获取data,已经刷新成主服务器的了
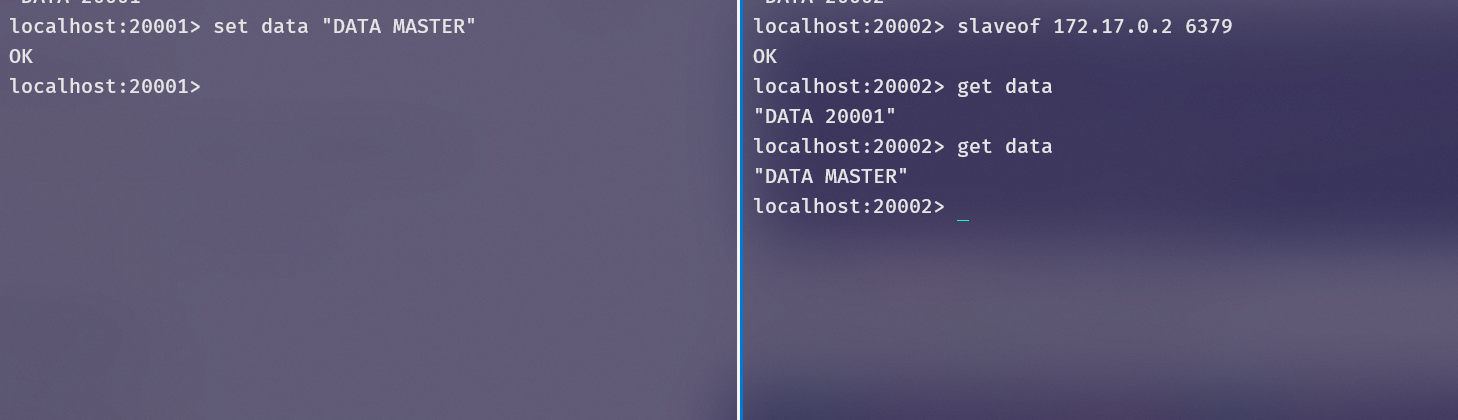
在主服务器中更新,发现从服务器也更新了
主从链#
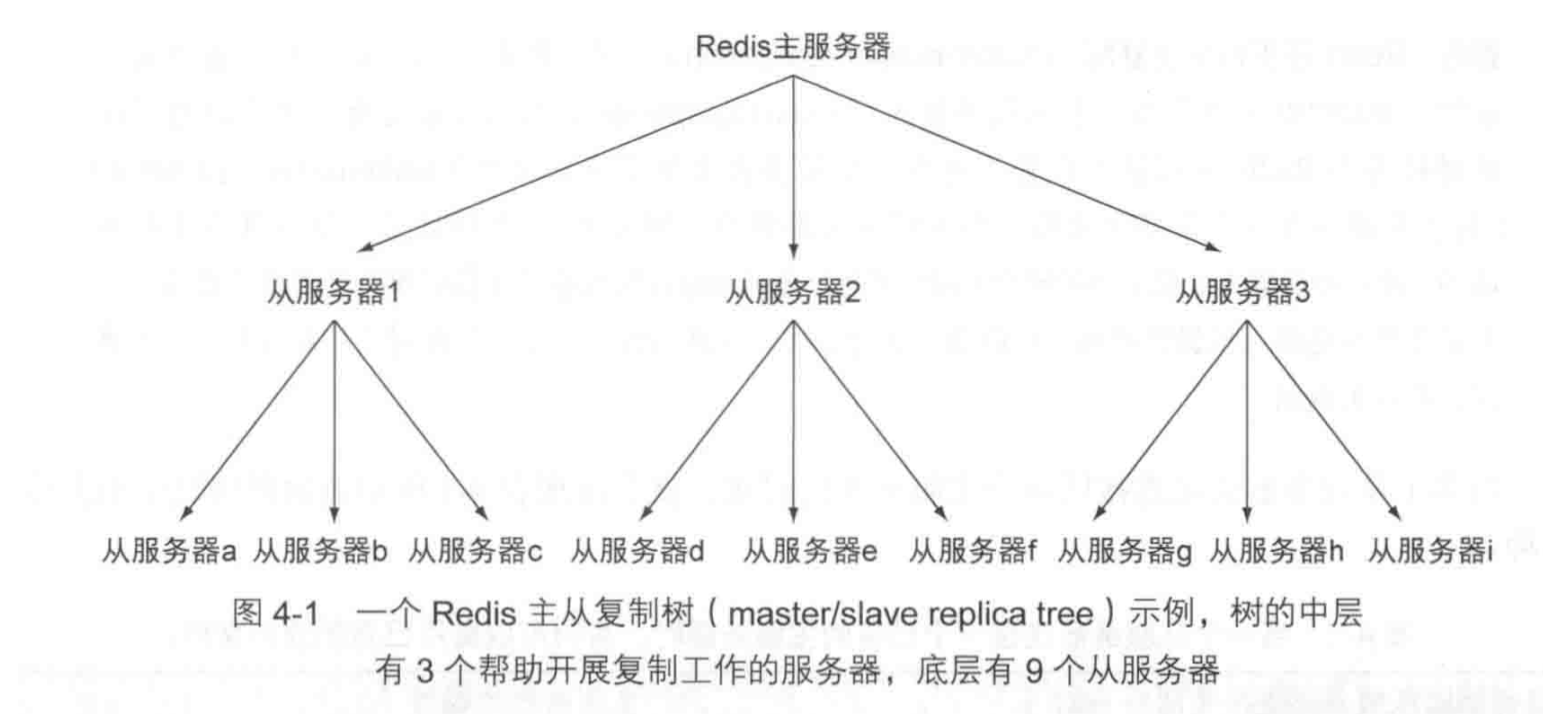
Redis的主服务器可以有多台从服务器来分享读取压力,但随着从服务器变多,主服务器向所有从服务器同步更新的压力越来越重。可以使用如下的树状或任何形状的多层主从复制结构构成主从链。
可以在每台机器上开启appendonly yes选项和appendfsync everysec来进行每秒一次的aof持久化。
处理系统故障#
验证快照文件和AOF文件#
在系统发生故障后,快照文件和AOF文件有可能处于损坏状态(考虑当更新这两个文件时系统发生断电),Redis提供了两个命令来检查这两个文件是否损坏。
-
redis-check-aof [--fix] <file.aof>,检查aof文件是否损坏,当--fix被指定,将aof中第一个不完整的命令到文件末尾的所有数据删除
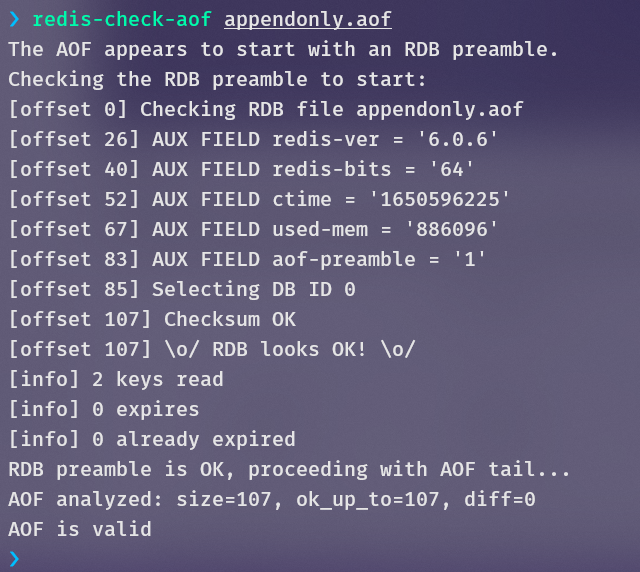
-
redis-check-rdb <file.rdb>,检查rdb文件是否损坏
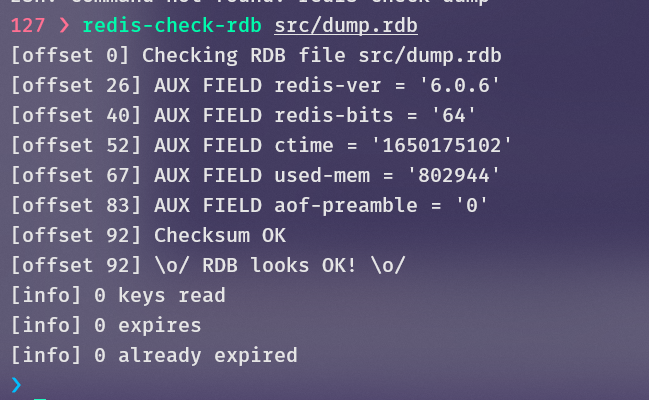
并没有办法可以修复出错的快照文件,可以通过备份多个并通过散列校验来更加保险的恢复数据。
更换故障主服务器#
现在假设,有服务器A和B,A是B的主服务器,这时候A坏了,我们可以通过在B上进行SAVE,然后把B的快照文件通过网络发给C,然后让C来代替A做B的主服务器。
创建两个容器实例,A和B
❯ docker run --name redis-server-A -p 20001:6379 -d redis
redis-server
