JVM 三 类文件结构 上
概述
现代编程语言大多数都不再是直接编译成本地机器码了,因为都要跨平台了。具体的实现方法大概就是提供一个中间格式的平台无关的(甚至语言无关)字节码文件,然后语言开发商再去针对不同平台编写不同的运行系统去解释运行(不完全是解释运行)这些字节码文件。
Java的字节码文件就是.class文件,Java的运行系统就是Java虚拟机。
为什么说语言无关呢,因为Java在设计之初就有让Java语言和Java虚拟机设计解耦的想法,于是就开发了两套规范,一套是Java语言规范,一套是Java虚拟机规范,而Java编译器作为中间人,把符合Java语言规范的Java代码编译为Java虚拟机规范所定义的字节码。
这样一来,其他人也可以开发自己的语言并且设计一款能够编译成Java虚拟机规范定义的字节码文件的编译器,使自己的语言运行在Java虚拟机上。Kotlin、Groovy、JRuby、JPython都是比较成功的为我们所知的案例,其中Kotlin已经大规模应用到Android开发前线中了。
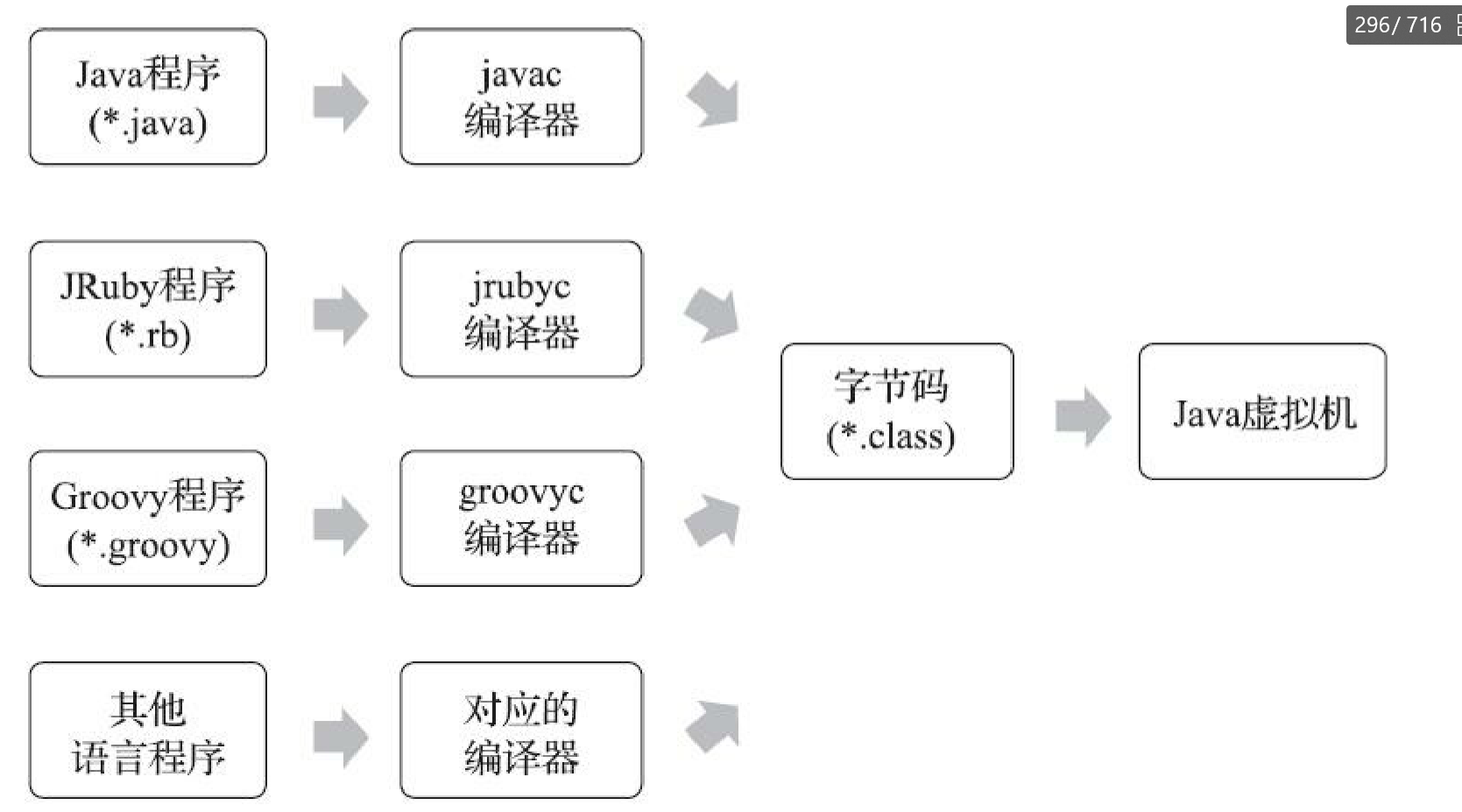
类文件结构
class文件就是一大堆二进制数字,由于只能包含二进制数字,所以class文件结构的格式都是死的,哪里应该出现什么这些都有着严格的定义。
Java虚拟机要保证向下兼容,所以Class文件结构相当稳定,除了拓展功能时有可能新增一些内容(其实也没几次)之外,所有的结构都还是Java语言设计之初所定义的结构。
这里所说的class文件并不单单指磁盘中存储的
.class文件,Java虚拟机可以从任意位置加载这些字节码,可以从网络,可以从内存中动态生成等等。所以class文件可以看作任何符合Java虚拟机规范的字节码文件的任何形式,由于我们目前只讨论文件形式的字节码,所以就简称为class文件。
