锁——MySQL技术内幕 InnoDB存储引擎
latch和lock
我们讨论数据库理论中的锁,实际上大部分时间是在讨论lock。lock的对象是事务,用来加锁的对象是数据库、表、页、行等。
除了这些之外,数据库还需要对其自身的线程和内存中的数据结构进行并发控制,比如访问、刷新缓存列表中的页等,用来保证这些操作的并发正确性的工具就是latch。latch的对象是线程。在数据库系统中,latch通常比lock要轻量许多。
InnoDB中的锁
锁类型
InnoDB采用行级锁机制,提供两种锁:
- 共享锁(S Lock)
- 排他锁(X Lock)

两种锁A和B是兼容的,仅当事务1在某行或某几行上加了A锁后,事务2在同样的行上加B锁时不需要等待事务1释放A锁。
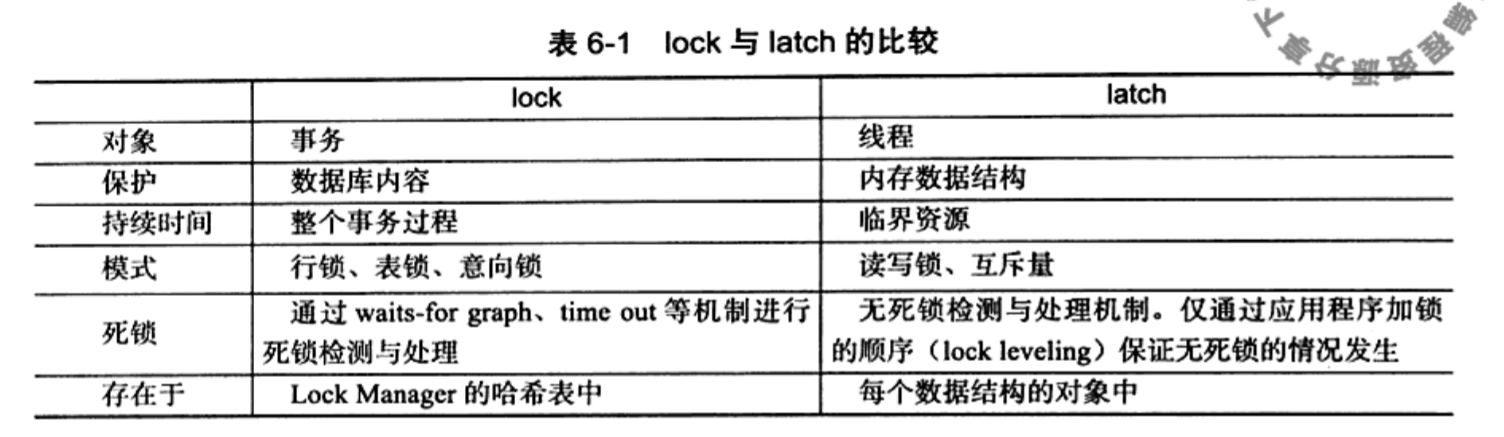
InnoDB提供表和行的多粒度加锁操作,所以它有意向锁,同时因为InnoDB只有行锁和表锁,所以它的意向锁只加在表上。
- 意向共享锁(IS Lock)
- 意向排他锁(IX Lock)
一个事务在一个表上加了意向锁,就证明它有在表中某(几)行上加锁的意向,反过来,如果事务想在表的某(几)行上加锁,必须先在行所在的表上加意向锁。
对于意向锁,不了解的可以去看我的另一篇笔记:事务的并发控制。
查看当前系统事务信息
