
论文阅读(XiangBai——【CVPR2017】Detecting Oriented Text in Natural Images by Linking Segments)
XiangBai——【CVPR2017】Detecting Oriented Text in Natural Images by link Segments
目录
- 作者和相关链接
- 方法概括
- 方法细节
- 实验结果
- 方法的局限性
- 总结与收获点
作者和相关链接
- 作者

方法概括
-
文章简述:
- 方法名字:SegLink
- 改进版的SSD用来解决多方向的文字检测问题
-
方法的性能
- ICDAR15 Incidental: 0.75(f)
- MSRATD500: 0.77(f), 8.9FPS (112 ms/per image)
- ICDAR2013: 85.3(f), 20.6FPS (50 ms/per image)
-
算法的pipeline
- 整个检测过程分两步
- Step 1: 图像输入到ssd网络,同时输出两类信息
- 第一类信息是text的box信息,有两点需要注意,一是这个box是多方向的,也就是带角度信息的;另一点是box不是整个文本行(或者单词)的box,而是文本行(或者单词)的一个部分,称为segment,可能是一个字符,或者一个单词,或者几个字符,比如图fig 1中的每个黄色框即为一个segment。
- 第二类信息是不同box的link信息,因为segment是类似于字符级或者单词级的,但最后目标是要输出整个文本行(或者单词),所以如果按以前传统方法,是要后处理把这些segment连接成文本行(或者单词)的,文章的高明之处在于把这个link也弄到网络中去自动学习了,网络自动学习出哪些segment属于同一个文本行(或者单词),比如图fig 1中连接两个黄框的绿色线即为一个link。
- Step 2: 有了segment的box信息和link信息,用一个融合算法得到最后的文本行(或者单词)的box(也是带方向的, x, y, w, h, θ)
- Step 1: 图像输入到ssd网络,同时输出两类信息
- 整个检测过程分两步


