并发:死锁和饥饿
原书《操作系统精髓与设计原理——富兰克林》第六章。
死锁的产生
死锁的产生就是由于一些进程对一些互斥资源不合时宜的访问。
资源可以是IO设备啊、内存单元啊、CPU啊、文件等,一个进程通常都是获取它们,然后运行一段事件,释放它们,并且当一个进程获取它们的时候其他进程不允许获取。有些类型的资源有多个实例,每一个实例可以被一个进程占用。
我们可以根据进程和系统中的资源进行建模,来绘制资源分配图。下图a,一个进程指向一个资源,这代表该进程请求获取该资源。图b,一个资源指向一个进程,这代表该资源已经被该进程占有。
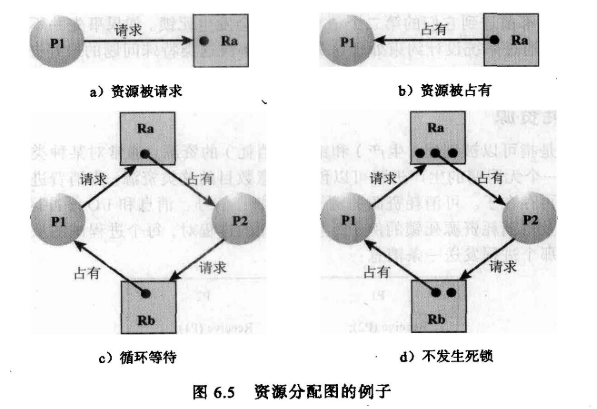
图c是一个死锁的例子,进程P1请求资源Ra,但资源Ra被P2占有,所以P1需要等待P2释放,而P2又请求了资源Rb,Rb又被P1占有,所以现在的局面就是P1等待P2释放Ra,而P2想要释放Ra必须要P1先释放Rb,这样系统就陷入了无尽的等待中。
图d不是死锁,虽然它的情况看起来和图c一样,但是不同的是资源Ra有3个实例,资源Rb有2个实例,所以进程P1和P2都无需等待对方释放资源。
死锁条件
产生死锁的必要条件有四个:
- 互斥:即不同的进程在同时访问互斥的资源
- 占有且等待:在一个进程正在等待其他进程的同时,继续占有已经得到的资源
- 不可抢占:不能强行抢占某个进程已有的资源
- 循环等待:存在一个封闭的进程链,使得每个进程至少占有此链中下一个进程所需要的一个资源
我们注意到第四个条件如果在前三个条件满足的情况下,这四个条件就会构成死锁的充分必要条件。
死锁的解决办法
死锁的解决办法无非三种,死锁预防,死锁避免和死锁检测恢复。
死锁预防和死锁避免有一些区别,虽然字面上看起来是一样的。死锁预防是预先采取某些办法让系统根本不会出现死锁,死锁避免是每次调用一个进程进程时动态判断,若系统认为调用该进程有可能出现死锁,就不调用它。死锁预防比死锁避免更加严格,并且死锁避免比死锁检测和恢复更加严格。死锁检测和恢复允许系统中出现死锁,只不过每过一段时间系统会检测,检测当前是否存在不安全状态(可能出现死锁的状态),若存在则采取一些恢复措施。
对于死锁的解决,并不是越严格越好,就如同数据库中是否应该实现完整的ACID特性,是否应该100%遵循范式设计是一样的。更加严格的解决办法带来的往往是更复杂的算法、更低的并发度和性能,我们往往要在性能和出错之间做一些权衡,在不出现非致命错误的前提下尽量保证性能。
有趣的是我在看本章时有些疑惑,所以去看b站的清华大学操作系统公开课,那位老师说当今我们使用的通用操作系统面对死锁的问题都是放着不管,它们假设系统中不会出现死锁。因为现存的死锁解决办法的成本在面对通用操作系统的需求时显得都比较高。
死锁预防
预防死锁,只需要打破我们上面所说死锁充分必要条件中的一个,当条件不充分,死锁自然不可能形成。
互斥
在互斥上别想做什么手脚,这些资源必须被互斥访问,最多它们可以被同时读,但是对于写操作必须和任何其它操作互斥。
占有且等待
如果一个进程可以一次性请求所有需要的资源(可能类似不可分的原子操作?),就不会发生它占有一部分资源但它还在等待其他资源的情况。但是程序对资源的访问往往是动态的,它可能起初只需要一部分资源就可以使用,如果一开始就让它获取它所有的资源,有一些资源可能并不能立即得到利用,但其他进程还不能访问这些资源。这造成了严重的浪费。
数据库系统为了使用锁保证事务的可串行化调度可能会使用这种一次性请求所有资源,一次性释放所有资源的情况,但是一个事务的执行周期往往很短,并且基本不会出现一些资源不能立即被利用的情况。
不可抢占
毁掉这个条件有两个思路,一是毁掉被等待进程(让被等待进程放弃),这时相当于等待的进程抢占了被等待进程。这个不太靠谱。
还有一个就是让等待的进程放弃等待。这个也不太使用,需要能够保存和恢复资源状态。
循环等待
有一个方法可以避免出现循环等待,即将所有资源排序。如果一个进程已经分配到了Ri,那么它想要请求Rj,只有当i<j时才行。该方法也有些低效,原理同打破“占有且等待”条件。
死锁避免
死锁预防需要在一早就做足准备,不让产生死锁的任一条件发生,它们通常是低效的。死锁避免则是在进程要有某些动作时动态检测,如果它可能产生死锁,就不执行这个操作。
现在系统中有n个进程和m种不同资源,定义如下向量和矩阵,我们的任务是通过这些设计一个算法,该算法给出在启动一个新进程时是否安全(不可能发生死锁)。如果该算法返回启动新进程不安全,那么就拒绝该进程,否则才启动。注意不安全不代表一定会产生死锁,只是有可能。

