EffectiveJava——第二章 创建和销毁对象
前言
本篇笔记是《Effective Java》一书的笔记。
有一定Java基础和设计模式基础的可以观看。嘻嘻。
用静态工厂代替构造器
如果你在设计一个类,你不知道该给你的类的使用者使用构造器还是静态工厂方法,大部分时候,静态工厂方法要比构造器更正确。
静态工厂方法能够带来很多好处。
静态工厂有名称
Java中的构造器被强制设计成与类同名,这可以理解,因为构造方法代表你正在创建一个类的实例,所以理应使用new 类名()的方式,这本没什么问题。但是你一定遇到过这样的问题,就是你正在设计某个用户类:
class User{
private int id;
private int age;
private String name;
}
你的业务逻辑决定你有时需要使用age,name创建用户对象,有时使用id,name创建用户对象,这时构造器就无法满足需求了。
public User(int id, String name){/* do something... */}
// 这个构造器和上面的有一样的方法签名,也就是参数类型,所以无法定义
public User(int age, String name){/* do something... */}
这时,一般我们会提供一个User(int id,int age,String name)的构造器,但是这样你就必须忍受每次使用age,name时必须也填入一个用于占位的id参数,对于id,name也是。一些人还会巧妙地进行如下设计:
public User(int id, String name){/* do something... */}
// 调换该构造器的参数顺序
public User(String name, int age){/* do something... */}
这样确实可以通过编译,而且也能解决每次传入一个多余参数的问题,但随之而来的是不清晰的定义,哪个构造器代表什么?我调用了这个构造器后会得到一个什么样的对象?如果你有很多需要这样处理的参数,指定会乱套。如果你是一个有洁癖的编码人员(实际上99%的编码人员对于代码都有洁癖),那你绝对忍受不了这样的API。
取而代之,使用静态工厂方法,你可以为它指定特别的名字:
public static User userWithIdAndName(int id,String name){/* do something... */}
public static User userWithAgeAndName(int age,String name){/* do something... */}
享元设计
这是在java.lang.Boolean中的一段代码
public static final Boolean TRUE = new Boolean(true);
public static final Boolean FALSE = new Boolean(false);
//...
public static Boolean valueOf(boolean b) {
return (b ? TRUE : FALSE);
}
public static Boolean valueOf(String s) {
return parseBoolean(s) ? TRUE : FALSE;
}
使用静态工厂方法,你可以只返回你创建好的对象,而不需要每次重新创建对象,这种设计模式叫享元模式,有点像单例模式。使用这种模式,你还可以让本类的实例受控在一定范围内,比如数据库连接池,只有200个连接对象,不会多也不会少。
这样做可以减少无用对象的创建,并且你可以设计这些对象是不可变的(Immutable)、单例的(Singleton)等,总的来说,你对它们的控制更强了。
可以返回原返回类型的任何子类型
使用Collections中的一个静态方法来说明:
// Collections.emptySortedSet
public static <E> SortedSet<E> emptySortedSet() {
return (SortedSet<E>) UnmodifiableNavigableSet.EMPTY_NAVIGABLE_SET;
}
// UnmodifiableNavigableSet.EMPTY_NAVIGABLE_SET
private static final NavigableSet<?> EMPTY_NAVIGABLE_SET =
new EmptyNavigableSet<>();
如你所见,Collections中的emptySortedSet方法的API返回一个SortedSet,这是一个接口,我们从库的使用者的角度来说,我们不知道实际返回的是什么类型,但只知道库肯定会返回一个实现类给我们,直接用就好了。实际上,它返回了UnmodifiableNavigableSet.EMPTY_NAVIGABLE_SET。
当然,这是一个老式的规约,因为在1.8以下的Java版本中,不支持在接口中创建静态方法,所以当时的约定是对于一系列Type类型的数据,使用一个不可实例化的Types类来提供一些静态工厂方法创建那些数据的对象,就像Collections一样。当然,现在我们没必要这么写了,因为接口中已经能创建静态方法了,但这种设计仍然有用武之地。
返回的对象可以随着每次调用发生变化
我举个例子,我们知到在排序数据量不大时,使用插入排序会比快速排序快,这是因为我们在分析算法复杂度时经常忽略掉常数系数。我们完全可以使用一个静态工厂方法来动态选择这两种排序。
public static <T> Sorter<T> getSorter(List<T> list){
