分析JavaWeb中的乱码问题
起源
嘶。。。
期末有一个作业是要把老师给的四个JavaWeb程序在电脑上运行起来,这倒没什么难的,关键是这四个项目里很多地方编码解码不统一,导致很多地方都乱码。
昨天检查作业,有个漂亮姐姐运行项目的时候出了编码问题,此前在寝室已经解决了这四个项目中大部分编码问题的我非常自信的就过去了,然后...可能也是因为在漂亮姐姐旁边比较紧张,脑子直接就不转了,仿佛回到了之前刚刚学习这些东西的时候遇到乱码就一顿瞎jier编解码,直到瞎猫碰到死耗子,碰到正确的编码组合,幸好昨天死耗子让我逮到了,要不不丢脸了吗xD。
所以,今天我打算重新下载这四个项目,对这四个项目中的所有乱码的位置进行分析,然后整理成一篇儿笔记分享出来~~~
为什么乱码(编解码原理)
乱码,无非就是解码过程使用的字符集和编码过程中不一致。
无论是英文还是中文,想要在计算机中保存就必须转换成二进制数字,因为它就认二进制嘛。
也就是说,编码无非就是将一串字符按照某种规则编成一堆二进制数字,而解码同样也是使用某种规则从一堆二进制数字构建一串字符,而这里面说的某种规则就是编码格式,比如常听到的ASCII、ISO 8859-1、GBK、UTF-8等。
所以Java中的编码过程就可以看作是将char[]转换成byte[],前者是由字符组成的字符数组,后者是用来保存二进制的字节数组。
常见编码
对常见编码已经有了解的可以不看这一段,直接到下一段
规约
下面介绍一些编码时,我会编写一些代码来说明,为了将目光聚焦在代码所实际想展示的内核上而非一些不重要的代码,我会在代码中使用一些工具方法而省略实现,这些工具方法如下:
/**
* 使用八位无符号二进制格式打印字节数组,末尾有换行符
* 示例:bytes = {1,2,3,4}
* 输出:00000001 00000010 00000011 00000100 [\n]
* @param bytes 要显示的字节数组
*/
void printBytesInBinaryFormat(byte bytes[])
/**
* 使用两位无符号十六进制格式显示字节数组,末尾有换行符
* 示例:bytes = {1,63}
* 输出:01 3f [\n]
* @param bytes 要显示的字节数组
*/
void printBytesInHexFormat(byte bytes[])
/**
* 将一批无符号整数转换成有符号字节数组
* @param numbers 要转换的一批无符号整数,方法假设对于每一个i,0 <= numbers[i] <= 255
* @return 返回bytes数组
*/
byte[] toSignedBytes(int...numbers)
这些工具方法的实现我会放到文章最后
某些时候我会使用断言来判断两个值是否相等,如
assertEquals(a,b)
如果a.equals(b)==true,那么断言成立,什么都不会发生,如果a.equals(b)==false,那么断言不成立,抛出异常,程序结束。
assertEquals是大部分测试框架开箱即用的功能,对于没使用过测试框架的朋友,assertEquals的一个简单实现如下:
void assertEquals(Object a, Object b) {
if(!a.equals(b)) {
throw new AssertException(
"Assert Exception: \n" +
"\tExcept: " + a + "\n" +
"\tActual: " + b
);
}
}
ASCII
嘶,学计算机的最初认识的就是这个吧,我还记得在中专的时候上C语言课用的那个古老编程环境甚至只支持ASCII编码。
ASCII(美国标准信息交换码),这种编码很简单,是一种单字节编码,也就是说每个字符被编码成一个字节,并且在ASCII编码中这个字节的最高位还空着,只用最低七位存储。也就是说它最多只支持\(2^7=128\)个字符。
请原谅我为了方便演示而在测试方法中使用输出语句,这是不好的写法。忽略这些,这段代码的含义就是打印出将字符串hello用ASCII编码编成的字节数组。string.getBytes(encoding)方法将字符串string用encoding编码格式进行编码,并返回编码后的字节数组。
void testAsciiEncoding() {
byte bytes[] = "hello".getBytes(StandardCharsets.US_ASCII);
printBytesInBinaryFormat(bytes);
}
结果如下:
01101000 01100101 01101100 01101100 01101111
从结果可以看出,每个字符被编码成了一个八位二进制数,也就是一字节,最高位没有用到,所以都是0。
我不会介绍ASCII码以及后面任何编码中各种字符所在的区域范围(比如97~122为a-z),因为这只需要动动手指就能查到。