d1a5bbc3e63dcb2205d218fb4e732c37c111fcf91c7aa7d947d40527f812d452
❯ docker run --name redis-server-B -p 20002:6379 -d redis
redis-server
ae32a8e8faf2ebffdbc9fdad293fedf03d9e3c0b9188d0b485c327f151d85f0e
获取它们的IP:
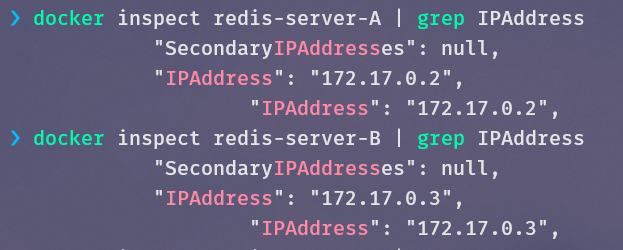
建立A和B的主从关系
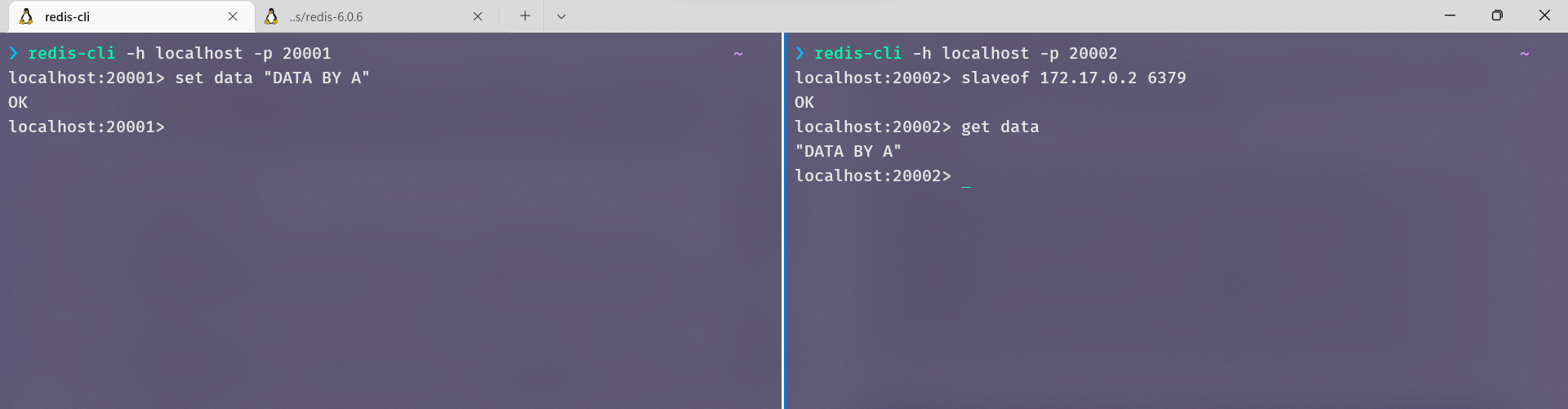
现在假设A崩溃,这里把容器A关闭了,B显示已经连不上主服务器了:
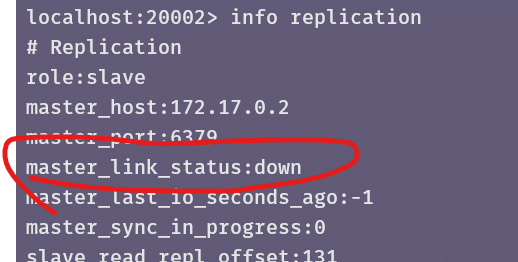
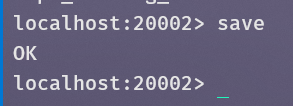
在B中使用SAVE保存快照:
将B中的dump.rdb文件拷贝到宿主机:
docker cp redis-server-B:/data/dump.rdb ./
创建容器实例C,并且将dump.rdb导入:
docker run -p20003:6379 --rm --name redis-server-C -v $(pwd)/dump.rdb:/data/dump.rdb redis
这里必须在创建容器时导入,先创建容器后覆盖这个文件没用。
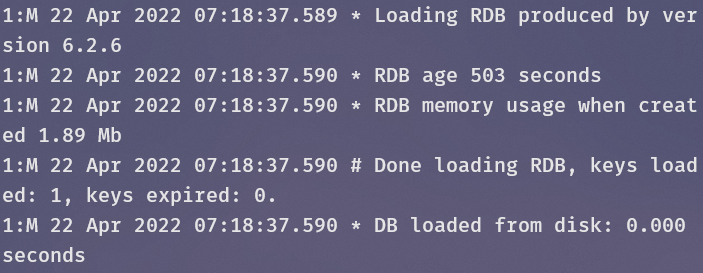
在容器C的启动日志中已经看到了它读取RDB文件的日志
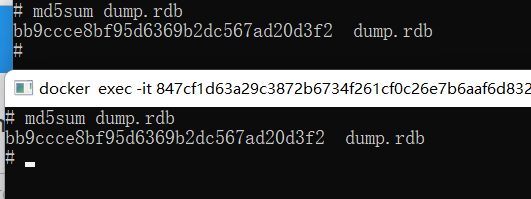
查看B和C的/data/dump.rdb二者的散列值相同,说明二者是一个文件
