
论文速读(Chuhui Xue——【arxiv2019】MSR_Multi-Scale Shape Regression for Scene Text Detection)
Chuhui Xue——【arxiv2019】MSR_Multi-Scale Shape Regression for Scene Text Detection
论文
Chuhui Xue——【arxiv2019】MSR_Multi-Scale Shape Regression for Scene Text Detection
作者
Chuhui Xue, Shijian Lu, Wei Zhang
亮点
- multi-scale网络中利用FPN的up-sampling把多个不同scale得到的结果进行融合(concat + uppooling)
- boundary-point regression部分直接预测点与最近的boundary point的dx和dy,思路清晰且易实现
方法概述
针对任意文字检测(水平、倾斜、曲文),通过网络来regress文字的边界像素点来得到text region。
整个检测的流程包括:
- 特征提取:通过一个类似于Image Pyramid的多通道多尺度网络来提取不同scale的图像特征(FPN框架)
- 目标预测:预测包括三个分支
- text region的classification分支
- 与nearest boundary point之间的x的dis
- 与nearest boundary point之间的y的dis
- 结果输出:利用Alpha-Shape Algorithm从boundary point set中的得到外边界凸多边形
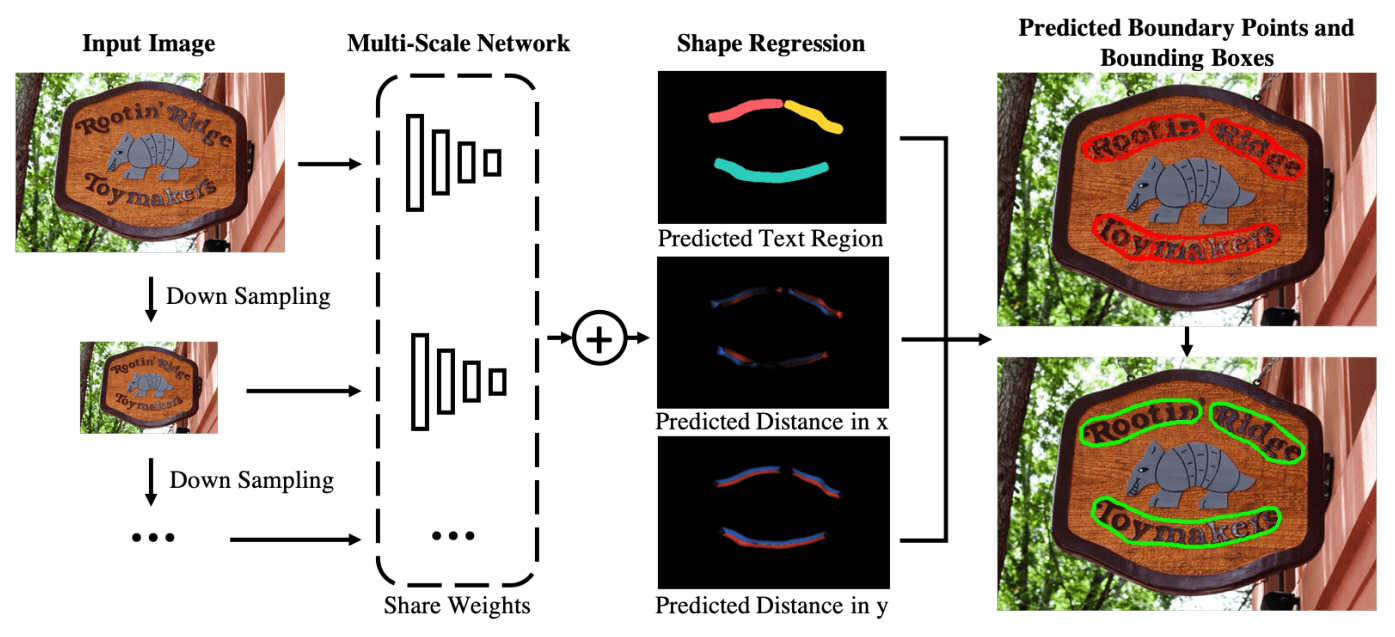
Fig. 1: Scene text detection using the proposed multi-scale shape regression network (MSR): For scene texts with arbitrary orientations and shapes in (a), MSR first predicts dense text boundary points (in red color) as shown in (b) and then locates texts by a polygon (in green color) that encloses all boundary points of each text instance as shown in (c).