几乎所有当前通用的编码都兼容ASCII(即ASCII表中的这128个字符在其他兼容ASCII的编码中也用同样的数字表示),也就是说如果一段文字中只包含ASCII表中存在的字符,那么你随便用什么编码格式进行编解码,只要编码和解码的格式都兼容ASCII,结果就不会乱码,这也就是英文几乎不会乱码的原因。
以下代码使用UTF-8编码,并分别使用GBK、GB2312和ISO-8859-1解码,因为测试使用的字符串中的每个字符都在ASCII表中,并且用于解码的编码格式都兼容ASCII,所以可以通过测试。需要说明的是,new String(bytes, encoding)将bytes按照encoding解码,生成一个字符串实例。
void testAsciiCompatibility() {
byte bytes[] = "hello".getBytes(Charset.forName("UTF-8"));
assertEquals("hello", new String(bytes, Charset.forName("GBK")));
assertEquals("hello", new String(bytes, Charset.forName("GB2312")));
assertEquals("hello", new String(bytes, Charset.forName("ISO-8859-1")));
}
以下代码不能通过测试
void testAsciiCompatibility2() {
byte bytes[] = "你好".getBytes(Charset.forName("UTF-8"));
assertEquals("你好", new String(bytes, Charset.forName("GBK")));
assertEquals("你好", new String(bytes, Charset.forName("GB2312")));
assertEquals("你好", new String(bytes, Charset.forName("ISO-8859-1")));
}
之所以没有测试UTF-16,是因为它不兼容ASCII。
ISO-8859-1
也是一个单字节编码,兼容ASCII,它将一个字节的最高位也用上了。第128—255个字符(其实是160—255,128—159在ISO-8859-1中并没有被使用,是空的)是在ASCII的基础上新增的字符,用于表示一些西欧语言比如希腊语。
ISO-8859-1的另一个名字是Latin-1,也就是MYSQL数据库的默认编码。
编码黑洞
以下代码打印出hello你好按照ISO-8859-1格式进行编码后的二进制和十六进制数字。
void testISO8859_1(){
byte bytes[] = "hello你好".getBytes(StandardCharsets.ISO_8859_1);
printBytesInBinaryFormat(bytes);
printBytesInHexFormat(bytes);
}
结果
01101000 01100101 01101100 01101100 01101111 00111111 00111111
68 65 6c 6c 6f 3f 3f
可以看到,"你好"两个字符被编码成了同样的数字,就是十六进制的3f。在ISO-8859-1中,所有它不支持的字符都会被编码成3f。
3f转换成十进制是63,也就是会显示成ISO-8851-1编码表中第63个字符,第63个字符是?。

所以,如果我们看到字符显示成了"??????",那多半就是错误的使用了ISO-8859-1进行编码导致的。
PS: ASCII码也有类似的编码黑洞的问题,不过好像没有什么现代程序使用纯ASCII编码了
GB2312和GBK
GB2312是在ASCII基础上扩展的一套编码表,支持简体中文。
既然要支持中文,肯定不能是单字节编码了,毕竟一个字节顶多只能表示256个字符,肯定容纳不下汉字。
GB2312中对于单字节能容纳下的那些字符(小于0xff),比如ASCII表中的所有字符,它们使用一个字节表示,对于单字节不能容纳下的那些字符,使用两个字节表示。
void testGB2312() {
byte bytes[] = "hello你好".getBytes(Charset.forName("GB2312"));
printBytesInHexFormat(bytes);
}
如下第二行是输出结果,第一行是原字符串中的每个字符在结果中对应的位置
h e l l o 你 好
68 65 6c 6c 6f c4 e3 ba c3
比如上面的字符,hello中的每个字母被变成一个字节,和ASCII、ISO-8859-1完全一致,而“你”被编成了两个字节c4 e3,“好”被编成了两个字节ba c3。
