事务——MySQL技术内幕 InnoDB存储引擎
事务是数据库中一个操作的最基本的单元,具有ACID特性。
- 原子性(A),事务是不可分割的,其中的操作要么都做了,要么都没做,不可能做一半。
- 一致性(C),事务在完成前数据库处于一致状态,完成后也要处于一致状态,事务不能打破数据库的一致性。
- 隔离性(I),事务看起来是被隔离的,即事务在提交之前,它对数据库所做的操作不能被其他事务看到。
- 持久性(D),事务一旦提交,它对数据库所做的操作就应该被永久记录,即使数据库宕机也不应该对其产生影响。
大部分数据库为了获得一定的并发性没有实现完整的ACID特性,并且一般情况下这并不会造成什么问题,就连Oracle默认的READ COMMITED隔离级别也没有遵循I,也就是隔离性。
InnoDB默认的REPEATABLE READ完整的实现了ACID特性。
事务的实现#
隔离性使用锁实现,当出现不相容的锁时(出现写操作),一个事务就会等待另一个事务释放锁,释放锁的时机是事务提交后。
原子性、一致性、持久性是通过redo和undo log实现。redo log记录事务对页的物理操作,而undo log用来支持基于MVCC的一致性非锁定读,记录的是对行的操作。redo log和undo log都由在磁盘上的文件和在内存中的缓冲区组成,为了一定程度上提高并发。
redolog#
redo log的刷新#
MySQL默认会在事务提交时刷新这个日志,这个行为可以通过innodb_flush_log_at_trx_commit来控制,这个参数有三个取值:
0:Master Thread每秒刷新一次,宕机时可能会丢失一秒钟的操作1:默认值,事务提交时进行刷新,并立即进行fsync操作,这一操作用于将文件实实在在的写入磁盘,而非写入到文件系统缓存中。2:事务提交时进行刷新,但不进行fsync操作,宕机时可能丢失尚未从文件系统缓存中刷到磁盘中的数据。
测试一下,在默认innodb_flush_log_at_trx_commit=1的情况下插入一万条数据
CREATE TABLE test_load (
a INT,
b CHAR(80)
);
DELIMITER //
CREATE PROCEDURE p_load(count INT UNSIGNED)
BEGIN
DECLARE s INT UNSIGNED DEFAULT 1;
DECLARE c CHAR(80) DEFAULT REPEAT('a', 80);
WHILE s <= count DO
INSERT INTO test_load SELECT NULL, c;
COMMIT;
SET s = s+1;
