【速读】——ResNeXt
Saining——【arXiv2017】Aggregated Residual Transformations for Deep Neural Networks
目录
- 作者和相关链接
- 主要思想
- ResNet和ResNext对比
作者和相关链接
- 作者

主要思想
- 要解决的问题是什么?
对于ResNet,VGG,Inception等网络,需要由一些重复的building block堆叠而成,而这些building block的滤波器个数,大小等不能任意设置,需要人工调整。由于其中有很多超参数需要调整,而且在不同的vision task甚至是不同的dataset上参数不能直接共享需要进行个性化定制,因此,这种需要为一定task或者dataset定制的module虽然效果好,但通用性太差。这篇文章介绍了一种新的building block,可以用来替换ResNet的building block,新的模型称为ResNeXt。ResNeXt的最大优势在于整个网络的building block都是一样的,不用在每个stage里再对每个building block的超参数进行调整,只用一个building block,重复堆叠即可形成整个网络。实验结果表明ResNeXt比ResNet在同样模型大小的情况下效果更好。
- 解决思路?
将ResNet的blcok(如图Figure 1的左图所示)换成ResNeXt的block(如图Figure 1的右图所示),实际上是将左边的64个卷积核分成了右边32条不同path,每个path有4个卷积核,最后的32个path将输出向量直接pixel-wise相加(所有通道对应位置点相加),再与Short Cut相加
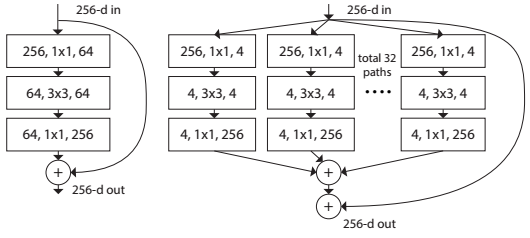 Figure 1. Left: A block of ResNet [13]. Right: A block of ResNeXt with cardinality = 32, with roughly the same complexity. A layer is shown as (# in channels, filter size, # out channels)
Figure 1. Left: A block of ResNet [13]. Right: A block of ResNeXt with cardinality = 32, with roughly the same complexity. A layer is shown as (# in channels, filter size, # out channels)
- Cardinality和Bottleneck
这篇文章提出了一种新的衡量模型容量(capacity,指的是模型拟合各种函数的能力)。在此之前,模型容量有宽度(width)和高度(height)这两种属性,本文提出的“Cardinality”指的是网络结构中的building block的变换的集合大小(the size of the set of transformation)。如图Figure 2所示,(a)、(b)、(c)三种结构是等价的,本文用的是图(c)。实际上Cardinality指的就是Figure 2(b)中path数或Figure 2(c)中group数,即每一条path或者每一个group表示一种transformation,因此path数目或者group个数即为Cardinality数。Bottleneck指的是在每一个path或者group中,中间过渡形态的feature map的channel数目(或者卷积核个数),如Figure 2(a)中,在每一条path中,对于输入256维的向量,使用了4个1*1*256的卷积核进行卷积后得到了256*4的feature map,即4个channel,每个channel的feature map大小为256维,因此,Bottleneck即为4。
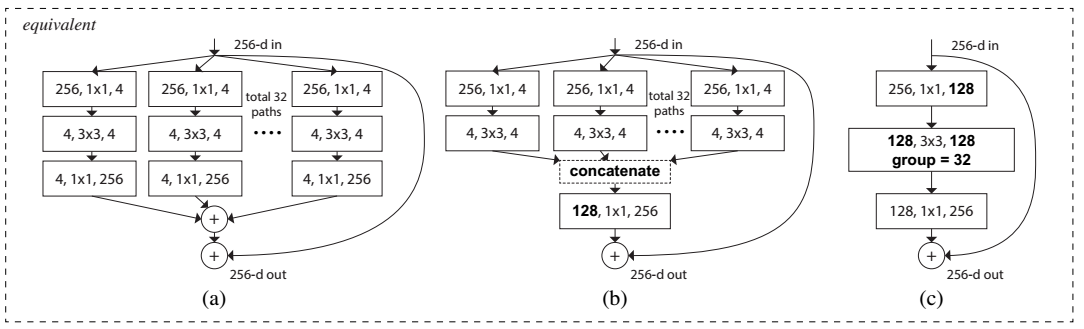
Figure 2. Equivalent building blocks of ResNeXt. (a): Aggregated residual transformations, the same as Fig. 1 right. (b): A block equivalent to (a), implemented as early concatenation. (c): A block equivalent to (a,b), implemented as grouped convolutions [23]. Notations in bold text highlight the reformulation changes. A layer is denoted as (# input channels, filter size, # output channels).
ResNet和ResNeXt对比
- 网络结构对比
图Figure 2所示表示的depth=3的情况下ResNet和ResNeXt的building block的对比。
- 具体配置对比
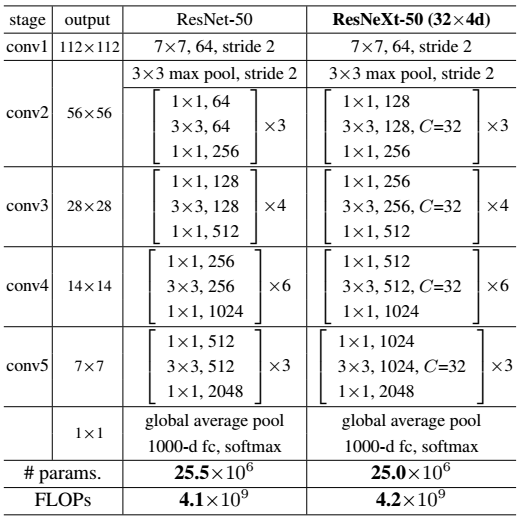
ResNet-50和ResNeXt-50的building block的配置对比如Table 1所示,图中C=32即表示Cardinality=32,Bottleneck= 4,即如图Figure 2中所示。
Table 1. (Left) ResNet-50. (Right) ResNeXt-50 with a 32×4d template (using the reformulation in Fig. 3(c)). Inside the brackets are the shape of a residual block, and outside the brackets is the number of stacked blocks on a stage. “C=32” suggests grouped convolutions [23] with 32 groups. The numbers of parameters and FLOPs are similar between these two models.
- 模型大小计算
以图Figure 3为例,ResNet的参数个数为256 · 64 + 3 · 3 · 64 · 64 + 64 · 256 ≈ 70k 。
ResNeXt的参数个数为C · (256 · d + 3 · 3 · d · d + d · 256),其中,C表示Cardinality=32,d表示bottleneck=4,因此参数总数 ≈ 70k 。