嘶,那么如何知道ba c3是一个双字节字符而不是两个单字节字符呢?GB2312对字符做了分区处理,其中有很多空着的位置,比如ba,GB2312中就没有ba对应的单字节字符,所以看到ba就知道它要与后面的一个字节组成一个双字节字符了。
如下测试试图将单独的ba按照GB2312编码,又将ba和c3一起按照GB2312编码:
void testGB2312_2() {
String string = new String(
toSignedBytes(0Xba),
Charset.forName("GB2312")
);
System.out.println(string);
String string2 = new String(
toSignedBytes(0Xba, 0Xc3),
Charset.forName("GB2312")
);
System.out.println(string2);
}
得到的结果是:
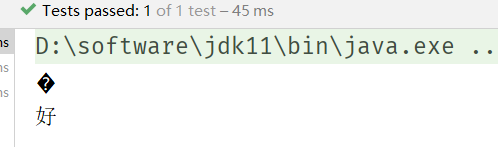
GBK与GB2312的区别就是,GBK扩展了GB2312,除了支持简体中文外,还支持所有亚洲文字,如日本语、汉语、繁体中文等。GBK兼容GB2312,所以使用GB2312编码的内容完全可以用GBK来解码。
Unicode
Unicode(Universal Code, 统一码),是一套ISO定义的规范,试图将世界上所有国家的文字创建统一的编码规则。
Unicode的实现有很多,比如UTF-8、UTF-16等。
Utf-16
Utf-16是定长双字节编码格式,它不会像GBK和GB2312那样在非必要时用单字节表示,即使是单字节完全能够表示的数据,也要用双字节来表示,所以它不能兼容ASCII。
void testUTF16() {
byte bytes[] = "hello你好".getBytes(StandardCharsets.UTF_16);
printBytesInHexFormat(bytes);
}
Unicode编码允许在最前面加上两个字节的BOM,这样解码端就知道该用什么具体编码规则来解码,下面的前两个字节fe ff就是代表名为ZERO WIDTH NO-BREAK SPACE的BOM。
对于剩余的字符,不管它能否用单字节表示,都会被编码成一个双字节数字,高位补零。
h e l l o 你 好
fe ff 00 68 00 65 00 6c 00 6c 00 6f 4f 60 59 7d
所以UTF-16并不兼容ASCII。
@Test
void testUTF16Compatibility() {
byte bytes[] = "hello".getBytes(StandardCharsets.UTF_16);
assertEquals("hello", new String(bytes, Charset.forName("ASCII")));
}
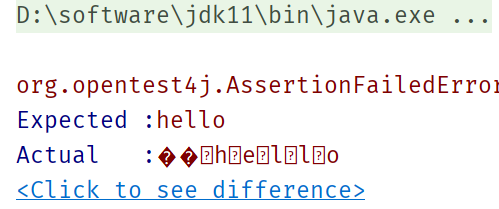
Utf-8
Utf-8是变长格式,对单字节字符用1个字节表示,对一些西欧字符用2个字节表示,对汉字等东方字符用3个字符表示,极少字符用4个字节表示。
Utf-8变长格式的原理如下:
- 如果有一个字节,以0开头,该字节代表了一个单字节字符
- 如果有一个字节,以10开头,该字节不是一个编码字符的首字节,需要向前查找它的首字符
- 如果有一个字节,以11开头,代表它是一个编码字符的首字节,连续1的个数是该字符占用的字节数
void testUTF8() {
byte bytes[] = "hello你好".getBytes(StandardCharsets.UTF_8);
printBytesInBinaryFormat(bytes);
printBytesInHexFormat(bytes);
}
01101000 01100101 01101100 01101100 01101111 11100100 10111101 10100000 11100101 10100101 10111101
68 65 6c 6c 6f e4 bd a0 e5 a5 bd
何时会出现编码/解码
了解了编码/解码的原理以及常见编码格式,下面就要了解何时会出现编码/解码。
编码一般出现在将内存中的字符串写入到其他位置时,比如写入到文件、发送网络请求。Java默认的内存中的编码格式是UTF-16,也就是说Java中的一个char占用2个字节。
解码一般出现在从外部读入字符串时,比如读文件,接收网络请求。
还有一部分情况,我们会在内存进行编码,这里列举出Java中常见的几个编解码的例子:
- Servlet接收到用户访问的HTTP请求时,要对请求的各个部分进行解码
- Servlet响应用户时,要将响应的内容按照某种格式进行编码。
- Java编译器读取java源文件时,会按照某种编码格式解码文件中的文本内容(由-Dfile.encoding参数指定)
- 和数据库进行交互的时候,会按某种编码格式对数据库返回的内容进行解码
- ...
