
论文阅读(Xiang Bai——【CVPR2012】Detecting Texts of Arbitrary Orientations in Natural Images)
Xiang Bai——【CVPR2012】Detecting Texts of Arbitrary Orientations in Natural Images
目录
- 作者和相关链接
- 方法概括
- 方法细节
- 创新点和贡献
- 实验结果
- 问题讨论
- 总结与收获点
-
作者和相关链接
-
- 华科:姚聪(Cong Yao),白翔(Xiang Bai),刘文予(Wenyu Liu)
- 微软MSRA:马毅(Yi Ma)
- UCLA(加州大学圣地亚哥分校):屠卓文(Zhuowen Tu)
- 文章中提到的MSRA-TD 500 数据库

-
方法概括
- 方法简述:
- 使用SWT提取候选区域,用字符级分类器(简单特征+随机森林)过滤非字符区域;
- 利用字符间相似性连接成字符串,再用字符串级的分类器(简单特征+随机森林)过滤非文字串。
- 方法流程图:
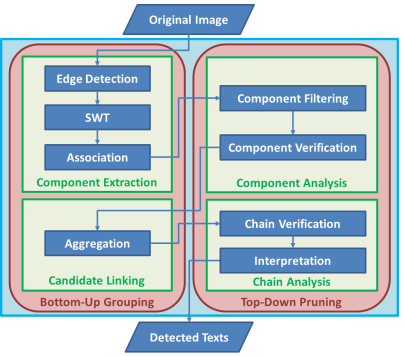
图1. 流程图
-
方法细节
-
- 提取候选字符区域
- canny边缘检测
- SWT
- 连通分量聚合(相邻笔画宽度小于3倍)
- 提取候选字符区域
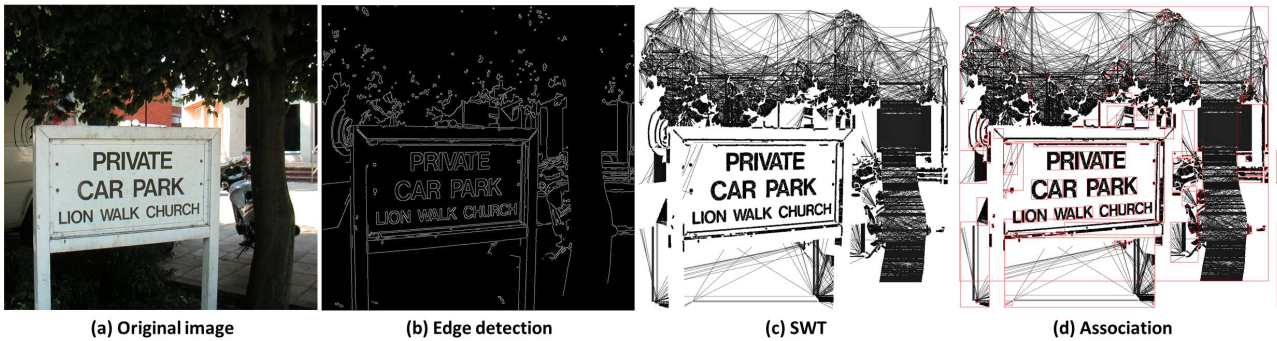
图2. 提取候选字符区域的三个步骤效果图
-
- 组件分析(组件级噪声过滤)
- 启发式规则过滤(特征:宽度方差,长宽比,占比;设定阈值范围)
- 组件分析(组件级噪声过滤)

-
-
- 组件级分类器过滤(特征:6种自己提的分量级特征;分类器:随机森林)
- 特征:轮廓形状,边缘形状,占比,轴比,宽度方差,密度
- 组件级分类器过滤(特征:6种自己提的分量级特征;分类器:随机森林)
-
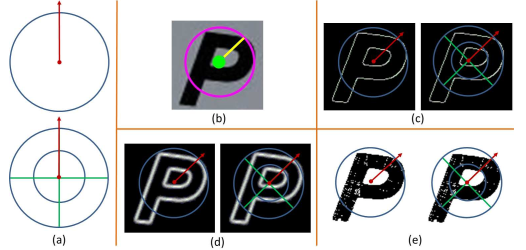
图3. 组件级特征计算,(a)为模板,(b)为模板叠加在原图的示例图,(c)、(d)、(e)分别用来计算轮廓形状特征,边缘形状特征,占比特征
- 如上图所示,(a)为两种模板。上面是只有一种半径,一个扇形区域(整个圆),下面是有两种半径,共八个扇形区域(4个小的,4个大的)。每个扇形区域单独计算直方图(边缘,轮廓,占比),然后把每个区域的直方图串起来作为整个图的特征。(b)为在一个原图上叠加一种模板的示例图。(c)图为轮廓图上叠加两种模板的示例图。(d)为边缘图上叠加两种模板的示例图。(e)为二值图上叠加模板的示例图。
- 实际计算特征(比如,边缘特征)的时候,第一,先利用Camshift计算出每个连通分量的质心,尺度(最大轴与最小轴的和),方向(角度);第二,各种梯度方向都按照第一步求出的方向进行旋转(为了和模板对齐),并归一到[0,Π]上;第三,将模板中心固定在质心上,模板半径为尺度的大小,统计模板上每个sector的(轮廓形状,边缘形状,占比)直方图,并把每个sector的直方图串起来形成特征向量。