return list.size() < 200
? new InsertSorter<T>(list) : new QuickSorter<T>(list);
}
同样,对于使用者来说也不知道这些细节,它们只知道返回了一个Sorter,可以调用Sorter有的方法。
方法返回的对象所属的类,在编写包含该静态工厂方法的类时可以不存在
用JDBC来举例吧,JDBC只提供了一套接口,定义了一套使用Java访问数据库的标准,对应的实现由数据库厂商来自行根据这套标准设计。
如果你足够细心,应该发现了,Driver、Connection、Statement和ResultSet这四个我们最常用的东西,它们都是接口,当我们使用它们的时候,你就会发现,我们使用的其实是厂商的实现类:
public static void main(String[] args) throws Exception {
Class.forName("com.mysql.jdbc.Driver");
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost/mysql","root","root");
System.out.println(conn);
conn.close();
}
这个实现类在JDBC标准设计之初并未发布,但在这里我们却能通过注册厂商驱动,然后使用一个静态工厂方法来获得它,这给我们的程序带来了很多灵活性,让我们能随意替换一些实现。
下面是getConnection方法的部分代码,选择性观看
private static Connection getConnection(
String url, java.util.Properties info, Class<?> caller) throws SQLException {
// ...
// 这里遍历所有已注册的驱动程序
for(DriverInfo aDriver : registeredDrivers) {
// 如果驱动程序能够处理这次连接
if(isDriverAllowed(aDriver.driver, callerCL)) {
try {
// 连接
Connection con = aDriver.driver.connect(url, info);
if (con != null) {
// Success!
println("getConnection returning " + aDriver.driver.getClass().getName());
// 返回connection
return (con);
}
} catch (SQLException ex) {
if (reason == null) {
reason = ex;
}
}
} else {
println(" skipping: " + aDriver.getClass().getName());
}
}
// ...
}
更多:桥接模式、ServiceLoader、服务提供者框架
缺点一,无法被子类化
当然,静态工厂方法有缺点,其中一个就是它无法被子类化,也就是说如果你使用了静态工厂构造对象,那么你就不要希望它的子类也可以如此被构造出来,这时显然更适合使用构造器。
当然这也不全是负面影响,这样的实现方式更像组合(composition),很多时候,组合要比继承更加灵活强大。
缺点二,程序员很难发现
在API文档中,静态方法并没有像构造器一样被明确的标注,需要特别注意。
Java有一套惯用名称,在使用静态工厂方法时请按照规约编写:
- from——类型转换,将一个东西转换成对应实例
Date date = Date.from(instant); - of——合并多个参数
Set<Rank> faceCards = EnumSet.of(JACK,QUEEN,KING); - valueOf
Bigintege me = Bigintege .valueOf(Intege .MAX_VALUE); - instance/getInstance——获取实例
StackWalker luke = StackWalker.getInstance(); - create/newInstance——创建新实例
Array.newInstance(clz,len); - getType ——和getInstance一样,在获取的实例不在本类中使用
FileStore s = File.getFileStore(path); - newType
- type——getType和newType的简写
Collections.list(legacyLitany);
遇到多个构造器参数时要考虑使用构建器
在业务中,很多时候需要应对一个类有大量的属性的情况,我们用一个代表HTTP请求的类来说,这里我就暂且称之为HttpRequest。
请求方法、请求URL、Header、Cookie、请求体、是否使用安全连接...光是想想就已经麻了...最关键的是这些参数并不一定在一次创建时都使用,我们可能指定URL,忽略Header;或者指定URL、Header,忽略请求体,所以我们很可能会编写这样的构造器:
public HttpRequest(String url){}
public HttpRequest(String url,String method){}
public HttpRequest(String url,Header header){}
public HttpRequest(String url,String method,Header header){}
public HttpRequest(String url,Cookie cookie){}
// ...
