索引——高性能MYSQL
简介
索引就是一个用于快速查找的文件
MYSQL的索引是存储引擎相关的,所以不能说是一个特定的数据结构,但大多都是基于B树和B+树。
由于树索引的有序性,所以查询时不用便利整个表,而且对于范围查询和排序操作有天生的优势。
推荐一篇B树和B+树的文章:面试官问你B树和B+树,就把这篇文章丢给他
复合索引
复合索引通过将列按照从左到右的顺序来作为键存储,如有一个表的schema中有
key(firstname,lastname,dob)
则在树中的键上也是按照firstname,lastname,dob进行存储的,也就是先比较第一列的大小,然后是第二列,然后是第三列,这说明
- 查找时也需要使用左到右的方向
- 如果只查询lastname或者dob,那么索引用不上
- 无法跳过列,如查询firstname和dob
- 如果左边的某一列是范围查询,则右边的所有列都无法使用索引
哈希索引
通过计算散列实现的索引
1. 全值查询很快
2. 因为无序,所以无法排序和范围查询
3. 多个列时,由于计算了整个的散列值所以无法按单个的列来使用索引
4. 哈希冲突如果过多的话,性能急剧下降
自定义哈希索引
大部分存储引擎不支持哈希索引,可以在B树索引上自定义,如存储URL,可以使用一个url和一个另外的url_crc列,使用crc32算法对url进行散列运算,存储到url_crc列中,然后查询。
SELECT id FROM urls WHERE url="www.baidu.com" AND url_crc=CRC32("www.baidu.com");
这样MYSQL优化器会选择这个url_crc列做查询,性能更快,而对于插入,则可以手动插入或使用触发器插入。
注意,原始的url比较在查询中依然不可省略,这个条件用于解决哈希冲突。
注意不要使用md5和sha1这种作为哈希函数,长字符串浪费空间,比较也慢。
高性能的索引
独立的列
查询时,索引列不能是表达式的一部分,也不能是函数的参数,否则无法使用索引。
如下,无法使用索引
SELECT actor_id FROM actor WHERE actor_id + 1 = 5;
修改
SELECT actor_id FROM actor WHERE actor_id = 4;
前缀索引
索引一个很长的字符串列时,可以考虑使用它的前缀。
这引入了一个问题,毕竟参与索引的不是完整数据,会造成索引选择性低的问题,就是说不重复的索引值和数据表记录的总行数比值过低。
所以必须在前缀长度和索引选择性之间做一个权衡,书中给了一个表,是一些城市信息,如下的查询显示了每个城市在表中出现的次数。

如果我们查询前三个字母,看看重复有多少

这表明了使用前三个字符作为前缀索引是不明智的,会大大降低索引选择性。
当查询前7个字母时,是比较合适的

还有一个办法计算该前缀可选长度,首先我们先计算该列不重复的值的个数/数据行数来计算出一个数

之后取前缀,直到接近这个数字

单列索引
“把WHERE条件里面的所有列都建立索引”这句话是有问题的。
SELECT film_id,actor_id FROM film_actor WHERE actor_id = 1 OR film_id = 1;
即使将WHERE中的所有列都建立了单独的索引,如上的代码在老版本的MYSQL中还是会变成全表扫描。
在MYSQL5.0以后则会使用两个单独的索引分别查询,并合并结果。
显然都不太好。
选择合适的索引列顺序
当不考虑排序和分组时,可以按索引列的选择性来选择合适的索引顺序。
SELECT * FROM payment WHERE staff_id=2 AND customer_id = 584;
如果要把上面的两个列创建索引,如何安排两个列的顺序呢