URLEncode
当你发送的URL字符中包含任何非ASCII字符时,浏览器就会对你发送的URL进行URL编码(URLEncode),这个编码和我们之前说的将字符编码成二进制数字不一样,而是把非ASCII字符编码成ASCII字符。
我们通过Edge浏览器随便发送点带中文的URL,它会被编码成下面的内容并发送:
原URL:
http://abc.d/中文?a=中文
编码后的URL:
http://abc.d/%E4%B8%AD%E6%96%87?a=%E4%B8%AD%E6%96%87
其实就是将非ASCII字符以UTF-8格式编码,并将每个字节前加上%。
不同浏览器对URL的编码方式不一致,也就是说不一定所有浏览器都采用UTF-8进行编码,甚至同一个浏览器对URL的路径和querystring的编码方式都不一致,而且这个默认编码格式大部分是可以让用户修改的。所以尽量不要在URL中传递中文,如果非要传递,请先自己选择一个编码格式对URL进行编码,别让浏览器帮你编码。
在Java中可以通过如下两个方法进行编解码
URLEncoder.encode(string, charset)
URLEncoder.decode(string, charset)
在JavaScript中可以通过encodeURI或encodeURIComponent来进行编码
进入正题
下面就是解决那四个项目中所有的编码问题了,项目的代码有点。。。一言难尽,不知道从哪复制的,不管了,我们就分析、解决它就完了、
文件以错误的编码格式打开
第一个错误就是,当我打开一个预备好的sql文件时,我发现这个文件中的中文全部乱码了。
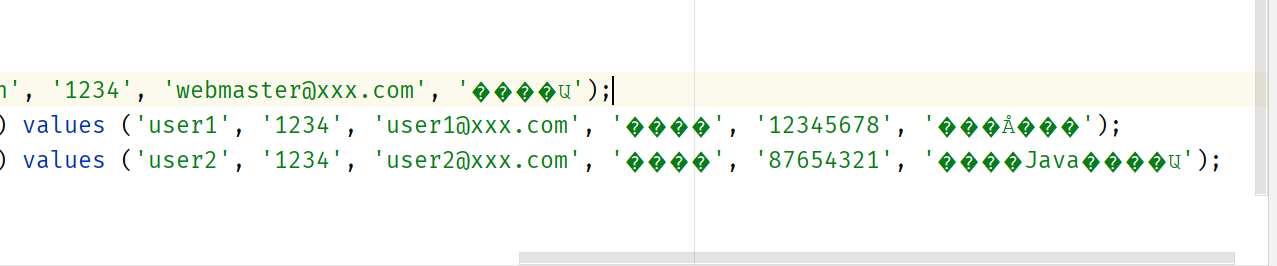
并且IDEA弹出了这样的提示
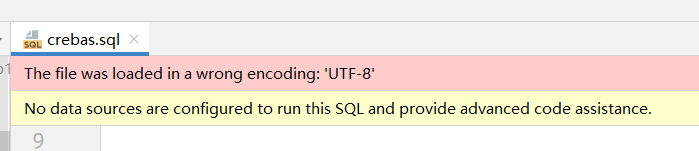
貌似是它检测出了我们使用了错误的编码格式来解码这个文件,我们使用的是UTF-8,而以老师的习惯,我猜。。。这个文件实际应该是使用GBK进行编码的,因为编码和解码使用的编码方式不一致,所以出现了乱码,所以我们要改用GBK进行解码。
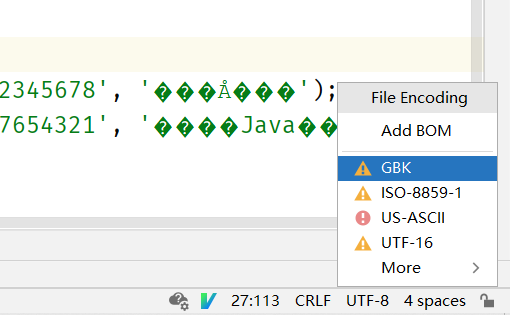
问题解决

URL中的编码错误
在我注册时,填写了注册信息之后,点击提交,页面就会跳转到主页

跳转到主页后,左上角有个什么东西发生了乱码
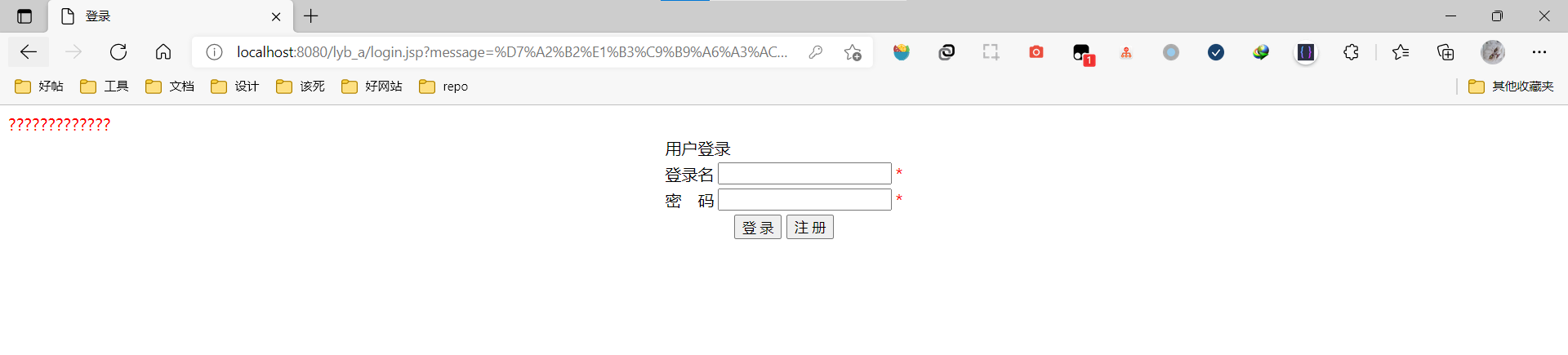
从URL分析来看,是注册页面表单提交后,服务器执行完,将注册的执行结果以一个URL querystring的方式传递到了登录页,这个参数名是message,然后登录页将这个参数渲染到页面上用户就知道注册的结果了。
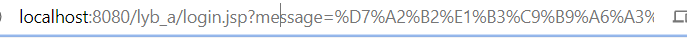
快速查看这部分代码:
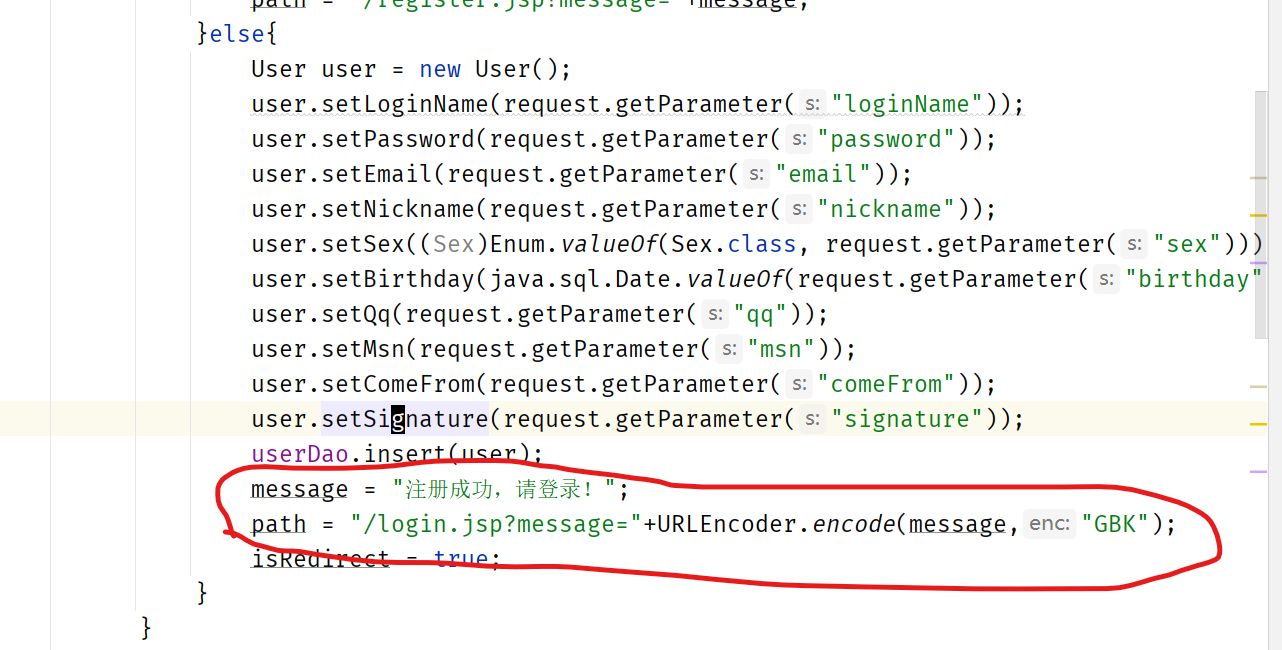
这里就是服务器操作DAO进行插入操作后跳转到首页并通过querystring传递操作结果的代码,我们看到这里后端使用GBK对message进行URL编码,然后进行重定向到login.jsp页面,当服务器接收到客户端重定向过来的请求后,服务器必须以GBK对URL进行解码才能收到正确的内容。
