Spring实战 十一 使用ORM框架
Spring提供spring-orm提供orm框架相关的支持。支持Hibernate、iBatis和JPA等。
导入
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-orm</artifactId>
<version>${spring.version}</version>
</dependency>
使用Hibernate框架
导入Hibernate核心库
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>${hibernate.version}</version>
</dependency>
创建SessionFactory
SessionFactory管理和产生Hibernate与数据库的会话,里面存储着DataSource对象。
下面的代码创建了SessionFactory的Bean对象。
@Bean
public LocalSessionFactoryBean localSessionFactoryBean(DataSource dataSource) {
LocalSessionFactoryBean factoryBean = new LocalSessionFactoryBean();
// 设置数据源
factoryBean.setDataSource(dataSource);
// 设置实体类(@Entity类)的位置,Hibernate会进行自动扫描
factoryBean.setPackagesToScan(new String[]{"io.lilpig.springlearn.springlearn02.web.domain"});
Properties properties = new Properties();
// 设置数据库方言
properties.setProperty("dialect","org.hibernate.dialect.H2Dialect");
factoryBean.setHibernateProperties(properties);
return factoryBean;
}
但是如下图LocalSessionFactoryBean和SessionFactory并无任何继承关系
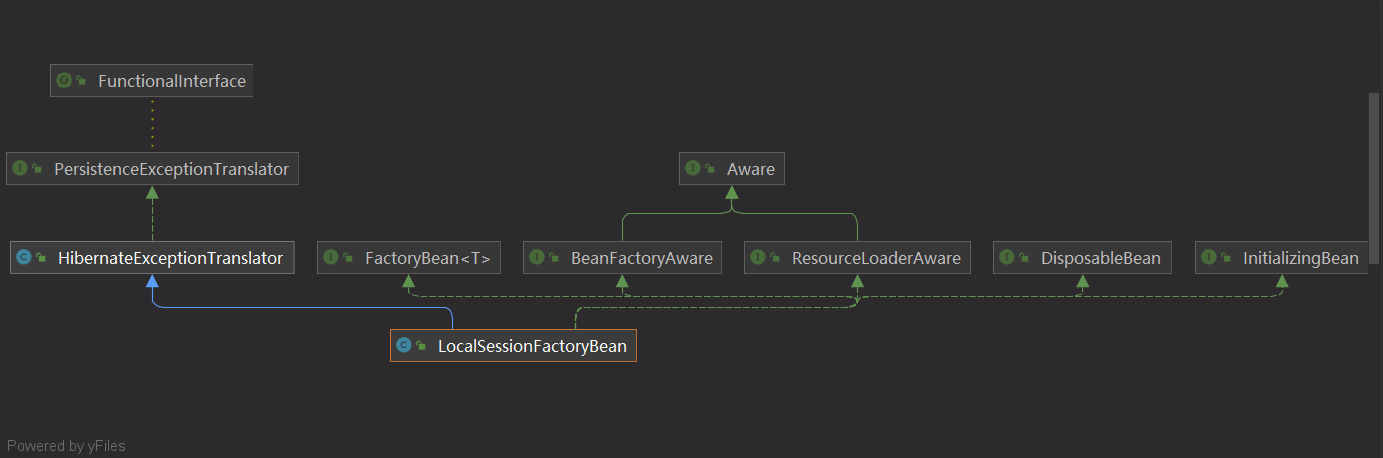
LocalSessionFactoryBean实现了Spring提供的FactoryBean接口,这个接口的作用就是以工厂模式创建一个Bean,有如下三个方法
public interface FactoryBean<T> {
String OBJECT_TYPE_ATTRIBUTE = "factoryBeanObjectType";
@Nullable
T getObject() throws Exception;
@Nullable
Class<?> getObjectType();
default boolean isSingleton() {
return true;
}
}
Spring在发现一个Bean是FactoryBean的实现类之后,会调用它的getObject方法,所以实际上创建的Bean不是这个FactoryBean而是类型为泛型T的Bean。而LocalSessionFactoryBean就实现了FactoryBean<SessionFactory>,所以实际上创建的Bean是SessionFactory。
LocalSessionFactoryBean使用的设计模式类似建造者,但是没有链式调用,它把所有的属性先缓存到自己身上,等到设置完成后再将它们一一设置给SessionFactory属性,然后在getObject中返回。
@Override
public void afterPropertiesSet() throws IOException {
if (this.metadataSources != null && !this.metadataSourcesAccessed) {
// Repeated initialization with no user-customized MetadataSources -> clear it.