经过上面的查询,发现customer_id=584的记录数量远远比staff_id=2的小,这说明(可能)customer_id的选择性更高。

在查询给定customer_id=584的条件下的staff_id=2的记录条数,发现也不大,所以我们应该建立一个(customer_id,staff_id)这样的索引。
不过上面的计算是根据指定的情况(customer_id=584 and staff_id=2)来排列索引列顺序的,我们可以根据上文中的方法来获取每一列的选择性。
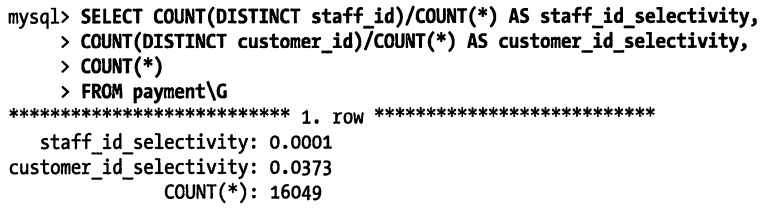
显然,customer_id的选择性更高。
在很变态的数据集分布中,这样的法则可能不适用,就比如几百万条数据中99%的人的用户名都是guest,并且他们所处的组基本都相同时用不用索引或者谁排在前面都几乎相当于全文搜索。
聚簇索引
所谓聚簇索引就是使用一个主键来组织数据的存储方式,并且它的数据行在索引的叶子页中

