Servlet笔记
先导
实现Servlet
创建一个Servlet需要实现Servlet接口,里面有五个抽象方法。其中有一些看起来像是生命周期方法。
import javax.servlet.*;
import java.io.IOException;
import java.io.PrintWriter;
public class MyFirstServlet implements Servlet {
@Override
public void init(ServletConfig servletConfig) throws ServletException {
System.out.println("init...");
}
@Override
public ServletConfig getServletConfig() {
System.out.println("getServletConfig...");
return null;
}
@Override
public void service(ServletRequest servletRequest, ServletResponse servletResponse) throws ServletException, IOException {
System.out.println("service...");
}
@Override
public String getServletInfo() {
System.out.println("getServletInfo...");
return null;
}
@Override
public void destroy() {
System.out.println("destroy...");
}
}
在每个方法中都打印一些消息,看看它们何时被调用。
运行,控制台并没有任何消息,访问这个servlet,控制台输出如下消息
init...
service...
所以,当servlet被访问时会调用init和service
再次访问这个servlet,控制台输出如下消息
service...
所以,init只会在第一次访问时被调用一次而service每次访问都会被调用
这里面的三个生命周期方法的官方定义如下:
- init:由Servlet容器(tomcat)调用,代表Servlet将开始服务。
- service:由Servlet容器调用,用来响应请求
- destroy:由Servlet容器调用,代表Servlet将停止服务
看起来,我们如果要编写应用,只需要关注service方法即可,其它的我们并不关心,因为我们关心的始终只是响应用户的请求。
GenericServlet
GenericServlet可以让我们的目光聚焦在service方法上,它为其它的方法提供了默认实现,并将service设置为抽象方法,我们只需要实现service即可。
public class MySecondServlet extends GenericServlet {
@Override
public void service(ServletRequest servletRequest, ServletResponse servletResponse) throws ServletException, IOException {
System.out.println("SecondServlet Service...");
}
}
清晰了许多
GenericServlet代码
我们先暂时只关注其中的生命周期方法的默认实现,对于init,它是这样实现的
// 实现Servlet中的接口方法
public void init(ServletConfig config) throws ServletException {
this.config = config;
// 调用自定义的重载方法
this.init();
}
// 自定义的重载init方法
public void init() throws ServletException {
}
对于init,它将config设成了一个属性并且调用了重载的init方法,这个方法没有参数,并且也不是抽象的,默认情况下,它什么都不做。
也就是说,GenericServlet给我们实现了一个默认的init并且如果你想在你的Servlet初始化时做一些工作,你也可以选择重写它,是否重写在你自己,需要即拿。
而对于destroy它则是什么都没做
public void destroy() { }
HttpServlet
嘶。。GenericServlet貌似挺好了,但是我们做后端处理的都是浏览器发出的请求,也就是基于HTTP协议的请求。GenericServlet中并没有和HTTP相关的东西,任何请求它都照单全收。想想,这样写后端接口很难受啊,因为HTTP协议有自己的一套规范,它有一系列请求方法(GET,POST,HEAD...),URL参数,Header,请求体等。如果这些都让我们自己处理,处理好了也没力气写业务代码了。
HttpServlet解决了此问题,让我们把目光再次聚焦在HTTP请求和响应身上。
public class MyThirdServlet extends HttpServlet {
}
???我们啥都没写都不爆红,HttpServlet并没有任何抽象方法。
运行之,访问之...

有了默认的返回页面,是一个405页面。
HttpServlet代码

它继承自GenericServlet,我们去看看它的生命周期方法里都干了啥。
首先在service中,先对req和res进行了强转,转换成了HttpServletRequest和HttpServletResponse,能强转证明它们本来就是这两个对象,只是类型退化了,难道说Tomcat本来在遇到HTTP请求的时候构建的就是HttpServletRequest和HttpServletResponse?
