中级SQL
连接表达式
连接条件
自然连接只有当指定属性相等时才能将两个表进行连接,而on可以指定自定义的任意连接条件。
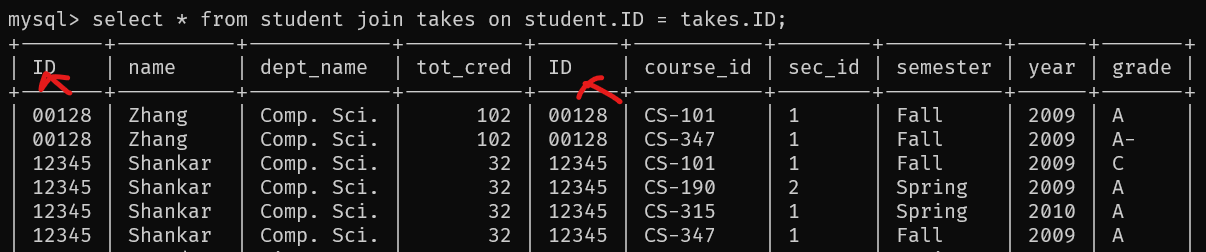
如下SQL找出了所有学生的所有选课。
select *
from student join takes
on student.ID = takes.ID;
和自然连接不一样的就是,自然连接会在结果中自动去除它检测的两个关系中的相同属性,而在join on中,ID属性出现了两次。
上面的查询和下面的等价
select *
from student, takes
where student.ID = takes.ID;
如果你不像显示两个ID,那么就要手动在select后面的属性列表中手动指定要显示的所有属性。
on在外连接的情况下与where子句的表现不同,并且,把通过相同属性来连接两个关系的谓词放在on中,比放在where中可读性要好。
外连接(outer join)
假如要显示所有学生,并显示它们选的所有课程,那么使用natural join得到的结果可能和预期不一致,如果一个学生根本没有选课,那他的ID属性不会和选课关系中的任何一个元组的ID属性匹配,所以它不会出现在结果中。
SELECT * from student
natural join takes;
执行结果

外连接通过显示空值的方式来保留这些在另一个表中不存在的数据。例如有一个学生Snow,它不存在于选课表中,那么外连接中也会包含他,但是结果中Snow那个元组关于选课表中的属性都为空。
外连接分为:
- 左外连接(left outer join):保留出现在连接操作左边的关系中的元组
- 右外连接(right outer join):保留出现在连接操作右边的关系中的元组
- 全外连接(full outer join):保留出现在两个关系中的元组
之前的连接称为内连接(inner join)
select * from student
natural left outer join takes;
结果比之前多了一行