END WHILE;
END;
//
DELIMITER ;
CALL p_load(10000);
卧槽,这电脑不能要了......

修改innodb_flush_log_at_trx_commit=0
SET GLOBAL innodb_flush_log_at_trx_commit=0;
DELETE FROM test_load;
CALL p_load(10000);
时间减少了一半。

其实正确的做法并不是修改这个参数,毕竟它会让数据库丧失一致性和持久性,正确的做法是我们在做这种大型的插入时,把它们看作一个事务,就是不要在其中进行commit。
SET GLOBAL innodb_flush_log_at_trx_commit=1;
DROP TABLE test_load;
DROP PROCEDURE p_load;
CREATE TABLE test_load (
a INT,
b CHAR(80)
);
DELIMITER //
CREATE PROCEDURE p_load(count INT UNSIGNED)
BEGIN
DECLARE s INT UNSIGNED DEFAULT 1;
DECLARE c CHAR(80) DEFAULT REPEAT('a', 80);
WHILE s <= count DO
INSERT INTO test_load SELECT NULL, c;
SET s = s+1;
END WHILE;
END;
//
DELIMITER ;
SET autocommit=0;
CALL p_load(500000);
COMMIT;
SET autocommit=1;
可以看到,修改后,我们即使插入比之前大50倍的数据也只需要15秒。

binlog与redo log的区别#
binlog与那两个日志不一样,那两个日志是InnoDB存储引擎的日志,binlog是MySQL进行记录的,默认情况下在事务提交时进行记录。也就是不管你用什么存储引擎,binlog都会在。它主要用于进行主从复制。
binlog和重做日志的区别:
- binlog记录对数据库的逻辑操作,其中记录的是SQL语句,redo log记录的是对于页的物理修改。
- binlog只在事务提交完成后进行一次写入(这里不是指刷新到磁盘),而redo log在事务执行过程中一直被写入。这说明,redolog并不是按照事务提交顺序进行排序的。
log block#
redolog不需要double write技术,因为它被分割成512字节大小的重做日志块,和磁盘扇区大小一致,所以它的写入是原子的。
