InnoDB特性介绍——MySQL技术内幕 InnoDB存储引擎
MySQL体系结构和存储引擎#
数据库和数据库实例#
- 数据库:一组用于保存数据的物理操作系统文件或其他形式文件类型的集合。
- 实例:用于操作数据库文件。

如上命令显示/var/lib/mysql/就是我的MySQL数据库实例用来保存数据库文件的地方。

这里有一些文件夹,每一个文件夹都是一个数据库,我们随便打开一个看看。
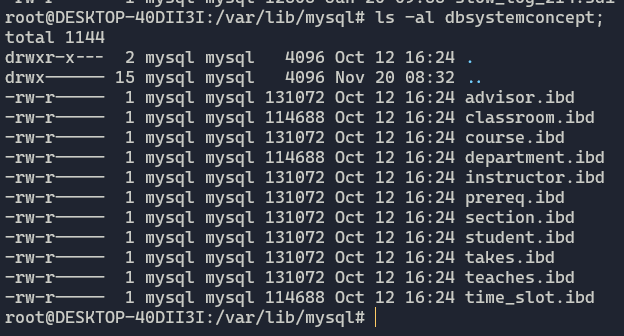
这里面都是表文件,ibd格式是innodb引擎的表文件。
MySQL体系结构#
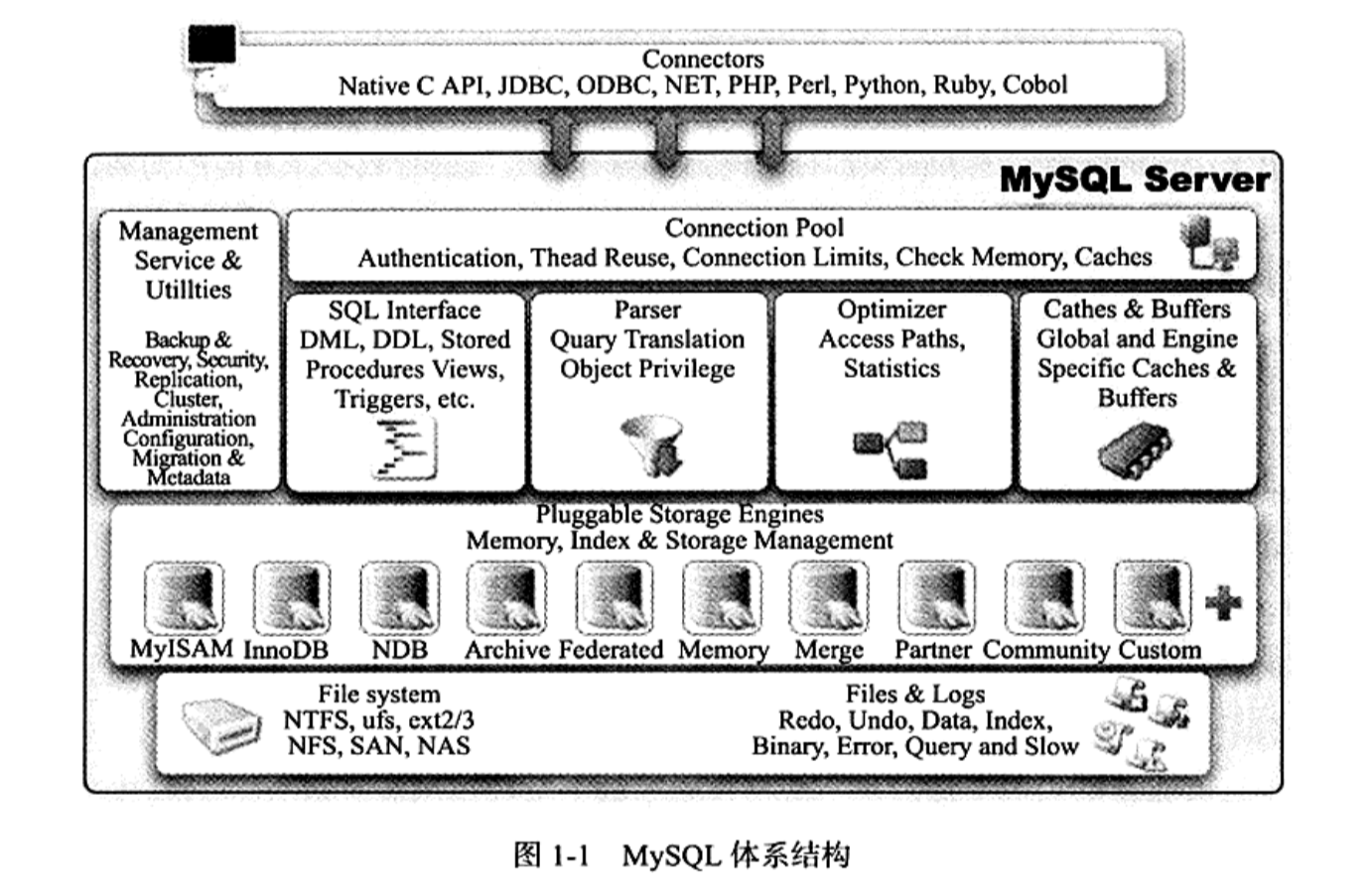
- 最顶层是MySQL向各个语言提供的连接器,这里包括熟悉的
JDBC驱动和ODBC驱动 - 下面就是MySQL服务器层,里面包含连接池、认证、线程复用、缓存、管理工具、备份恢复工具等等。
- 再下面一层用来处理SQL,包括SQL编译、SQL优化
- 再下面就是以插件形式存在的存储引擎,它们的工作任务就是管理内存、索引和数据的物理存储。
- 然后就是文件系统了,数据库和表最终要以文件的形式保存,这一部分和存储引擎密切相关。
不同的存储引擎擅长处理不同类型的业务,这让MySQL变得异常强大。
存储引擎是基于表的,不是数据库。
InnoDB存储引擎#
- 支持ACID事务,行级锁设计,主要面向OLTP应用(在线事务处理)
- 使用MVCC多版本并发控制
- 提供SQL标准的4种隔离级别,默认为可重复读
- 数据表文件被存储为
ibd格式,以聚集索引形式存储,也就是说按主键顺序存储
MyISAM存储引擎#
- 不支持事务,表锁设计,主要面向OLAP应用(在线分析处理)
- 支持全文索引