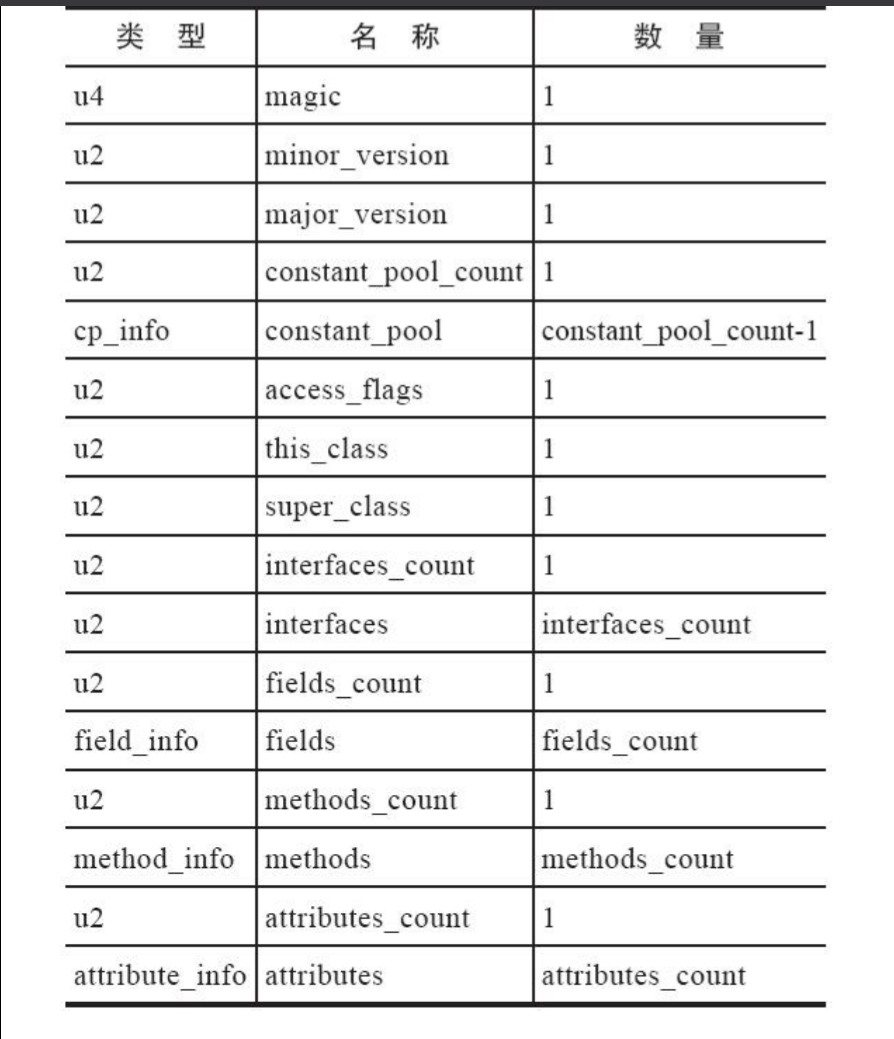
Class文件中只有两种数据结构,只有两种数据结构。
第一种就是无符号数,第二种就是表。
无符号数代表的就是一串固定位数的二进制数,u1,u2,u4,u8分别代表1字节,2字节,4字节和8字节的无符号数。
而表则是一个复杂的嵌套数据结构,其中可能包含其他表和无符号数。一般class文件中定义的表名都已_info结尾,为了清晰的和无符号数做区分。
你发现Class文件中只有无符号数和表两种结构,而表中也可以包含这两种数据结构,那么class文件也就可以看成是一个表了。
如下是一个class文件的组成
可以发现一个行为,当遇到无法确定有多大的数据的时候,比如fields,一个类中的字段列表,因为这是无法预定的,主要看程序员编写了多少,所以描述这种数据都要跟一个形如fields_count的数据来说明有多少个。
魔数
魔数不是class文件才有的,很多文件都使用魔数来检测文件格式,比如GIF,JPEG等。我们知道,扩展名是很容易被用户修改的,而未经系统学习的用户却很难直接与字节码打交道。所以Java虚拟机并不认为一个文件只要扩展名是.class那么它就是一个文件了,还要检测魔数。
魔数是class文件中最先出现的数字,占用4个字节。
一个16进制数能表示16种状态,也就是能表示\(2^4\)种状态,也就是说能代表4位二进制数,而一个字节有8位二进制数,这样,两个16进制数代表一个字节。4个字节就是8位16进制数。
我们打开一个class文件,就会看到这个魔数——0xCAFEBABE,所以程序员才是最浪漫的。
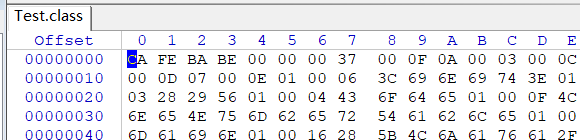