默认情况下,Tomcat会先使用ISO-8859-1对URL进行解码,对于Query String,可以配置它使用Header中的ContentType进行解码,但当没配置时,默认也是采用ISO-8859-1进行解码,也就是因为这个原因,ISO-8859-1特有的编码黑洞问题出现了。
我们可以修改Tomcat的配置,在Connector上添加URIEcoding属性,Tomcat就会对URL和querystring使用gbk进行解码。如果想要让querystring根据请求header中的Content-Type进行解码的话,使用useBodyEncodingForURI="true"(因为有的浏览器会这样编码querystring),需要特别注意的是useBodyEncodingForURI属性仅仅影响querystring,但它取了这么个让人迷糊的名字。
<Connector URIEncoding="gbk"/>
反正我记得我昨天给小姐姐解决的时候不是这么弄的,我也不知道我咋弄的,反正瞎鼓捣鼓捣好了。好像是因为Tomcat8.x的版本默认使用UTF-8对QueryString进行解码,所以我让Servlet使用UTF-8对URL进行编码就好了,也就是把代码改成这样

要注意的是,转发(forward)的时候没这种问题,因为转发不涉及到编码解码。
也是同一个Servlet中的这些代码,完全没有编码,但也不会出现编码问题。

静态文件编码与响应头中指定的编码不一致
找回密码的页面直接乱码
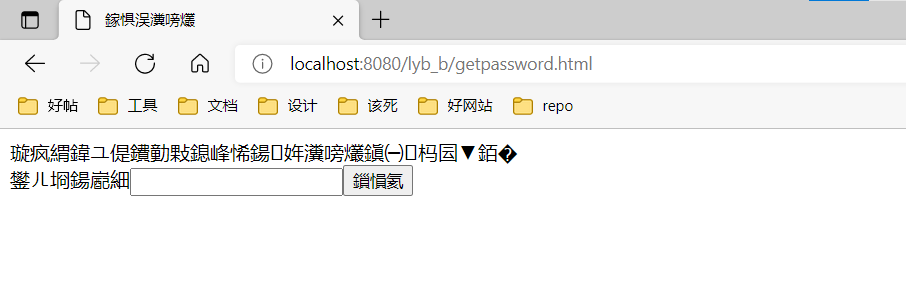
getpassword.html作为服务器端的一个静态网页文件为用户提供交互,这中间的过程是这样的:
- 服务器程序设计者编写了
getpassword.html文件,这个文件以程序设计者在所使用的编辑器上预先设定的编码格式进行编码,并以二进制的形式保存在服务器磁盘上。 - 客户端请求这个静态资源文件,服务器端从磁盘上读取这个文件到内存(默认是以平台默认编码格式读取,在中国的Windows机器上应该是GBK,具体参见DefaultServlet.fileEncoding属性)
- 服务器端将读取到的文件发送给客户端,如果设置了
response.setCharacterEncoding,服务器会使用这个编码格式来发送静态资源,并给响应的Header的ContentType中添加对应的编码,保证发给客户端的数据的编码和客户端解码的方式一致 - 客户端收到响应后,会按照响应Header中的ContentType中配置的编码格式来进行解码
这里面一共有两次编码解码,一次是程序编写者编码服务器端程序解码,一次是服务器端程序编码,用户浏览器解码。这两次编解码过程中肯定有地方出了问题。
我们先去看看第一步,去查看getpassword.html文件的编码格式

getpassword.html文件的编码格式是非GBK,但服务器读取这个静态文件时使用的是GBK(或其他平台默认的编码格式),总之就是二者的编码没有一致。两个解决办法,第一个办法就是把getpassword.html改成平台默认的编码格式(也就是GBK),第二个办法就是设置DefaultServlet.fileEncoding为getpassword.html的实际编码格式。