下面介绍两种思路的死锁避免算法:
- 如果一个进程的请求会导致死锁,则不启动该进程
- 如果一个进程增加的资源请求会导致死锁,则不允许此分配
进程启动或拒绝
Claim矩阵给出了进程i对资源j的最大需求,这是进程与系统的一个约定,意图在于告诉操作系统进程i不会请求多于\(C_{ij}\)个资源j。
下面关系成立:
- \(R_j = V_j + \Sigma_{i=1}^n A_{ij}\) 资源总量等于剩余资源+已分配资源
- \(C_{ij} \leq R_j\) 任何进程宣称需要的资源的需求数不可超过该资源总量
- \(A_{ij} \leq C_{ij}\) 分配给任何进程的资源数不大于该进程最初声明它需要的总数
此时,当一个新进程需要启动时,我们如果能保证对于每个资源j:
资源j的数量足够新来的进程和之前的所有进程使用才启动这个进程。
此方案不会产生死锁,因为它保证对于任何的进程对于任何资源的请求,系统中都有足够的资源进行分配,它也足够简单,但唯一的缺点是它过于严格。
资源分配拒绝 —— 银行家算法
在我们运行的系统中有若干进程和若干资源,银行家算法首先定义了两种状态:
- 安全状态:至少有一个资源分配序列保证不会导致死锁
- 不安全状态:可能没有这样的资源分配序列
银行家算法在当进程请求一组资源时,先假设同意该请求,然后通过状态判断算法判断同意后系统是否在安全状态,若在安全状态即真正同意该请求,分配资源给进程,若在不安全状态,则阻塞该进程,直到有一刻同意它的请求后还是安全状态。
如下是银行家算法的部分:

request代表该进程本次请求的资源数,它是一个向量,包含了它本次要请求的所有资源数,首先算法先检测了该进程已经被分配的资源加上它本次请求的资源是否大于它向操作系统声明的最大资源总量,如果是就发生错误了。
然后,它判断了当前系统中剩余的资源是否已经不能满足该进程本次的申请了,如果是就挂起,否则进行模拟分配,创建新的状态,把alloc(已分配矩阵)和available(剩余资源矩阵)更新成满足该请求后的状态。
然后再判断当前系统是否处于安全状态,如果是,就同意该请求,如果不是,恢复初始状态,阻塞进程。
现在问题就到了safe函数如何实现。

safe算法假设了一个前提,即如果一个进程获得了它全部的资源,那么在未来的某一时刻,它会执行完毕,释放它的资源。
基于这个假设,safe主要做的工作就是循环寻找一个进程,若它日后还需要的资源数(该进程总共需要的资源数减去它以经被分配的资源数)小于当前系统拥有的资源总数,那么该进程可以立即被执行。如果找到了这样一个进程,测试安全算法假设它已经执行完毕,并把所有分配给它的资源收回,把该进程在剩余进程列表中移除。
当再也无法找到这样可以被立即分配执行的进程时,退出循环,若此时进程列表中已经没有进程了(所有的进程都被执行完了),那么当前系统的状态就是SAFE,因为这表明存在一条资源分配序列,它保证不会导致死锁,否则就是UNSAFE。
UNSAFE状态不一定会产生死锁,但是SAFE状态一定有一条路径不会产生死锁,并且这条路径已经被safe算法找出。
对于银行家算法我的理解还不太深,如有错误请帮忙指正,感激。
死锁避免算法有一些限制:
- 需要的前置信息太多,系统必须知道每个进程需要的资源情况
- 进程需要的资源情况必须固定
- 占有资源时进程不能退出
- 进程之间的执行不能有某种同步关系
死锁检测与恢复
死锁检测
恢复


 浙公网安备 33010602011771号
浙公网安备 33010602011771号