- 数据表文件被存储为
MYD文件,索引文件被存储为MYI文件。
Memory存储引擎#
- 数据被存放在内存中,数据库重启数据就消失
- 由于它的特性,所以MySQL经常会在一些操作中使用Memery引擎来存放查询结果的中间集
Archive存储引擎#
- 只支持SELECT和INSERT
- 使用zlib算法对数据行进行压缩存储
- 使用行锁插入,单非事务安全的存储引擎
- 适合存储日志等归档数据
InnoDB体系架构#
InnoDB是使用MySQL进行OLTP应用开发的首选引擎。
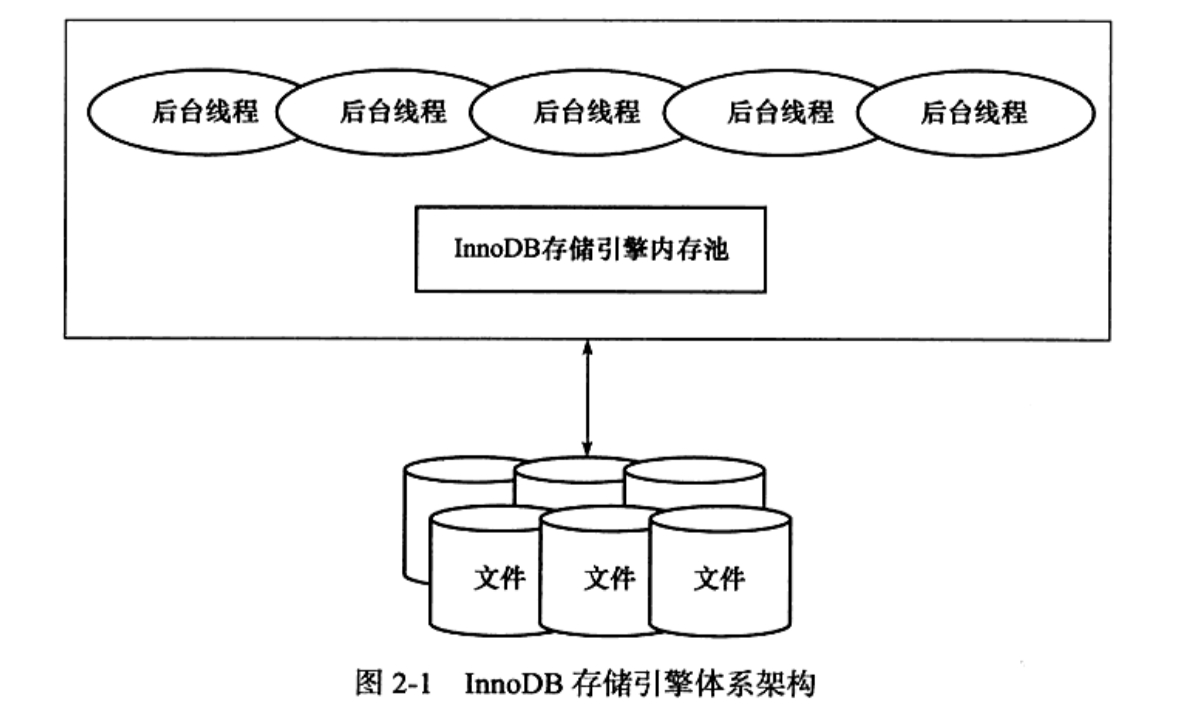
内存池负责缓存磁盘文件上的数据,以提高整体的读写性能。除此之外,内存池中还有重做日志的缓冲,后台线程依赖的一些内部数据结构。
后台线程主要负责将文件中的数据调度到内存池中,并在必要的时候将内存池中改变了的新数据刷回到文件中。
后台线程#
Master Thread#
负责将缓冲池中的数据异步刷回磁盘,包括脏页的刷新、合并插入缓冲、UNDO页的回收等。
IO Thread#
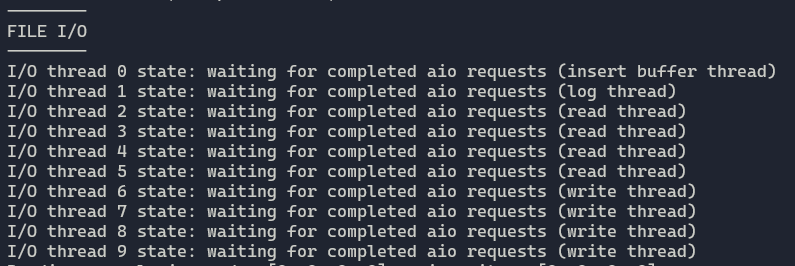
用于处理InnoDB中大量的异步IO(AIO)请求。
有四种IO Thread,分别是:write、read、insert buffer和log IO thread。
查看IO Thread的状态,可以看到read和write线程分别有4个,在老版本中可能只有1个。
SHOW ENGINE INNODB STATUS\G;
Purge Thread#
用于清理已提交数据的undolog。
在InnoDB 1.1之前,这部分工作在Master Thread中进行
查看Purge Thread的个数