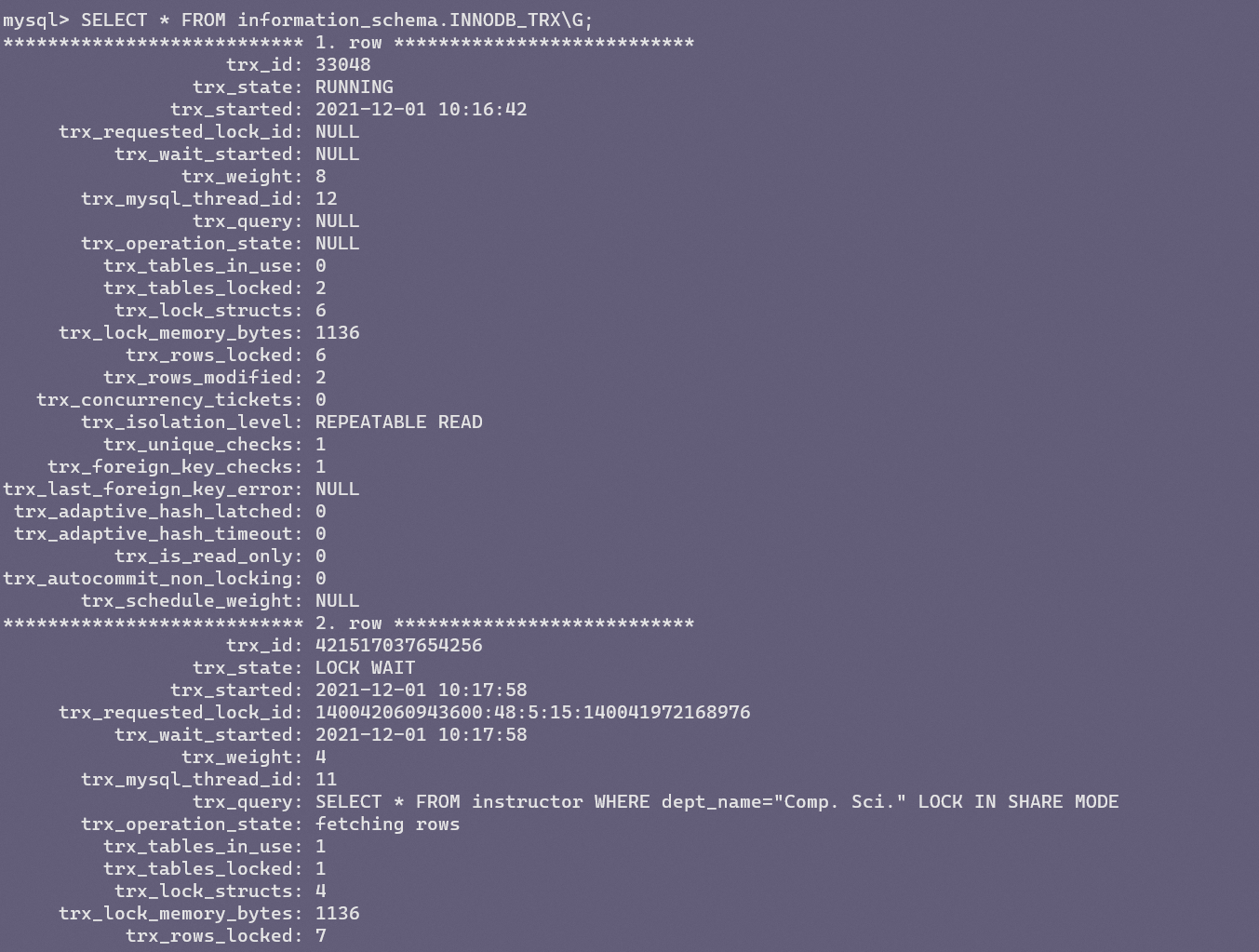
MySQL的information_schema下有三张表可以供我们查看当前系统中正在运行或等待的事务详情。分别是:INNODB_TRX、INNODB_LOCKS、INNODB_LOCK_WAITS,但它们其中的一些表已经不推荐使用了,并且在MySQL8中删除。
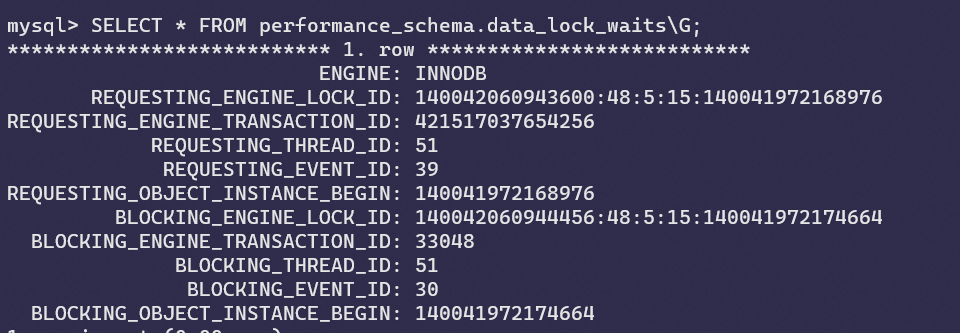
这里可以看到,第二个事务执行查询时被阻塞。
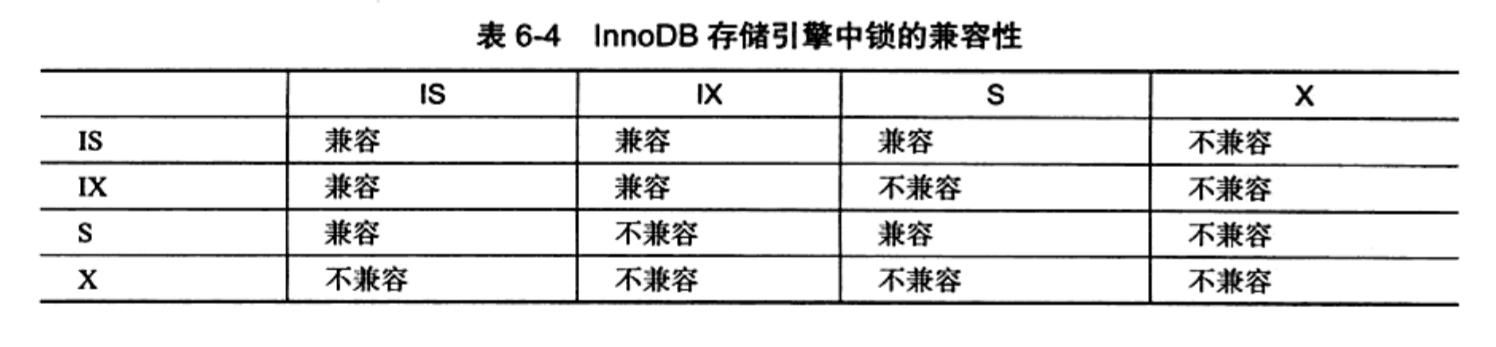
这个表展示了当前系统中的事务的运行状态信息,但还有些局限性,比如我们不能发现当前事务持有的锁的id信息。恰好INNODB_LOCKS表存储了当前系统中锁的信息。这个表能表明某一个事务持有某一个锁。

不过这个表已经在MySQL8中被删除了,取而代之的是performace_schema.data_locks和data_lock_waits。
我们直接在data_lock_waits中就能看到所有等待中的事务还有它们的ID、锁的ID,阻塞它们的事务ID,阻塞它们的锁的ID等信息。
而data_locks表中能看到锁定的类型,模式以及状态还有锁加在了哪个索引上。
