论文阅读(Weilin Huang——【AAAI2016】Reading Scene Text in Deep Convolutional Sequences)
Weilin Huang——【AAAI2016】Reading Scene Text in Deep Convolutional Sequences
目录
- 作者和相关链接
- 方法概括
- 创新点和贡献
- 方法细节
- 实验结果
- 问题讨论
- 总结与收获点
- 参考文献
作者和相关链接

方法概括
- 解决问题:单词识别
- 主要流程:maxout版的CNN提取特征,RNN(LSTM)进行分类,CTC对结果进行调整。整个流程端到端训练和测试,和白翔的CRNN(参考文献1)方法几乎一样,以下为流程图
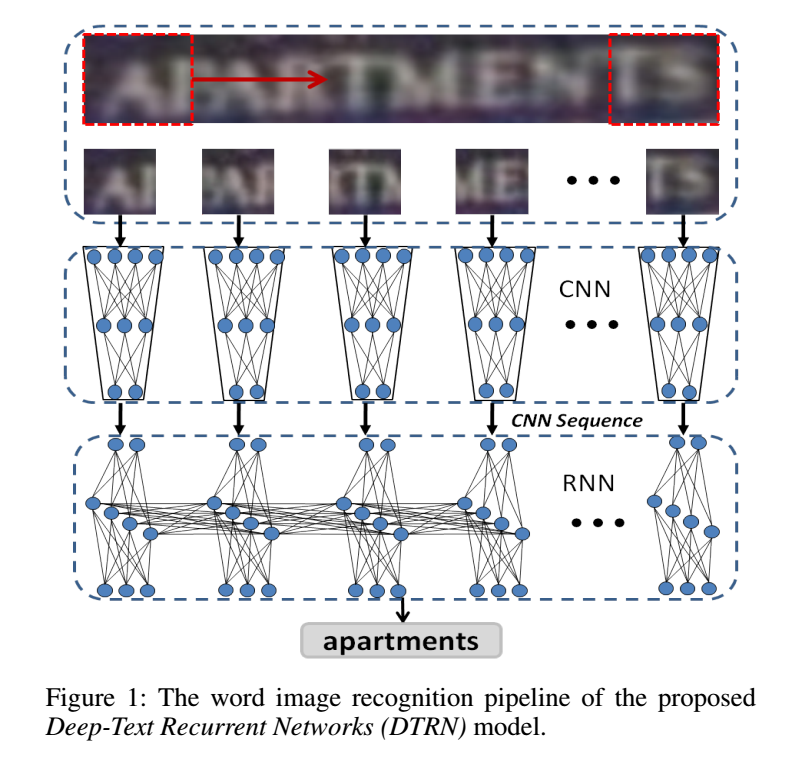
创新点和贡献
-
idea的出发点——把单词识别问题看成是sequence labelling的问题
- 传统的OCR流程:
- 字符级分割
- 字符分类器
- 后处理(语言模型)
- 传统的OCR流程:
-
- 传统OCR方法的问题:
- 字符分割难度大,准确率受限 → 影响识别的整体性能 —— 不用分割(当做序列识别问题)
- 忽略了上下文信息 → 削弱识别的鲁棒性和可靠性 —— 用RNN做分类器可以充分利用上下文信息
- 一般用低级(像素级)或中级特征(HOG,strokelet之类)→ 鲁棒性差 —— 用CNN学习鲁棒的特征(CNN的区域卷积具备平移不变形,对形变具有鲁棒性)
- 传统OCR方法的问题:
-
方法的优点
- 能正确识别有歧义的文字图像
- 能正确识别形变大的文字图像
- 不用字典(可以识别新词,任意没有语义的字符串)
- 效果好!(IC03-50 = 97, IC03-FULL = 93.8,SVT-50 = 93.5)
方法细节
-
maxout CNN
-
maxout激活函数和ReLU激活函数的对比
- ReLU只是简单的截断(小于0),Maxout则是一个分段线性函数(可以拟合任何的凸函数)
- 参数个数:ReLU只有一套参数(1个W和b),maxout有多套参数(k个W和k个b)
-

