Java并发——性能与可伸缩性
本篇博文是Java并发编程实战的笔记。
对性能的思考
性能与可伸缩性
可伸缩性是衡量并发程序性能的一个指标,可伸缩性指的是:当增加计算资源时(CPU、内存、存储容量或I/O带宽)程序的吞吐量或处理能力也相应的增加。
另外的一些指标比如:服务时间、延迟时间、吞吐率、效率和容量等。
和单线程程序中所说的“性能”不同,在并发程序中,我们通常比较注重可伸缩性,而实现可伸缩性需要将一个任务做一定程度的分解(比如将一整个单体后端程序拆成MVC三层),而这些分解一定会比不分解的情况下带来更多的性能开销。但如果不追求可伸缩性,单独追求性能而使用较大的单体系统来完成程序的话,在该系统到达性能瓶颈时想要扩展就会变得困难。
评估各种性能权衡因素
- “更快”的含义是什么
- (如果要优化的话)该(优化)方法在什么条件下运行的更快?在低负载还是高负载的情况下?大数据集还是小数据集?能否通过测试来验证你的答案?
- 这些条件在运行环境中触发的概率?
- 在其它不同条件的环境中能否使用这里的代码?
- 在实现这种性能提升时要付出哪些隐含代价?如增加开发风险或维护开销?这种权衡是否合适?
避免不成熟的优化。首先使程序正确,然后再提高运行速度——如果它运行的还不够快。
Amdahl定律
即使在并发程序中,也一定存在着某些显眼或不显眼的串行部分。对于并行部分来说,在一定范围内增加线程数量是会带来正收益的,对于串行部分来说,不管你有多少CPU,你创建了多少线程,不可能有两个线程同时踏足这个部分,所以这部分是不会因为你创建多个线程而得到任何提升的。
Amdahl定律给出了你在增加计算资源(CPU、线程)的情况下,程序理论上能够获得的最高加速比:
当N趋近于无穷大时(也就是说你有无限个处理器),最大加速比趋近于\(1/F\),也就是系统中必须以串行执行的任务比例的倒数。如果程序中有\(50/100\)的计算需要串行执行,那么最大加速比只能是\(100/50=2\)。
假设,你那些可以并行执行的部分的执行根本没花时间,那你还有一半儿的任务必须以串行方式(以原来的速度)执行并结束,那怎么可能将程序加速到原来的两倍以上呢?
下图是在程序中的串行部分所占用不同比例下的最高CPU利用率,利用率的定义为最高加速比/CPU个数:

所以,由于程序中存在串行部分,即使它们只是很小一部分,一味的增加CPU数量也会导致分配到每个CPU上的利用率越来越低。所以扩展CPU只是带来性能提升的一部分,另一部分是要设法减少程序中的串行部分。
根据上一段的理论来说,那些串行部分多的程序的可伸缩性都不是太好,在相应的加大处理器数量后,由于利用率降低,它们的性能可能并未得到什么太大的提升
并行程序中一定有串行部分,即使它们的工作毫不相关,但它们也一定会产生某种结果或者效应,比如输出到日志文件、保存到某种数据结构,合并计算。
线程引入的开销
除了串行部分带来的问题外,线程本身也会引入一些开销
上下文切换
如果可运行的线程数量大于系统中的总处理器数量,那么不同的线程将会切换执行,使得其它线程可以使用CPU的处理能力。这个切换需要保存线程当前的各种状态,并将新线程加载进CPU中。除此之外,在线程调度过程中还需要操作系统和JVM的配合,它们也需要使用一些CPU的时钟周期。
当线程阻塞时,JVM通常会将它挂起并允许它被交换出去,这里说通常是因为JVM在短时间阻塞的情况下可能采取更加保守的方式(如自旋),但通常线程越多的发生阻塞,上下文切换就越频繁。
内存同步
synchronized和volatile为保证内存可见性会使用内存栅栏,它们会将工作内存中的缓存刷回主内存以保证可见性。内存栅栏会抑制编译器进行某种优化操作,所以也会对性能有一些间接的影响。
有些时候你为了保证你的类的线程安全,你对某些位置加了锁,但调用者可能在完全无竞争的条件下使用你的类,这时JVM会做出一些优化,使得这个加锁操作很快完成或者直接去掉这个锁。
所以我们不必太担心不会产生竞争的锁带来的性能开销。
阻塞
减少锁的竞争
串行操作会降低可伸缩性,上下文切换会降低性能。在锁上发生竞争会同时导致这两种问题:
- 锁会产生程序中必须串行的代码段
- 锁会产生阻塞,从而导致上下文切换(和一些其它的性能影响)
我们将从锁的请求频率和每次持有锁的时间这两个因素上来优化以减少锁竞争。
缩小锁的范围
下面的代码userLocationMatches方法整个加上了锁,这导致所有线程必须串行的执行这个方法,并产生阻塞。但实际上,只有attributes.get这一个操作才需要加锁,其它操作根本无需加锁。