Java虚拟机规定,class文件必须以魔数开头才会被虚拟机加载。
版本号
接下来两个2字节的数据就是minor_version和major_version,分别是次版本号和主版本号。
Java虚拟机规范中规定不允许加载版本号比当前版本高的class文件。
次版本号自Java1.2之后就没被使用,直到12的时候才再次启用,作为一些实验性功能的开启开关。
常量池
常量池中存储的大部分就是字面量,大概包含如下一些内容。

注意它和虚拟机里的运行时常量池可不一样,它是class文件中的静态常量池。虚拟机会把这些东西加载到运行时常量池中。
从版本号之后紧挨着的就是常量池信息,因为常量池有中的数据量在每个class文件中不一致,所以需要提供一个u2类型的数据来定义常量池中有多少个常量。
编译一个简单的类,并通过字节码分析工具打开它,这里用的WinHex。
package io.lilpig.clazz;
public class TestClass {
private int m;
public int inc() {
return m + 1;
}
}
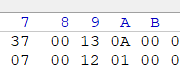
这里的0013转换成十进制就是19,但它代表常量池中有\(19-1=18\)个数据。
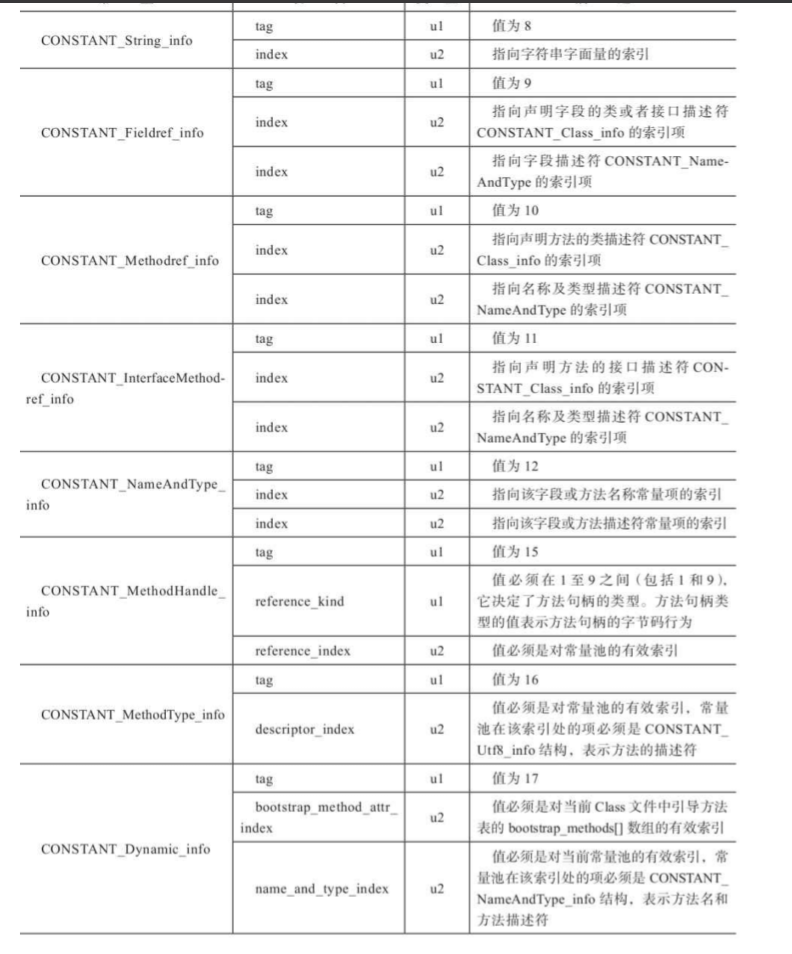
之后就是常量池中的具体数据了,常量池中的每个数据都是一个表,这个表中包含两个数据,这些表的第一个数据都是一个u1类型的tag标识常量具体的类型。
如下是常量池中可以存在的的数据类型和tag的对应
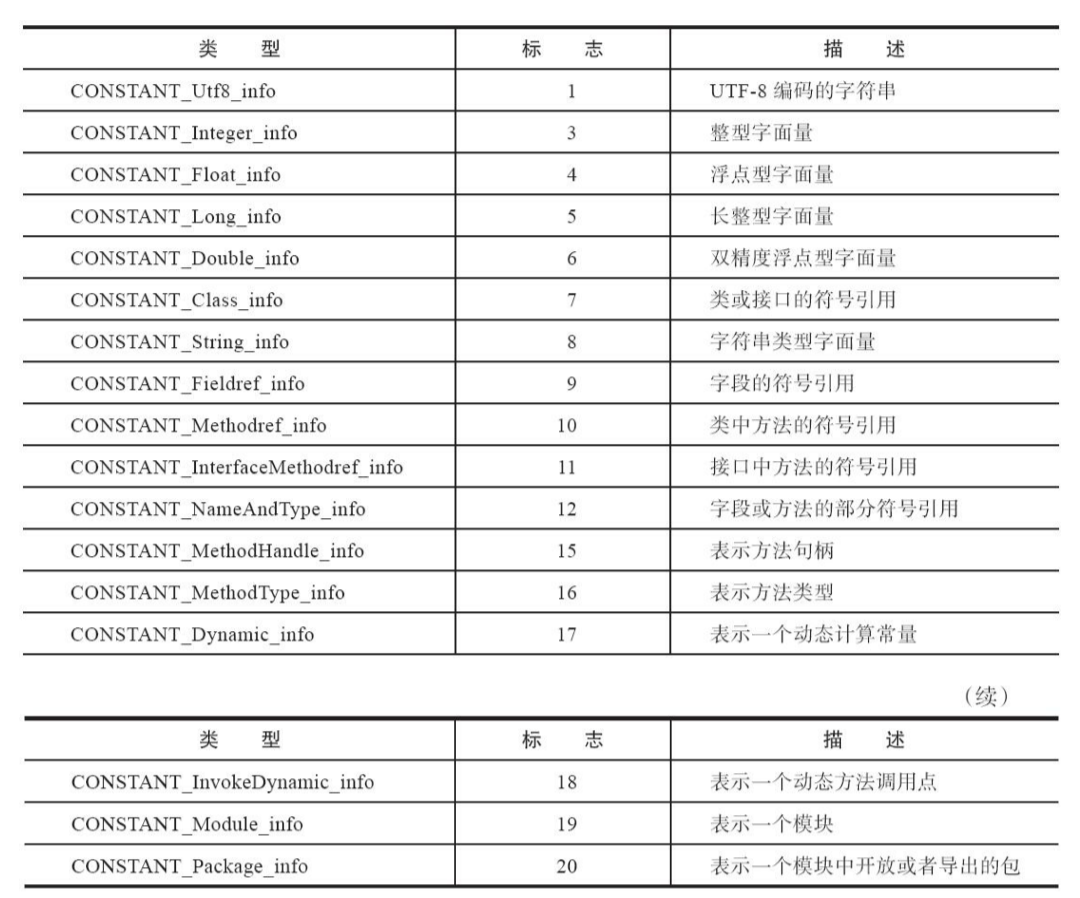
这些数据类型以表的形式存在,并且除了都有一个tag之外,其内部结构完全不同。
看常量池中第一个常量