service
public void service(ServletRequest req, ServletResponse res) throws ServletException, IOException {
HttpServletRequest request;
HttpServletResponse response;
try {
request = (HttpServletRequest)req;
response = (HttpServletResponse)res;
} catch (ClassCastException var6) {
throw new ServletException(lStrings.getString("http.non_http"));
}
this.service(request, response);
}
然后,它调用了this.service(request,response),也就是重载的另一个Service
这代码不算短,慢慢看
protected void service(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 获取请求的方法,GET、POST还是什么
String method = req.getMethod();
long lastModified;
// 如果是GET方法
if (method.equals("GET")) {
// 获取上次修改该地址的时间
lastModified = this.getLastModified(req);
// 如果没这东西
if (lastModified == -1L) {
// 正常调用doGet响应,一会再说doGet
this.doGet(req, resp);
} else {
// 这里尝试获取客户端的If-Modified-Since
long ifModifiedSince;
try {
ifModifiedSince = req.getDateHeader("If-Modified-Since");
} catch (IllegalArgumentException var9) {
ifModifiedSince = -1L;
}
// 如果 页面过旧
if (ifModifiedSince < lastModified / 1000L * 1000L) {
// 重新设置LastModified
this.maybeSetLastModified(resp, lastModified);
// 正常调用doGet响应
this.doGet(req, resp);
} else {
// 否则,客户端缓存中的数据还有用,直接返回304通知客户端使用缓存即可
resp.setStatus(304);
}
}
} else if (method.equals("HEAD")) {
lastModified = this.getLastModified(req);
this.maybeSetLastModified(resp, lastModified);
this.doHead(req, resp);
} else if (method.equals("POST")) {
this.doPost(req, resp);
} else if (method.equals("PUT")) {
this.doPut(req, resp);
} else if (method.equals("DELETE")) {
this.doDelete(req, resp);
} else if (method.equals("OPTIONS")) {
this.doOptions(req, resp);
} else if (method.equals("TRACE")) {
this.doTrace(req, resp);
} else {
// 方法不支持
String errMsg = lStrings.getString("http.method_not_implemented");
Object[] errArgs = new Object[]{method};
errMsg = MessageFormat.format(errMsg, errArgs);
resp.sendError(501, errMsg);
}
}
其实就是为每个Http方法定义了一个单独的回调函数,doXXX。然后做一些预处理并调用。
然后这些doXXX的默认实现基本都是直接向客户端返回一个方法不支持的消息

就是我们刚刚访问页面时看到的那个了。
所以如果想继承HttpService进行开发,很简单,只需要自己实现对应的doXXX然后进行相应的处理就好了。
init和destroy
HttpServlet并没有实现这两个方法,也就是说,你可以实现也可以不实现,需要就实现,不需要就会调用到GenericServlet中的默认实现
向前端返回一句话
怎么也得给前端返回点啥啊,我们先小试一下,随便调调里面的函数。
先实现个doGet
public class MyThirdServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
}
}
然后看看API里对HttpServletRequest中方法的解释,找到一个getParamter方法

就是说获取一个请求参数,对于HttpServlet来说就是URL中的请求参数,如果不存在则为null
String name = req.getParameter("name");
if (name!=null) {
// 返回欢迎信息
}
我们看看如何返回欢迎信息
在HttpServletResponse的API中找到这么一个方法

可以看出是获取一个PrintWritter对象向客户端打印一些字符,并且这些字符通过一个getCharacterEncoding方法编码,默认是ISO-8859-1所以可能产生编码问题,我们先用英文来规避这些问题。
public class MyThirdServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
String name = req.getParameter("name");
PrintWriter writer = resp.getWriter();
if (name!=null) {
writer.write("Hello, " + name);
} else {
writer.write("Hello, anonymous");
}
}
}