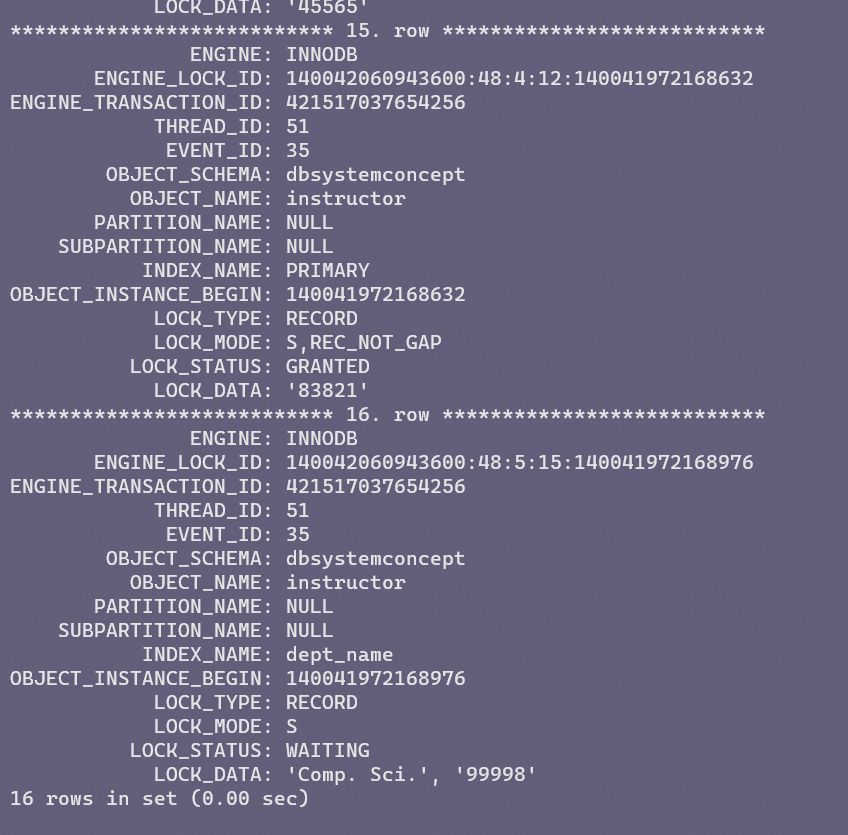
注意,InnoDB只支持行锁和表锁,并且如果查询没有用到索引,就只能通过全表扫描,所以需要加表锁。
一致性的非锁定读
为了提高并发性,大部分数据库系统中都提供了多版本控制机制(MVCC)来进行一致性非锁定读,即通过记录多版本快照技术达到在不使用锁定,无阻塞的情况下还能保证一致性的读取。

比如上图,在进行SQL查询时,要查询的某条记录被上了一个X锁,这代表有一个事务T正在修改或要删除它,这时可以通过读取上一个已提交的快照数据即可绕开等待T的提交或回滚。
几点:
- InnoDB在undo段上保存多版本控制机制的快照
- 快照数据都是之前的事务产生的已提交数据
- 快照数据由于已经提交,所以不可能被修改,所以不需要对它们上锁
- 在不同的隔离级别下,InnoDB选定历史版本的行为不一致
- 在REPEATABLE READ下,当前事务T总是读取T开始时的那个行数据版本
- 在READ COMMITED下,当前事务T总是读取最新的版本
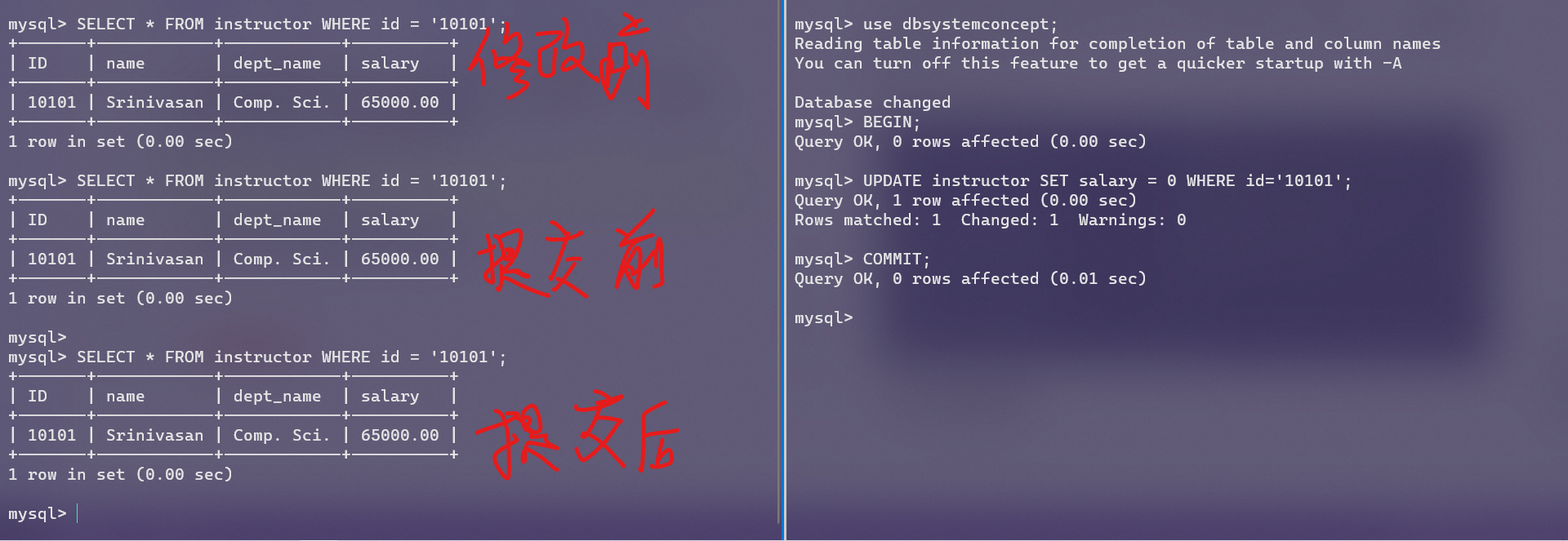
做个小实验,我们开启两个mysql连接,然后分别开启一个事务,一个进行写数据,另一个进行读数据,在REPEATABLE READ下和READ COMMITED下进行两次这种试验。