Page Cleaner Thread#
InnoDB1.2中提供的新线程,目的是将脏页刷新放到独立于Master Thread的线程中执行
内存#
缓冲池#
缓冲池是在内存中的一块区域,用于提高数据库系统的整体性能,每次读取操作将读取到的页(块)保存到缓冲池中,下次读取时直接使用缓冲池中的数据。当对数据库中的数据修改时,也先修改缓冲池中的数据,再以一种称为Checkpoint的机制刷新回磁盘。
缓冲池越大,数据库能保存在内存中的数据就越多,数据库的性能就越好。

嘶,我们才给数据库分配了128MB的内存。在专门的数据库服务器上,可以考虑加大这个数值。
缓冲池中并不是只缓冲数据表文件中的数据,如下是InnoDB存储引擎的内存分布。
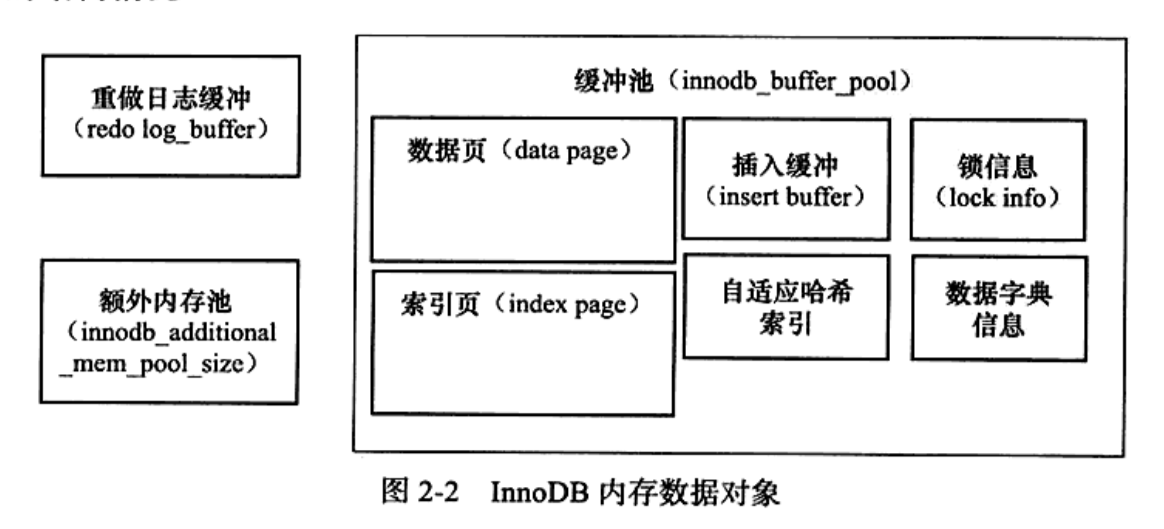
可以设置多个缓冲池实例,每个页根据hash分配到不同的缓冲池示例中,减少并发情况下的资源竞争。innodb_buffer_pool_instances就是用来配置缓冲池实例个数的。
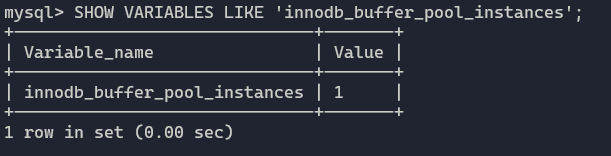
可以通过SHOW ENGINE INNODB STATUS来观察缓冲池的状态。在MySQL5.6之后,还可以通过information_schema.INNODB_BUFFER_POOL_STATS来观察,这样可以过滤掉很多无用信息。
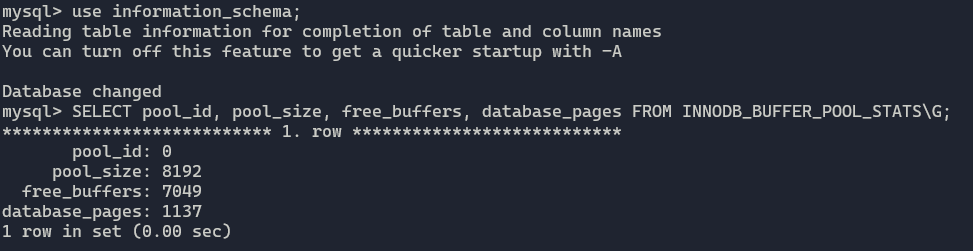
use information_schema;
SELECT
pool_id, pool_size, free_buffers, database_pages
FROM INNODB_BUFFER_POOL_STATS\G;
LRU List, Free List, Flush List#
经典的LRU(最近最少使用)算法是将频繁使用的页放在LRU列表的前端,这样不频繁使用的页就跑到了LRU列表的尾端。当缓冲池中无法容纳新读取到的页时,就优先释放尾端不常使用的页。
InnoDB对经典的LRU算法进行了改进,即新从磁盘读取到的页插入到midpoint,而不是LRU列表首部。midpoint是InnoDB的LRU算法中新旧数据的分界点,这一个点之后的数据称为old数据,之前的数据称为new数据。
之所以这样,是因为如果将新读取的页直接插入到LRU首部的话,那么可能将一部分new页挤到old中,而被LRU算法从列表中移除。尤其在数据扫描操作时,几乎要访问全表的数据。
我们可以通过innodb_old_blocks_pct参数来查看midpoint的位置,37代表LRU列表尾部的37%的位置之后被认为是old,新读取的磁盘页也会在这尾部的37%中。