意思就是,索引的行和该行的数据是放在一起的。
InnoDB通过主键聚集数据,如果没定义主键,则使用非空的唯一索引代替,如果没有,则会自己生成一个隐式列来作为聚簇索引。
相对的是非聚集索引,也就是二级索引,除主键索引之外都是非聚集索引。
优点:
- 数据访问更快,因为数据和索引在一起
缺点:
- 插入速度依赖于插入顺序,非顺序插入可能会出现页分裂
- 更新主键代价过高,因为行也要跟着移动
- 二级索引需要两次索引查找,第一次找到主键值,第二次根据主键找到行数据
在InnoDB中,定义聚簇索引最好:
- 主键和数据无关,避免更改
- 主键最好有序,避免使用UUID这种随机且分布范围大的数据
所以我们定义主键时使用INT PRIMARY KEY AUTO_INCREMENT几乎是对于聚簇索引最好的写法了。
下面是同样一张表使用自增整数和uuid进行插入数据的比较
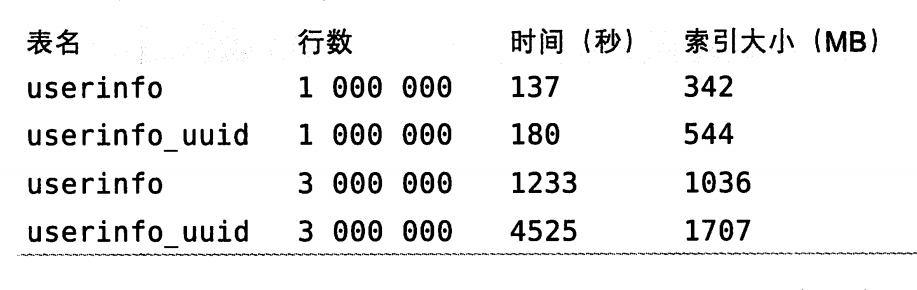
出现问题的原因在于,非顺序的插入大部分情况下会插入到已有数据的中间而不是直接加到最后,这会造成一些问题:
- 待插入的页面已经被刷出缓存,需要重新载入
- 插入的页已经不能容纳这行数据了,这时就要进行页分裂
- 由于经常出现页分裂,页会变得稀疏,并被不规则的填充,会产生数据碎片
而顺序插入恰好可以避免这些问题。
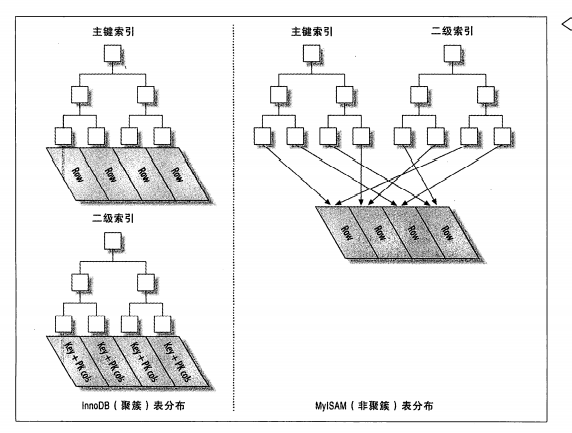
InnoDB和MyISAM的数据分布
CREATE TABLE layout_test(
col1 int NOT NULL,
col2 int NOT NULL,
PRIMARY KEY(col1),
KEY(col2)
);
MyISAM
- 数据按插入顺序存储在磁盘上
- 聚簇索引和非聚簇索引并无区别,都是按照键+行号的模式存储
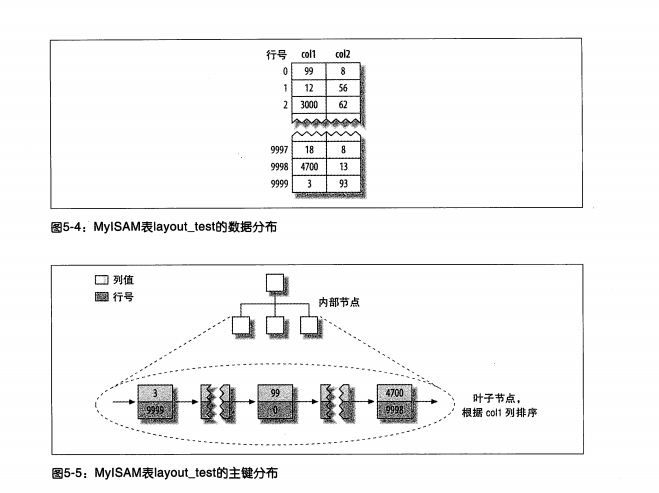
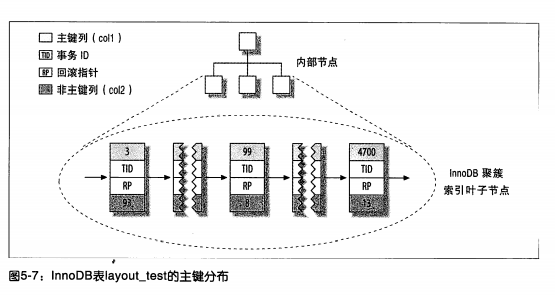
InnoDB
- 聚簇索引存储表的数据,每个索引的子页就是数据行
- 非聚簇索引存储键+主键
覆盖索引
覆盖索引部分内容来自:MYSQL覆盖索引——寻找风口的猪
所谓覆盖索引就是说索引包含了查询中的所有列,包括查询列和条件列,这样MYSQL就可以直接使用索引,而不用去找整张表。
例如现在有一个索引(store_id,film_id),执行如下查询
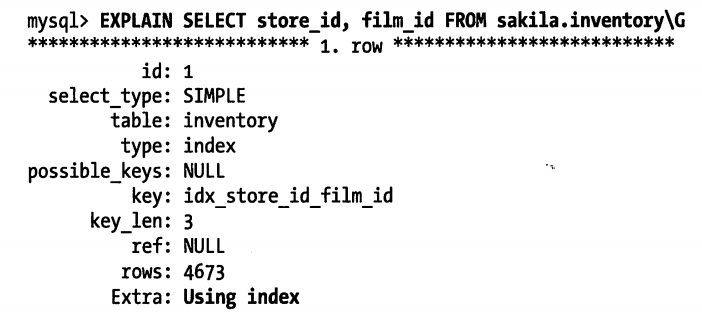
因为查询只需要store_id和film_id,正好有一个索引能覆盖他们两个,并且Extra字段为Using index,表示此次查询使用了覆盖索引。
覆盖索引的好处:
- 索引远远比数据行小,能极大的减小数据访问量
- 对于范围查询,由于索引都是按顺序存储,这样会比随即索引减少很多IO
- InnoDB使用聚簇索引,所以二级索引的叶子节点保存了主键,如果查询覆盖了二级索引的所有列和主键列,此时也可以覆盖,无需二次查询
看下这条查询(inventory_id为索引):
select sql_no_cache rental_date from t1 where inventory_id<80000;
这个查询在where中使用了inventory_id为索引,过滤了小于80000的数据,然后由于查询中需要列rental_date,索引中没有,所以这79999条数据都通过主键返回到了主表进行查询。
explain select sql_no_cache rental_date from t1 where inventory_id<80000
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
type: range
possible_keys: inventory_id
key: inventory_id
key_len: 3
ref: NULL
rows: 153734
Extra: Using index condition
1 row in set (0.00 sec)
建立联合索引
alter table t1 add key(inventory_id,rental_date);
explain select sql_no_cache rental_date from t1 where inventory_id<80000
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
type: range
possible_keys: inventory_id,inventory_id_2
key: inventory_id_2
key_len: 3
ref: NULL
rows: 162884
Extra: Using index
1 row in set (0.00 sec)
再来看一个查询(tid为主键)
explain select tid,return_date from t1 order by inventory_id limit 50000,10
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 1023675
1 row in set (0.00 sec)
type: ALL证明这是一个全表扫描,性能很垃圾。优化:
alter table t1 add index liu(inventory_id,return_date);
explain select tid,return_date from t1 order by inventory_id limit 50000,10\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
type: index
possible_keys: NULL
key: liu
key_len: 9
ref: NULL
rows: 50010
Extra: Using index
1 row in set (0.00 sec)
这里有一个小技巧,因为InnoDB的索引叶子节点就是主键id,所以这里创建的索引无需包含主键id。
使用索引排序
因为索引是有序的,如果排序用到的列是索引,那当MYSQL遇到ORDER BY时就不会排序,而是使用索引,这时只需要按顺序读就行了。
设计索引时如果想要根据它们排序,需满足
- 索引顺序和ORDER BY顺序一致,排序方向一致
- 关联多张表时,ORDER BY的字段来自第一个表
- 最左前缀要求
- 非最左前缀但左面的列被指定成常数
下面来几条语句,索引为(rental_date,inventory_id,customer_id)
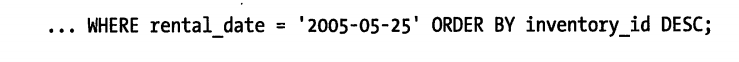
这条使用了索引排序,因为rental_date是常数,与inventory_id构成最左前缀
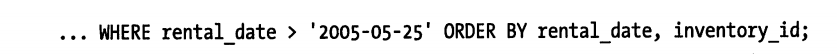
这个当然也没问题,虽然前面使用了范围查询,但ORDER BY中就是最左前缀