连接容器C,确实能获取到data
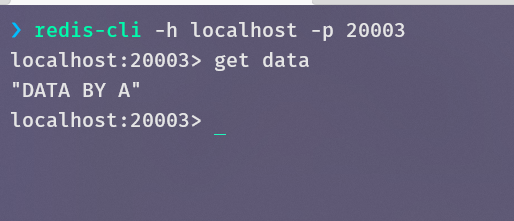
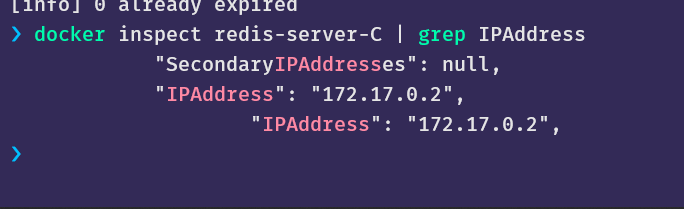
查看容器C的IP地址,它占用了A之前的地址
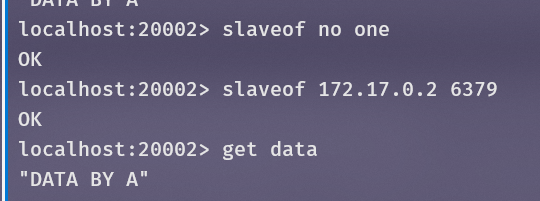
将B作为C的从服务器,并获取之前由A设置的值
Redis事务#
事务介绍#
这里书上对Redis事务的讲解非常少,上来就直接写了个案例导致很多地方不明不白的。我这里将官方文档中的部分内容翻译过来,作为前置知识。
Redis事务允许在单一步骤中执行一组命令,事务围绕着如下命令运行:MULTI、EXEC、DISCARD、WATCH。Redis事务具有如下两方面的保证:
- 事务中的所有命令都已被序列化并以顺序方式执行,一个来自其它客户端的请求永远不会在事务的中间执行,这保证事务中的命令可以作为一个单一的被隔离的操作执行。
EXEC命令会触发事务中所有命令的执行,所以如果一个客户端在一个并未执行EXEC命令之前的事务环境中丢失了与服务器的连接,那么所有命令都不会执行,相反,如果EXEC命令被执行了,所有的操作就都被执行了。当你使用append-only文件时,Redis使用一个write(2)系统调用来保证将事务写进磁盘中。如果Redis服务器崩溃或者被系统管理员意外结束,那么有可能只有部分的操作被记录了,Redis将在重启时检测到这个情况,退出并抛出异常。使用redis-check-aof工具可能可以修复append-only文件并移除不完整的事务语句来让Redis服务器正常启动。
在Redis2.2之后,Redis提供了比上面两条更多的保证——以一种非常类似于CAS的乐观锁形式。这篇文档的稍后会对此进行介绍。
事务使用#