REPEATABLE READ下,MVCC保证了一个事务读不到另一个事务已经提交的数据,并且一个事务的读不阻塞另一个事务的写,因为根本就没有锁。
下面把隔离级别改成READ COMMITED

READ COMMITED下,一个事务可以读取到另一个事务已经提交的数据,但未提交的读取不到。
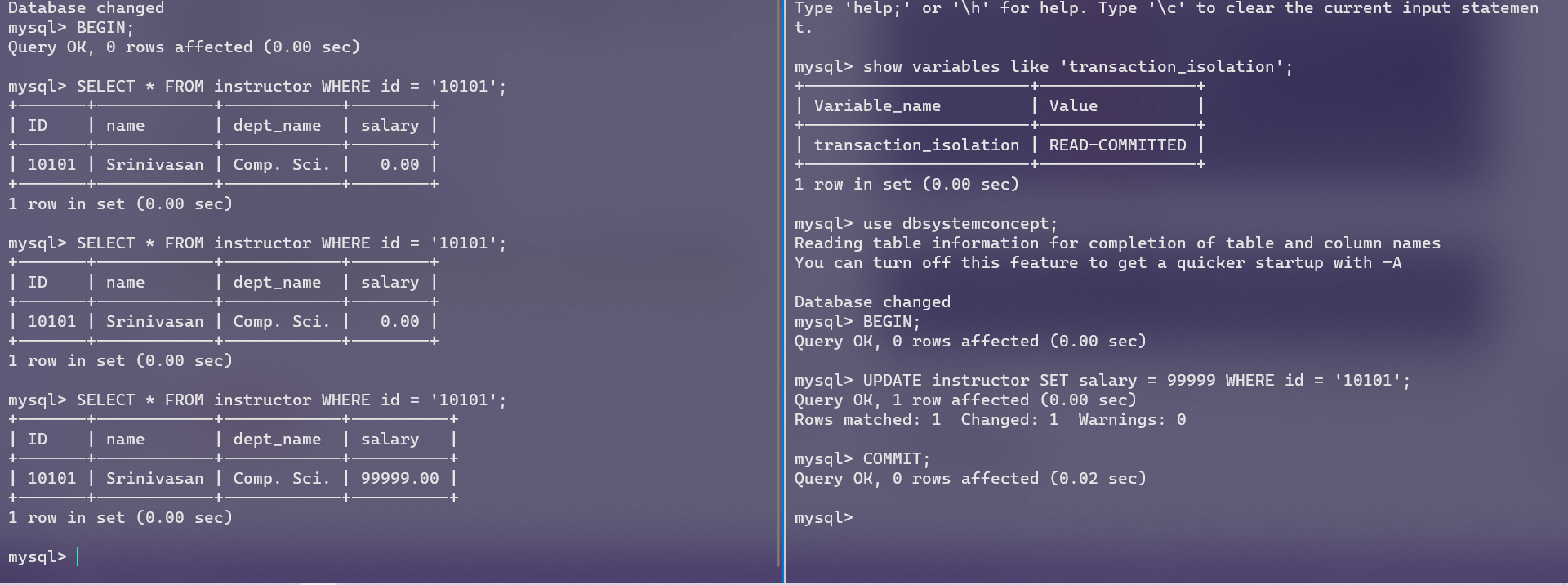
已提交读从数据库理论上违反了ACID中的I,也就是隔离性,但在高并发或分布式数据库服务器的场景下还是可能会用到。
一致性锁定读
默认情况下InnoDB使用一致性非锁定读来提高服务器的并发处理能力,但这不代表用户无法进行锁定读,用户可以使用如下两条语句进行一致性锁定读操作:
SELECT *** FOR UPDATE
SELECT *** LOCK IN SHARE MODE
前者对读取的记录添加X锁,后者对读取的数据添加S锁。
自增长与锁
自增主键插入的时候MySQL需要执行一个获得计数器的值,然后用这个值加一插入。
SELECT MAX(auto_inc_col) FROM t FOR UPDATE;
这个自动添加的锁是一个表锁,并会在插入完成后自动释放,而不是在一个事务完成后释放。这种方式叫AUTO-INC Locking