this.metadataSources = null;
}
LocalSessionFactoryBuilder sfb = new LocalSessionFactoryBuilder(
this.dataSource, getResourceLoader(), getMetadataSources());
// 开始将this中缓存的设置设置给builder
if (this.entityInterceptor != null) {
sfb.setInterceptor(this.entityInterceptor);
}
if (this.implicitNamingStrategy != null) {
sfb.setImplicitNamingStrategy(this.implicitNamingStrategy);
}
if (this.physicalNamingStrategy != null) {
sfb.setPhysicalNamingStrategy(this.physicalNamingStrategy);
}
// 省略各种设置...
this.configuration = sfb;
// 使用builder构建sessionFactory
this.sessionFactory = buildSessionFactory(sfb);
}
总之,现在SessionFactory对象已经创建好了,Hibernate和数据库连接上了。
设置事务管理器
@Bean
public TransactionManager transactionManager(SessionFactory sessionFactory){
HibernateTransactionManager manager = new HibernateTransactionManager();
manager.setSessionFactory(sessionFactory);
return manager;
}
记得要在配置类上使用@EnableTransactionManagement开启事务管理
设置Spring的异常转换器
上一章,Spring的jdbcTemplate把jdbc中不清晰的SQLException映射成更加清晰的异常类型,如果我们改用ORM框架,这些异常类型就会变成ORM框架定义的异常类型。Spring的转换器可以为@Repository类的每个方法添加异常切面,将异常转换成熟悉的友好的Spring异常。
@Bean
public BeanPostProcessor persistenceTranslation() {
return new PersistenceExceptionTranslationPostProcessor();
}
实体类的设置
如果想让Hibernate能够发挥自动生成SQL的能力,还要在之前的实体类中进行一些设置。
@Entity
public class Spitter {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
// ...
}
首先在整个实体类上添加了@Entity注解,之前在LocalSessionFactoryBean中设置的setPackagesToScan方法会扫描指定包中有这个注解的类并将它们认为是需要Hibernate进行持久化的实体类。Hibernate认识的注解有JPA的@Entity,Hibernate自己的@Entity和JPA的@MappedSuperClass。
在主键上设置了@Id注解,Hibernate会知道这个字段是主键,并进行一些主键相关的特殊处理,比如插入自动返回主键。
@GeneratedValue是针对自增主键设置的注解,strategy是主键自增的策略,GenerationType.INDENTITY代表使用数据库标识列为实体分配主键。注意,GenerationType.AUTO并不是AUTO_INCREAMENT的对应策略,而是自动选择策略。
编写Repository实现类
要注意的就是试用@Transactional开启事务,注入sessionFactory并使用getCurrentSession获取当前线程的数据库会话。
@Repository
@Transactional
@Primary
public class HibernateSpitterRepository implements SpitterRepository{
private SessionFactory sessionFactory;
@Autowired
public HibernateSpitterRepository(SessionFactory sessionFactory){
this.sessionFactory = sessionFactory;
}
private Session currentSession() {
return sessionFactory.getCurrentSession();
}
@Override
public int save(Spitter spitter) {
System.out.println("hibernate save...");
Serializable id = currentSession().save(spitter);
return 1;
}
@Override
public Spitter getOne(Long id) {
System.out.println("hibernate getOne...");
return currentSession().get(Spitter.class, id);
}
@Override
public Spitter getOneByUserName(String username) {
System.out.println("hibernate getByUserName...");
return (Spitter) currentSession()
.createCriteria(Spitter.class)
.add(Restrictions.eq("userName",username))
.list().get(0);
}
public List<Spitter> findAll() {
return (List<Spitter>) currentSession()
.createCriteria(Spitter.class).list();