Figure 1. Illustration of SegLink. The first row shows an image with two words of different scales and orientations. (a) Segments (yellow oriented boxes) detected on the image. (b) Links (green lines) detected between pairs of adjacent segments. (c) Segments connected by links are combined into whole words. (d-f) The SegLink strategy is able to detect text in arbitrary orientation and long lines of text in non-Latin scripts.
-
改进的SSD的地方:
-
- 原版SSD只输出rectangle bounding box(x, y, w, h四个参数)→加入角度信息,输出的是oriented bounding box(x, y, w, h, θ), θ表示矩形的角度(与水平方向,按顺时针为正,逆时针为负)
- 每个feature map的每个位置上有多个不同aspect ratio的default box →每个位置上只有1个default box(加速的原因之一)
- 每层的feature map决定的default box的scale不再人工定义(10-90,平均分5次)→scale由感受野大小来决定
- 最大的亮点:网络不但学习了segment的box,也学习了segment的link关系,来表示是否属于同一个单词(或者同一文本线)
- 训练用的groundTruth除了因为多方向所以用的是旋转后的groundTruth,还要有一个link的groundTruth
- 损失函数加入了link的损失项
-
方法的优势
- 多方向,多语言,速度快,精度高,易训练,可检测任意长度(单词或者文本行)
方法细节
-
word, segment, link的定义(看不是很懂?那就往下看...)
- segment: A segment is a bounding box that covers a part of a word (for clarity we use “word” here and later, but segments also can be applied to a “text line” that contains multiple words)
- link: A link connects a pair of adjacent segments, indicating that they belong to the same word. Links are not only necessary for combining segments into whole words, but also helpful for separating two adjacent words, between which the link should be predicted as negative.
- Word: Each word is composed of a number of segments with the links between all the adjacent pairs
-
CNN modelCombining segments with links
-
网络结构
-
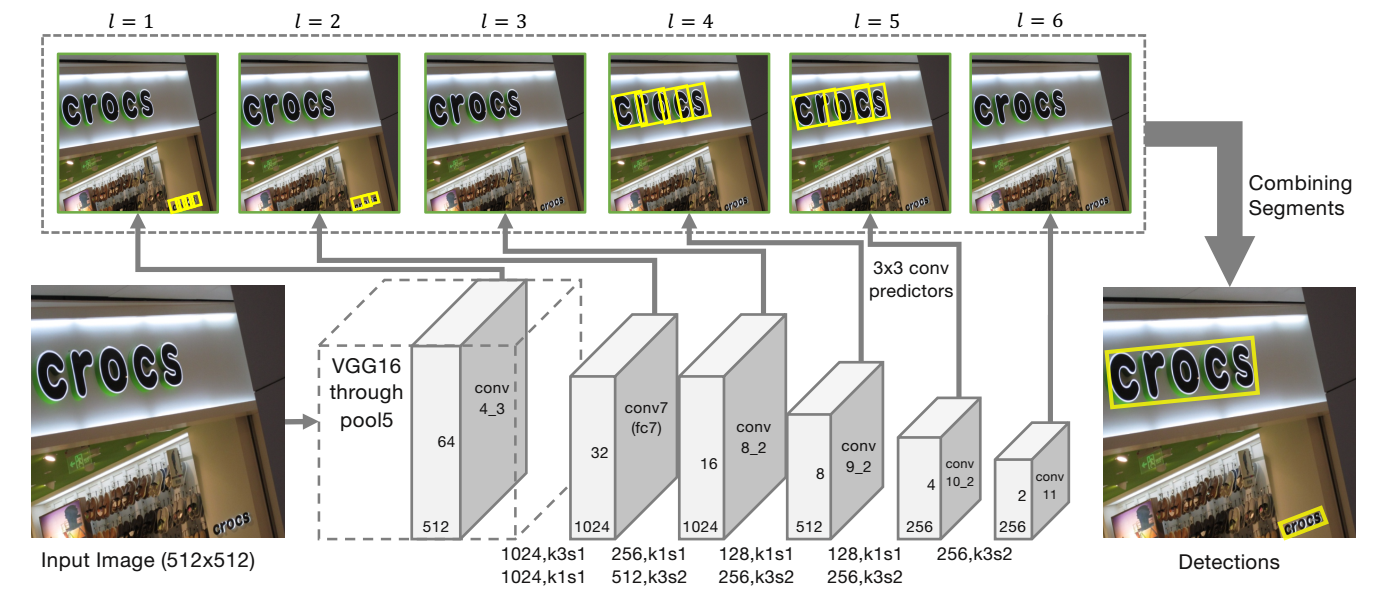
Figure 2. The architecture of the proposed detection network. The network consists of convolutional feature layers (shown as gray blocks) and convolutional predictors (thin gray arrows). Convolutional filters between the feature layers (some have one more convolutional layer between them) are represented in the format of “(#filters),k(kernel size)s(stride)”. Segments (yellow boxes) and links (not displayed) are detected by the predictors on multiple feature layers (indexed by l), then combined into whole words by combining algorithm.
-
-
- 若只考虑segment的box预测部分(segment detection),网络结构上和原来的ssd相似,不同的地方在于
- ssd最后一个pool层变成了conv11
- 每个feature map的每个位置上只用了一个aspect ratio = 1(不是原来的1, 2, 3, 1/2, 1/3)
- 输出从(x, y, w, h)变成了(x, y, w, h, θ),论文中提到的公式1~6实际上和ssd是一样的,换汤不换药
-
- 原图大小为
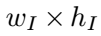 ,第l层的feature map大小为
,第l层的feature map大小为
-
default box 的中心位置(这个怀疑公式是不是写错了? 应该是xa=(x+0.5)/wL*wi...?)
- 原图大小为
- 若只考虑segment的box预测部分(segment detection),网络结构上和原来的ssd相似,不同的地方在于
-
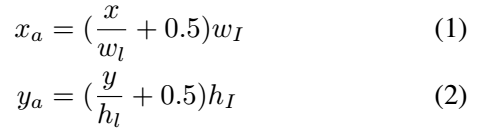
-
-
-
-
- default box 的scale设置不再是人工设置,而是与感受野大小相关
- 原来的ssd的scale: ar表示default box的长宽比,sk表示第k层的default box的scale。smin=0.2, smax=0.9, m = 6。
- default box 的scale设置不再是人工设置,而是与感受野大小相关
-
-
-