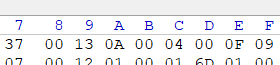
它的tag是0A,转换成十进制就是10,是CONSTANT_Methodref_info类型的常量。这个类型的常量类型的结构如下

一个u1类型的所有常量都有的tag,一个指向方法所在的类的u2类型的描述符,存储指向CONSTANT_Class_info类型的一个索引。另一个是同样类型的指向方法描述符的CONSTANT_NameAndType_info的索引项。这两个u2类型的数据分别是0x0004和0x000F,也就是指向了常量池中第4个常量和第15个常量。
我们通过使用javap -v 字节码文件来阅读我们的class文件的话,会发现我们的理论完全正确。
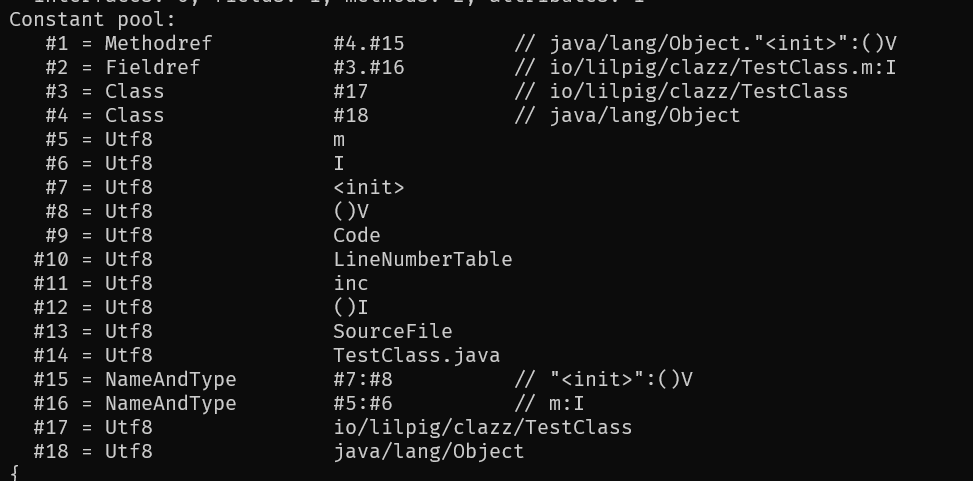
之后我们都会在javap中看,不再阅读字节码了。
我们发现第四个常量是一个CONSTANT_Class_info类型的常量(javap中写成了Class),这个类型的常量的结构如下

首先还是u1类型的tag,其次是一个u2类型的name_index,它存储了指向CONSTANT_Utf8_info的常量用于描述具体的类名。这也是把文字常量提取出来方便在以后的位置直接通过引用使用的思想,压缩了class类型的空间,并且更灵活。
而CONSTANT_Utf8_info的常量结构如下

除了tag之外,还有一个u2类型的length,代表该常量的长度。所以也可以初步断定java的类名就算没有明确限制,实际上也不能超过这个长度限制。然后就是连续length个u1类型用来表示这个字符。也就是说,class文件限制了Java的方法名,类名的定义不能超过65535个字节,即u2能表示的最大数个字节。
对于其它类型的常量,不做分析了,太枯燥太无聊。
