
Hbase问题小结(一)
1. Hbase读写优化
- 写:
批量写、异步批量提交、多线程并发写、使用BulkLoad写入、表优化(压缩算法、预分区、合理的rowkey设计、合理关闭WAL或异步WAL)
SKIP_WAL:只写缓存,不写HLog日志。这种方式因为只写内存,因此可以极大的提升写入性能,但是数据有丢失的风险。在实际应用过程中并不建议设置此等级,除非确认不要求数据的可靠性。
ASYNC_WAL:异步将数据写入HLog日志中。
SYNC_WAL:同步将数据写入日志文件中,需要注意的是数据只是被写入文件系统中,并没有真正落盘,默认。
FSYNC_WAL:同步将数据写入日志文件并强制落盘。最严格的日志写入等级,可以保证数据不会丢失,但是性能相对比较差。
- 读:
批量get请求、合理设置scan缓存大小、指定请求列族或者列名、设置只读Rowkey过滤器、关闭ResultScanner、表优化(配置表的优先缓存、Block大小、数据编码、压缩方式)
2. bulkload入库的hfile是否有限制,可以怎么调整参数
hbase.hregion.max.filesize:默认配置:10737418240(10G)
最大文件大小。
如果一个区域的HFiles的大小之和超过了这个值,那么该区域将被一分为二。
该选项的工作方式有两种选择,
第一种是当任何store的大小超过阈值时,然后分割,
另一种是整个区域的大小超过阈值,然后分割,它可以通过hbase.hregion.split.overallfiles进行配置。
hbase.hregion.split.overallfiles: Default true
当检查到分裂时,我们是否应该合计整个区域的文件大小。
hbase.mapreduce.bulkload.max.hfiles.perRegion.perFamily:默认配置:100
允许的hfile的最大个数,但是在bulkload中默认为32,可以调整这个参数进行修改
3. rowkey设计原则
- Rowkey的唯一原则
- Rowkey的排序原则:HBase的Rowkey是按照ASCII有序设计的
- Rowkey的散列原则:Rowkey应均匀的分布在各个HBase节点上(Region热点)
解决热点问题:
Reverse反转:(典型:手机号码);
Salt加盐:将每一个Rowkey加一个前缀,前缀使用一些随机字符,使得数据分散在多个不同的Region,达到Region负载均衡的目标。前缀是随机的,读这些数据时需要耗费更多的时间,所以Salt增加了写操作的吞吐量,不过缺点是同时增加了读操作的开销。(当然这个缺点在很多情况下也是可以解决的,比如根据rowkey计算固定的Salt);
Hash散列或者Mod:用Hash散列来替代随机Salt前缀的好处是能让一个给定的行有相同的前缀;
- Rowkey的长度原则:建议是越短越好,
其一是HBase的持久化文件HFile是按照KeyValue存储的,
如果Rowkey过长,在大数据量情况下Rowkey本身就要占据大量空间,会极大影响HFile的存储效率。
二是MemStore缓存部分数据到内存,
如果Rowkey字段过长内存的有效利用率会降低,系统无法缓存更多的数据,这会降低检索效率。
4. 简单介绍Compaction
HBase是基于一种LSM-Tree(Log-Structured Merge Tree)存储模型设计的,写入过程如下
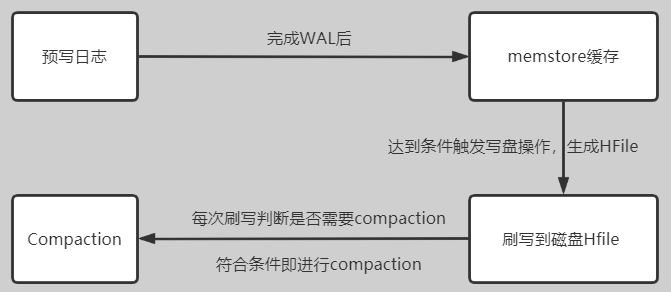
- Compaction作用:Compaction操作属于资源密集型操作特别是IO密集型操作,以短时间内的IO消耗,以换取相对稳定的读取性能。
- 分类:Minor Compaction 与 Major Compaction,通常我们简称为小合并、大合并
| 类型 | 作用 | 删除的内容 |
|---|---|---|
| Minor Compaction | 选取一些小的、相邻的HFile将合并成一个大的HFile | 1. 默认删除选取HFile中的TTL过期数据 |
| Major Compaction | 将一个Store中所有的HFile合并成一个HFile | 1.被删除的数据(打了Delete标记的数据) 2.TTL过期数据 3.版本号超过设定版本号的数据 |
- 触发条件:
| 触发条件 | header 2 |
|---|---|
| memstore flush | compaction的根源就在于flush, memstore达到一定条件就会触发flush生成HFile, compact的根本目的是控制HFile的数量。 所以每次flush之后,都会判断是否要进行compaction |
| 后台线程周期性检查 | 后台线程 CompactionChecker 会定期检查是否需要执行compactionhbase.server.thread.wakefrequency * hbase.server.compactchecker.interval.multiplier |