对于前一个办法,我们可以像第一个问题一样的步骤把getpassword.html这个文件的编码转换成GBK,记得如果有缓存,请在浏览器端删除缓存(Ctrl+F5)。
这里演示第二个办法,在web.xml中添加如下代码,设置服务器读取静态资源文件时的fileEncoding。
<servlet>
<servlet-name>default</servlet-name>
<servlet-class>org.apache.catalina.servlets.DefaultServlet</servlet-class>
<init-param>
<param-name>fileEncoding</param-name>
<param-value>UTF-8</param-value>
</init-param>
</servlet>
总结
在我机器上能够复现出来的编码问题就这些了,其实这四个项目在其他人的机器上还有连数据库时的编码问题,这里就不说了。
总结几个好习惯
- 一个项目中的编码解码要统一,包括静态资源文件、服务器和数据库服务器的编码统一、前端与服务器的编码统一。在服务器端和前端,可以通过
request/response.setCharacterEncoding来设置编码格式。 - 不要在URL、Cookie中传递非ASCII字符,如非要传递,请进行URLEncode
- 尽量设置Tomcat对URL的解析方式
- 尽量使用Utf-8编码因为我喜欢
- 遇到乱码不要盲目的搜索、尝试、复制粘贴,思考哪个环节出现了编解码操作,又是哪个环节导致的乱码。不要瞎猫碰死耗子。
关于编码问题,本文还不够全面,因为毕竟只是针对期末作业的四个项目中的问题来编写的,如果还有任何其他方面的疑问,第一个推荐的是去查询API,API才是开发人员获取消息的首选方式,因为它是没经过任何第三人曲解的一手官方消息,第二个推荐的,可以看看君山老师的《深入分析JavaWeb技术内幕》,也是本笔记主要参考的对象。
代码
测试类:
package top.yudoge.encoding;
import org.junit.jupiter.api.Test;
import java.nio.charset.Charset;
import java.nio.charset.StandardCharsets;
import static org.junit.jupiter.api.Assertions.*;
import static top.yudoge.encoding.Utils.*;
public class EncodingTest {
@Test
void testAsciiEncoding() {
byte bytes[] = "hello".getBytes(StandardCharsets.US_ASCII);
printBytesInBinaryFormat(bytes);
}
@Test
void testAsciiCompatibility() {