这里就是如果客户端参数中有name,那么就返回Hello,和他的名字进行问好,如果没有,那么就返回Hello, anonymous。
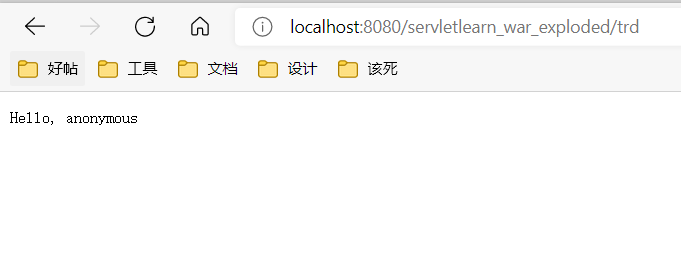
运行之,访问之。
当我们不带参数的时候,结果是
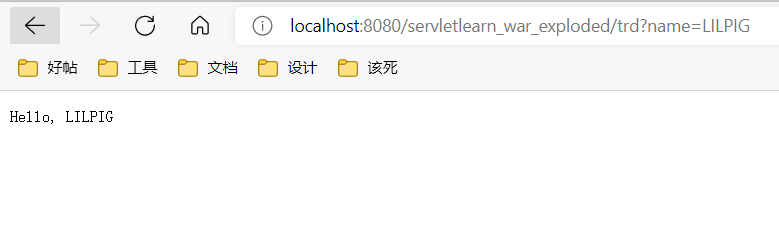
当我们带参数的时候,结果是
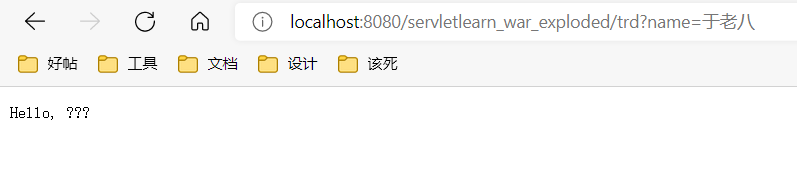
如果传递中文,那么根据默认编码ISO-8859-1,那么肯定得到的是一系列问号。
对于编码问题,推荐一本书:深入分析JavaWeb技术内幕
web.xml
url-pattern
web.xml中可以定义servlet,在前导中的那篇文章里有介绍。
url-pattern中的格式有四种
| 名称 | 模式 | 功能 |
|---|---|---|
| 精确匹配 | /具体名称 | url路径完全匹配时触发Servlet |
| 前缀匹配 | /路径/* | 匹配路径下的所有请求,包含服务器资源 |
| 后缀匹配 | /*.后缀 | 指定后缀结尾的触发Servlet |
| 默认匹配 | / | 匹配所有请求,包含服务器资源,不包含jsp |
它们之间的顺序关系如下
- 精确查找仅当url后面的内容和指定的完全匹配,不多不少时才作用,它的优先级最高
- 如果没找到,那么就去前缀匹配,一系列前缀匹配中,层级越深的优先级越高,如当访问
/zzz/bbb/ccc时/zzz/bbb/*会比/zzz/*要高 - 如果没找到合适的前缀匹配,那么就看看路径中是否有后缀,也就是最后一个
.后面的东西,如果有,这个servlet就作用 - 都无果,使用默认Servlet
注意,这些模式不能混合使用,如你不能这样配置/abc/*.ext。
load-on-startup
之前说了init在servlet第一次被调用时被调用。
这是没有指定load-on-startup或指定为负数时的缺省行为。
如果指定了load-on-startup,并设置为一个非负整数,那么它就会在容器启动时就被加载,init也随之被调用,优先级就是越小的越先被加载。
这样设置,这个Servlet会在容器启动时就被初始化,并且设置为0就是第一个初始化。
<servlet>
<servlet-name>MyFourthServlet</servlet-name>
<servlet-class>io.lilpig.servletlearn.MyFourthServlet</servlet-class>
<load-on-startup>0</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>MyFourthServlet</servlet-name>
<url-pattern>/fourth</url-pattern>
</servlet-mapping>
注解配置Servlet
这年头谁还用XML啊。。。。。。
Servlet3.0之后可以使用注解配置Servlet
使用@WebServlet注解来声明一个Servlet
@WebServlet("/fifth")
public class MyFifthServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
PrintWriter writer = resp.getWriter();
writer.write("<h1>HELLO</h1>");
}
}
常用到的属性就是value、urlPattern和loadOnStartUp,分别和XML中的一样,value和urlPattern的作用一致,它们是字符串数组,上面的写法就是一个精确匹配的简写(使用value)。
因为使用注解可以一次性绑定多个路径
@WebServlet(urlPattern = {"/a","/b"})
所以Servlet的名字就显得不那么重要了,当然也可以通过name属性设置名字。
@WebServlet注解可以和XML共同作用于同一个Servlet
404
如果容器没有扫描你使用注解编写的Servlet,你应该会得到一个404。
去看看web.xml中的这个属性
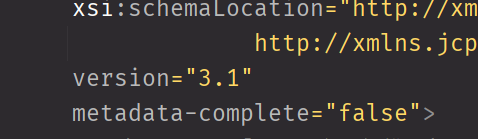
就是这个metadata-complete是否被设置成了true, 这个属性代表是不是完整的配置信息都在XML文件中,如果是true,容器不会去扫描使用注解声明的Servlet。
获取请求参数
GET
前端页面
<form action="/servletlearn_war_exploded/register" method="get">
<h1>注册</h1>
<input type="text" name="username" placeholder="用户名"/>
<br/>
<input type="password" name="password" placeholder="密码"/>
<button type="submit">注册</button>
</form>
后端Servlet
@WebServlet("/register")
public class RegisterServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
System.out.println("账号:"+req.getParameter("username")+
",密码:"+req.getParameter("password"));
}
}
这没啥好说的,挺简单的。
需要注意的是编码问题,如果你在Tomcat8以下的版本输入中文会出现编码问题,那你就需要统一客户端和服务器端的编码了。客户端的URL中使用utf-8编码(以后会详细介绍),而服务器端默认是ISO-8859-1,你也需要使用utf-8解码。
new String(name.getBytes("ISO8859-1"), "UTF-8");
POST
修改前端的method为post
后端:
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
System.out.println("账号:"+req.getParameter("username")+
",密码:"+req.getParameter("password"));
}
英文没问题,中文会出现乱码。

这里只需要在获取参数之前调用req.setCharacterEncoding,让它和客户端编码一致即可。
那么为啥之前我们GET出问题的时候不使用这个方法去设置呢?而是自己转换?