| 手动触发 | HBase Shell、Master UI界面或者HBase API |
- 相关参数
| header 1 | header 2 |
|---|---|
hbase.hregion.majorcompaction |
Major compaction周期性时间间隔,默认值604800000,单位ms major compaction耗时、耗资源,一般禁用 |
hbase.hregion.majorcompaction.jitter |
抖动参数,默认值0.5 避免major compaction同时在各个regionserver上同时发生 major compaction就会在 +\- 两者乘积的时间范围内随机发生 |
hbase.hstore.compaction.min |
一次minor compaction最少合并的HFile数量,默认值 3 |
hbase.hstore.compaction.max |
一次minor compaction最多合并的HFile数量,默认值 10 |
hbase.hstore.compaction.min.size |
filesize < 该参数值的为适合进行minor compaction文件, 默认值 128M(memstore flush size) |
hbase.hstore.compaction.max.size |
filesize > 该参数值的不会加入minor compaction 默认值Long.MAX_VALUE,表示没有什么限制 |
hbase.hstore.compaction.ratio |
判断filesize > hbase.hstore.compaction.min.size的HFile是否也是适合进行minor compaction,默认值1.2。 |
hbase.hstore.compaction.ratio.offpeak |
在非高峰时段是包含更大的StoreFiles压缩比例 默认5.0,需要配合 hbase.offpeak.start.hour hbase.offpeak.end.hour使用 |
hbase.regionserver.thread.compaction.throttle |
compaction线程的选择,默认2.5G(按官网应该是1.25G) 如果compaction大于此阈值,则将其放入largeCompactions, 否则放入smallCompaction hbase.hstore.compaction.max * hbase.hregion.memstore.flush.size |
hbase.regionserver.thread.compaction.largehbase.regionserver.thread.compaction.small |
largeCompactions与smallCompactions的线程池大小 |
hbase.hstore.blockingStoreFiles |
每次刷新MemStore都会写入一个StoreFile 在任何一个Store中存在超过这个数量的StoreFile, 该region的更新就会被阻塞,直到compaction完成, 或者超过 hbase.hstore.blockingWaitTime。默认:16 |
hbase.hstore.blockingWaitTime |
在达到hbase.hstore.blockingStoreFiles定义的StoreFile限制后, 该region将阻塞更新一段时间。 在这段时间过后,即使compaction没有完成,该region也将停止阻塞更新。 默认9000,15min |
- Compaction 线程池
HBase RegionServer内部专门有一个 CompactSplitThead,
用于维护执行minor compaction、major compaction、split、merge操作线程池。
其中compaction操作有关的线程池称为largeCompactions与smallCompactions,分别用于处理大规模compaction、小规模compaction。默认大小为均为1。
这里的minor compaction、major compaction与largeCompactions、smallCompactions并不是对应的。参考上面参数说明
- Compaction 对读写请求的影响
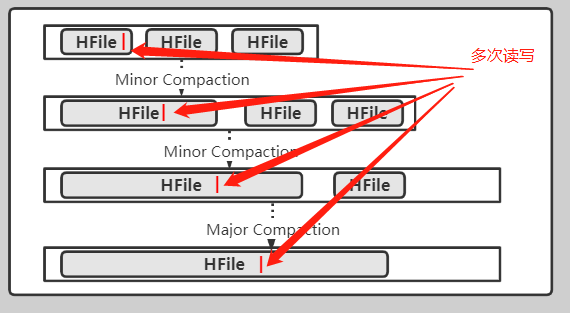
存储上的写入放大,特别是在写多读少的场景下,写入放大就会比较明显,
随着minor compaction以及major Compaction的发生,某些数据会被反复读写多次
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号