使用MULTI指令进入一个Redis事务,这个命令总会返回OK,在这时,用户可以提交多条指令,为了执行这些指令,Redis会将它们放到一个队列中,所有的指令都会在EXEC被调用后执行。
和EXEC相反,调用DISCARD会刷新事务队列,并退出事务。
EXEC返回一组回执,即事务中每条指令的结果,它们的顺序与提交时相同。
当Redis连接在MULTI请求的上下文中时,所有的命令将返回QUEUED(已入队),一个已入队的命令将在EXEC被调用后被调度执行。
事务中的错误#
事务过程中可能遇到两种指令错误:
- 一个命令可能排队失败,所以调用
EXEC之前可能会有错误。比如一个命令可能存在语法错误或者服务器陷入了一些危险状态,比如内存溢出。 - 一个命令可能在
EXEC被调用后执行失败,比如我们错误的设置一个键的值(比如对一个字符串值调用列表指令)
Redis2.6.5开始,服务器可以检测到EXEC执行前的命令错误,它将在EXEC期间拒绝执行事务并返回一个错误,然后discard(丢弃)这个事务。在这之前,客户端需要手动检查每个命令是否返回QUEUED,当没有返回QUEUED,客户端需要手动DISCARD该事务。
EXEC执行之后的错误不会以某种(类似传统事务的)特殊的方式处理,即使事务中的某些指令执行失败,其他指令也会被执行。
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
MULTI
+OK
SET a abc
+QUEUED
LPOP a
+QUEUED
EXEC
*2
+OK
-ERR Operation against a key holding the wrong kind of value
比如上面的例子,事务中的第一个语句执行成功,第二个执行失败,服务器返回了两个结果,结果显示第一个语句并没有因为第二个失败而被放弃执行。