看下API中对这个方法的解释

这个只是重设请求体中使用的字符编码名称,post的参数在请求体中,而get的参数在url中。
设置完之后,成功解码

发送响应
注册成功后我们应该给前端返回一个内容
PrintWriter writer = resp.getWriter();
writer.println("注册成功");
这是前面都有过的内容。
访问之,乱码了
这也是因为我们服务器端默认是ISO8859-1的编码格式,客户端并不知道,它们按自己的方式解析。
想让它们知道,需要设置
resp.setCharacterEncoding("UTF-8");
resp.setHeader("Content-type","text/html;charset=utf-8");
这两行代码,第一行,是重设响应体中的字符编码,同样它也必须在getWriter之前调用。第二行是告诉浏览器,我响应的内容使用utf-8编码,请你使用utf-8解码。
简单办法
resp.setContentType("text/html;charset=utf-8");
请求转发
现在我们有这样的代码:
@WebServlet("/showall")
public class ShowAllAdmin extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 设置字符集
req.setCharacterEncoding("UTF-8");
resp.setContentType("text/html;charset=utf-8");
// 调用service层业务逻辑
List<Admin> admins = service.getAll();
// 返回数据
PrintWriter writer = resp.getWriter();
writer.println("<html>");
writer.println("<head>");
writer.println("<meta charset='utf-8'/>");
writer.println("</head>");
writer.println("<body>");
writer.println("<h1>用户列表</h1>");
writer.println("<ul>");
for (Admin admin : admins) {
writer.println("<li>");
writer.println(admin.getUsername()+", "+admin.getAddress()+", "+admin.getPhone());
writer.println("</li>");
}
writer.println("</ul>");
writer.println("</body>");
writer.println("</html>");
}
}
它的问题就是,Servlet又参与了业务逻辑的调用,又参与了显示给前端的工作。这两个功能应该分开,由两个Servlet来做。一个专门处理业务逻辑,一个专门显示,这样他们就解耦了。
// 处理业务逻辑的Servlet
@WebServlet("/showall")
public class ShowAllAdminController extends HttpServlet {
private AdminService service = new AdminServiceImpl();
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
req.setCharacterEncoding("UTF-8");
List<Admin> admins = service.getAll();
}
}
// 给前端返回数据的Servlet
@WebServlet("/showallview")
public class ShowAllAdminView extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
resp.setContentType("text/html;charset=utf-8");
PrintWriter writer = resp.getWriter();
writer.println("<html>");
writer.println("<head>");
writer.println("<meta charset='utf-8'/>");
writer.println("</head>");
writer.println("<body>");
writer.println("<h1>用户列表</h1>");
writer.println("<ul>");
for (Admin admin : admins) {
writer.println("<li>");
writer.println(admin.getUsername()+", "+admin.getAddress()+", "+admin.getPhone());
writer.println("</li>");
}
writer.println("</ul>");
writer.println("</body>");
writer.println("</html>");
}
}
现在有了两个Servlet,还缺一个东西把它们连接起来,让第一个Servlet跳转到第二个Servlet,并且传递用户列表到第二个Servlet中,因为第二个Servlet中的用户列表admins还是不存在的,它在第一个Servlet中。
请求转发就是用来解决上面的问题,一个Servlet做完它该做的部分的工作之后,转发给另一个Servlet,让它继续处理。
使用下面的代码可以进行这个操作,forward方法中的参数是重定向发起方的Servlet中的req和resp,这说明这两个对象应该是在转发链中共享的。
req.getRequestDispatcher("/showallview").forward(req, resp);
那么又回到了第二个问题,如何传递数据。
req中有一个setAttribute方法和getAttribute方法可以在转发链中共享数据。
下面是第一个处理业务逻辑的Servlet代码
req.setCharacterEncoding("UTF-8");
List<Admin> admins = service.getAll();
req.setAttribute("admins",admins);
req.getRequestDispatcher("/showallview").forward(req, resp);
下面是第二个用于显示的Servlet代码
resp.setContentType("text/html;charset=utf-8");
List<Admin> admins = (List<Admin>) req.getAttribute("admins");
PrintWriter writer = resp.getWriter();
writer.println("<html>");
// ...
writer.println("<ul>");
for (Admin admin : admins) {
// ...