取出重做日志头的12字节和重做日志尾的8字节,一个重做日志块可以存储492字节的日志。以下是重做日志缓存的结构
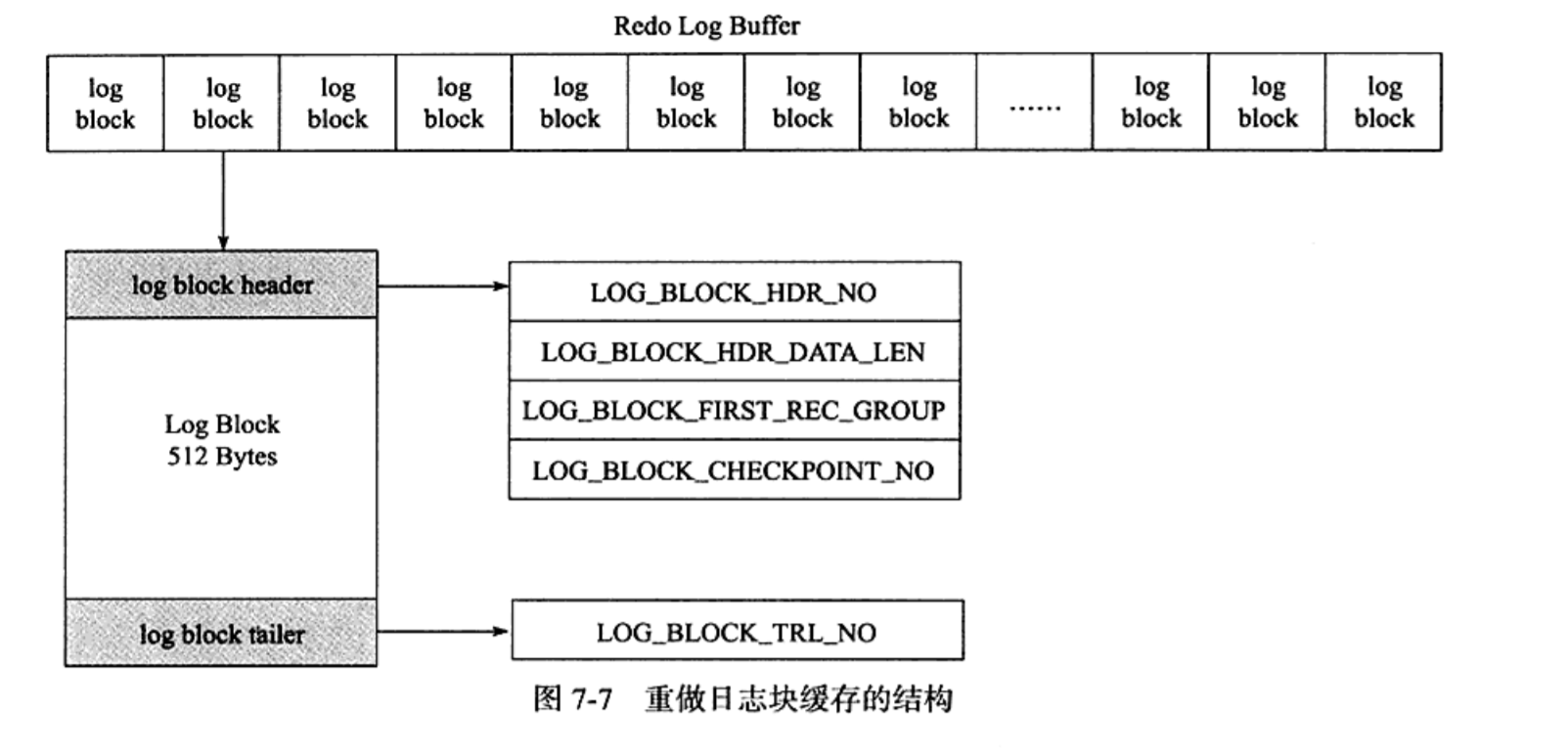
Redo Log Buffer是一个数组,其中存储了一大堆log block,每个log block可以被原子的刷回磁盘。
log block header:

LOG_BLOCK_HDR_NO:块在Redo Log Buffer数组中的位置LOG_BLOCK_HDR_DATA_LEN:记录日志块中的数据大小,当满时该值为0x200。LOG_BLOCK_FIRST_REC_GROUP:块中的第一个日志的偏移量LOG_BLOCK_CHECKPOINT_NO:该日志块最后被写入时的检查点
第三个参数是因为有的时候一个事务产生的日志会占用多个日志块,比如T1某次记录重做日志占用了762字节,T2某次占用100字节,就会产生如下情况:
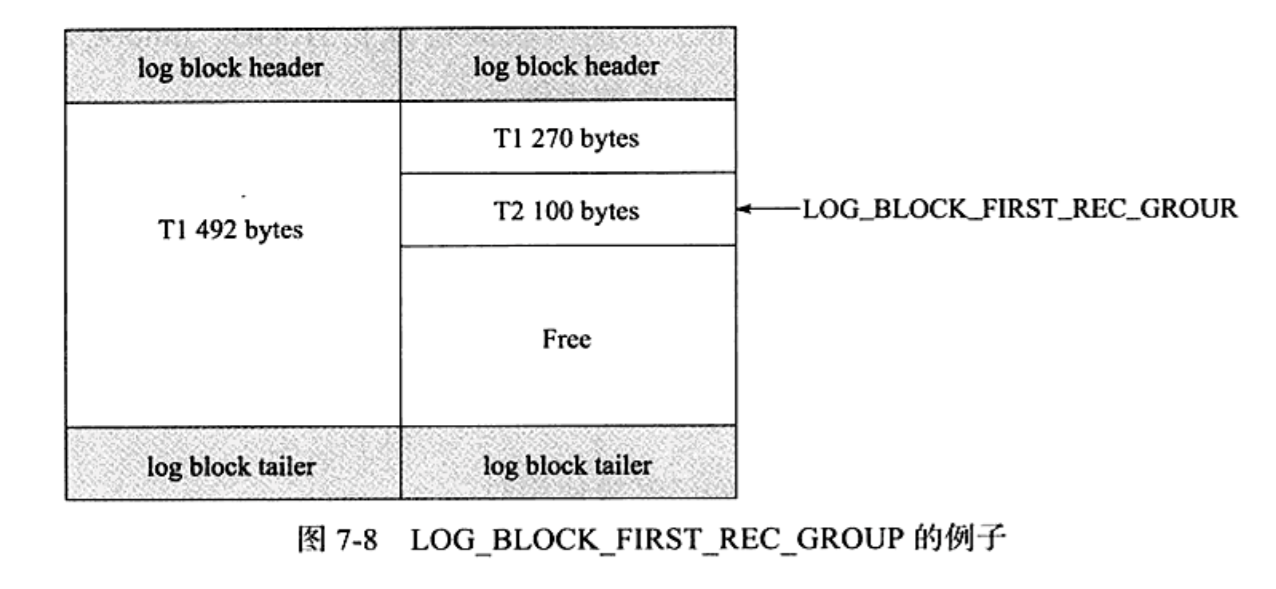
第二个日志块保留了前一个的后半部分,LOG_BLOCK_FIRST_REC_GROUP指向事务T2的起始位置。
log group#
重做日志组,包含多个重做日志文件,是一个逻辑上的概念,它只代表一批重做日志文件。
重做日志文件中保存的就是log buffer中的log block,按照512字节的块进行存储。log buffer会根据如下规则将log_block刷新到磁盘:
- 事务提交时
- log_buffer一半的内存空间被使用时
- log checkpoint时
写入追加到重做日志文件的最后部分,当一个重做日志文件满了,写入下一个,最后一个满了写入第一个。
LSN#
LSN(日志序列号)占用8字节,单调递增,能够表示
- 重做日志写入总量
- checkpoint的位置
- 页的版本(这里的页和块好像有了区别,页还是之前那个16KB的东西,块则是512KB的重做日志块,重做日志文件也是基于页管理的,可以说页中保存了一些块??这我也有懵)
比如LSN是1000,事务T1写入了100字节的重做日志,LSN就会变成1100。
每个页的页头也都有使用FIL_PAGE_LSN记录该页最后刷新时的LSN,因为LSN单调递增,所以能够使用它区分页的版本,LSN更大的页肯定是更新的。
MySQL启动时也是通过判断重做日志中的LSN是否大于页中的LSN来进行数据恢复。
通过SHOW ENGINE INNODB STATUS\G可以查看LSN的详细信息。
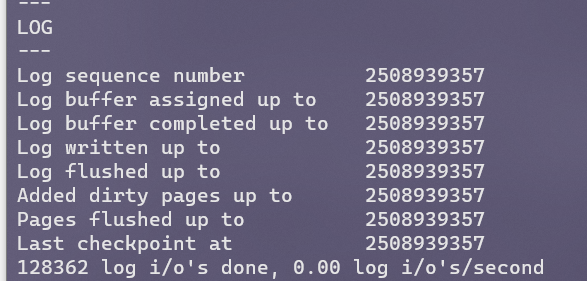