}
}
使用JPA
JPA是Java Persistence API(Java持久化接口),是Java定义的持久化规范。
实体管理器工厂
JPA中使用EntityManager类来操作实体,它封装了对实体的增删改查操作。实体管理器工厂是用来创建实体管理器的。
配置实体管理器工厂有两种办法,应用程序管理和容器管理,应用程序管理是由应用自己接管打开关闭实体管理器和事务控制,容器管理把这些功能托管给容器,同时保留一些配置权限。
Spring提供了两个工厂Bean来实现这两种管理器工厂。
LocalEntityManagerFactoryBean:生成应用程序管理类型的EntityManagerFactoryLocalContainerEntityManagerFactoryBean:生成容器管理类型的EntityManagerFactory
配置容器类型的实体管理器工厂
@Bean
public LocalContainerEntityManagerFactoryBean entityManagerFactoryBean(
DataSource dataSource, JpaVendorAdapter vendorAdapter) {
LocalContainerEntityManagerFactoryBean emfb
= new LocalContainerEntityManagerFactoryBean();
emfb.setDataSource(dataSource);
emfb.setJpaVendorAdapter(vendorAdapter);
emfb.setPackagesToScan("io.lilpig.springlearn.springlearn02.web.domain");
return emfb;
}
没啥好说的,都差不多,jpaVendorAdapter是其他厂家的jpa实现,因为jpa只是个标准,需要有一个实现,这里我们采用Hibernate的jpa实现。
@Bean
public JpaVendorAdapter jpaVendorAdapter() {
HibernateJpaVendorAdapter adapter = new HibernateJpaVendorAdapter();
adapter.setDatabase(Database.H2);
adapter.setShowSql(true);
adapter.setGenerateDdl(false);
adapter.setDatabasePlatform("org.hibernate.dialect.H2Dialect");
return adapter;
}
编写Repository
使用@PersistenceUnit注入EntityManagerFactory,但是问题在于每次都要创建EntityManager好像并不能复用EntityManager。
@Repository
@Primary
@Transactional
public class JpaSpitterRepository implements SpitterRepository{
@PersistenceUnit private EntityManagerFactory emf;
@Override
public int save(Spitter spitter) {
emf.createEntityManager().merge(spitter);
return 1;
}
@Override
public Spitter getOne(Long id) {
return emf.createEntityManager().find(Spitter.class, id);
}
// ...
}
使用@PersistenceContext可以注入一个EntityManager的代理对象,其实每次调用对应方法的时候调用的都是当前事务自己的EntityManager,如果没有就创建一个新的。
@Repository
@Primary
@Transactional
public class JpaSpitterRepository implements SpitterRepository{
// @PersistenceUnit private EntityManagerFactory emf;
@PersistenceContext private EntityManager em;
@Override
public int save(Spitter spitter) {
em.merge(spitter);
return 1;
}
@Override
public Spitter getOne(Long id) {
return em.find(Spitter.class, id);
}
// ...
}
要使用@PersistenceContext或@PersistenceUnit注解,要配置一个持久化注解的处理器,因为这些不是Spring的注解。
@Bean
public PersistenceAnnotationBeanPostProcessor annotationBeanPostProcessor() {
return new PersistenceAnnotationBeanPostProcessor();
}
Spring Data自动化实现JPA Repository
引入
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-bom</artifactId>
<version>2021.0.5</version>
<scope>import</scope>
<type>pom</type>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-jpa</artifactId>
</dependency>
<dependencies>
SpringData用于自动创建Repository实现类,像MyBatis那样。
实现JpaRepository接口
我重新编写了localSessionFactoryBean并设置成了主要Bean保证JpaRepository运行成功,原理我尚不明确。
// [+] 添加Bean Name
@Bean(name = "entityManagerFactory")
@Primary