byte bytes[] = "hello".getBytes(Charset.forName("UTF-8"));
assertEquals("hello", new String(bytes, Charset.forName("GBK")));
assertEquals("hello", new String(bytes, Charset.forName("GB2312")));
assertEquals("hello", new String(bytes, Charset.forName("ISO-8859-1")));
}
@Test
void testAsciiCompatibility2() {
byte bytes[] = "你好".getBytes(Charset.forName("UTF-8"));
assertEquals("你好", new String(bytes, Charset.forName("GBK")));
assertEquals("你好", new String(bytes, Charset.forName("GB2312")));
assertEquals("你好", new String(bytes, Charset.forName("ISO-8859-1")));
}
@Test
void testISO8859_1(){
byte bytes[] = "hello你好".getBytes(StandardCharsets.ISO_8859_1);
printBytesInBinaryFormat(bytes);
printBytesInHexFormat(bytes);
}
@Test
void testGB2312() {
byte bytes[] = "hello你好".getBytes(Charset.forName("GB2312"));
printBytesInBinaryFormat(bytes);
printBytesInHexFormat(bytes);
}
@Test
void testGB2312_2() {
String string = new String(
toSignedBytes(0Xba),
Charset.forName("GB2312")
);
System.out.println(string);
String string2 = new String(
toSignedBytes(0Xba, 0Xc3),
Charset.forName("GB2312")
);
System.out.println(string2);
}
@Test
void testUTF16() {
byte bytes[] = "hello你好".getBytes(StandardCharsets.UTF_16);
printBytesInHexFormat(bytes);
}
@Test
void testUTF16Compatibility() {
byte bytes[] = "hello".getBytes(StandardCharsets.UTF_16);
assertEquals("hello", new String(bytes, Charset.forName("ASCII")));