}
// ...
注意,请求转发是发生在服务器端的,对于浏览器端,它们并不知道发生了转发,它们认为是一个请求。
请求重定向
重定向是HTTP规范中定义的操作,它的作用大概就是网站从旧地址迁移到了新地址,旧地址不再提供服务了,那么旧地址返回一个状态码告诉新地址需要重定向,并且返回新地址给浏览器,浏览器接收到之后自动向新地址发送请求。
我们也可以使用重定向来完成单纯的页面跳转功能。
使用resp.sendRedirect来向客户端浏览器返回重定向状态码,这个参数就是重定向的地址。注意这个地址需要是基于项目的。因为重定向大多数时候都是项目发生迁移。
@WebServlet("/source")
public class SourceServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
resp.sendRedirect("/servletlearn_war_exploded/target");
}
}
@WebServlet("/target")
public class TargetServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
resp.getWriter().write("Target Servlet!!!!");
}
}
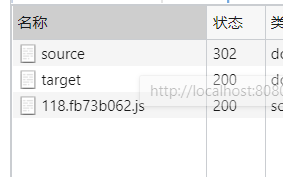
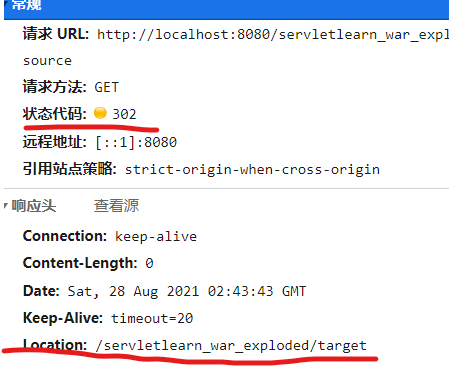
访问一下,可以注意到跳转到TargetServlet并且浏览器的地址栏也发生了变化。这也证明浏览器确实发送了两个请求。
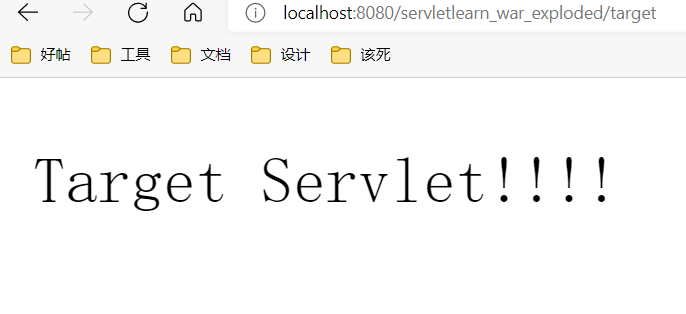
从浏览器的开发者工具中也可以看到,之前的source返回了302状态码(重定向码),并且响应头的Location字段指明了要跳转的地址。
那么重定向能不能像转发一样传递数据呢??
很抱歉不能。。。。
但是可以通过在重定向的url中添加参数,再去目标Servlet中通过req.getParamter获取。
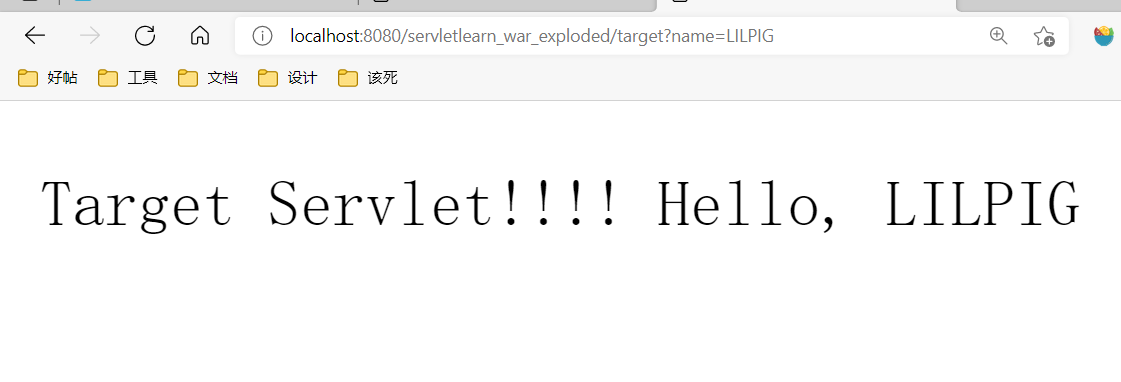
resp.sendRedirect("/servletlearn_war_exploded/target?name=LILPIG");
resp.getWriter().write("Target Servlet!!!! Hello, "+req.getParameter("name"));
这也暗示了你不管传啥参数,必须转成字符串形式,而且受get请求的URL长度限制
简单阐述Servlet生命周期
其实前面也差不多知道了。
一个Servlet经过四个部分
- 实例化
- 初始化
- 服务
- 销毁
实例化就是指Servlet对象被创建出来,你可以理解为构造方法被调用了。这主要看load-on-startup参数,为负数或没设置就是第一次被请求时实例化,否则就是启动时就按顺序被实例化。
实例化后会调用初始化的生命周期方法init,这个方法只会被调用一次。
当Servlet接收到用户请求时,service方法会被调用,就是一次服务。
当容器关闭或重新部署时,destroy方法会被调用,也就是销毁了Servlet。
线程安全
由于Servlet是单例的,但是容器在处理请求时是并发的,所以如果在Servlet中访问公共资源就会出问题。请不要在Servlet中使用公共变量,其实一般情况下也不会去用。
除非在一个就算错了也不要紧的条件下,比如记录一个API提供服务的次数,并且你不依赖这个次数做任何服务器端的压力分析操作,只是给用户看一下,那么就算错了一点也没关系,因为用户对这个数据也不是特别关心。
Cookie
Cookie是服务器端设置给客户端的一些数据,客户端接收到这些数据后,会在以后的请求中携带这些数据,从而在无状态的多次HTTP请求中保存状态。
创建Cookie
一个Cookie项目用Cookie对象表示,包含一个键值对。可以使用setMaxAge方法以秒为单位设置Cookie的过期时间,当这个时间为负数时,就是浏览器会话关闭后Cookie失效。setPath可以指定Cookie有效的路径,指定后,在这个路径下的所有请求浏览器都将携带返回的Cookie。
@WebServlet("/setcookie")
public class SetCookieServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
Cookie cookie = new Cookie("username","lilpig");
cookie.setMaxAge(60*60*24);
cookie.setPath("/servletlearn_war_exploded/getcookie");
resp.addCookie(cookie);
}
}
req.getCookies用于返回客户端携带的Cookie数组,如果没有Cookie则数组为null。
@WebServlet("/getcookie")
public class GetCookieServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
Cookie[] cookies = req.getCookies();