物理系的名为Snow的学生是没有选课的,所有选课表中的属性在他连接后所在的元组中都为NULL

右外连接和左外连接对称
select * from takes
natural right outer join student;
全外连接的例子
显示Comp. Sci.系的所有学生以及他们在2009年春季选修的所有课程段的列表,2009年春季的课程段必须显示,即使没有学生选修它。
select * from student
natural full outer join takes
on dept_name = 'Comp. Sci.' and semester='Fall' and year = 2009;
mysql不支持全外连接,没法测试
这是书上给的答案
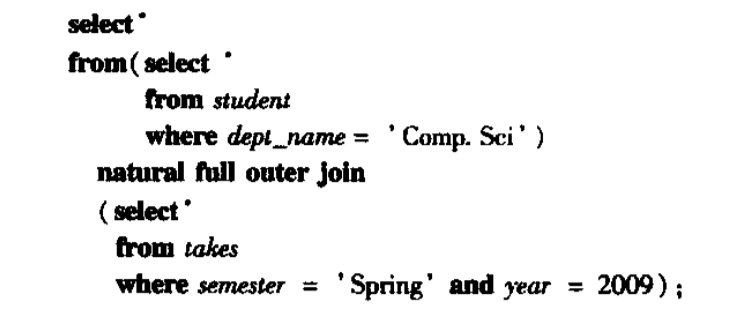
还有就是where和on的区别,on是在创建外连接的过程中的谓词,而where是对连接结束后产生的关系应用的谓词。
比如书上的这个例子
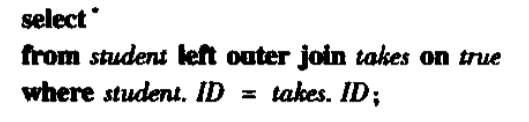
这行代码因为on条件为true,所以产生两个表的笛卡尔积,因为没有不满足的条件,然后再去过滤where student.ID=takes.ID,那么当学生表中有没选课的,他们又不会出现在结果中了。
视图
创建并使用视图
我们可能频繁的需要获取一个关系中的一部分,而不是整个关系,比如:
select ID, name, dept_name
from instructor;
在不关心教师的工资时,我们经常会使用上面的语句,这个例子还不算复杂,如果我们想频繁的查询2009年秋季物理系开设的课程列表,包含课程id,时间段id,教学楼和房间号,那么就要编写如下sql:
select course_id, sec_id, building, room_number
from course natural join section
where dept_name = 'Physics'
and semester = 'Fall'
and year = 2009;
一个办法是把这个查询得到的关系存到本地,然后每次用户查询,把这个关系直接返回给用户。但是如果course和section关系稍有变动,我们之前存到本地的结果旧可能是不准确的旧数据了。
视图则是存储这个查询语句,作为一个虚关系,然后每次用户查询这个虚关系时,去执行视图指定的查询。
create view physics_fall_2009 as
select course_id, sec_id, building, room_number
from course natural join section
where dept_name = 'Physics'
and semester = 'Fall'
and year = 2009;
然后我们像可以查询一个真正存在的关系一样查询这个视图
select * from physics_fall_2009
where building = 'Watson';
由于Select语句返回的是一个关系,所以视图返回的结果能够像真正查询关系一样被使用在from子句里。
物化视图
一些数据库系统允许将视图返回的关系存储起来。
这就要考虑如何在视图依赖的关系更新时更新本地的物化视图了。一般有两种办法
- 当视图中依赖的关系更新时,立即更新物化视图
- 周期性的更新物化视图
第一种所消耗的系统资源更高,会拖慢响应速度,第二种不会,但可能会从物化视图中读取到过时数据。
具体还要看系统需要更快的响应性还是更精确的数据。
视图更新
如果对这样一个视图进行更新
create view faculty as
select ID, name, dept_name
from instructor;
insert into faculty
values('20111', 'Green', 'Music');
该如何处理呢?因为视图中只包含了它所依赖的关系中的部分属性,salary属性它都没有。唯一的办法,当salary不为not null时,可以考虑向视图中插入
instructor ('20111', 'Green', 'Music', null)
这还能够处理,如果是一个更加复杂的视图,
create view instructor_info as
select ID, name, building
from instructor, department
where instructor.dept_name = department.dept_name;
这个视图列出的是每个教师的ID,name和所在系的建筑名。
如果我们向这个视图中插入数据,因为我们列出的只有教师ID,姓名和系所在的建筑,我们根本没法指定教师在哪个系,就算我们插进去了,结果也不会包含在视图中,因为视图依赖系名做判断。
所以视图的更新很麻烦,一般有如下限制:
from子句中只有一个关系select子句中只包含关系的属性名,不包含表达式、聚集函数或distinct- 没有出现在
select子句中的属性没有not null限制 - 查询中没有
group by和having
具体SQL实现的限制不同。
即使符合限制,还会有一些问题,比如如下视图
create view history_instructors as
select * from instructor
where dept_name = 'History';
如果你插入
history_instructors ('25566', 'Brown', 'Biology', 100000)
那么视图查询不到这条数据,因为它的dept_name字段不在视图的SQL查询的范围内。
可以向定义视图语句的末尾添加with check option,这样向视图中插入数据时会预先检测插入的数据是否符合视图where子句中的条件。如果不符合则拒绝插入。
完整性约束
保证用户的修改不会破坏数据库的一致性,一般有如下完整性约束的例子:
- 限制属性不能为null
- 限制元组中某些属性不能重复,比如说不能有相同的教师ID
- course关系中的某个系名必须在department关系中有一个对应的系名
- 系的预算必须大于0
not null
可以指定一个属性不允许为空
create table x (
y varchar(10) not null
);
SQL定义了主码不能为null,所以主码可以省略not null.
unique
unique定义了同一个关系的元组中的某些属性不能有重复值。
比如unique(A1,A2,A3),指定一个关系中不能存在这样两个元组,它们的A1、A2、A3属性相同。
这就构成了一个由A1,A2,A3组成的候选码,候选码可以为null。
check子句
可以使用check(salary > 0)来保证一个教师的工资不大于0的更改不会应用到数据库中。