还有一个参数,innodb_old_blocks_time,它用于指定读取到mid位置的页等待多久才会被加入到LRU列表的new端。也就是说如果这个页在指定的时间内没被刷出的话,那么就认为该页称为了热页,该被加到new端了。

FREE页是空闲页,数据库最初启动时,LRU列表中没有页,而空闲页列表是满的,如果空闲页列表中还有页的话,先从空闲页列表中删除一个页,并放入到LRU列表中。如果没有才考虑将LRU列表中的旧页淘汰。
当页从LRU列表的old部分被添加到new部分时,称为page made young,当因为innodb_old_blocks_time的存在导致暂未从old部分被添加到new部分的操作称为page not made young
使用SHOW ENGINE INNODB STATUS可以看到这两个操作的详情

除此之外还能看到缓冲池中的总页数,Free页列表中的页数等信息
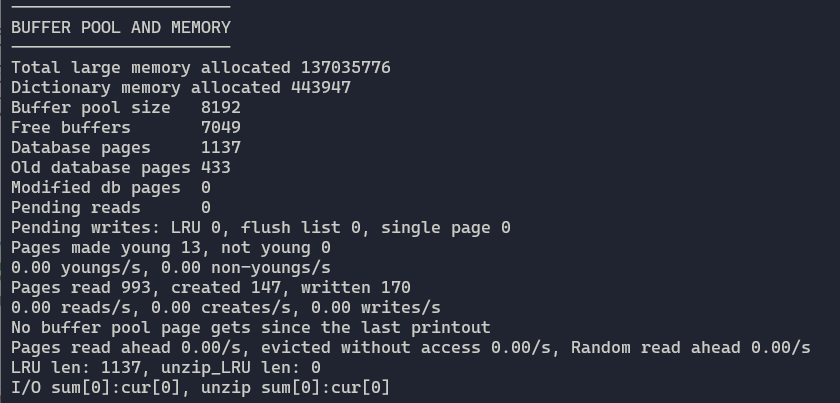
可以看到用来保存数据库页的空间和空闲空间加起来不等于缓冲池的总空间。因为缓冲池还要缓冲别的东西。
通过information_schema中的INNODB_BUFFER_POOL_STATS表来查询缓冲池相关的信息。(因为啥也没干所以命中率为0)
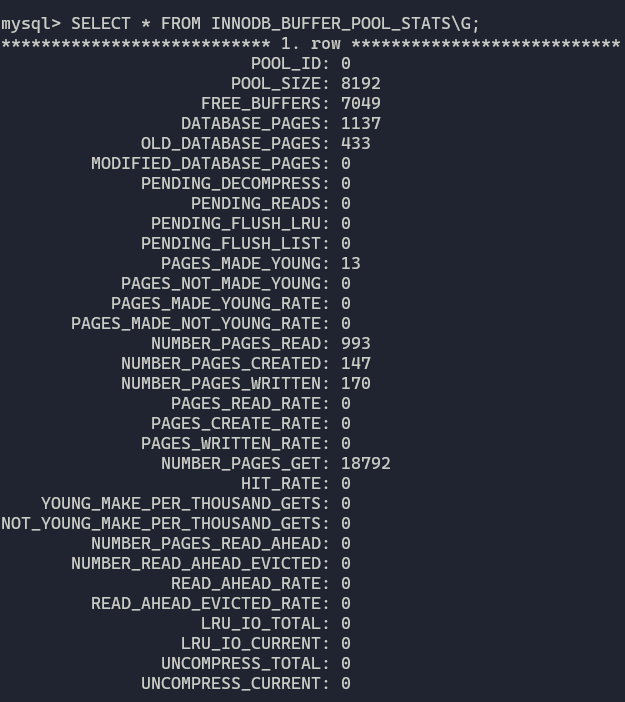
InnoDB支持压缩页功能,把16KB的页压缩成8KB、4KB、2KB和1KB。压缩的页存储在unzip_LRU中,LRU的长度包含unzip_LRU的长度。

FLUSH列表保存的是那些在内存中已经被修改过并尚未回写到磁盘文件中的页,这种页叫脏页,它们既存在于FLUSH列表中也存在于LRU列表中。
重做日志缓冲#
用来保存数据库的重做日志的,数据库写重做日志时先缓存到这里,然后按一定频率刷到重做日志文件中。
这样可以查看重做日志缓冲区的大小。