Figure 3. Left: A block of ResNet [13]. Right: A block of ResNeXt with cardinality = 32, with roughly the same complexity. A layer is shown as (# in channels, filter size, # out channels)
- 实验结果对比
- 证明ResNeXt比ResNet更好,而且Cardinality越大效果越好
Table 2. Ablation experiments on ImageNet-1K. (Top): ResNet-50 with preserved complexity (∼4.1 billion FLOPs); (Bottom): ResNet-101 with preserved complexity ∼7.8 billion FLOPs). The error rate is evaluated on the single crop of 224×224 pixels.

-
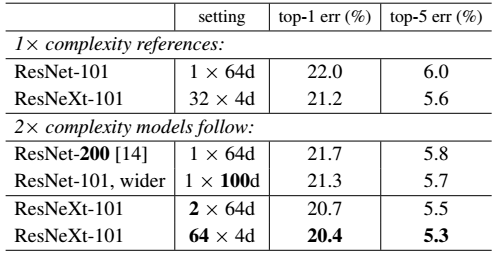
- 证明增大Cardinality比增大模型的width或者depth效果更好
Table 3. Comparisons on ImageNet-1K when the number of FLOPs is increased to 2× of ResNet-101’s. The error rate is evaluated on the single crop of 224×224 pixels. The highlighted factors are the factors that increase complexity.