上面的语句中使用check限制了semester属性只能在春夏秋冬四个季节中取值。
SQL标准中允许check使用子查询,但是好像没有哪个实现了。
参照完整性
想要限制在一个关系中的属性在另一个关系中出现,需要使用参照完整性。
比如想要course中插入的课程的dept_name字段,必须在department表中有了这个系,也就是department表中也有dept_name属性相同的元组。
可以用如下代码表示
foreign key(dept_name) references department
默认情况下,SQL外键中的key指定的是当前关系中的属性,它要参照的是被参照表的主码。
SQL还允许key中指定一系列属性,这些属性必须在被参照表中被定义成了候选码(unique)。
默认情况下,当对关系的修改违反了参照完整性约束时,应该拒绝执行这条语句,但SQL也允许你做一些其他操作。

比如这条语句,当在department中删除一个course中依赖的系时,系统并不会拒绝,而是级联删除course中所有的课程。对于更新也是一样的。
除了cascade,还可以设置on delete set null或on delete set default在删除时为另一个关系中的相关属性设置为null或默认值。
事务对完整性约束的违反
假如有一个person表,主码是id,它有一个属性是spouse,代表这个人的配偶,并且参照person表的id属性。
这时无论你怎么插入,都无法满足参照完整性约束,因为你无法同时插入两条数据,插入男方时,由于配偶还未插入,所以spouse不满足参照完整性约束,只有女方的数据也被插入后,两个参照完整性约束才被满足。
SQL标准允许向声明中添加initially deferred,只在事务提交后进行参照完整性检查,而非每一个中间步骤。
授权
可以对每一个连接到数据库的用户分别独立的授予增删改查权限。
权限作用在关系或视图上,如果用户对关系或视图进行了它无权限的操作,数据库将拒绝该操作。
权限的授予与收回
授权的基本命令格式如下
grant <权限列表>
on <关系或视图名>
to <用户/角色列表>
权限列表可以是select、insert、upda*te和delete,all priviledges是所有权限的简写。
grant select on department to Amit, Satoshi;
现在这两个用户可以在department表中执行查询了。
用户创建关系后自动享有对该关系的所有权限
用户名public代表对系统当前的所有用户和未来用户都赋予权限
使用revoke可以收回权限
revoke <权限列表>
on <关系或视图名>
to <用户/角色列表>
角色
学校有成百上千的教师,为他们分别授权是不明智的。有两个解决办法:
- 所有教师分配一个统一的用户
- 将对教师的授权存储成一个模板,为每个教师用户直接分配这个模板
第一个确实很方便,但缺点是我们无法知道是谁进行了操作。第二个是比较好的做法。
角色就是第二个办法里说的这个模板。
# 创建角色
create role instructor;
# 对角色授权
grant select on takes to instructor;
# 赋予用户角色
grant instructor to Amit;
在SQL中除了赋予用户角色还可以赋予一个角色角色。被赋予的角色会继承旧角色的所有权限。
视图权限
比如一个工作人员,它只能看Geology系的员工工资,那么我们需要使用一个视图来返回他需要的关系,然后禁止它直接访问instructor。
和创建关系不一样,创建视图的用户并不一定获取这个视图的全部权限,他获得的权限取决于他对视图依赖的关系的权限。比如他不具有创建的视图依赖的关系的update权限,那么他就会没有视图的update权限。如果该用户没有关系的任何权限,系统会拒绝他创建视图。
权限的转移
在授权命令后面加上with grant option允许被授权的用户将权限授予其他人。
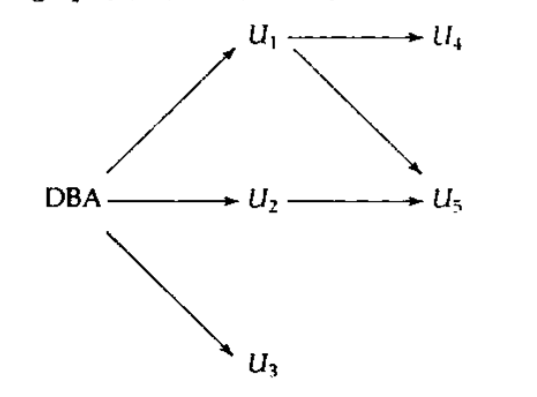
上图是数据库授权的权限图,DBA授予了U1,U2和U3权限,然后U1又授予了U4和U5权限,U2又授予了U5权限。
一个用户只有当从DBA处走到他所在位置的路径时才具有权限,比如DBA现在撤销U1的权限,那么默认情况下U4的权限也会被回收,U1赋予U5的权限也会被回收,不过现在仍然有一条路径从DBA到U5,即DBA->U2->U5,所以U5仍然有权限。
这种设计能够确保DBA一定能够回收权限,比如DBA先授予U2权限,U2再授予U3,然后U3再把权限回授给U2,这时如果DBA撤销U2的权限,从直觉来说,U2和U3依然具有权限,因为它俩互相授权了。但是U2和U3在权限图中都不具有DBA能够达到的路径了,所以他们都没有权限。
默认情况下权限是级联收回的,也可以在回收时在命令行末尾指定restrict,这样如果存在需要级联收回的请求,就报错,不进行回收。
revoke select on department from Amit restrict;
习题