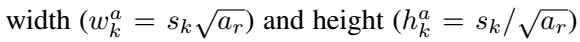

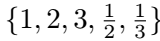
-
-
-
-
-
- 现在的ssd的scale: 分子wI表示输入的原图大小,分母wl表示第l层的feature map的大小,所以wI/wl可以表示该层的神经元的感受野。比如原图8*8,现在feature map只剩4*4了,说明,现在的每个像素对应原来的(8/4)×(8/4)= 2*2的区域,所以default box的大小设置应该与这个感受野成正比。
-
-
-
-
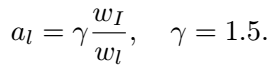
-
-
-
-
- 预测的offsets里除了Δx, Δy, Δw, Δh, 多了一个Δθ
-
-
-

-
-
within-layer link and cross-layer link detection
- within-layer link:在同一个feature map层(conv 4_3, conv7, conv8_2, conv9_2, conv10_2, conv11这六层后面接3*3的filters进行prediction),每个segment与它周围的8连通的8个邻居的segment的连接情况,每个link有两个分数,一个用是正分,一个是负分,正分用来表示二者是否属于同一个单词,是否应该连接;负分表示二者是否属于不同单词,是否应该断开连接。所以,每个segment的link应该是8*2=16维的向量。neighbor的规范化定义如公式(9)。如图Fig 3中的(a)图,黄色框的邻居为两个蓝色框,他们之间有link(绿色的线),表示属于同一个单词。
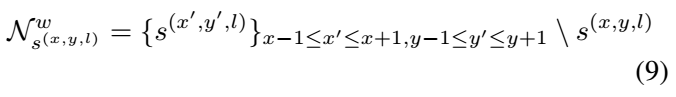
- within-layer link:在同一个feature map层(conv 4_3, conv7, conv8_2, conv9_2, conv10_2, conv11这六层后面接3*3的filters进行prediction),每个segment与它周围的8连通的8个邻居的segment的连接情况,每个link有两个分数,一个用是正分,一个是负分,正分用来表示二者是否属于同一个单词,是否应该连接;负分表示二者是否属于不同单词,是否应该断开连接。所以,每个segment的link应该是8*2=16维的向量。neighbor的规范化定义如公式(9)。如图Fig 3中的(a)图,黄色框的邻居为两个蓝色框,他们之间有link(绿色的线),表示属于同一个单词。
-
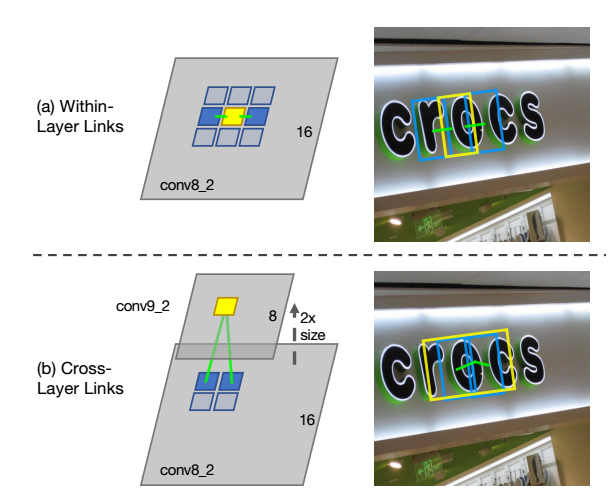
Figure 3. Within-Layer and Cross-Layer Links. (a) A location on conv8˙2 (yellow square), its 8-connected neighbors (blue squares). Two within-layer links (green lines) connect a segment (yellow box) and its two neighboring segments (blue boxes) on the same layer. (b) Two cross-layer links connect a segment on conv9 2 (yellow) and two segments on conv8 2.
-
-
-
cross-layer link:因为同一个单词可能在不同层上都检测到了,只不过segment的大小有所不同。所以为了解决这种重复检测的冗余问题,引入了这个跨层链接。在相邻两层的feature map上,后面那层的segment的邻居除了自己本层的邻居外,在前一层也有它的邻居(注意只是前一层是后一层的邻居,但后一层不是前一层的邻居,所以,只有conv7, conv8_2, conv9_2, conv10_2, conv11这5层有前邻居,conv4_3无前邻居)。它的邻居是指前一层那些更小的segment。由于conv 4_3, conv7, conv8_2, conv9_2, conv10_2, conv11这几层中,后一层的feature map都是是前一层的feature map大小的一半(conv4_3后有一个2*2的pool, conv8_2~conv10_2后分别有一个3*3,步长为2的卷积,所以都是大小减半,但是conv7到conv8_2之间没有pool或步长为2的conv啊?),所以实际上是后一层的每个segment的前邻居就是前一层的feature map对应位置的2*2=4个小segment。另外,这种策略要求所有的feature map大小是偶数的,所以,输入图像要求是128的倍数(怎么算的?)。cross-layer的link的规范化定义如公式10。如图Figure 3所示,黄色框是下一层的segment,蓝色框是上一层的更加细,更加小的框,黄色框与上一层的两个篮框有连接,说明属于同一个单词,后面会根据这个信息把这三个框融合起来。
-
-
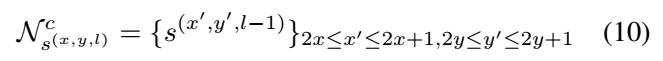
-
-
output of convolutional predictor,每一层的输出参数个数
- 如下图,第l层的feature map大小为,每个位置上都有2+5+16+8=31维的输出。2表示是或不是字的二类分类分数,5表示位置信息x, y, w, h, θ,16表示8个同层的neighbor的连接或者不连接2种情况,8表示前一层的4个neighbor的连接与不连接情况。当然,conv4_3层没有cross-layer link,所以只有2+5+16=23维输出。
- 如下图,第l层的feature map大小为
-