索引案例
现在我们要设计一个在线约会网站,用户信息包括国家、地区、城市、性别、眼睛颜色、年龄等等,需要我们来支持根据各种信息搜索用户,还要允许通过用户的最后在线时间、其他会员对用户的评分等对用户进行排序并对结果进行限制。
支持多种过滤条件
首先肯定是选择性高的放在索引的前面,但是这里我们可以把选择性很低的sex和country作为前缀构成(sex,country),在线约会网站的特性决定了这两个字段经常在过滤中被用到,而且就算不被用到,也可以使用sex in ('m','f')来跳过这个字段。但这个in列表不能太长,如国家和地区就不太适合用这个技巧,根据乘法原理,MYSQL优化器将它们展开后得到的组合数会很多。
然后还有就是可能有下面这些经常被用到的索引:
(sex,country,age)、(sex,country,region,age)和(sex,country,region,city,age),如果想复用索引,可以使用前面的in方法,但是这个组合数就很多了。
把age放在后面是有原因的,因为age大部分时间内都是范围查询。
对于,眼睛颜色,头发颜色这些生僻的不会经常被查询到的并且选择性很高的列,可以直接不管他们,让MYSQL多扫描一些额外的行,也可以在age前面加上这些行,然后必要时使用in来过滤。
避免多个范围条件
WHERE eye_color IN ('brown','blue','hazel')
AND hair_color IN ('black','red','brown')
AND sex IN ('m','f')
AND last_online > DATE_SUB(NOW(),INTERVAL 7 DAY)
AND age BETWEEN 18 AND 25
这个查询有多个范围条件,这会导致age用不上索引或者last_online用不上索引。并且这两个中的任何一个转换成in的形式所带来的组合数都是很高的。
这时我们可以通过维护一个active列,每次用户登陆时将它设置为1,使用定时任务为7天未登录的用户设置为0,然后将active加入到索引中即可。
优化排序
一般来说都是通过rating这种列来排序的,我们可以创建例如(sex,rating)的索引来优化排序。
SELECT * FROM profiles WHERE sex='m' ORDER BY rating LIMIT 10;
这会使上面的查询效率极大提升。
同时分页偏移量过大会影响效率,这可以通过限制用户能翻的页数来解决。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号