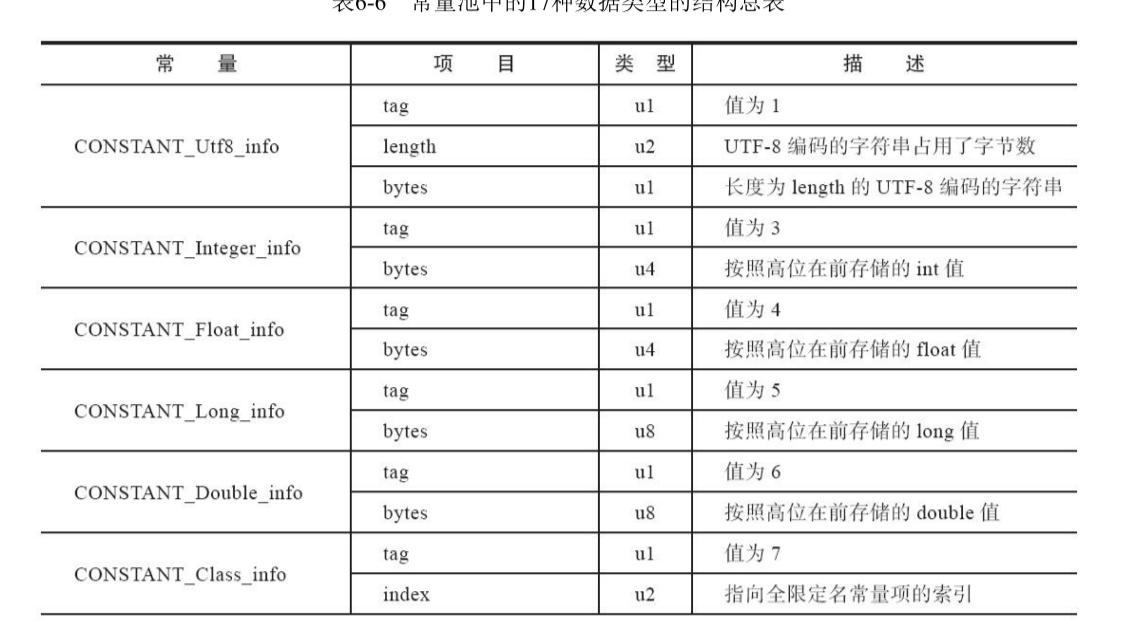
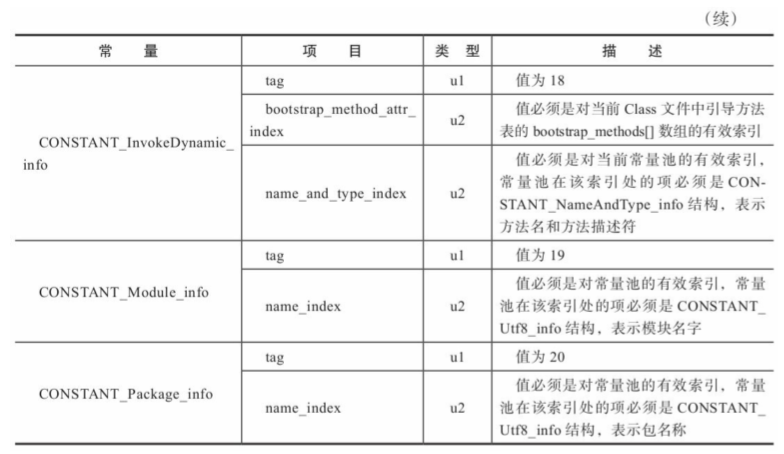
下面给出class常量池中的各种数据类型的结构表
访问标志
在常量池之后就是该类的访问标志。
一个类的标识符可以有public、abstract、enum等等......访问标志就用来指定这些。
访问标志是一个u2类型的数据。
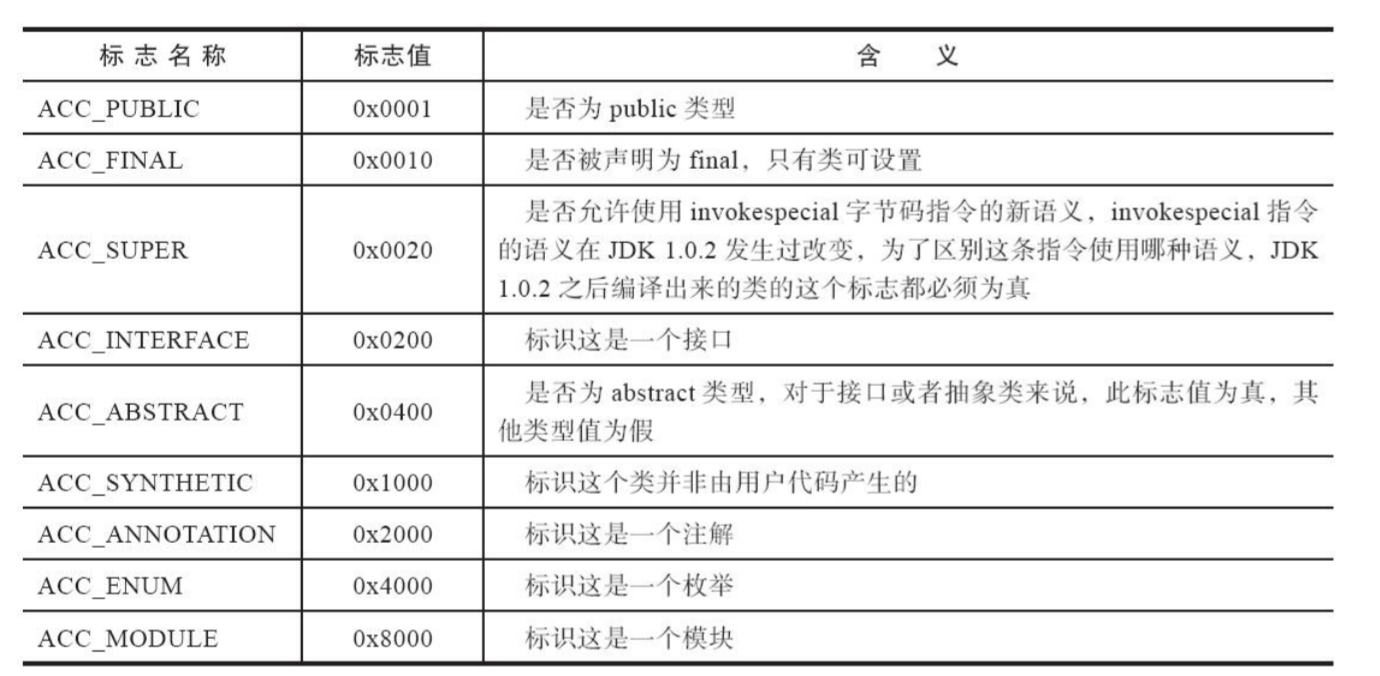
相当于提供16个二进制位,每个位代表一个开关。1为被该标识符标注,0为没被该标识符标注。当前只定义了其中的9个标志位。没有使用到的标志位要求一律为0。
类索引、父类索引与接口索引集合
访问标志之后就是类索引,父类索引和接口索引集合。
类索引和父类索引都是u2类型的数据,它们指向常量池中的一个CONSTANT_Class_info的一个索引。
而接口索引集合不一样,因为Java允许实现多个接口,所以不能用一个u2类型来表示。采用了和之前差不多的,一个u2的标志位(interfaces_count),表示有多少个接口,然后是连续interfaces_count个u2类型的指向常量池中CONSTANT_Class_info类型的数据。
字段表集合
再往下来是字段表,字段表描述了类中声明的变量,“字段”包括静态变量和实例变量。
一个字段表的结构如下
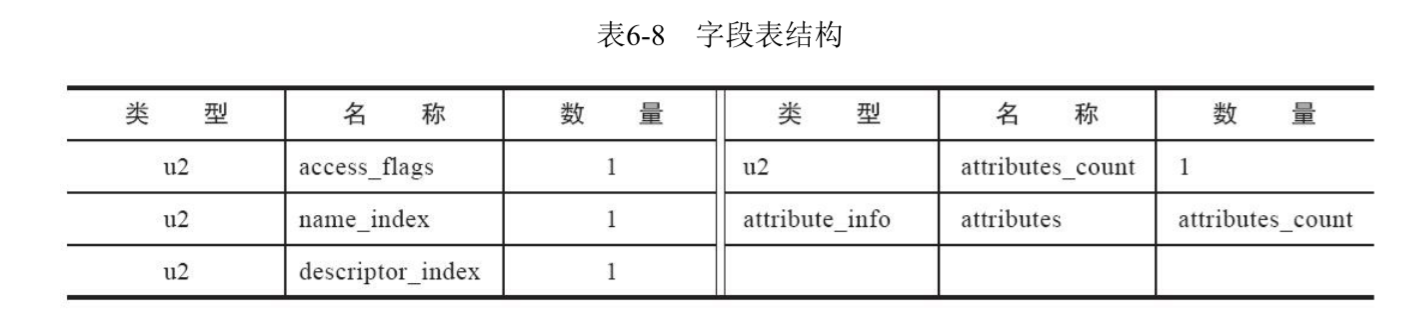
access_flags是一个字段的访问标识符,和类的访问标识符有所区别,因为字段上能用的修饰符和类上的不一样。但是原理是一样的,不介绍了,只将访问字段的表放在下面
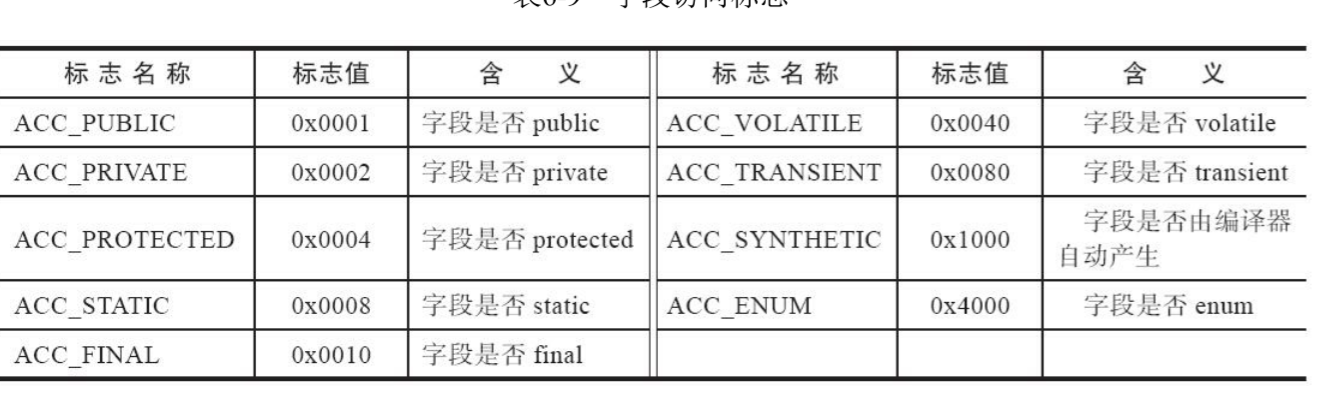