这代表我们必须为可选参数的每种组合创建一个单独的构造器,在这种情况下,无论是构造器和工厂方法都无法好好工作。
构建器天生适合解决这种问题。
public final class HttpRequest {
private String url;
private String method;
private Cookie cookie;
private Header header;
private Body body;
private boolean useSSL;
private HttpRequest(){}
static class Builder {
private HttpRequest request;
public Builder(){
request = new HttpRequest();
}
public Builder url(String url){
request.url = url;
return this;
}
public Builder method(String method){
request.method = method;
return this;
}
public Builder cookie(Cookie cookie){
request.cookie = cookie;
return this;
}
public Builder header(Header header){
request.header = header;
return this;
}
public Builder body(Body body){
request.body = body;
return this;
}
public Builder useSSL(boolean useSSL){
request.useSSL = useSSL;
return this;
}
public HttpRequest build(){
return request;
}
}
}
我们先是把类声明为了final,这让该类无法被继承(这条不是必须的),然后把构造方法设置成了private,让它无法被调用,这样外部就只能使用它的静态的内部类Builder进行初始化对象了。每个Builder持有了一个外部类HttpRequest对象,HttpRequest中的每一个属性都对应Builder中的一个方法,用户调用这个方法然后Builder去设置外部类实例对应的属性,并且每个方法都返回了Builder自己,这让外部可以进行链式调用:
HttpRequest request = new HttpRequest.Builder()
.url("baidu.com").method("get").useSSL(true).build();
这使得Java也能模拟Python之类的命名参数。注意在每个调用链的最后,build方法返回实际的对象。
Android的AlertDialog和OkHTTP的Request,还有很多很多东西都使用了构建器。
那么为什么不把这些东西做成一个JavaBean呢?而是通过自己编写一个冗长的构造器?像下面这样写代码不也挺好吗?
HttpRequest request = new HttpRequest();
request.setUrl("baidu.com");
request.setMethod("get");
request.setUseSSL(true);
首先不说在写法上更加丑陋了,而且对象在创建过程中分了好几个步骤,所以在并发场景下对象可能处于不一致的状态,而构建器模式的对象一旦构建出后可以是不可变的(Immutable),我们的例子中就是,这样就不会出现并发场景下的莫名其妙的、难以调试的异常。
传统的构建器稍加改动就可以适用于具有层次结构的类:
public abstract class Pizza {
public enum Topping { HAM, MUSHROOM, ONION, PEPPER, SAUSAGE };
final Set<Topping> toppings;
abstract static class Builder<T extends Builder<T>>{
EnumSet<Topping> toppings = EnumSet.noneOf(Topping.class);
public T addTopping(Topping topping){
toppings.add(Objects.requireNonNull(topping));
return self();
}
protected abstract T self();
public abstract Pizza build();
}
Pizza(Builder<?> builder){
toppings = builder.toppings.clone();
}
}
public static class NyPizza extends Pizza{
public enum Size { SMALL, MEDIUM, BIG };
private final Size size;
public static class Builder extends Pizza.Builder<Builder>{
private final Size size;
public Builder(Size size){
this.size = Objects.requireNonNull(size);