这样的实现方式有一个问题,所有的插入语句被强制串行执行了,注意,这里说的是插入语句,而不是一个事务。事务还是具有并发性的。
MySQL5.1.22开始,MySQL提供了基于轻量级互斥量的自增长机制,使用innodb_autoinc_lock_mode可以控制使用哪一种自增长机制。
先看几种插入模式。

以下是三种自增长锁定模式

外键和锁
CREATE TABLE parent(
id INT PRIMARY KEY AUTO_INCREMENT
);
CREATE TABLE child(
id INT PRIMARY KEY AUTO_INCREMENT,
pid INT NOT NULL,
FOREIGN KEY f_id (pid) REFERENCES parent (id)
);
INSERT INTO parent SELECT 1;
INSERT INTO parent SELECT 2;
INSERT INTO parent SELECT 3;
INSERT INTO parent SELECT 4;
INSERT INTO parent SELECT 5;
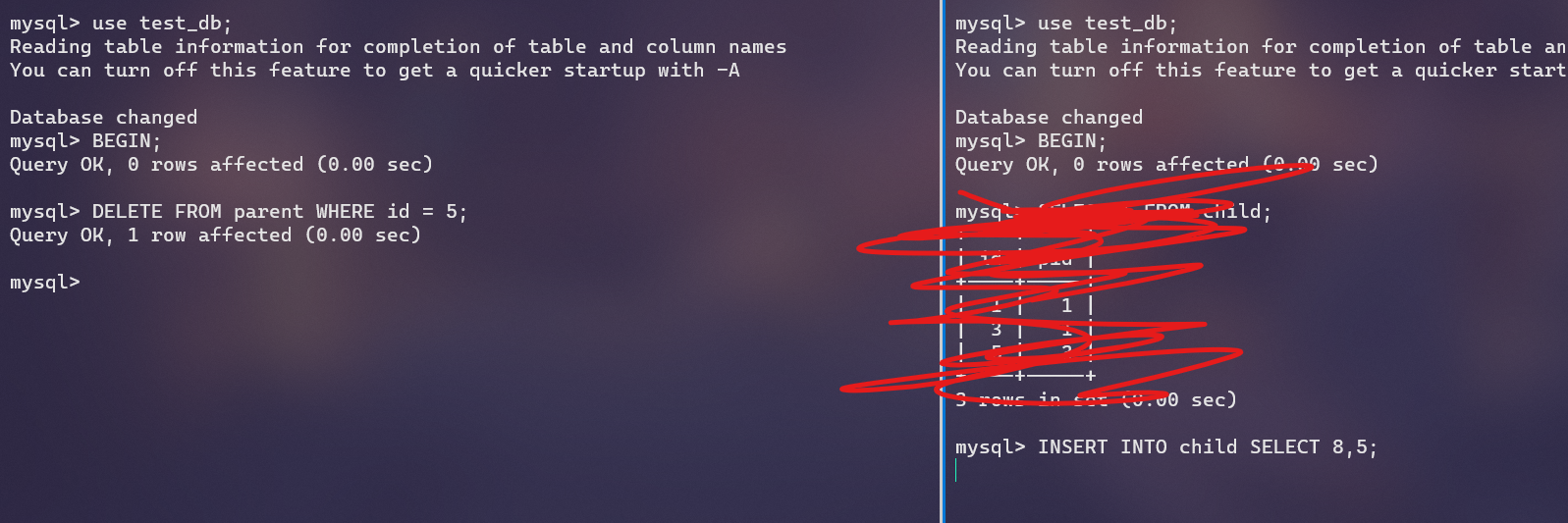
INSERT INTO child SELECT 1,1;
INSERT INTO child SELECT 3,1;