关于回滚#
Redis不支持事务回滚,因为事务回滚会给Redis的简单性和性能带来严重的冲击。
使用check-and-set的乐观锁#
WATCH用于给Redis事务提供check-and-set(CAS)行为。
被WATCH的键将被监视以发现它们的变化。如果至少有一个被WATCH的键在执行EXEC之前被改变了,整个事务都会被放弃,EXEC会返回空以示事务失败。
例如,想象我们有一个原子的将一个键递增1的需求(我们假设Redis没有INCR指令),我们要做下面这几件事:
val = GET mykey
val = val + 1
SET mykey $val
仅当我们在给定时间内只有一个客户端在执行该操作,上面的代码才能可靠的运行。如果多个客户端尝试同时递增这个键,将产生竞态条件。比如:客户端A和B都读到了旧值10,那么最终两个客户端都会调用SET将这个键更新为11,所以(在这种情况下)最终的结果是11并不是12。
感谢WATCH给了我们处理这种问题的能力:
WATCH mykey
val = GET mykey
val = val + 1
MULTI
SET mykey $val
EXEC
使用上面的代码,如果发现竞态条件并且其它客户端在我们调用WATCH和MULTI期间改变了该键,事务将失败。
(在事务失败的情况下)我们可以重复上面的操作并且祈祷这次不会有新的竞态条件,这种形式的锁称为乐观锁,多个客户端可能访问不同的键,所以冲突不会经常发生——通常情况下我们不用重复操作。
解释WATCH#
所以WATCH命令究竟是什么?它是一个让EXEC具有附加条件的命令:只有当没有被WATCH的键被修改时我们才能向Redis请求执行事务。这包括用户通过客户端执行的修改(比如执行一条命令)和Redis本身所做的修改(比如expiration和eviction)。
注意!!