}
@Override
protected Builder self() {
return this;
}
@Override
public Pizza build() {
return new NyPizza(this);
}
}
NyPizza(Builder builder) {
super(builder);
size = builder.size;
}
}
public static class Calzone extends Pizza{
private final boolean sauceInside;
public static class Builder extends Pizza.Builder<Builder>{
private boolean sauceInside = false;
public Builder sauceInside(){
sauceInside = true;
return this;
}
@Override
protected Builder self() {
return this;
}
@Override
public Pizza build() {
return new Calzone(this);
}
}
Calzone(Builder builder) {
super(builder);
this.sauceInside = builder.sauceInside;
}
}
这里有三个类型,父类是一个抽象类,Pizza,它有两个实现类,一个是纽约风味NyPizza,一个是内置馅料的半月形Calzone披萨。除了Pizza都共有的Topping外,它们还有自己的属性,NyPizza需要传递一个大小,这里选择了在它的构建器的构造方法中传入,Calzone需要指定酱汁是否内置,使用一个构建器方法传入。
值得学习的是这里的泛型Builder和子类提供self方法实现的模板设计模式(Template Pattern)。
我稍微说一下这个self方法,因为topping是所有Pizza都要有的,所以Pizza类中的抽象的Builder类提供了一个公有的addTopping方法,这样其它的Builder都无需再次实现了,然而这个公有方法作为构建器链式调用的一部分,必须精准的返回一个子类中的Builder对象,这时this就不那么奏效了,Java中又没有诸如self这种东西,所以使用泛型让用户自己将这个子类Builder传入,并且规定所有子类必须实现self抽象方法来返回对应类型的Builder对象来满足链式调用。
有点绕,但这种实现挺常见的,例如Android的RecyclerView.Adapter就使用了这种类似的实现。
在外部,可以这样调用这些构建器
Pizza nyPizza = new NyPizza.Builder(NyPizza.Size.SMALL)
.addTopping(Topping.HAM)
.addTopping(Topping.MUSHROOM)
.build();
Pizza calzone = new Calzone.Builder()
.addTopping(Topping.ONION)
.addTopping(Topping.PEPPER)
.sauceInside()
.build();
对于Builder在特定场景下带来的灵活性,我不再夸了,自己体会。
Singleton的一些说道
传统的Singleton实现有两种
class Singleton{
private final static Singleton instance = new Singleton();
private Singleton(){}
public static Singleton getInstance(){
return instance;
}
}
class Singleton2{
public final static Singleton2 instance = new Singleton2();
private Singleton2(){}
}
第一种使用私有域,然后提供一个公有静态方法返回实例,第二种则是直接使用公有域。
这两种方法都有可能被反射打破,创建多个实例或者其他什么。两种方法各有优缺点,公有域更清淅简洁,私有域能让我们对类的控制能力更强,可以轻易的替换一些实现。
如果你将单例对象序列化,写入硬盘,再读入,就会产生两个对象,这时对象就已经不是单例的了。
@Test
public void testSerializable()throws Exception{
Singleton singleton = Singleton.getInstance();
ObjectOutputStream oop = new ObjectOutputStream(new FileOutputStream("./obj1.ser"));
oop.writeObject(singleton);
oop.close();
ObjectInputStream oip = new ObjectInputStream(new FileInputStream("./obj1.ser"));
Singleton singletonFromFile = (Singleton) oip.readObject();
oip.close();
Assert.assertEquals(singleton,singletonFromFile);
}