Figure 4. Outputs of a convolutional predictor. Cross-layer link scores are not predicted on conv4 3.
-
Training
-
GroundTruth of segments and links
- 如何判断一个default box为正样本?如何确定一个default box和哪个groundTruth的word进行link?
-
(1) 如果图上只有1个word(原始groundTruth),则一个default box判断为正样本且和该word有link的条件
-
-
-
-
- default box的中心在word里面(如图Figure 5.(1)中所示)
- default box的高度和word的高度比小于1.5,即
-
-
-
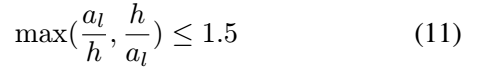
(2) 如果图上有多个word(原始groundTruth),则一个default box判断为正样本且和某word有link的条件
-
-
- default box和任何word都不满足(1)中的条件,则标记为负样本,与所有word都不link。否则,标记为正样本,且与大小和该default box最接近的那个word有link。
-
-
-
-
- 由原始的groundTruth如何得到训练要用的可以用来选择segment的groundTruth segment?
- 如图Figure 5,先把原始的groundTruth——黄色的word bounding box绕default box的中心逆时针旋转θ(实际上这个图里的θ是负数的,所以我们看到的是顺时针旋转),把不在default box的左右两边部分裁掉,再绕default box的中心顺时针旋转θ,转回原来的word bounding box所在的位置,这样得到的那个裁切过后的矩形(也带角度)为所谓的groundTruth segment。可以看出,最终的效果实际上就是把原来的word bounding box裁到和default box宽度一样,以此来作为训练要用的groundTruth segment。之所以要这么做,是因为现在的网络目标是要找到segment,而不是要整个word。最后网络要学的offset的时候就是如图Figure 5.(4)中的蓝色default box和黄色groundTruth segment之间的offset(包括中心点的x, y, w, h, θ) (要学习的宽度的offset,Δw不是应该始终为0?)
- 由原始的groundTruth如何得到训练要用的可以用来选择segment的groundTruth segment?
-