修改后:

由于在AttributeStore中只有一个状态,我们可以将这个状态的维护委托给线程安全的容器来实现,比如Hashtable、ConcurrentHashMap,这样就可以进一步缩小访问Map期间的加锁范围,并降低将来的代码维护者无意破坏线程安全性的风险。
注意缩小的范围一定不能小于你要在方法中保证原子性的范围
降低请求频率
降低请求频率可以通过减小锁的粒度实现,通常有两种办法,核心思路就是将原本使用一个锁来保护的部分变成多个锁,它们来保护之前需要保护的范围的一个子集,这样每个锁被请求的频率降低了。
锁分解
下面的代码,user和query的逻辑并无关系,但它们都使用同一个锁进行保护,这将导致访问user和访问query之间需要串行。

下面将它们分解成两个锁:

锁分解的一个前提条件是,目前要保护的范围中有多个独立的变量。
锁分段
个人感觉锁分解只是一个好的编码习惯,它并不能改变什么。对于单独的一个锁上的激烈的竞争,它还是没办法。
ConcurrentHashMap采用了另一个思路,它维护16个锁,每个锁保护散列桶的1/16。如果散列函数均匀的话,这就将原来的单个锁上的请求频率降低到了原来的1/16。
锁分段导致的一个问题是对于跨段的数据的访问不好管理,复杂且开销更加高,如果你的类和ConcurrentHashMap一样大部分情况下只需要访问其中的一个段,那问题不是太大。
下图是书上的一个自己实现的基于分段锁的HashMap,它的大部分操作都只获取其中的一个锁,只有clear操作时才获取每个锁。

避免热点域
考虑你实现一个HashMap的size方法,你会怎么实现?
你肯定不是每次调用size的时候去计算里面所有的元素,你会维护一个域,在put时将这个域加一,在remove时将它减一。在单线程或使用单一锁的实现中可以,但是如果使用上面的锁分段技术,在修改size这种范围覆盖到每个段的域时也要获得全部的锁或者一个独占锁,但是put和remove操作都需要访问到size,这会使得size这种热点域的维护重新成为了系统可伸缩性的瓶颈。
ConcurrentHashMap为每一个段维护一个自己的size,在使用size方法时将它们进行简单的加和。
一些代替独占锁的方法
- ReadWriteLock
- 原子变量
原子变量采用操作系统的底层并发原语(如CAS)实现了对单个整数操作的细粒度原子性保证
检测CPU的利用率
向对象池说不
当线程分配新对象时,基本不需要在不同线程间进行协调,而对象池则需要各种协调机制来复用池中的对象,Java中目前的内存分配开销比产生阻塞后的开销小得多。
所以复用对象带来的性能提升和它带来的可伸缩性变差,需要进行权衡
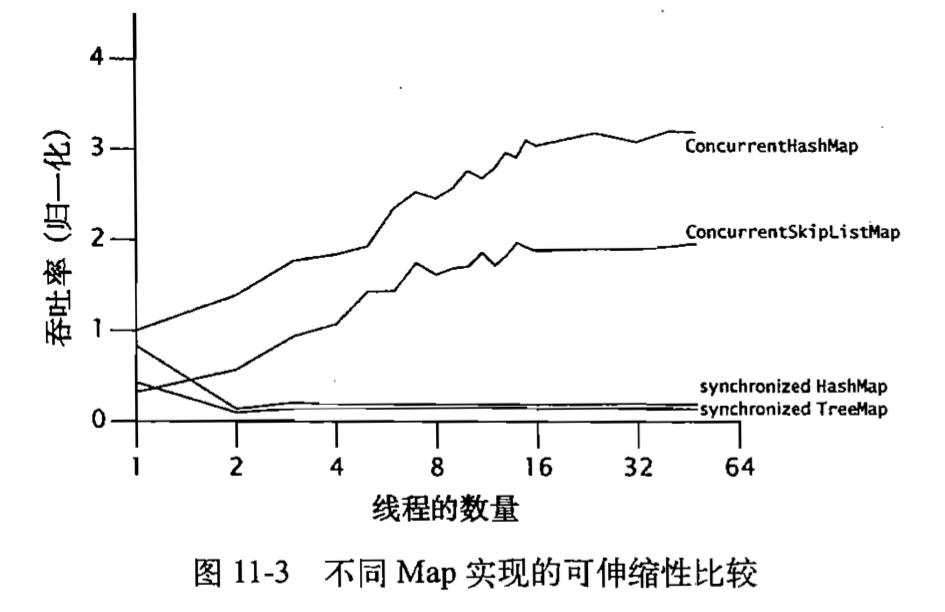
不同Map实现可伸缩性的比较

 浙公网安备 33010602011771号
浙公网安备 33010602011771号