接下来name_index指向字段的简单名称,descriptor_index指向字段的描述符。
简单名称就是单纯的变量名,不包含包名和类名。而descriptor_index有点复杂,它是被定义在虚拟机层面的一个类型描述符,它主要被用来描述方法签名。
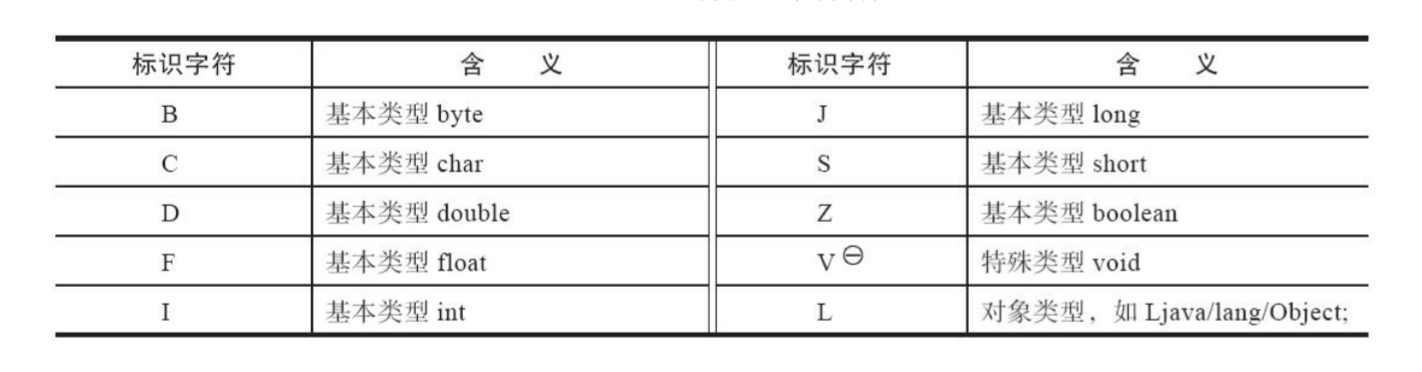
数组类型使用一个前置的[来表示
如果一个方法的签名是void inc(),在Java虚拟机中就会这样表示()V,代表没有参数,返回void。如果签名是java.lang.String toString(),则会被表示成()Ljava.lang.String,int indexOf(char[] source,int sourceOffset, int sourceCount, char[] target, int targetOffset, int targetCount, int fromIndex)则会被表示成([CII[CIII)I
对于上面的代码,只有一个int类型的变量m。我们不看字节码了,就在常量池中找找有没有对应的索引吧。

attributes相关的两个数据,应该是用来记录常量值的。
父类的字段不会出现在子类中。
方法表集合
方法表存储类中的方法。
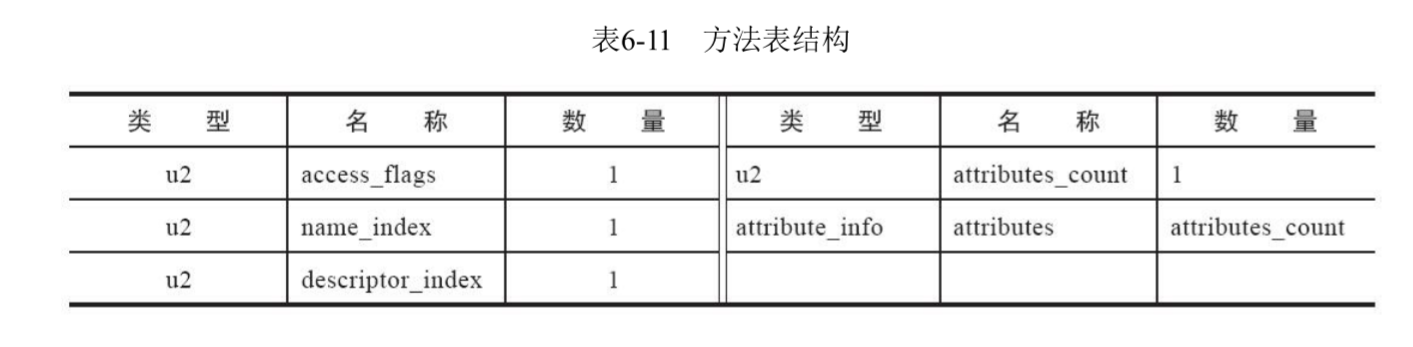
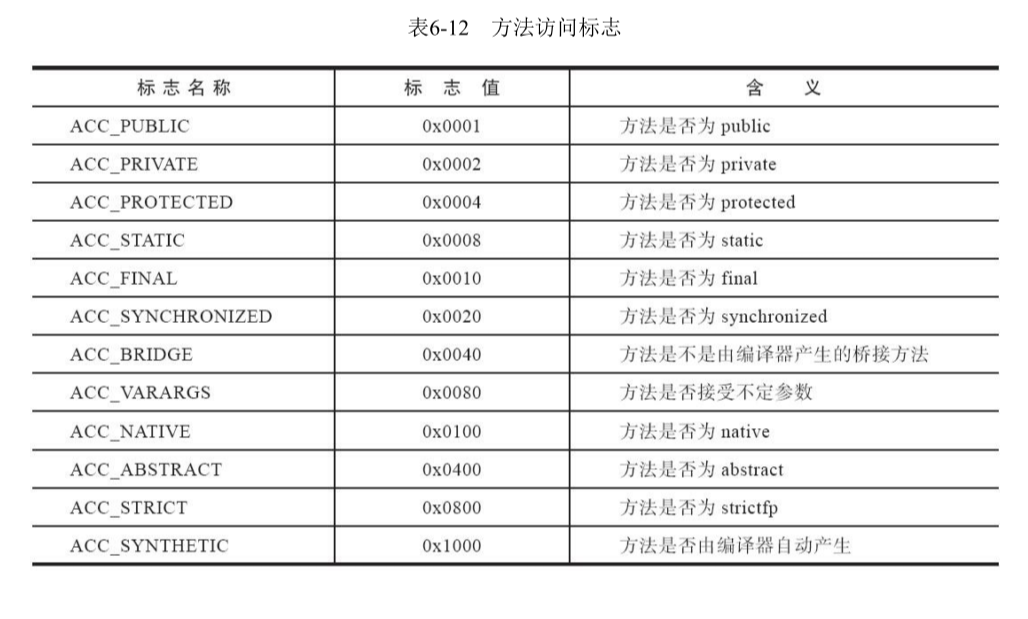
方法中的代码存在哪了?Java编译器会把所有的代码的字节码描述放到方法表集合中一个名字为Code的属性里面,然后attribute相关的属性会做相关的描述,找到方法的字节码表示。
父类的方法,子类没有重写的,不会出现在该类的方法表中。