java.lang.AssertionError:
Expected :io.lilpig.chapter02.Singleton@722c41f4
Actual :io.lilpig.chapter02.Singleton@33833882
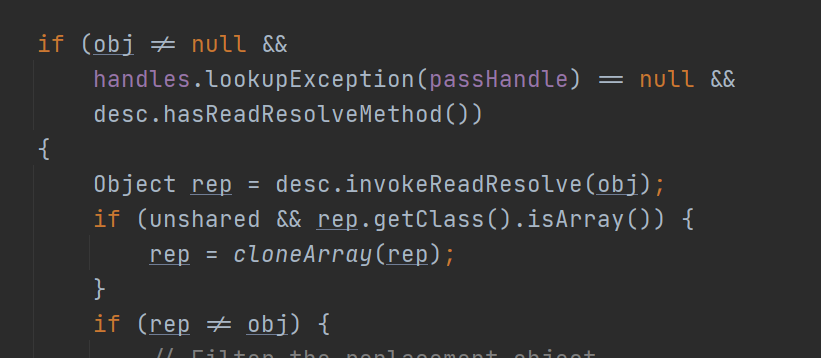
可以通过添加readResolve方法解决这个问题。
class Singleton implements Serializable {
private final static Singleton instance = new Singleton();
private Singleton(){ }
public static Singleton getInstance(){
return instance;
}
public Object readResolve(){
return getInstance();
}
}
修改后通过测试。
关于原因是ObjectInputStream中会自动检测对象有无readResolve方法,如果有会自动调用这个方法返回的对象代替。
创建单例模式的第三种方法,也是最简洁最强大的方法,是使用枚举类
enum Singleton3{
INSTANCE;
public void leaveTheBuilding(){}
}
@Test
public void testEnumSingleton(){
Singleton3.INSTANCE.leaveTheBuilding();
}
直接从根本上解决了反射和序列化问题。
不可实例化的类
当一个类不想被实例化,可能我们会将它的构造器设置成private,但是依然可以使用反射绕过访问权限控制来进行创建对象。
在构造器中抛出一个异常即可阻止它被实例化。
public class UtilityClass{
private UtilityClass(){
throw new AssertionError();
}
}
这样做也可以避免不小心在类的内部调用构造器。
这样做之后,这个类也无法被继承了,因为子类都要调用父类的构造器,不过一般设计成无法实例化的类也不会拥有子类。
依赖注入
依赖注入(Dependency Injection , DI)应该都听过,但是实际上,几乎我们所有人都自己编写过依赖注入功能。
// 拼写检查器
public class SpellChecker {
// 词典对象
private final Lexicon lexicon;
public SpellChecker(Lexicon lexicon){
this.lexicon = lexicon;
}
public boolean isValid(String word){...}
public List<String> suggesstions(String typo){...}
}
这就是依赖注入,即将外部的一个对象(只要符合这个类型)传入,为本类所服务即可。它适合一个可能使用一个类的任意多种实现,并且在编写时并不知道都有哪些实现的情况。这种情况下往往静态工厂和工具类并不适合。
有很多大型依赖注入框架,Spring就是其中之一。
避免创建不必要的对象
下面是两个功能一模一样的方法,只是其中稍有不同,我们能看到其中巨大的性能差异:
public static void impl1() throws InterruptedException {
List<String> strings = new ArrayList<>();
for (int i=0;i<10000000;i++){
// new String()
strings.add(new String("ABCDEFG"));
}
Thread.currentThread().sleep(1000*60*60);
}
public static void impl2() throws InterruptedException {
List<String> strings = new ArrayList<>();
for (int i=0;i<10000000;i++) {
// 使用字面量
strings.add("ABCDEFG");
}
Thread.currentThread().sleep(1000*60*60);
}
public static void main(String[] args) throws InterruptedException {
// impl1();
impl2();
}
Impl1的结果
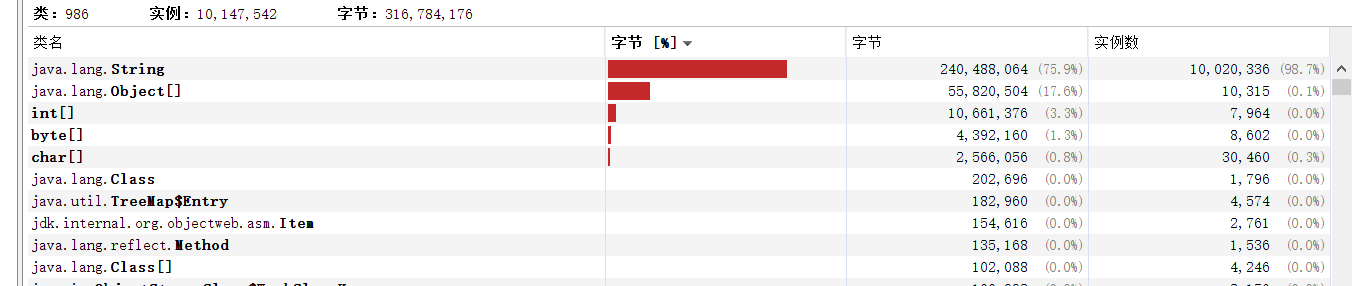
Impl2的结果

使用impl1时,系统中有一千万多个对象,正好是我们循环的数量,并且其中有75.9%的内存都是字符串占用的。而使用impl2时只有十万多个对象,而String只占用了小到可以忽略的一部分。
我们还可以观察到impl2的实例数其实就是impl1的零头,也就是说明,impl2中String对象是共用的,而impl1则每次都创建一个对象。
尤其在循环中创建变量更要小心,避免不需要的变量的创建。比如很多人在写一些需要循环的正则匹配的时候直接这样写:
while(id++<1000){
Pattern pat = Pattern.compile(REGEX);
Matcher matcher = pat.match(str[id]);
// ...