方法细节
- Multi-scale Network
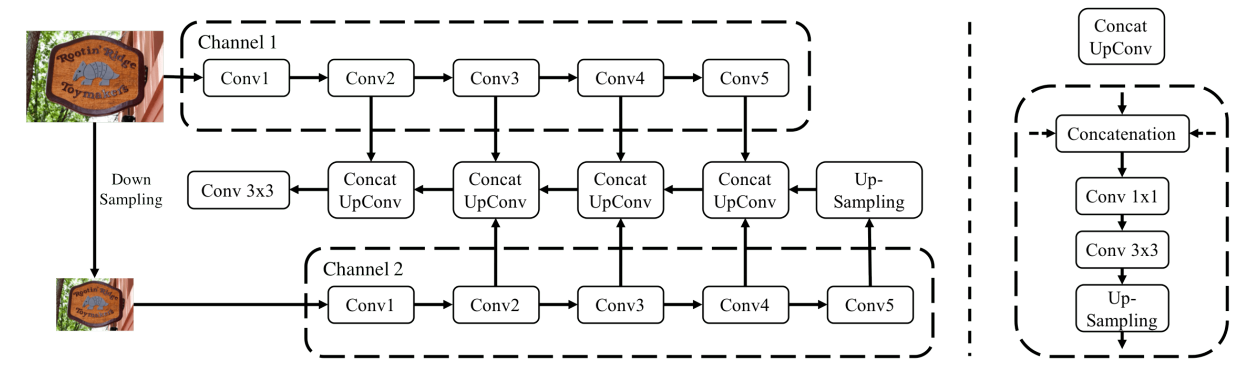
Fig. 3: Structure of proposed multi-scale network (for two-scale case): Features extracted from layers Conv2 - Conv5 of two network channels are fused, where features of the same scale are fused by a Concat UpConv as illustrated and features from the deepest layer of the lower-scale channel are up-sampled to the scale of the previous layer for fusion.
- Alpha-Shape Algorithm
- 参考文献:N. Akkiraju, H. Edelsbrunner, M. Facello, P. Fu, E. Mucke, and C. Varela, “Alpha shapes: definition and software,” in Proceedings of the 1st International Computational Geometry Software Workshop, vol. 63, 1995, p. 66.
- groundTruth生成
- 用Triangle算法将多边形转为多个三角形
- 取三角形两侧边的1/4点处,把下图b中的绿色点依次连接起来,得到一个shrink的text region(下图c中的蓝色区域)
- 求text region中每个点的最近的boundary point,并计算与该boundary point的x的offset,y的offset,得到两个distance_x_map(e)和distance_y_map(f)

Fig. 4: Illustration of ground-truth generation: Given a text annotation polygon in (a), triangulation is performed over the polygon vertices to locate the vertices (green points in (b)) of the central text region in blue color in (c). For