- 在Redis6.0.9之前,一个过期的键不会导致事务失败
- 事务中的修改不会触发
WATCH条件,因为直到EXEC被发送时它们都还只处于排队状态
当EXEC被调用,所有的键都被UNWATCH,不管事务是否失败而被终止,并且在客户端连接关闭时,一切都被UNWATCH。
pipeline简要介绍#
Redis pipeline是通过一次提交多条指令,不用等待每条独立指令的回复来提高性能的一种技术。
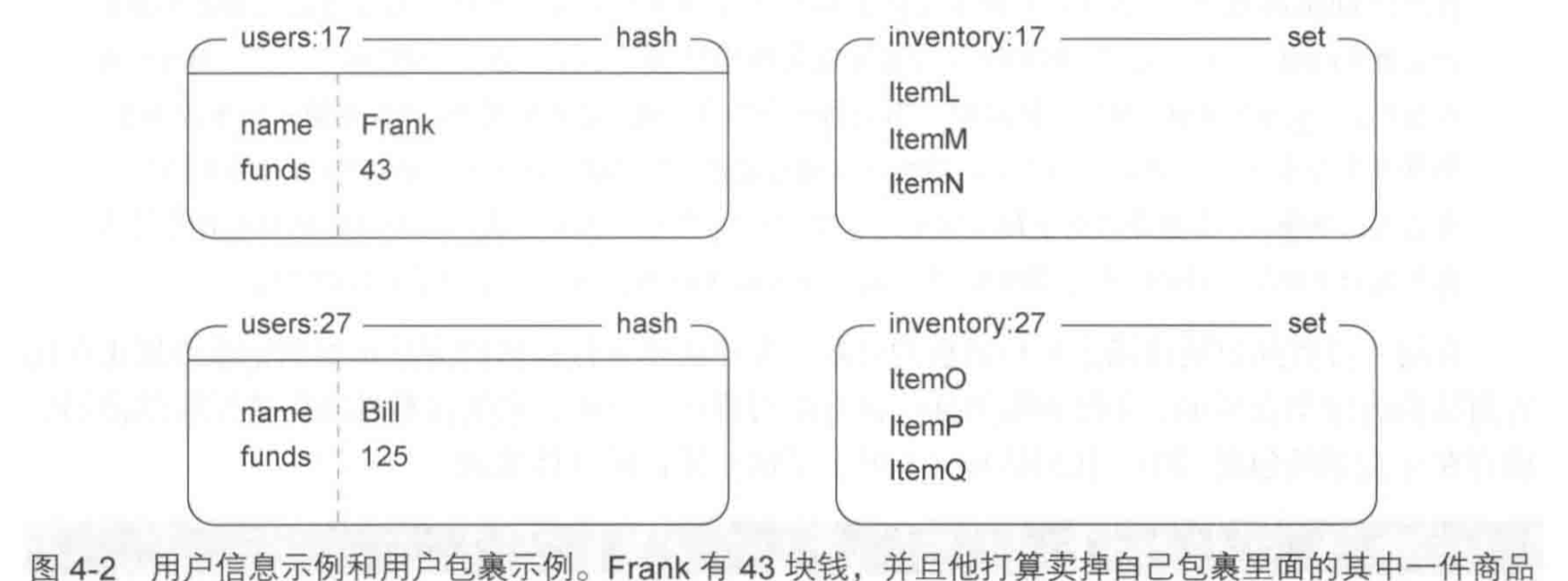
示例:游戏商品买卖市场#
每个用户的信息通过一个hash表来记录,用户仓库中的物品通过一个set集合来记录,用户id为UID的用户的表为users:UID,仓库为inventory:UID
市场使用一个zset有序集合market:来维护,目前只支持根据价格排序,集合中保存了平台中所有用户所需要销售的所有物品,对于一个用户UID,它想要以PRICE的价格销售物品ITEM,那么market:中有这样一条映射:ITEM.UID -> PRICE
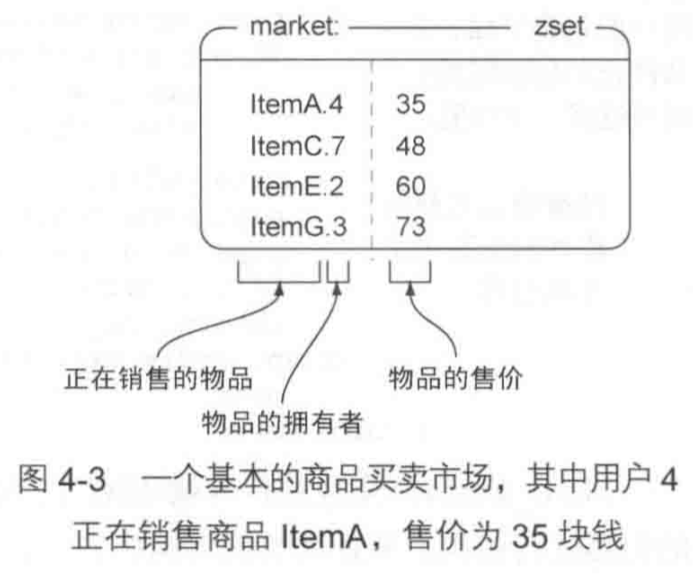
将商品放到市场上销售#
下面的代码用于将商品放到市场上销售,首先客户端开启了一个pipeline,然后客户端会监测是否用户的仓库被改动。下面,判断用户的仓库中是否有它正要销售的物品,如果没有就退出并UNWATCH。然后使用multi开启事务,事务中使用zadd向市场中添加这个物品,通过srem移除用户中这个物品。直到现在,我们都假设在我们前面的判断和EXEC之间该用户的仓库没被修改过,但是实际上这种情况是有可能发生的,所以在execute被服务器接到时,之前的WATCH能保证若仓库被修改过则失败,若仓库没被修改过则成功(注意这里监视的是整个仓库不是仓库中的一个物品)。外层的循环是在发生竞态条件导致事务失败时,在五秒钟之内进行重试。
def list_item(conn, itemid, sellerid, price):
invetory_name = "inventory:%s" % sellerid
market_item_name = "%s.%s" % (itemid, sellerid)
end = time.time() + 5
pipe = conn.pipeline()
while time.time() < end:
try:
pipe.watch(inventory_name, invetory_name)
if not pipe.sismember(itemid):
pipe.unwatch()
return None
pipe.multi()
pipe.zadd("market:", {market_item_name: price})
pipe.srem(invetory_name, itemid)
pipe.execute()
return True
except redis.exceptions.WatchError:
pass
return False