刷新时机:
- Master Thread每秒钟刷一次
- 事务提交完成前刷一次,为了保证此时崩溃后能恢复到一致状态
- 重做日志缓冲池空间小于1/2时刷一次
额外的内存池#
用来对一些系统运行需要的数据结构分配内存。
当加大上面那些缓冲池大小时,也应考虑加大额外内存池的大小。因为缓冲池更大,用来记录一些控制信息的数据结构也就更大,比如LRU、锁、等待信息等。
CheckPoint技术#
CheckPoint技术解决三个问题
- 缩短数据库重做时间
- 当LRU列表中的旧页被弹出时,刷新其中的脏页
- 重做日志不可用时刷新脏页
第一点,当数据库宕机并重启时,需要从重做日志中恢复系统,如果有了checkpoint就只需要恢复检查点之后的,还没来得及刷入磁盘的操作,因为检查点之前的已经被刷入磁盘了。
第二点,LRU列表中的旧页需要弹出时,其中可能存在脏页,在弹出之前必须强制产生检查点把这些脏页刷回磁盘。
第三点,重做日志文件不可能无限大,都是循环使用的,上一次检查点之前的数据已经被刷回磁盘,日志里的这部分数据就没用了。所以当重做日志文件中已经不能容纳新的日志时,需要强制产生检查点。
InnoDB通过8个字节的整数LSN(日志序列号)来标记版本并判断新旧。页有LSN,重做日志有LSN,CheckPoint也有LSN。可以通过SHOW ENGINE INNODB STATUS\G来查看
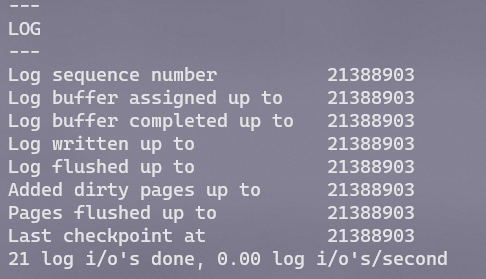
InnoDB中有两种CheckPoint
- Sharp Checkpoint
- Fuzzy Checkpoint
第一种是将所有脏页都刷回到磁盘中,这一般发生在数据库关闭时,不会在运行时使用。
第二种是将部分脏页刷回到磁盘中,这是运行时使用的。
在运行期又有四种可能发生的Fuzzy Checkpoint:
- Master Thread Checkpoint
- FLUSH_LRU_LIST Checkpoint
- Async/Sync Flush Checkpoint
- Dirty Page too much Checkpoint
第一个大概就是主线程会异步的以一秒或几秒钟的间隔产生Fuzzy Checkpoint。
第二个就是LRU列表没有足够空间需要移除末尾的页时,如果这些被移除的页中有脏页产生的Fuzzy Checkpoint。innodb_lru_scan_depth参数指定了LRU列表必须存在的可用空闲页数量,如果空闲页小于这个数字就要移除LRU列表末尾的页。在InnoDB1.1.x之前这个操作发生在用户线程,1.2.x版本中已经放在Page Cleaner线程中了。

Async/Sync Flush Checkpoint的目的是当重做文件不可用的情况下强制刷回一些页到磁盘。

假设当前重做文件2GB,那么async_water_mark=1.5GB,sync_water_mark=1.8GB。checkpoint_age = redo_lsn - checkpoint_lsn,即已经写入到重做日志文件的LSN减去已经刷回磁盘的最新页的LSN。
当checkpoint_age > async_water_mark时(不大于sync_water_mark),那么进行一次刷新,从FLUSH列表中刷新足够的脏页到磁盘,使得checkpoint_age < async_water_mark
当checkpint_age > sync_water_mark时执行一次刷新,使得checkpoint_age < async_water_mark。
这个操作同样也在1.2.x版本中放到Page Cleaner Thread中处理了。
最后一种,Dirty Page too much Checkpoint,即当缓冲池中脏页数量太多产生一次Checkpoint。可以通过innodb_max_dirty_pages_pct参数控制。下面就是当脏页占据了90%的缓冲池空间时刷一次。

Master Thread工作方式#
1.0.x版本之前的Master Thread#
Master Thread由多个循环组成:
- loop:主循环
- background loop:后台循环
- flush loop:刷新循环
- suspend loop:暂停循环
这四个循环会根据当前数据库系统的运行状态不断切换。
主循环由两部分操作组成,即每秒钟做一次的操作和每十秒钟做一次的操作:

这个秒数使用thread sleep实现,在负载很大的情况下可能不精准。
每秒钟一次的操作

合并插入缓冲会在InnoDB认为当前系统IO压力很小的情况下发生(前一秒的IO次数小于5次)
刷新脏页会在当前缓冲池中的脏页比例超过innodb_max_dirty_pages_pct参数时(默认为90%)刷新。
每十秒钟一次的操作

第一个操作,当InnoDB认为IO压力小时刷新(10秒钟内IO次数小于200次)。
下面两个操作没啥可说的。
再有就是undo页的删除,就是full purge操作。uodo页用来实现多版本并发控制,它会在一些记录被更新或删除时保留原有信息,full purge会判断这些原有信息是否已经可以删除了,如果可以就将其删除。InnoDB每次最多尝试回收20个undo页。
最后如果缓冲池中有超过70%的脏页,刷新100个到磁盘,否则刷新10%的脏页到磁盘。
接着我们看background loop,这是数据库空闲时或关闭时切换到的循环 。

此时,如果flush loop中也没有什么事情可以做了,那么InnoDB就会切换到suspend loop。此时Main Thread挂起,等待事件发生。
1.2.x版本之前的Master Thread#
这个版本主要解决的问题就是上一个版本中刷新脏页和undo页还有合并插入缓冲的硬编码问题。
IO性能越来越强,尤其是SSD出现之后,而InnoDB因为硬编码了刷新数据的数量,所以它只能慢慢悠悠的做。
这个版本主要通过提供一个参数——innodb_io_capacity——来解决这个问题,它表示磁盘IO的吞吐量,默认是200。
- 合并插入缓冲时,合并数量为
innodb_io_capacity的5% - 从缓冲区刷新脏页时,脏页的刷新数量为
innodb_io_capacity
innodb_max_dirty_pages_pct也被从90调节到了75,即缓冲区中的脏页比例到达75时就刷新脏页。
再有就是加入了innodb_adaptive_flushing,这个参数会根据产生重做日志的速度来自动决定刷新脏页的数量,在脏页比例小于innodb_max_dirty_pages_pct时也会刷新一些脏页。
最后一个就是加入了innodb_purge_batch_size,它代表每次ful purge时回收Undo页的数量。
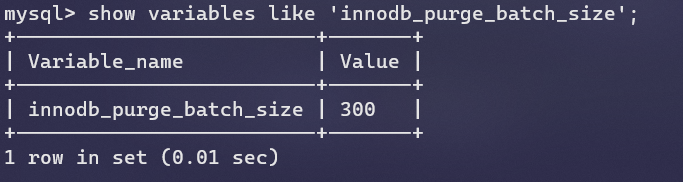
1.2.x版本的Master Thread#
主要将脏页刷新操作分离到Page Cleaner Thread中,并且将之前一秒钟和十秒钟的模型改为如下:

就是空闲时执行10秒一次的操作,正常时执行1秒一次的操作。
InnoDB关键特性#

这些特性是InnoDB高性能高可用的秘密。
Insert Buffer#
前面说了好久Insert Buffer,也不知道是个啥。
我们想想数据库插入时都需要做什么,对于InnoDB这种使用主键聚集索引的存储方式来说,肯定是先按这个聚集索引顺序将数据插入到对应位置。如果此时某些字段上有其他非聚集的索引,那么要更新这些索引项。
自增主键的插入不会产生随机的磁盘读写,因为主键是有序递增的整数。对于UUID这种,或者MD5这种离散的主键,也会产生随机磁盘读写(UUID_TO_BIN然后再倒序不会)。
CREATE TABLE t(
a INT AUTO_INCREMENT,
b VARCHAR(30),
PRIMARY KEY(a)
);
再有就是对于其它索引,比如下面的b,由于插入数据的随机性,也会产生随机磁盘读写,除非插入的数据是像购买时间这样有序的数据。
CREATE TABLE t(
a INT AUTO_INCREMENT,
b VARCHAR(30),
PRIMARY KEY(a),
KEY(b)
);
不管怎么说,随机磁盘读写总是拖慢数据库系统效率的最大原因,因为这需要不断的移动磁头,移动磁头的时间称为磁盘搜索时间。
InnoDB采用Insert Buffer(插入缓冲)理念,即对非聚集索引的插入或更新操作,如果非聚集索引的索引页在缓冲池中,那么执行插入或更新,否则,先放到Insert Buffer中。然后以一定的频率和情况将Insert Buffer中的数据和辅助索引页中的节点进行merge(合并)操作,并且此时如果有多个插入操作要插入到同一个索引页中,往往能将它们合并。
使用Insert Buffer的两个前提条件:
- 索引是辅助索引
- 索引不是唯一的
关于第二点,是因为既然选择缓存到Insert Buffer中,就没办法去校验索引的唯一性,因为校验唯一性就必须读取辅助索引文件,那么就又会产生随机磁盘读写。此时就不如让它直接插入。
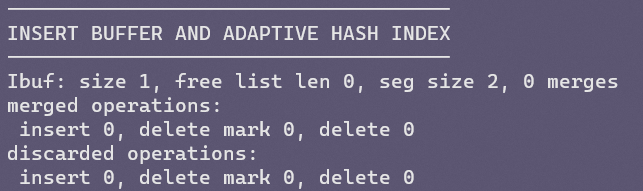
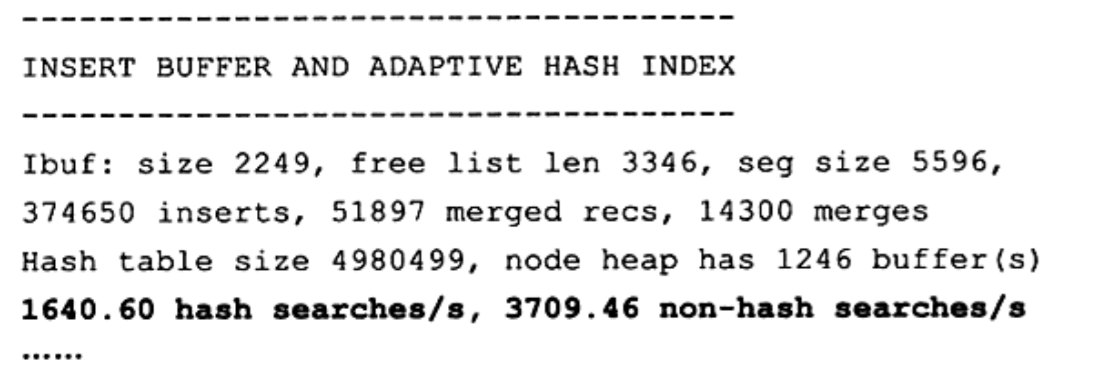
这是使用SHOW ENGINE INNODB STATUS命令得到的关于插入缓冲的信息