}
@Test
void testUTF8() {
byte bytes[] = "hello你好".getBytes(StandardCharsets.UTF_8);
printBytesInBinaryFormat(bytes);
printBytesInHexFormat(bytes);
}
}
Utils
package top.yudoge.encoding;
public class Utils {
/**
* 使用二进制格式显示字节数组
* @param bytes 要显示的字节数组
*/
public static void printBytesInBinaryFormat(byte bytes[]) {
for (int i=0; i<bytes.length; i++){
printByteInBinaryFormat(Byte.toUnsignedInt(bytes[i]));
System.out.print(" ");
}
System.out.println("\n");
}
/**
* 使用十六进制格式显示字节数组
* @param bytes 要显示的字节数组
*/
public static void printBytesInHexFormat(byte bytes[]) {
for (int i=0; i<bytes.length; i++){
printByteInHexFormat(Byte.toUnsignedInt(bytes[i]));
System.out.print(" ");
}
System.out.println("\n");
}
/**
* 将一批无符号整数转换成字节数组
* @param numbers 要转换的一批无符号整数,要求0< numbers[i] <=255
* @return 返回bytes数组
*/
public static byte[] toSignedBytes(int...numbers) {
byte bytes[] = new byte[numbers.length];
for (int i=0; i < bytes.length; i++) {
int unsignedByte = numbers[i];
bytes[i] = unsignedByte > 127 ? (byte)(unsignedByte-256) : (byte)unsignedByte;
}
return bytes;
}
public static void printByteInBinaryFormat(int b){
System.out.printf("%08d",Integer.parseInt(Integer.toBinaryString(b)));
}
public static void printByteInHexFormat(int b) {
String hex = Integer.toHexString(b);
if (hex.length()==1)hex = "0"+hex;
System.out.print(hex);
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号