Java层面中,方法的特征签名不包括返回值,所以返回值不同不能构成重载,但字节码层面的方法特征签名包括返回值,所以只有返回值不同的两个方法是完全能存在于class文件中的。
属性表集合
attribute_info类型的数据之前出现了很多次,但一直模棱两可,因为在字段和属性中它的定义不一样,所以我们放到最后说。
属性表集合不要求各个属性的顺序必须像class文件中其它部分一样严格,只是别有同名属性即可。
可以有如下类型的属性表
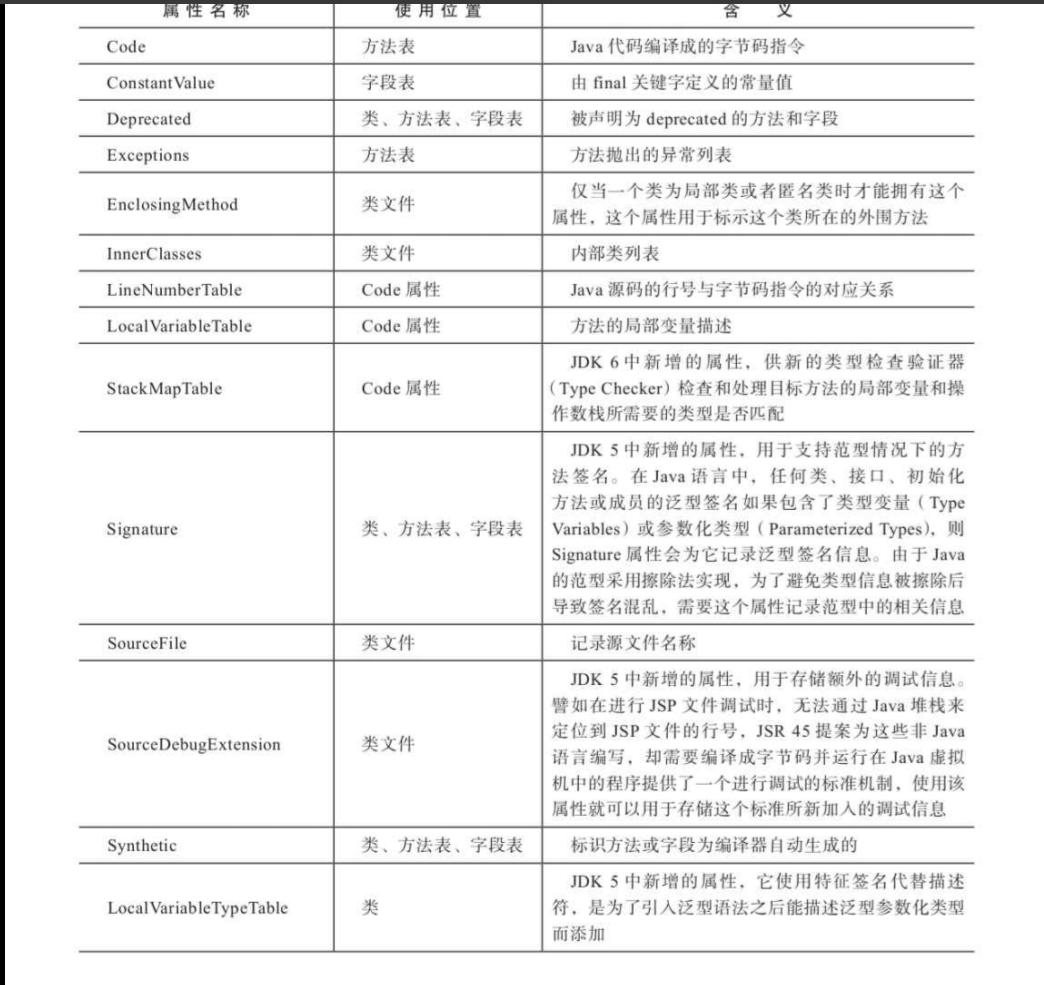
一个符合规则的基本的属性表应符合如下规则,而不同类型的属性表又有各自不同的实现。

一个u2类型指向常量池中的一个CONSTANT_Utf8_info用来表示属性的名字,一个u4类型的attribute_length字段表示这个属性的长度,而下面的attribute_length个u1则代表指定字节的实际属性数据。
Code属性
Code属性表保存了代码中的方法。它的结构如下。
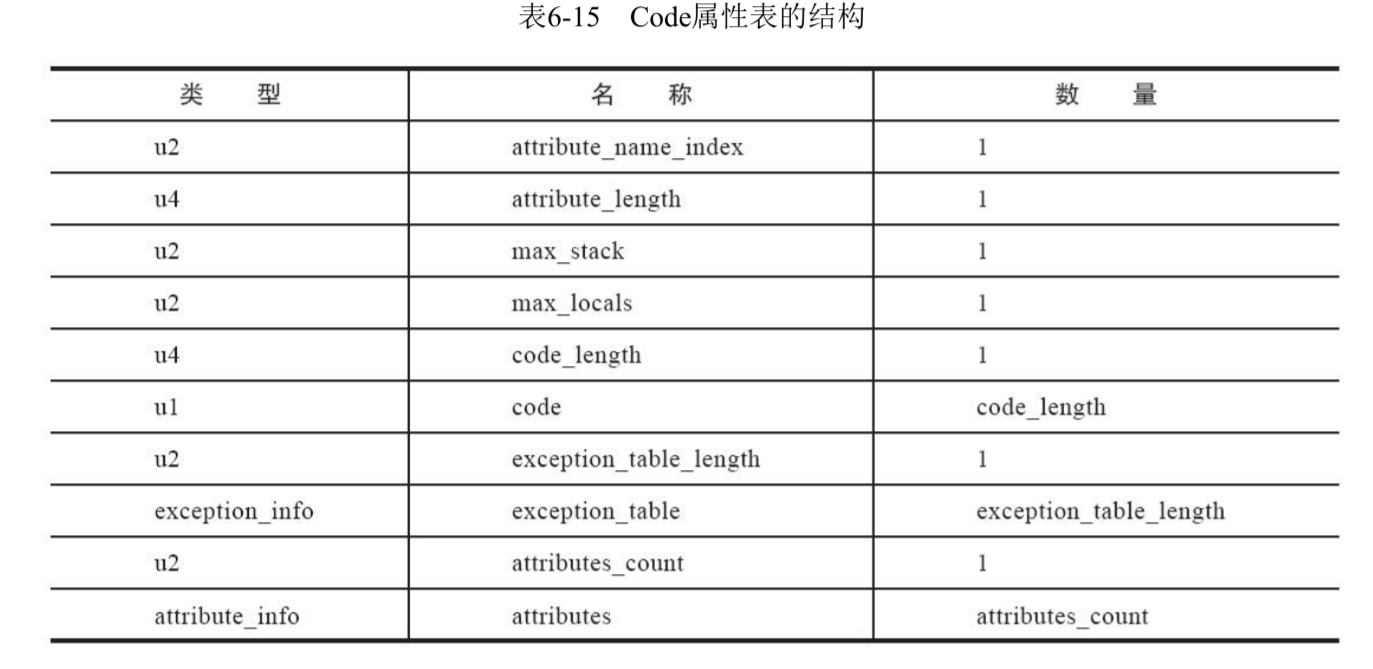
attribute_name_index固定指向常量池中值为Code的Utf8常量。attribute_length指定了该属性的长度。这是基本的属性描述信息。它们占用了6字节。
剩下的就是Code属性表特有的信息了,max_stack代表操作数栈深度的最大值,在方法执行的任何时刻,操作数栈都不会超过这个深度。max_locals代表方法中的局部变量所需要的存储空间,单位为变量槽,之前的文章介绍过。
Java虚拟机会为每个32位的局部变量分配一个槽,64位的分配两个,还会为this分配额外的一个。方法中所有的局部变量,包括try-catch块中的,都会被分配到一个槽上。但是这不代表有一个变量就分配一个槽,槽在一些情况下可以重用。