seg size是当前插入缓冲区的大小(2x16KB),free list是空闲列表长度,size代表已经合并记录页的数量。inserts代表插入的记录数,merged recs代表合并的记录数,merges代表合并次数。可以看到Insert Buffer把本该产生的一些随机磁盘读写合并到一起,变成更少的几次非随机磁盘读写来提高性能,并且效果非常不错。
插入缓冲最大可以占用1/2的缓冲池内存,这在写密集的情况下可能对其它操作带来一些影响。
Change Buffer#
Change Buffer是Insert Buffer在1.0.x版本的升级版。它不仅可以对插入进行保存合并,对删除,更新操作也可以。
Change Buffer分为三个:Insert Buffer、Delete Buffer和Purge Buffer。
Delete Buffer用于将记录标记为删除,Purge Buffer用于将记录真正删除。对于UPDATE操作可以看作Delete Buffer -> Purge Buffer -> Insert Buffer的一次联用。
参数innodb_change_buffering用来指定开启的缓冲类型,默认为all代表全部开启。
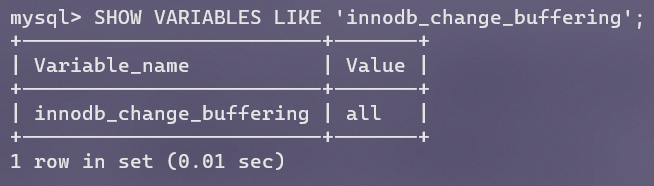
该值还可以为inserts、deletes、purges、changes、none。changes代表inserts和deletes一起。
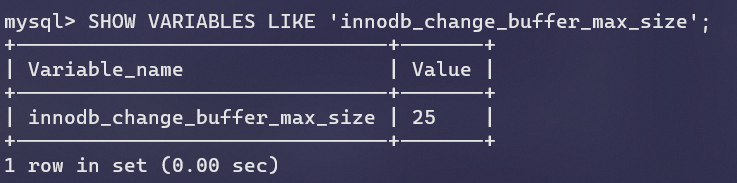
Innodb1.2.x中可以使用参数innodb_change_buffer_max_size来控制Change Buffer最大的内存用量,解决了之前占用缓冲池过多的问题。25代表最大占用缓冲池的1/4,最大50。
同时在支持Change Buffer的InnoDB版本中查看引擎状态时,可以看到如下信息,即插入,删除标记和删除操作都合并了多少
Insert Buffer内部实现#
这里只简单介绍一下,如想更深了解请看原书《MySQL技术内幕——InnoDB存储引擎》。
Insert Buffer的实现是一颗全局唯一的B+树
非叶子节点如下
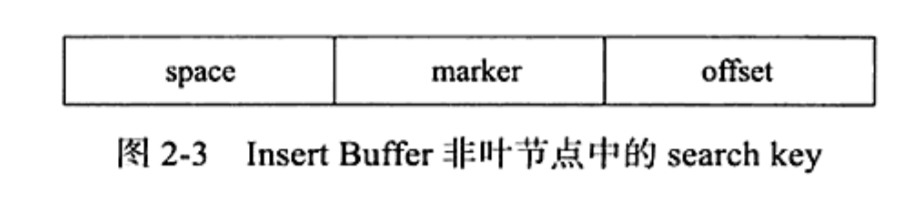
space代表待插入记录的表空间,InnoDB中每一个表都有一个4字节的表空间,marker是为了兼容老版本Insert Buffer留下的一个字段,offset是页所在的偏移量。
叶子节点如下
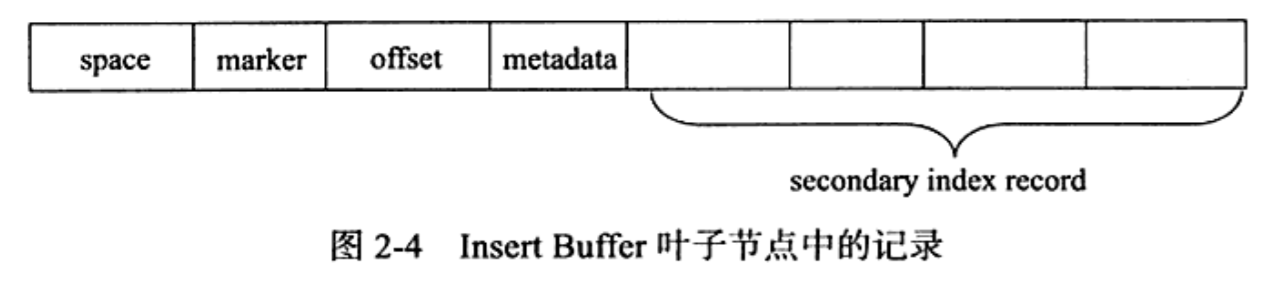
前三个和之前一样,第四个是待插入记录的元数据,比如插入数据的排序信息(谁应该比谁先插入)就会存到这里,然后就是二级索引记录的每一个字段了。
Merge Insert Buffer#
Insert Buffer中的记录何时合并到辅助索引中?
- 当辅助索引页被读取到缓冲池中
- Insert Buffer Bitmap页追踪到该辅助索引页已经无可用空间时
- Master Thread
两次写#
即为了保证数据库宕机后能够提供有效的恢复机制而设计的功能。
当刷新脏页时如果直接刷到磁盘里,16KB的页如果只刷了4K就宕机了,那么磁盘中的页就会被毁掉。这是重做日志也没法处理的,因为重做日志记录的都是对页的物理操作。
double write功能在刷新脏页时先将脏页复制到内存中的doublewrite buffer中,然后doublewrite buffer先将脏页数据存到共享表空间的物理磁盘上,当完成这次写入后再真正的将脏页刷新到表空间中。
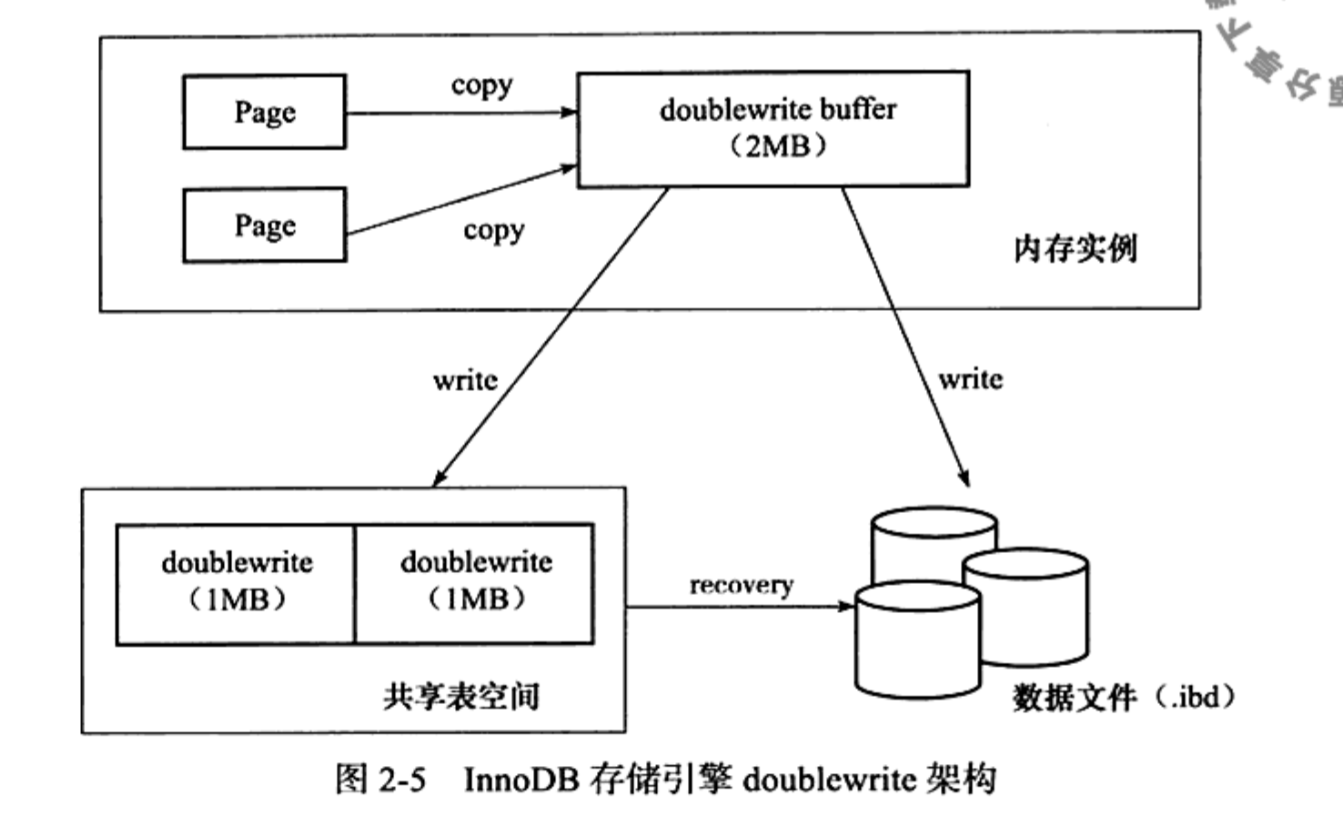
这时系统如果在写入页到磁盘中的表空间的过程中发生故障,就可以在下次启动时通过共享表空间来恢复。如果在写到共享表空间的过程中就发生故障,那么脏页应该写到的表空间文件没被破坏,重做日志可以直接对其进行重做。
如果使用主从服务器技术,可以考虑在从服务器上关闭两次写以提高性能,但主服务器不能关闭。在本身提供了防止部分写失效功能的文件系统上也可以关闭两次写。
这部分触及到我的知识盲区,所以有问题帮助我指出~谢谢。
自适应哈希索引(Adaptive Hash Index, AHI)#
自动对热点页据建立哈希索引。
AHI的自动建立要求页的连续访问模式是一样的,即查询的条件一样。以下是具体的要求:
- 页以同样的模式访问了100次
- 页以同样的模式访问了N次,N=页中记录/16
可以在引擎工作状态里看到这些信息。
因为Hash索引只能应用于等值查找,所以这里有没用上索引的情况。可以通过如下参数设置是否开启AHI