each centraltext-region pixel tp (in blue color in (d)), the nearest point on the text annotation box b p in yellow color is determined as the nearest text boundary point as shown in (d), and the distance between t p and bp is used to generate ground-truth distance maps as shown in (e) and (f)
-
损失函数
-
点分类(Dice coefficient)
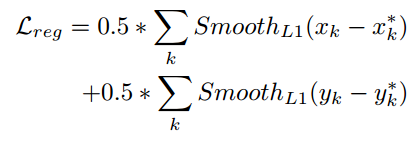
-
最近boundary point的dx、dy回归(Smooth_L1)
-
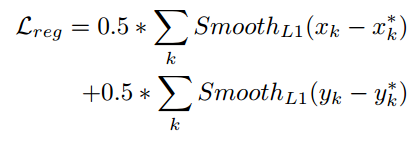
- 总的
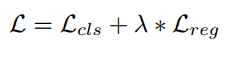
实验结果
-
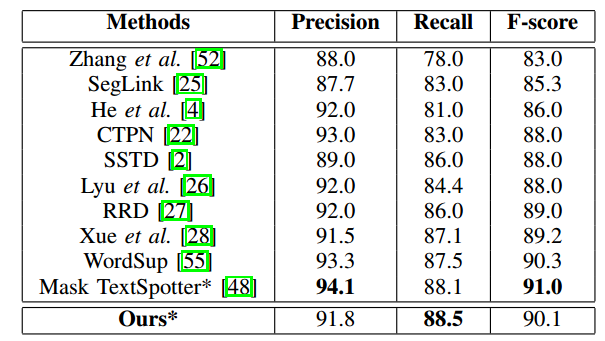
ICDAR13
-
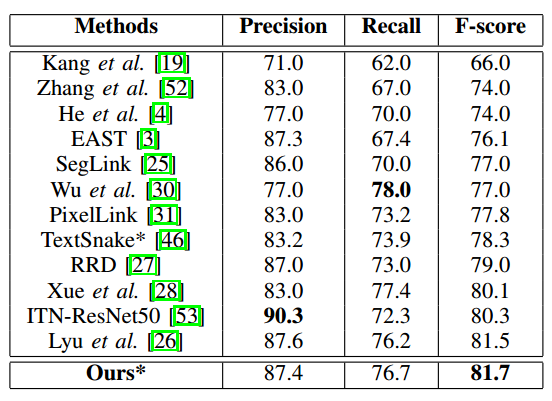
MSRA-TD500
-
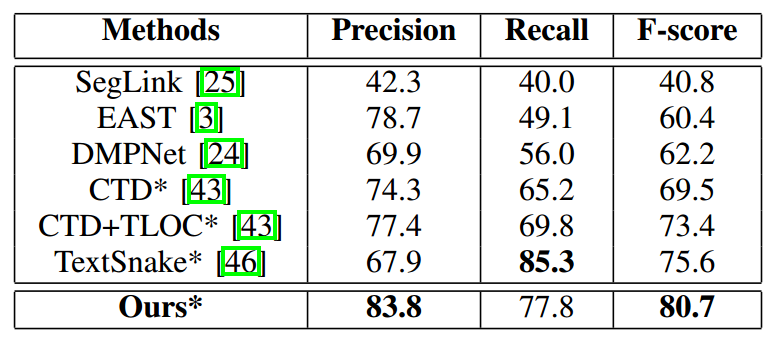
CTW1500
-
Total-Text
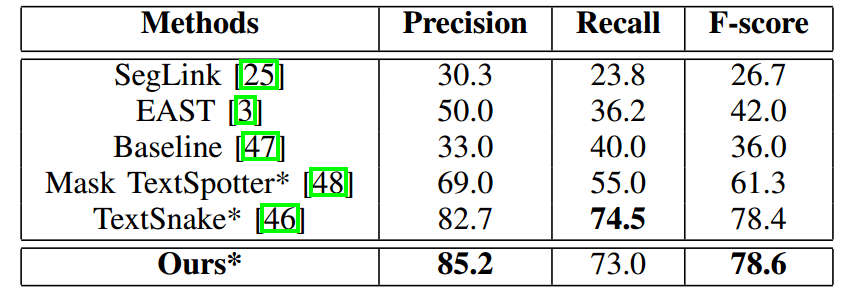
- Ablation experiments on CTW1500
- Baseline-EAST
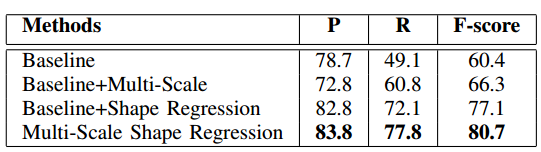
- Baseline-EAST
疑问问题
- 存在部分regress错误的outlier点,怎么消除?
- 最后的prediction只利用了class_score_map(score > threshold)的点 + dx、dy,得到的regression boundary point map来算凸多边形,没有利用class_score_map图本身信息?(结合这个是不是效果会更好?)
- 三角化用的是什么算法?
收获点与问题
- 用embedding来学习字符间的关系还是比较新的一个出发点。整个方法还是传统方法字底向上的思路,多步骤而且速度应该比较慢。整体感觉偏engineering,实验上标明也是一些比较工程上的trick对实验结果提升较明显