图4. 组件级噪声过滤(组件分析)的效果,(e)图为规则过滤,(f)为分类器过滤,经过两层过滤后大部分非文字的组件都被过滤掉了
-
- 候选区域连接
- 两两组队pair(相似性度量:笔画宽度,大小,颜色,距离;设定阈值范围)
- 聚类
- 至少包含一个公共组件
- 相似性度量:方向一致,群体一致(组件个数差异小)
- 候选区域连接
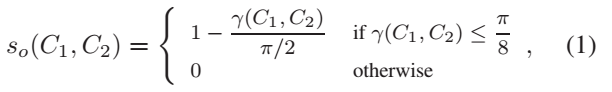
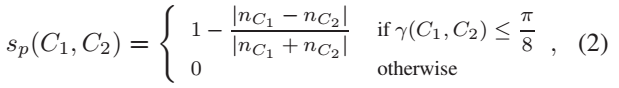
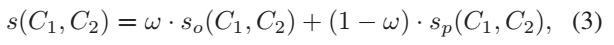
-
-
-
-
- 公式(1)中的So表示的是方向一致性,C1和C2是两个不同的chain,初始每个chain就是由两个相似组件得到的一个pair,γ(C1,C2)表示的是C1和C2之间的夹角(每条chain利用线性最小二乘法拟合出一条直线。两个chain的夹角就表示这两条直线间的夹角)。So是保证要聚类的两个chain的方向尽可能一致。
- 公式(2)中的Sp表示的是群体一致性,nC1是C1中组件的个数。Sp是保证要聚类的两个chain的个数差异不要太大。
- 公式(3)中的S是总的相似性度量的标准,是So和Sp的加权求和。每次要聚类时都是选择使得S最大的两个chain进行合并,这样采用自底向上进行合并的方式可以适用于任意方向,而不单纯是水*(或*似水*),甚至可以处理竖直,斜线的,更重要一点是,把在阈值范围内可能形成直线的组合都找的出来。如图5所示。
-
-
-

图5. 候选区域连接的效果,不但找到了PRIVATE,CAR等水*的,还找出了PCO,PRL这样的潜在的组合
-
- 链分析(链级噪声过滤)
- 链级特征:11种特征
- 链中候选区域个数
- *均概率(组件级分类器打分)
- *均转角(每个组件与左右相邻组件形成的直线的夹角)
- 大小方差(每个组件的尺度)
- 距离方差(质心的欧氏距离)
- *均角度偏差(每个组件的最大轴方向与拟合出的链的直线方向的垂直方向间的角度偏差)
- *均轴比
- *均密度
- *均宽度方差
- *均颜色自相似性(颜色直方图的cosine相似性)
- *均结构自相似性(边缘形状描述子的cosine相似性)
- 分类器:随机森林
- 链级特征:11种特征
- 新的数据库和评价标准
- MSRA-TD数据库
- 样本数:train-300,test-200
- 语言:中文,英文,中英混合
- 标注粒度:文本线(无字符,单词级标注)
- 图像大小:1296*864~1920*1280
- 标注矩形类别:最小面积矩形(mini area rectangle)
- 评价标准:
- 链分析(链级噪声过滤)

-
-
-
- 上图中(c)所示,G和D分别为groundTruth和detection的bounding box。由于两个都是斜的,直接计算交并比意义不大,故先求出两个box的角度(相对于水*方向的旋转角度),并将其转至水*,如图中的虚线图G'和D',再通过计算G'和D'的交并比来判断。
- 检测正确的标准是:(1) G和D的旋转角度差的绝对值小于Π/8;(2)G'和D'的交并比大于0.5;
-
-
-
创新点和贡献
- 解决的问题角度新:从一般的水*或*水*文字检测到任意方向的文字检测(直线)
- 提出了两级分类机制,尤其是其中的字符特征:组件级特征与链级特征
- 介绍了专门用来检测任意方向的文字的新的MSRA-TD数据库:针对任意方向的文字检测的数据库,切提出了新的评价标准
-
实验结果
- ICDAR03, detection:

-
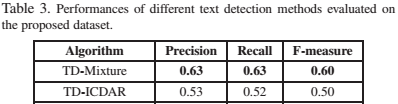
- MSRA-TD, detection:
-
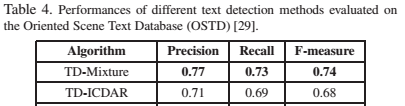
- OSTD:
-
问题讨论
- 为什么文中的方法可以用来检测各种方向的文字?
- 特征的旋转不变性,尺度不变性;
- 字符链形成算法比较通用,适用于各种方向,不一定是水*或者竖直。
- 组件级分类器正样本怎么获得?(MSRA-TD库上只有链级的标注)
- 链级分类器的正样本怎么获得?(ICDAR03库上最多只有单词级标注,没有包含多个单词的链级样本,是否采用简单规则先把groundTruth进行合并?)
- mini area rectangle的原理?(如何从四个点得到一个包含这四个点的最小面积矩形?)
- 长轴和短轴指的是字符的竖直和水*?(不是对角线?)
- 如何用Camshift得到质心,方向,和长短轴?
- 为什么文中的方法可以用来检测各种方向的文字?
-
总结与收获点
- 这篇做文字检测的方法思路很传统,从字符到字符串,然后给字符和字符串分别用一个分类器过滤噪声。比较有用的有三点,第一,整理的这些字符特征都是人工,经验得到的,简单有效;第二,字符链的形成算法有一定借鉴意义;第三,新的数据库和评价标准成为了后来检测多方向的主流。