if (cookies != null) {
for (Cookie cookie : cookies){
System.out.println(cookie.getName()+" : "+cookie.getValue());
}
}
}
}
覆盖Cookie
当新返回的Cookie的路径和名字和旧的Cookie相同时,新的Cookie会覆盖旧Cookie,这个覆盖包括值,存活时间等。
编码问题
Cookie的键只能是ASCII字符集中的字符,值有没有要求不清楚,这个好像是依赖于浏览器的,但是最好,统一规范,在设置Cookie和获取Cookie时都使用统一的URL编码,而且能不传递ASCII字符以外的数据就不要传递。
new Cookie(
URLEncoder.encode("姓名", StandardCharsets.UTF_8),
URLEncoder.encode("于老八",StandardCharsets.UTF_8)
);
System.out.println(
URLDecoder.decode(cookie.getName(), StandardCharsets.UTF_8) +" : "+
URLDecoder.decode(cookie.getValue(), StandardCharsets.UTF_8)
);
Cookie的问题
- 大小受浏览器限制,不能存太大
- 存在客户端,不安全
- 用户可以禁用Cookie
Session
Session解决了Cookie的一部分问题。
一,首先Cookie不能过长,Session技术只利用Cookie传递一个很短的JSESSIONID,然后其他所有的值都通过这一个ID来存取。并且Cookie只能存储字符串,还得进行繁杂的编码解码来保证不出现乱码,而Session可以存储所有类型的数据。
二,Cookie存在客户端,容易被篡改,劫持,不安全。Session技术则是将所有数据存储在服务器端,只让用户存储一个JSESSIONID,然后用户通过向服务器提交这个ID来让后端确认他的身份,获取他的数据。
首先,通过HttpServletRequest对象获取HttpSession。通过setAttribute来向Session中存值。
@WebServlet("/session")
public class SessionServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
HttpSession session = req.getSession();
session.setAttribute("username","于老八");
}
}
当调用req.getSession()时,如果之前该请求并没有一个与之关联的session,容器会自动创建一个session并且给一个唯一的id(不知道重复了会发生啥),并将这个id通过JSESSIONID字段设置到响应cookie中。
如果调用req.getSession()时,该请求已经关联过一个session了(Cookie中有JSESSIONID字段),那么就返回这个关联的session。
req.getSession(boolean create)方法,如果create为true,行为与req.getSession()一致,如果为false的话,那么当该请求是第一次访问时,不会创建一个session。
下面的代码获取与当前请求相关联的Session并且获取其中的username属性,如果没有该属性,getAttribute会返回null。
@WebServlet("/getsessionvalue")
public class GetSessionServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
HttpSession session = req.getSession();
String username = (String) session.getAttribute("username");
System.out.println("username: "+username);
}
}
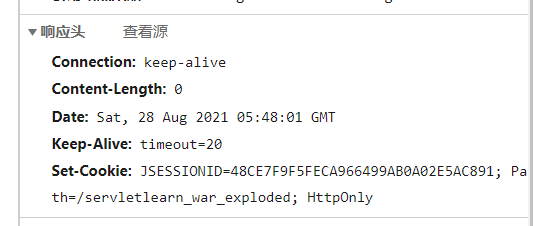
运行,请求/session,可以看到我们的后端通过在Cookie中加入一个JESSIONID来给浏览器返回会话身份标识。并且Path说明了这个标识在整个项目中都可用。
接下来请求/getsessionvalue,可以看到请求头中已经把身份标识给带进Cookie中一并传递给后端了,所以后端再次进行req.getSession时就会获取到已经关联到该请求上的Session。

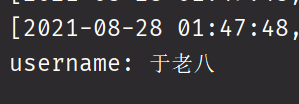
查看控制台,成功获取到数据。
session.removeAttribute可以在当前session作用域中移除一个数据。
@WebServlet("/removesessionvalue")
public class RemoveSessionServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
HttpSession session = req.getSession();