需要格外注意的就是那个unwatch操作,如果不做服务器会一直监视这个键。
事务不是已经提供原子性了吗?那我们就把检测的代码放到事务中不好吗?别忘了,事务只有当
EXEC后才会被一次性的执行,在这期间你没有像传统关系型数据库的那种查询某些值的能力,因为所有命令只会返回QUEUED。
购买商品#
def purchase_item(buyerid, itemid, sellerid, lprice):
buyer = "users:%s" % buyerid
seller = "users:%s" % sellerid
market_item_name = "%s.%s" % (itemid, sellerid)
buyer_inventory_name = "inventory:%s" % buyerid
end = time.time() + 10
while time.time() < end:
try:
pipe = conn.pipeline()
pipe.watch(buyer, "market:") # 如果购买者信息发生变化(资产发生变化)或者市场发生变化(要买的商品已经被买走)
buyer_funds = int(pipe.hget(buyer, "funds"))
price = pipe.zscore("market:", market_item_name)
if price != lprice or buyer_funds < price:
pipe.unwatch()
return None
pipe.multi()
pipe.hincrby(buyer, "funds", -int(price))
pipe.hincrby(seller, "funds", int(price))
pipe.sadd(buyer_inventory_name, itemid)
pipe.zrem("market:", market_item_name)
pipe.execute()
return True
except:
pass
return False
非事务型流水线#
很多时候我们期望通过打包执行命令来减少消耗在网络通信中的时间,这时我们会使用pipeline。
如果你使用redis-py库,那么默认情况下,pipeline将缓冲你的所有命令,直到你调用pipeline.execute,你的所有命令将被打包进一个事务(使用MULTI和EXEC包裹)并发一起发送给服务器。
>>> import redis
>>> conn = redis.StrictRedis(host="192.168.50.2", port=6379, db=0)
>>> pipe = conn.pipeline()
>>> pipe.set("A", "12")
Pipeline<ConnectionPool<Connection<host=192.168.50.2,port=6379,db=0>>>
>>> pipe.get("A")