INSERT INTO child SELECT 5,3;
创建了外键后,为了保证参照完整性,parent表的更新操作会受到限制。在更新parent表id为x的记录时会先向child表进行一个查询:
SELECT * FROM child WHERE pid = x LOCK IN SHARE MODE;
这是一个锁定读,会向child表中的相关记录添加S锁。这回导致我们在一个事务中更新parent表的数据时,其他事务中child表的写操作被阻塞。因为这时左边的事务持有child表的S锁,右面的事务试图加X锁,这俩锁不兼容。
InnoDB创建外键时会在外键列上创建一个索引,以避免主表插入时为了参照完整性约束对副表进行全表扫描。比如上面的例子,会在child的pid列上创建一个索引。这样可以一定程度上避免死锁。
锁算法
- Record Lock:锁定单个记录
- Gap Lock:锁定一个范围,不锁定具体的记录
- Next-Key Lock:锁定范围并锁定记录,等于1+2
范围锁定主要用于解决幻读问题,场景如下:
事务A查询 年龄 < 20 的用户 返回10行
事务B插入一个 年龄 < 20 的用户
事务A再次查询 返回11行 一致性丢失
因为传统的基于单个记录加锁,只能阻塞其他事务中对该条记录的修改,没办法限制其他数据插入,所以要引入基于范围加锁的功能。InnoDB使用Next-Key Lock技术实现范围锁定。
