
论文阅读(Xiang Bai——【CVPR2015】Symmetry-Based Text Line Detection in Natural Scenes)
Xiang Bai——【CVPR2015】Symmetry-Based Text Line Detection in Natural Scenes
目录
- 作者和相关链接
- 方法概括
- 创新点和贡献
- 方法细节
- 实验结果
- 问题讨论
- 总结与收获点
- 参考文献
-
作者和相关链接
- 作者

-
方法概括
- Step 1: 采用多尺度滑窗检测文本线的中心像素点,用对称特征和表观特征训练的随机森林得到候选的字符像素区域(两种特征是作者自己提的,文章亮点所在);
- Step 2: 利用字符像素的角度和距离约束,将候选字符像素点聚合成字符串区域;
- Step 3: 用两个CNN分类器,字符级和字符串级,过滤非字符串区域,并采用常规的方法将文本线切成单词(不是重点,很简略)

Figure 2. Schematic pipeline of our symmetry-based text-line detection algorithm. (a) Input image; (b) Response map of the symmetry detector; (c) Symmetrical point grouping; (d) Estimated
bounding boxes based on the detected symmetrical axes. (e) Detection result after false alarm removal.
-
创新点和贡献
- idea出发点:人眼看图像中是否有文字,不需要逐字确认,甚至只需一瞥就可以确定,这是因为文字区域本身具有和背景不同的对称性和自相似性。也就是说,想确定文字区域,可以从通过两个角度出发,第一,不检测单个文字,而是检测整个文字串,利用整个串的整体信息;第二,寻找文字串本身的特性,对称性(上下)和自相似性(内部相同,但是和背景不同)

Figure 1. Though the sizes of the characters within the yellow rectangles are small, human can easily discover and localize such text lines.
-
- 创新点:
- 提出了针对文字串(character group)的对称性(symmetry)特征;
- 和传统方法不同,不通过检测字符,笔画来确定文字区域,而是检测文字串
- 创新点:
-
方法细节
1. Symmetry-based 文本线候选区域生成
-
- feature extraction
- Symmetry template
- (x,y)表示大矩形(4s*4s)的中心点
- 最小矩形大小为4s*s,包括RT,RMT,RMB,RB四个矩形
- 中间矩形为红色区域,大小为4s*2s,包括RM(由RMT,RMB两个矩形合成)
- Symmetry template
- feature extraction

Figure 3. Left: Template used to compute the features for symmetry axis detection, which consists of four rectangles with equal size. The height and the width of each rectangle are s and 4s, respectively. The scale of the template is determined by s. Right: The contents within the two middle rectangles are similar to each other but dissimilar to the contents of the top and bottom rectangles. Therefore, the symmetry response on the center line (the adjacent edge of the two middle rectangles) of the text region should be high.
-
-
- Symmetry feature
- 每个矩形的特征直方图定义如下,c表示某一种特征(直方图表示)
- Symmetry feature
-
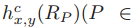

-
-
-
- c的含义(共5中特征)
- brightness-L*:LAB颜色空间中的L,32bin
- color-a* :LAB颜色空间中的a,32bin
- color-b* :LAB颜色空间中的b,32bin
- texture-T* :文献1中提取的纹理特征,?bin
- gradient-G* :梯度特征,16bin
- 三种直方图的对称性特征
- 文字区域的上半部和下半部的对称性:

- 文字区域的上半部与背景的差异:

- 文字区域的下半部与背景的差异:

- 文字区域的上半部和下半部的对称性:
- 总的symmetry feature的特征维度
- 5种cue*3种对称性= 15维
- c的含义(共5中特征)
- appearance feature: 采用文献2的LBP算法,取59个bin
- total feature calculation : 15维symmetry feature + 59维的appearance feature = 74维特征(注意特征是对每个中心点的特征)
-
-
-
- symmetry axis detection
-
-
- 分类器:random forest-50
- 样本:
- 正样本:距离groundTruth小于2个pixels的像素点,共45万个
- 负样本:距离groundTruth大于5个pixels的像素点,共45万个
- 训练尺度:
- 正样本:1种尺度,s等于groundTruth的bounding box的高度的一半
- 负样本:24种尺度,s= [2,256]
- 测试尺度:24种尺度,多种尺度进行非极大值抑制
- proposals generation
- group pixels into fragments
- 像素距离小于3的合并成fragments
- aggregate the fragments into text lines
- 把fragments聚成文本线,采用图模型的方法,每个fragment看成一个节点,每两个fragment的相似性看成边,找出每个连通子图即为每个文本线 两个fragment的相似性度量(A和B表示两个fragment,Φ表示每个fragment的角度)
- angular diference constraint:
- group pixels into fragments
-

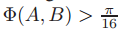
-
-
-
-
- distance constraint
-
-
-


2. 用CNN进行文本线噪声过滤
-
- 先用字符级CNN过滤,再用单词级CNN过滤(文中没有提到有关CNN的相关细节)
- 字符级样本:文献3的字符数据库
- 单词级样本:ICDAR2011,SVT, IIIT5K-word,PASCAL-VOC, BSD500的样本
- 文本线切分成单词的方法参考文献3
3. 多尺度进行检测

Figure 4. Procedure of text line proposal generation. (a) Input image. (b) Feature extraction at multiple scales. (c) Symmetry probability maps. (d) Axes sought in the symmetry probability maps. (e) Bounding box estimation. (f) Proposals from different scales
-
实验结果
- 实验速度:平均30s每张图(Matlab, 2.0GHz 8-core CPU, 64G RAM and Windows 64-bit OS)
- Symmetry和Appearance特征的实验效果

-
- ICDAR2011

-
- ICDAR2013

-
- SVT

-
- 其他语言的扩展

-
问题讨论
- 本方法的不足
- 速度慢
- 只能处理水平、近水平的文字
- 本方法的不足
-
总结与收获点
- 现在的文字检测方法越来越偏向于利用文字上下文信息检测文本,都喜欢一开始就检测文本块,文本行,而不再像原来一样先检测单个字符,因为这种方法确实更鲁棒
- 文字的对称性特征挺好的,从低级特征中提取,可以扩展到其他问题中,先mark
- 文中举出了一些文字检测的难点的案例,非常有代表性
- 对比度低:上图——(b), (i), 下图——(c)
- 笔画断裂:上图——(c)
- 光照影响:上图——(g), 下图——(a),(b)
- 点矩阵字:上图——(a),(j)
- 分辨率低:上图——(g)
- 字符相连:上图——(h)
- 单个字符:下图——(f)
- 字符大小差异很大:下图——(d)


-
参考文献
- D. R. Martin, C. Fowlkes, and J. Malik. Learning to detect natural image boundaries using local brightness, color, and texture cues. IEEE Trans. Pattern Anal. Mach. Intell., 26(5):530–549, 2004.
- T. Ojala, M. Pietik¨ainen, and T. M¨aenp¨a¨a. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell., 24(7):971–987, 2002.
- M. Jaderberg, A. Vedaldi, and A. Zisserman. Deep features for text spotting. In Proc. of ECCV, 2014.