session.removeAttribute("username");
}
}
访问/removesessionvalue,再次访问/getsessionvalue,发现username属性已经没了。
Session失效时间
默认情况下Session是当你关闭了浏览器才失效的。
你可以通过setMaxInactiveInterval给它设置一个失效时间,秒为单位。
HttpSession session = req.getSession();
System.out.println(session.getId());
// 设置失效时间
session.setMaxInactiveInterval(60*60);
session.setAttribute("username","于老八");
这个时间只存在于服务器,和客户端没关系,也就是说客户端的JSESSIONID的这个Cookie的时间并不会修改,关闭浏览器后,用户会丢失这个Session,那么即使服务器端存着这个Session也没用了,因为没法再把这个浏览器和已存在的Session关联起来。
如果指定的时间到了,服务器端的Session过期,客户端的JSESSIONID服务器端无法识别了,因为没有和这个ID绑定的一个SESSION,所以就得重新创建一个Session。
你可以创建两个Servlet然后来回做做实验。
session.invalidate让Session立即失效
HttpSession session = req.getSession();
System.out.println(session.getId());
String username = (String) session.getAttribute("username");
System.out.println("username: "+username);
// 立即失效这个Session
session.invalidate();
有没有办法让Session存在时间长一点呢?不知道有没有官方API,但我个人的猜想就是,你大可以自己将SessionID覆盖到Cookie中并指定一个过期时间,这样SessionID会被缓存到硬盘中。
禁用Cookie?
感觉没啥比用不记了。
Session保存登录信息
当用户登录成功之后,你可以将信息保存到Session中,然后下次用户访问,你就可以直接获取用户的信息。
Admin admin = service.login(username,password);
// 登陆成功
if (admin!=null) {
HttpSession session = req.getSession();
session.setAttribute("admin",admin);
// 跳转到查看用户列表页面
resp.sendRedirect("/servletlearn_war_exploded/showall");
} else {
// 未登录的用户无权限查看用户列表
writer.write("登陆失败,请<a href='/servletlearn_war_exploded/login.html'>重新登录</a>");
}
// showall中的代码
// 获取Session和Admin对象
HttpSession session = req.getSession();
Admin admin = (Admin) session.getAttribute("admin");
// 如果已经登陆成功 做对应的操作
if (admin!=null){
List<Admin> admins = service.getAll();
req.setAttribute("admins",admins);
req.getRequestDispatcher("/showallview").forward(req, resp);
}else{
// 登陆失败,跳转到登录页面
resp.sendRedirect("/servletlearn_war_exploded/login.html");
}
ServletContext
我们之前在Tomcat服务器的配置文件中配置一个站点的时候,使用Context关键字。
Context容器是Tomcat中用于控制Servlet的容器,对应的对象就是ServletContext,那么一个站点自然只有一个Context,也就是说整个项目会共享一个ServletContext对象。
获取ServletContext的办法有三种,第一种就是每个Servlet都会有一个getServletContext方法,如果在Servlet中,直接调用此方法是最方便的。
第二种方法,使用ServletRequest中的getServletContext方法。

第三种办法,使用Session中的getServletContext。

使用ServletContext当然也有那些作用域方法,setAttribute,getAttribute,其中存储的值在整个项目中共享。
Filter
通过之前登录的小案例,我们发现项目中有很多冗余代码,比如在/showall这个Servlet中,我们还要检测用户是否已经登陆过了,如果其他位置也需要检测用户是否登录,那么这个检测,跳转的操作在每个Servlet中都要写一遍。