题目的意思是他们讲授的课程数,而不是课程编号
select ID, name,count(sec_id) as cnt
from instructor natural left outer join teaches
group by ID, name;

select T.ID, name, S.cnt from instructor as T,
(
select ID, count(*) as cnt
from teaches
group by ID
) as S
where T.ID = S.ID;

select name, course_id
from (section natural left outer join teaches)
natural left outer join instructor
where semester = 'Spring' and year = 2010;
没老师教的课显示“——”不会。

select dept_name, count(*) as num
from department natural left outer join instructor
group by dept_name;
不使用外连接重写如下SQL语句,并且处理NULL情况

第一条语句是获取学生选课信息,左外连接保证了当有一个学生完全没选课(选课关系中没有他相关的元组)那么他也应该在结果关系中。如果我们不写外连接,用内连接或者使用where student.id = takes.id的方式,那么选课关系中没有的学生都不存在于结果中,这时可以专门查询在学生表但不在选课表中的学生,并且使用union操作将缺失的数据补回来。
select * from student natural join takes
union
select ID, name, dept_name, tot_cred, NULL, NULL, NULL, NULL, NULL
from student
where not exists(
select takes.ID
from takes where takes.ID = student.ID
);
第二条语句则是当有一个课程完全没人选的话,那么他也应该在结果关系中。这就用两个并集不就好了吗。

- a. r(A=1, B=2), s(B=1, C=2), t(B=2, D=1)
- b. 不可能,表达式1中若想要C为空,当且仅当s外连接t的结果关系中没有一条能够与r中的至少一条元组在属性B上匹配,这时C和D都应该为空。

select ID, name, sec_id, semester, year, time_slot_id,
count(distinct building, room_number) from instructor
natural join teaches
natural join section
group by ID, year, semester ,sec_id, time_slot_id
having count(concat(building, room_number)) > 1;
由于MYSQL不允许直接count多个字段,所以只能将他们连接起来,但是这样有可能在极端情况下出错。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号