}
既然所有Pattern都是编译自一个完全一致的静态常量REGEX,那为什么要每次循环都创建一次呢?这不是给JVM找麻烦吗。
或者写出这样的具有隐式隐患的代码:
static boolean isValid(String s){
return s.match(REGEX);
}
因为String的match方法是这样写的:
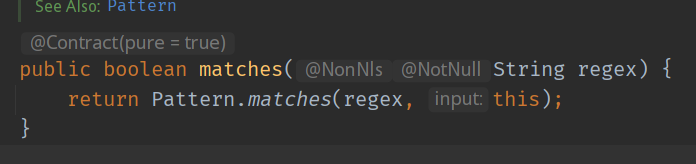
实际上还是每次创建了一个Pattern,如果你在循环中调用这样的方法,那会浪费非常多的空间,给JVM增加GC的压力。
对于有valueOf和提供构造器的类,优先使用valueOf,很多类的valueOf使用享元模式,根本不需要创建新对象。
还有装箱类型,也会创建多余变量,尽量不要在循环中使用。
当然这不是说“创建对象的成本很昂贵”,只是我们能避免时尽量避免,如果它真的是个巨大的问题,那为什么各种数据库框架还要用户的bean类使用装箱类型而非基本类型呢?如果真的有那么昂贵的成本,那么用极大的内存换null值的明确好像不太划算。
消除过期对象的引用
JVM能给我们自动清理已经没有引用的对象,程序员们不再关心对象的释放,但是很多时候,你会错误的保留已经过期对象的引用,这让JVM无法释放对象,造成内存泄漏。
如下的代码就是一个错误示范:
public class Stack {
private Object[] elements;
private int size = 0;
private static final int DEFAULT_INITIAL_CAPACITY = 16;
public Stack(){
elements = new Object[DEFAULT_INITIAL_CAPACITY];
}
public void push(Object e){
ensureCapacity();
elements[size++] = e;
}
public Object pop(){
if(size==0){
throw new EmptyStackException();
}
return elements[size--];
}
private void ensureCapacity(){
if (elements.length==size){
elements = Arrays.copyOf(elements,2*size+1);
}
}
}
pop方法中,只是将size自减一代表后面的元素已经是无用的了,但实际上那些对象仍在被引用着。直到push方法将它替换。
如果这种代码在一个长期运行的程序中存在,它就会慢慢的耗尽内存,造成严重后果。内存泄漏就像一个病毒,它可能会在系统中潜伏很久,最后爆发。
修改它也很简单
public Object pop(){
if(size==0){
throw new EmptyStackException();
}
// return elements[size--];
Object ret = elements[size];
elements[size--] = null;
return ret;
}
但是不要对这个问题过于警惕,这不是一个现代的面向对象程序员应该心心念念的事,只有当一个类自己管理内存时,可能出现内存泄漏问题,这时才应该警惕。
还有就是使用监听器模式,注册了很多监听器却没有取消注册,这些监听器就会堆积起来。
避免使用finalizer和cleaner
Java提供了finalizer方法和cleaner,这俩货并不是很多面向对象语言中所说的析构方法,它们的性能不可预测,也不一定会不会被调用,所以尽量别用。
如果你在设计一个类似数据库Connection的东西,可以使用它们进行保底,即当用户没有正确关闭Connection但该类已经要被销毁时,可以使用这俩货挣扎一下。
永远不要期望它们按照你的预期执行!!
try-with-resource优于try-finally
try-with-resource允许你写出更好看且更安全的try-catch块。
尤其在我们关闭多个资源时,经常写出嵌套好多层的try-catch-finally和if,又臭又长。
据统计,java类库中2/3的close方法都调用错了,大师也会用错,何况我们。
JDK7引入的try-with-resource就是用来解决这个问题的。

你只需要将一个或多个继承自AutoClosable的实例创建过程写在try后的括号中,并且用分号分割,java就会自动帮你处理这些资源的关闭。
其实这只是一个语法糖,编译后的代码会转换成之前我们常见的那种嵌套形式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号