Filter用来解决这个问题,Filter会先于Servlet被调用,它有权对请求和响应做一些操作,并且,它有权干涉Servlet是否响应。
创建一个Filter要实现Filter接口,下面通过这个检测登录的案例来学习下Filter
@WebFilter(value = "/*")
public class MyFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
// 先把ServletRequest转成HttpServletRequest,响应也是同理
HttpServletRequest req = (HttpServletRequest) servletRequest;
HttpServletResponse res = (HttpServletResponse) servletResponse;
// 获取Session,通过Session获取Admin
HttpSession session = req.getSession();
Admin admin = (Admin) session.getAttribute("admin");
// 如果admin不为空说明已经登陆,那么调用`filterChain.doFilter`继续向下传递请求,这个in什么的咱先不看
if (admin != null || StringUtil.in(req.getServletPath(),"/login.html","/login","/valicode")) {
filterChain.doFilter(servletRequest,servletResponse);
} else {
// 如果为空那么就是没登陆,跳转到登录页面
res.sendRedirect(req.getServletContext().getContextPath()+"/login.html");
}
}
@Override
public void destroy() {}
}
其实还挺简单,只是还有两个疑点,第一,filterChain是啥,doFilter做了啥。第二,那个in是干啥的。
首先,filterChain,如其名,就是过滤器链,一个请求可能有很多与之相应的Filter,它们可以安排顺序,一会会说,当上一个Filter对请求进行一些检测,发现没什么问题之后,调用doFilter,那么下一Filter就会开始工作,然后对请求进行其它的检测,继续重复上面的步骤,让这个请求一直沿着Filter链传递,最后一个Filter的doFilter会将请求发送给实际的接收者,也就是Servlet。它们的request和response是共享的,也就是说如果你对这两个对象进行修改,过滤器链后面的过滤器和Servlet都会感知到。
doFilter操作是同步的,也就是说你在doFilter操作下面编写的代码会在过滤器链的下一级操作做完之后执行。
那个in就是。。。。因为现在的Filter是拦截请求,检测下是否登录,没登陆就重定向到登录页面嘛,但是,有些页面是不需要登录权限的,比如/login.html,/login还有获取验证码的Servlet,它们本来就是提供给用户进行登陆操作的界面,自然要放行它们。要不就相当于这样:
用户:我要登陆
登录页面:好啊,登录之前请出示你的身份
用户:我得登录过才有身份啊,先让我登录
登录页面:好啊,登录之前请先出示你的身份
当然,不推荐这样进行硬判断的放行操作,如果你项目的静态页面多了,难道你每一个Filter都得添加一大堆硬编码的放行文件吗?最重要的还是要有一个良好的目录层级,比如需要登陆操作的功能,我们放到/admin/路径下,然后其它的放在其他功能各自的目录下,这时候我们的过滤器只需要指定/admin/*即可。
Filter也可以用注解配置,和Servlet没啥区别,这里不说了。
过滤器匹配模式
过滤器只有三种匹配模式
- 精确匹配
/login - 后缀匹配
*.html - 前缀通配符
/*
顺序和Servlet匹配模式的顺序一致,请勿使用/,Filter中没有默认匹配。
过滤器顺序
假设现在我有这么一个Filter,用来设置整个项目的字符编码。
@WebFilter("/*")
public class EncodingFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
servletRequest.setCharacterEncoding("UTF-8");
servletResponse.setContentType("text/html;charset=utf-8");
filterChain.doFilter(servletRequest,servletResponse);
}
@Override
public void destroy() {}
}
这样我就不需要在以后的每一个Servlet中进行编码设置了,但是问题是我需要这个Filter最先执行,因为其他Filter中也可能检测参数,我们要让它们也能享受这个Filter带来的便利。
可惜,使用注解方式@WebFilter无法配置注解的执行顺序,它们的执行顺序按照Filter类名称的字典序来排序。
如果想要精确的指定顺序,可以使用web.xml,web.xml中的规则是自上而下,先配置的先被执行。
如果项目中混合使用两种方式,那么web.xml中的Filter会先于注解方式的被调用。