Log sequence number记录当前的LSN,Log buffer assigned up to记录从log buffer刷新到日志文件的LSN,Last checkpoint at表示已经刷新到磁盘页上的LSN。
undo log#
redo log,如其名,就是由于某些原因数据库的操作丢失时对数据库进行重做。而undo log时由于某些操作不再需要时,对之前做过的操作进行撤销。
当事务由于某些原因执行失败了,那么就需要对该事务进行回滚,也就是所有它做过的操作都要被undo。undo log记录了数据的多个版本,撤销只不过是将数据恢复到事务开始时的版本。
undolog在MySQL8中位于data文件夹下两个独立的表空间中,分别是undo_001和undo_002,在之前位于共享表空间中的undo段中。
undo log的另一个作用就是实现MVCC机制。
History List#
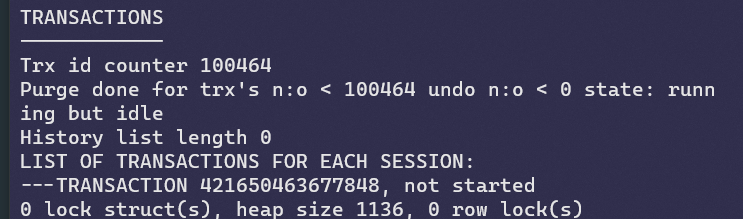
undo log并不是事务提交后就没用了,因为其他事务可能还需要查询undo log中该事务提交的数据。所以对于一个已提交的undolog,它会被放到History List这个链表中,具体能不能删除,何时被删除,都是由purge线程进行判断。
当前History List Length为0,证明History List中没有undo log。
undolog格式#
- insert undo log
- update undo log
insert undo log可以在事务提交时直接删除,update undo log记录了删除和更新操作,它们可能需要提供MVCC机制,所以它们不能在事务提交时直接删除。
purge#
上面也知道了,由于需要实现MVCC机制,所以对于删除和更新操作,不能直接删除或更新实际的物理记录,而是需要在undolog中记录,purge线程判断不会有事务再依赖之前版本的数据时,才会实际的进行删除或更新记录,并清除这些不用的undolog。
事务控制语句#
SET autocommit = 0/1启动或关闭自动提交START TRANSACTION | BEGIN显式开启事务COMMIT提交事务ROLLBACK回滚事务SAVEPOINT identifier创建保存点(这个保存点事务我没记,因为大部分情况下用的都是扁平事务)RELEASE SAVEPOINT identifier删除一个保存点ROLLBACK TO [SAVEPOINT] identifier回滚到保存点SET TRANSACTION设置事务隔离级别
COMMIT WORK和ROLLBACK WORK大部分情况下都和COMMIT和ROLLBACK相同,但前者可以用来实现链式事务。