public LocalSessionFactoryBean localSessionFactoryBean(DataSource dataSource) {
LocalSessionFactoryBean factoryBean = new LocalSessionFactoryBean();
factoryBean.setDataSource(dataSource);
factoryBean.setPackagesToScan(new String[]{"io.lilpig.springlearn.springlearn02.web.domain"});
Properties properties = new Properties();
properties.setProperty("dialect","org.hibernate.dialect.H2Dialect");
// 添加session上下文,基于thread
properties.setProperty("current_session_context_class","thread");
factoryBean.setHibernateProperties(properties);
return factoryBean;
}
下面编写接口
public interface AutoSpitterRepository
extends JpaRepository<Spitter,Long> {
}
这个接口继承JpaRepository并通过泛型指定了Bean类型为Spitter,主键类型为Long。然后Spring Data会自动生成这个接口的实现类,它的十几个方法可以直接供我们使用。
List<T> findAll();
List<T> findAll(Sort sort);
List<T> findAllById(Iterable<ID> ids);
<S extends T> List<S> saveAll(Iterable<S> entities);
void flush();
<S extends T> S saveAndFlush(S entity);
<S extends T> List<S> saveAllAndFlush(Iterable<S> entities);
/** @deprecated */
@Deprecated
default void deleteInBatch(Iterable<T> entities) {
this.deleteAllInBatch(entities);
}
void deleteAllInBatch(Iterable<T> entities);
void deleteAllByIdInBatch(Iterable<ID> ids);
void deleteAllInBatch();
/** @deprecated */
@Deprecated
T getOne(ID id);
T getById(ID id);
<S extends T> List<S> findAll(Example<S> example);
<S extends T> List<S> findAll(Example<S> example, Sort sort);
需要在配置文件上配置扫描包@EnableJpaRepositories(basePackages = "io.lilpig.springlearn.springlearn02.web.repository.auto"),Spring Data会扫描这个包下的接口生成对应的实现类。
扩展方法
public interface AutoSpitterRepository
extends JpaRepository<Spitter,Long> {
Spitter findByUserName(String username);
}
只需在这个接口中定义这个方法,也不需要实现,就能直接在Service或Controller中使用。
不是魔法,是SpringData定义了一套小型的领域特定语言(Domain-Specific Language, DSL),遵循这个语言进行命名,Spring就会生成对应方法的实现。
这个语言的格式大概如下动词+主题+By+断言。
比如findByUserName,find作为动词,主题省略了,因为方法返回值和类定义中的泛型都能够说明主题是Spitter了,断言就是UserName,这样,Spring会自动把domain对象中的userName属性给绑定到SQL的条件中。
SpringData支持四种动词,分别是get、read、find和count,前三个的作用一致,第四个count用于返回符合特定条件的结果的数量而不是结果本身。
下面是一个更长的例子
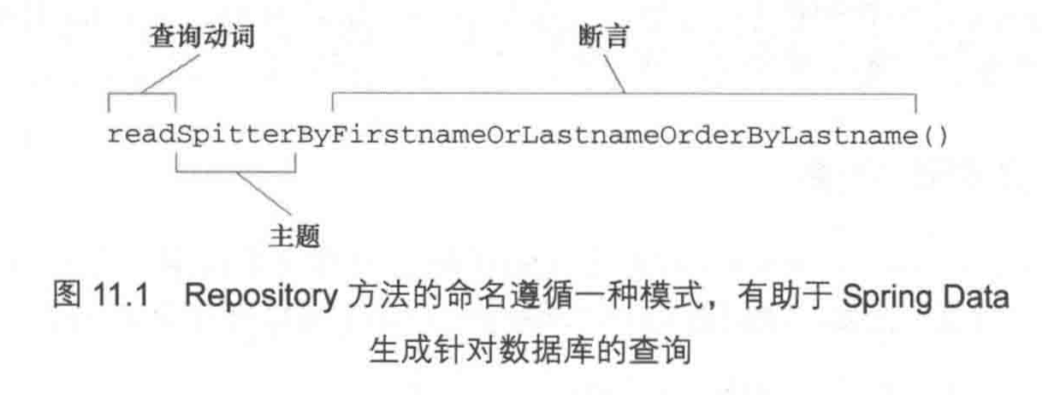
注意到断言阶段还可以有条件和OrderBy等子句。
主题名一般会省略,但当主题名以Distinct开头时会省略结果中重复的行。
断言中可以有一些比较语句作为限制条件,如下是可以使用的比较关键字(不知道怎么说了,只能用关键字)

处理字符串时还可以使用IgnoringCase/IgnoresCase来忽略大小写。

如果对全部条件都忽略大小写,那么可以在最后使用AllIgnoringCase或AllIgnoresCase

自定义查询
大部分高级方法往往不能适用于全部场景,一个好的设计应该是让高级方法在大部分时候能给人带来便利,并且保留低级的方法在高级方法没法奏效时也能够正常使用。
当自动化查询没法工作的时候,就可以使用自定义查询。
只需要使用@Query注解即可

指定注解后Spring Data会使用注解中的SQL语句生成实现类中的方法而不是解析方法名自动生成实现类中的方法。
当需要参数时也可以直接定义和语句中的参数名一样的方法参数即可。
混合自定义功能
如果自定义查询也用不了,可以使用混合自定义。
提供一个与Repository接口名相同的,后面加了Impl的类,像上面的例子就是AutoSpitterRepositoryImpl,SpringData在扫描原始接口的同时会扫描是否有这个类,如果有就将里面的方法与生成的实现类做合并,结果就是我们可以在生成的接口实现类中使用这两个类中定义的方法。

注意,AutoSpitterRepository接口也要实现SpitterSweeper

 浙公网安备 33010602011771号
浙公网安备 33010602011771号