public void a(int b){
if(b<10){
int c = 10;
}
int d = 20;
}
显然,这个方法只需要三个槽就能够容纳所有局部变量,而不是四个,首先需要一个来存储this,然后是b,然后if语句中需要一个来存储c,但是当执行到d的定义时,if语句中的变量c永远都无法获取到了,所以d可以重用这个槽。编译器会完成这个过程,并分配对应数量的槽。
当我们这样写代码时,显然要分配四槽,this,bcd各一个。
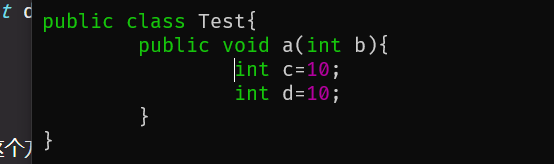
利用javap查看一下,注意locals字段
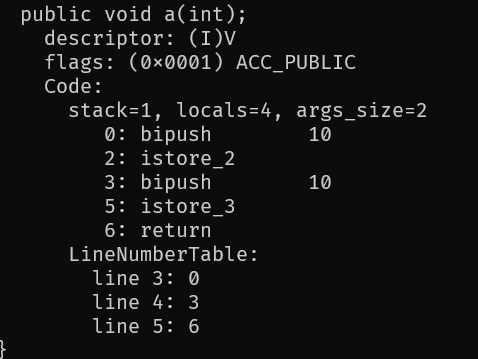
然后我们再修改代码
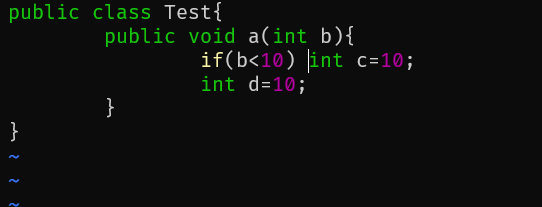
再次编译,javap查看,这次只用了三个槽
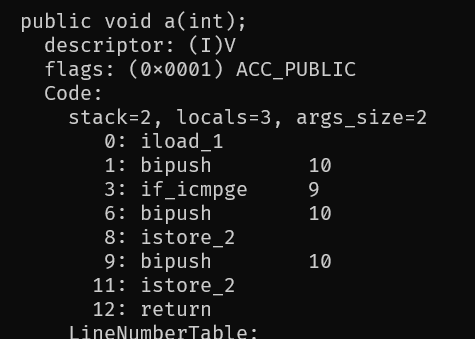
注意locals并不是槽的个数,只是需要使用几个变量,而槽的个数可以在输出的LocalVariableTable信息中查看,但不知道为啥我的javap中没有。
那为啥上面javap输出时的args_size是2呢,明明只用了一个参数,其实另一个参数是用于this的传递。这样我们才能在方法中访问到this。
code_length和code组合存储实际的字节码指令。
code_length虽然是u4类型,但是方法表中明确规定的是不允许方法编译后超过65535条字节码,所以说Java中一个方法的长度是有限制的。
剩下的不想记了,感觉很枯燥,记住也没太大帮助,就看看得了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号