嘶,,我还以为MySQL只支持扁平事务,看来对于保存点事务和链式事务也有支持。
隐式提交的SQL语句#
以下语句执行完毕后会隐式的产生一个COMMIT

隔离级别#
四个标准隔离级别
- READ UNCOMMITTED
- READ COMMITTED
- REPEATABLE READ
- SERIALIZABLE
大部分数据库厂商没提供完整的四个级别,Oracle就不支持READ UNCOMMITTED和REPEATABLE READ
SQL标准下的REPEATABLE READ会产生幻读,只有SERIALIZABLE才提供完整的ACID特性,而InnoDB在REPEATABLE READ下通过next locking技术解决了幻读,所以InnoDB在这个隔离级别下就能提供完整的ACID特性。
InnoDB的REPEATABLE READ和SERIALIZABLE都可以提供完整的ACID支持,区别是SERIALIZABLE为每个读取操作添加了LOCK IN SHARE MODE,也就是读取操作会添加共享锁,所以就不再需要MVCC。
分布式事务#
InnoDB提供XA事务的支持。
分布式事务是指允许多个独立的事务参与到一个全局事务中,参与全局事务的所有事务,要么都提交,要么都回滚。分布式事务必须使用SERIALIZABLE隔离级别。
XA事务允许参与全局事务的每一个事务是不同数据库系统上的,只要它们都支持全局事务,比如一台是MySQL,另一台是Oracle
不好的事务习惯#
在循环中提交#
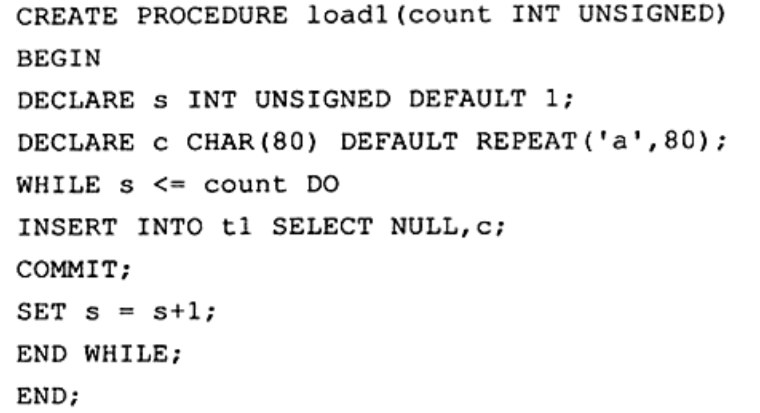
- 默认MySQL是自动提交的,所以这个COMMIT加不加没有什么实际效果
- 自动提交会频繁刷新重做日志,降低性能
- 如果这个过程运行到一半发生了错误,导致无法继续运行,那么前面已经插入的一半数据无法回滚。
所以推荐的做法是开启一个事务,并在最后提交
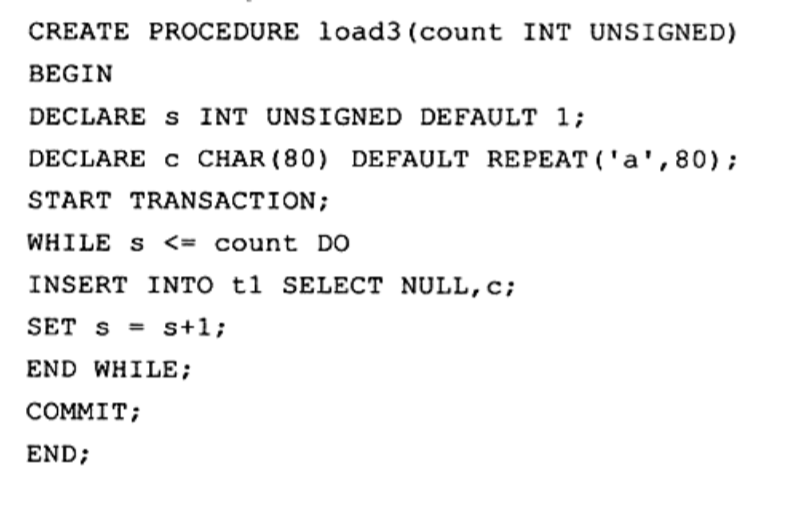
使用自动提交#
在不该使用自动提交的时候使用自动提交
作者:Yudoge
出处:https://www.cnblogs.com/lilpig/p/15666000.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
欢迎按协议规定转载,方便的话,发个站内信给我嗷~




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· winform 绘制太阳,地球,月球 运作规律
· 上周热点回顾(3.3-3.9)