-
-
maxout的示例
- maxout实际上就是把滤波器分成k=2(本例中取2)组,不同组的神经元输出互相一一对应,取其中最大的作为最后的输出
- 如下图所示,W1j和W2j是两组滤波器,每组是64个滤波器,上下两个滤波器互相对应,分别与上一层的feature map对应位置进行卷积,取其中大的为新的输出。例如蓝色和橙色,蓝色得到的结果比橙色大,故最后8*8*64的输出的feature map对应的位置为蓝色(蓝色滤波器卷积的结果),灰色和红色中红色更大。
-
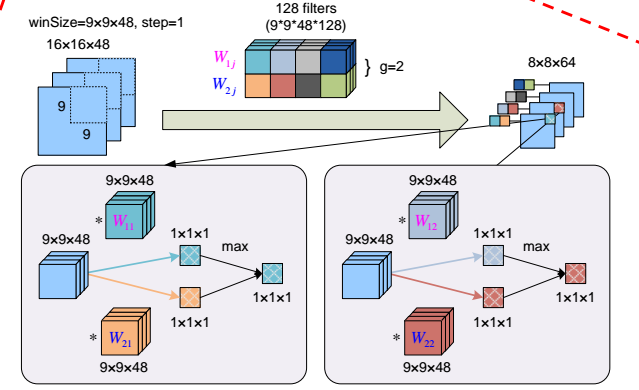
-
-
本文的maxout CNN 网络结构
- 五个卷积层,前四层提特征,最后一层分类器(实际上没用?),没有池化层,没有全连接层
- 第四层的128维即为CNN特征(要输入到RNN中的)
- 前3层的maxout分为2组,后面两层为4组。
-

-
RNN(LSTM)
-
- LSTM为双向LSTM
- xi就是CNN的128维特征,T表示单词的滑窗个数(高度归一化到32,步长为1进行滑窗,每个窗口得到一个长度为128的cnn特征——xi)
- pi是一个长度为37的概率向量(因为不考虑字母的大小写共36类,加1个背景类,共37类
识别(从CNN特征到最后的单词输出)流程
-
- 流程图
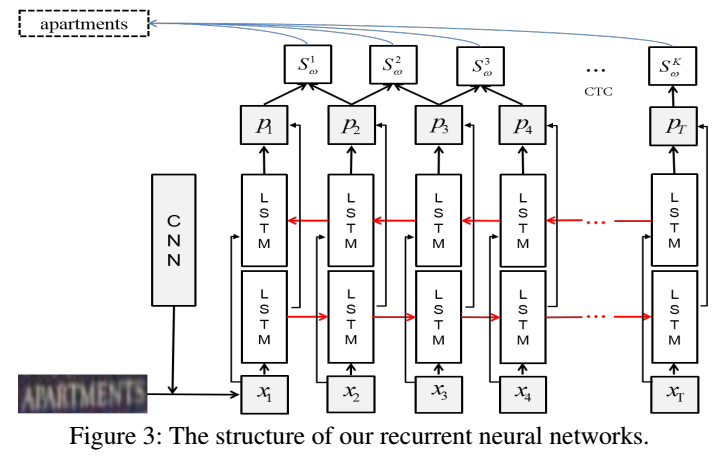
-
- RNN对每个位置的窗口进行识别:X = (x1, x2, ..., xT) → P = (p1, p2, ..., pT)
- CTC得到单词输出:P = (p1, p2, ..., pT) → L = (l1,l2,..., lk) ,例如,L = ‘apartments'
- CTC的全称:connectionist temporal classification (参考文献2)
- CTC的公式
- 其中,π表示某长度为T的某一个序列,例如,π = ’a__pp__aart_mm_een_t_s__'
- B表示简单的去掉空格和去重操作,例如B(π) = B(’a__pp__aart_mm_een_t_s__') = apartments
- P(π|p)=π的每个位置上属于某个字符的概率的乘积:P(π|p) = P(π1|p) × P(π2|p) ×P(π3|p) × .... ×P(πT|p)
![]()
-
-
- CTC实际上是用动态规划方法算出所有可能的串的概率(每个位置的概率乘积),然后选择其中概率最大的串作为最后输出
-
实验结果
-
识别结果(表格带字典,右图不带字典,为任意字符串)

-
结果示例

问题讨论
- maxout 的CNN中的最后一个softmax层似乎没用到?直接用RNN做的分类,整个过程也是端到端的训练
总结与收获点
- 本文方法和白翔的CRNN的不同点在于:第一,白翔的CNN是普通的CNN,本文CNN用的是maxout的CNN。第二,白翔的CNN最后用了一个Map-to-Sequence把CNN最后一层的feature map上的每个滑动窗口直接拉成一列一列的特征输出到RNN中,而这篇文章的CNN是原图中的每个32*32个大小的滑动窗口,直接得到第四层的一个卷积向量作为该窗口的特征(最后一层用的滤波器大小和该窗口对应的feature map大小一样,故得到1*1的值),虽然实际上大同小异。其他关于RNN和CTC的用法几乎一致,白翔的文章还提到了用字典和不用字典的两种识别策略。
- 本篇最大的亮点:把识别问题看成sequence labelling问题,把CNN和RNN放在一个网络中进行端到端训练(这一点也和白翔他们一样)
参考文献
- Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
-
Graves, A.; Fernandez, S.; Gomez, F.; and Schmidhuber, J. 2006. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. IEEE International Conference on Machine Learning (ICML)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号