Figure 5. The steps of calculating a groundtruth segment given a default box and a word bounding box.
-
-
optimization
- 目标函数:由三个部分构成,是否是text的二类分类的softmax损失,box的smooth L1 regression损失,是否link的二类的softmax损失。λ1和λ2控制权重,最后都设为1.
-
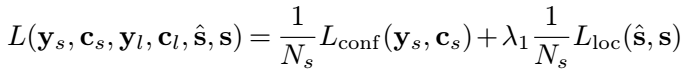

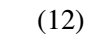
-
-
Online Hard Negative Mining和Data Augmentation的使用与SSD一样
-
-
Combining算法
- ssd网络的输出用阈值过滤一部分,α和β分别表示segment和link的阈值(这两个值用网格搜索找到最优)
- 把每个segment看做node, link当做edge,建立图模型,再用DFS(depth first search)找到连通分量,每个连通分量即为一个单词,用下面的Algorithm1进行融合输出单词的box
- Algorithm1 实际上就是一个平均的过程。先求所有segment的平均θ作为word的θ,再以得到的θ为已知条件,求出最可能过每个segment的直线(线段),以线段中点作为word的中心点(x, y),最后用线段长度加上首尾segment的平均宽度作为word的宽度,用所有segment的高度的平均作为word的高度。

实验结果
-
实验细节
- pretrain
- VGG的SynthText dataset
- learning rate = 10^-3 for first 60k iterations, decayed to 10^-4 for the rest 30k iterations
- fine tune
- real data
- learning rate = 10^-4 for 5-10k iterations
- SGD+moment = 0.9
- training image size = 384*384
- batch size = 32
- grid search step = 0.1
- TensorFlow framework
-
Xeon 8-core CPU (2.8 GHz), 4 Titan X Graphics Card, and 64GB RAM. The training process runs on 4 GPUs in parallel, with each GPU processing 8 out of the 32 images in a batch at a time.
-
The whole training process takes less than a day. Testing is performed on one GPU
- pretrain
-
评价工具
- 多方向:ICDAR15的官方提交的评价服务器,实际上和MSRATD500的评价标准很相似,具体可以看这篇论文介绍
- 水平:Detval
-
ICDAR2015 Incidental库的结果

-
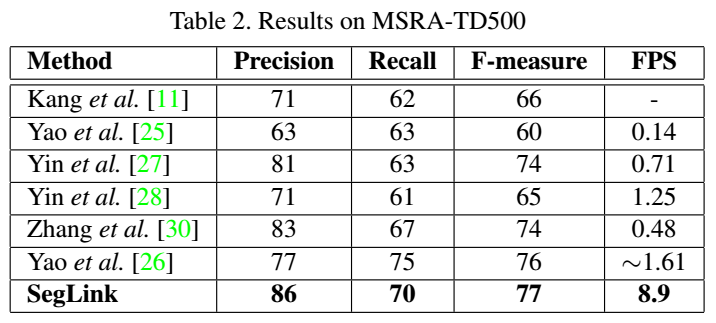
MSRA-TD500库的结果
-
ICDAR2013库的结果

-
检测结果样例

方法的局限性
- α和β这两个阈值设置需要人工,虽然用了网格搜索求得
- 不能检测间隔很大的文本行
- 不能检测形变或者曲线的文本

总结与收获点
- 多方向是个热点,今年的多篇文章都是做多方向的
- 这篇文章主要是两点创新,第一加入方向信息把ssd改造成多方向的,第二把link融合到网络一起学习。方法不但性能好,速度真的是相当快,都快达到实时的要求了...