AIO#
异步进行IO操作,除了比同步资源利用率高之外,还可以进行IO Merge操作,即,将多个同个页内的操作合并为一次IO操作。
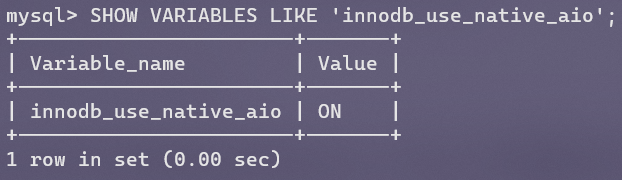
InnoDB1.1.x开始提供更高性能的原生AIO支持,此前都是InnoDB存储引擎层面对AIO的模拟,但前提是MySQL运行所在的操作系统也要支持Native AIO。可以通过如下参数查看Native AIO是否开启。
刷新邻接页#
即对脏页刷新时检测该页所在区的所有页,如果是脏页,则一同刷新。
问题:
- 一同刷新的页是否不是太“脏”,以至于刷新后它又很快变成脏页
- 对于非传统机械硬盘,这个特性能带来的收益微乎其微
可以通过innodb_flush_neighbors参数开启或关闭该特性
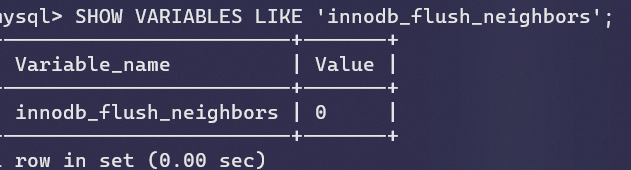
我这里默认已经是关闭了。
作者:Yudoge
出处:https://www.cnblogs.com/lilpig/p/15583682.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
欢迎按协议规定转载,方便的话,发个站内信给我嗷~




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· winform 绘制太阳,地球,月球 运作规律
· 上周热点回顾(3.3-3.9)
2020-11-21 四分树——UVa 297、UVa 806