Pipeline<ConnectionPool<Connection<host=192.168.50.2,port=6379,db=0>>>
>>> pipe.execute()
[True, b'12']
注意,在这里,get操作由于被缓冲,所以你并不能获得A的值,只有当execute时它们才被实际的执行,并且它们的返回值以数组形式被返回。但我们上面的代码中明明使用各种获取操作来检查仓库和用户是否有足够的钱了啊!这个问题一会儿会说。
所以,默认情况下,pipeline就会保证其中所有命令的原子性,因为它们被包裹在一个事务中。但是事务是有性能损耗的,有时我们并不希望保证我们的命令在一个事务中且具有原子性,可以通过调用pipeline时传入False来取消它的事务性,这称为非事务型流水线。
>>> pipe = conn.pipeline(transaction=False)
>>> pipe.set("A", "12")
Pipeline<ConnectionPool<Connection<host=192.168.50.2,port=6379,db=0>>>
>>> pipe.get("A")
Pipeline<ConnectionPool<Connection<host=192.168.50.2,port=6379,db=0>>>
>>> pipe.execute()
[True, b'12']
可以看到,虽然取消了事务性,但pipeline还是会将所有语句打包执行,只是不使用MULTI、EXEC包裹,你也不能获得A的值。
我们经常希望能够检索某些值,而且这些需要能够检索值的需求往往与WATCH一同出现。所以,在redis-py中,当你使用pipe.watch,立即执行模式被打开,客户端不会缓冲你发起的命令,而是立即进行执行,此时,事务和原子性也没法得到保证。
而这种原子性往往在你执行multi时又被需要,所以当你执行pipe.multi,客户端会回到缓冲执行模式,它缓冲你的所有命令并等待execute时去执行。
>>> pipe = conn.pipeline()
>>> pipe.watch("A")
True
>>> pipe.get("A")
b'12'
>>> pipe.multi()
>>> pipe.get("A")
Pipeline<ConnectionPool<Connection<host=192.168.50.2,port=6379,db=0>>>
>>> pipe.execute()
[b'12']
>>>
参考#
作者:Yudoge
出处:https://www.cnblogs.com/lilpig/p/16179141.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
欢迎按协议规定转载,方便的话,发个站内信给我嗷~




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· winform 绘制太阳,地球,月球 运作规律
· 上周热点回顾(3.3-3.9)