如果有如下索引:10,11,13,20,Next-Key Locking,会建立如下范围区间

当索引是非唯一索引:
- 等值查询:包含查询指定值的范围会被加上Next Key Lock,下一个范围会被加上Gap Lock。比如上面一个事务对10加锁,那么\((-\infty, 10]\)会被加上Next Key Lock,\((10, 11]\)会被加上Gap Lock。
- 范围查询:where中指定的范围被加上Next Key Lock
当索引是一个唯一索引:
- 等值查询:Next-Key Lock会被降级成Record Lock,因为这时无法插入相同索引值的记录,所以无幻读现象,无需范围索引。
- 范围查询:where中指定的范围被加上Next Key Lock
一个小例子
CREATE TABLE test_nextkey(
a INT,
b INT,
PRIMARY KEY(a), KEY(b)
);
INSERT INTO test_nextkey SELECT 1, 1;
INSERT INTO test_nextkey SELECT 3, 1;
INSERT INTO test_nextkey SELECT 5, 3;
INSERT INTO test_nextkey SELECT 7, 6;
INSERT INTO test_nextkey SELECT 10, 8;
主键等值查询情况下,Next-Key Lock被降级成Record Lock,所以不会阻塞。

普通索引等值查询情况下,使用Next-Key Lock,右面的事务被阻塞。
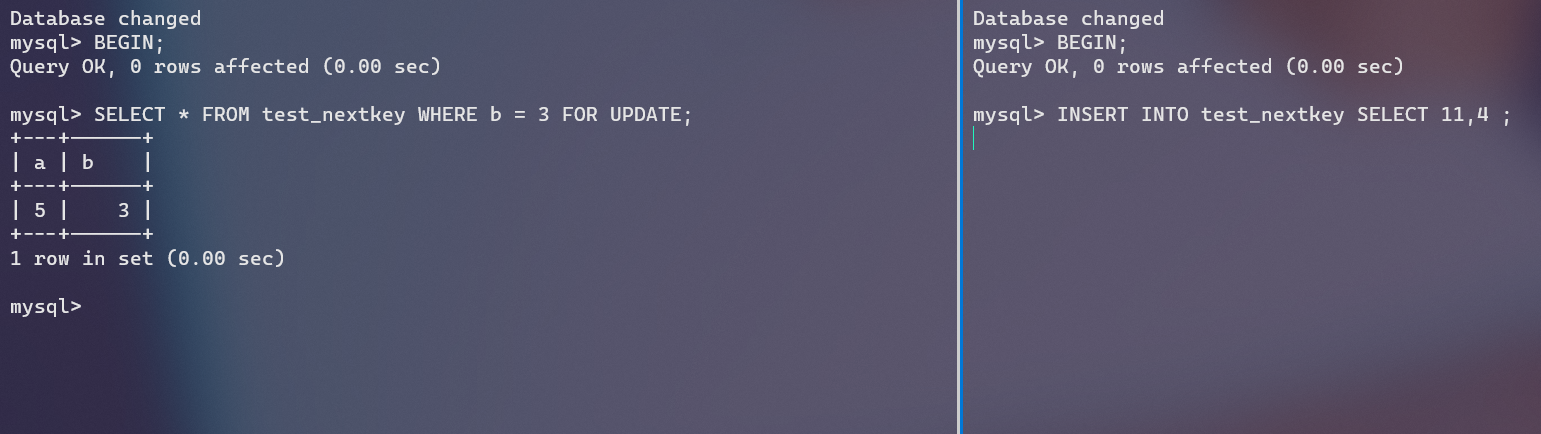
分析一波,b列的值有1,3,6,8,那么会建立如下区间
然后,左边的事务查询b=3时会锁定(1,3]的区间,实际上还会锁定待插入区间的下一个区间(3, 6]。所以右面的事务插入4时,会阻塞。
很多地方还不太清晰,之后会再来更新
阻塞
使用锁机制,在锁不兼容时阻塞必然发生。
可以使用一些参数控制阻塞的超时时间,以及超时后是否回滚事务。
死锁
表面上看,上面说的超时时间就可以解决死锁问题了,但是,首先,那需要一段时间的延时才能破解死锁,并且数据库无法选择哪个事务进行回滚,而是完全取决于哪个事务超时了。
在死锁时,选择一个权重比较低(锁定行和已经操作行比较少)的事务进行回滚是有好处的,因为这样会减少由于回滚该事务带来的事务级联回滚。
所以大部分数据库使用等待图来主动检测死锁,并且选择权重较低的回滚。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号