
大数据系列4:Yarn以及MapReduce 2
系列文章:
大数据系列:一文初识Hdfs
大数据系列2:Hdfs的读写操作
大数据谢列3:Hdfs的HA实现
通过前文,我们对Hdfs的已经有了一定的了解,本文将继续之前的内容,介绍Yarn与Yarn在MapReduce 2的应用
MapReduce1 作业流程
在介绍Yarn之前,我们先介绍一下Mapreduce1作业流程。
有了这个基础,再去看看采用Yarn以后的MapReduce2到底有啥优势也许会有更好的理解。
首先先介绍一下相关的几个实体:
Client:负责提交MapReduce作业jobtracker:协调作业运行,是一个Jave程序,主类为JobTrackertasktracker:运行作业划分后的任务,是一个Jave程序,主类为TaskTrackerHdfs:分布式文件系统,用于在其他实体之间共享作业文件
作业流程图如下:
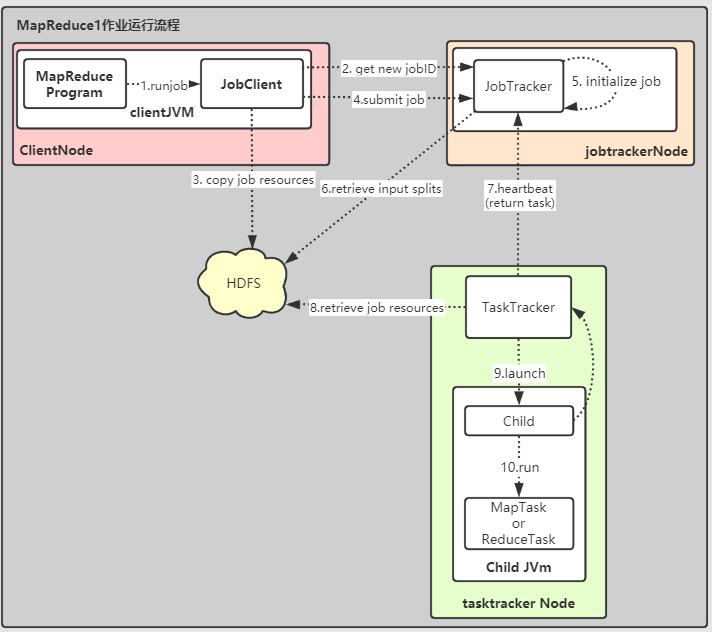
-
MapReduce Program调用runJob()创建JobClient并告知其提交作业。
在提交作业后runJob()会每秒轮询作业进度,如果发生改变就把进度输出控制台。
作业成后输出作业计数器,如果失败,则输出失败信息。 -
JobClient通过调用JobTracker.getNewJobId()请求一个新的JoobId。 -
将运行作业需要的资源(作业
Jar文件,配置文件,计算所得的输入分片)复制到以JobId命名的目录下jobtracker的HDFS中。
作业Jar的会有多个副本(mapred.submit.replication默认10),在运行作业的时候,tasktracker可以访问多个副本。 -
调用
JobTracker.submitJob()方法告知jobtracker作业准备执行。 -
JobTracker接收到对submitJob()的调用后,会把改调用放入一个内部队列,交由作业调度器(job scheduler)进行调度。
同时会对Job初始化,包括创建一个表示Job正在运行的对象,用来封装任务和记录的信息,用于追踪任务的状态和进程。 -
为了创建人物运行列表,作业调度器会从共享文件系统中获取
JobCient已经计算好的输入分片信息。
然后为每一个分片创建一个map任务。
至于reduce任务则由JonConf的mapred.reduce.task决定,通过setNumReduceTask()设置,
然后调度器创建相应数量的reduce任务。
此时会被指定任务ID -
tasktracker与jobtracker之间维持一个心跳,
作为消息通道,tasktracker或告知自身存活情况与是否可以运行新的任务。
根据信息,jobtracker会决定是否为tasktracker分配任务(通过调度算法)。
这个过程中,对于map任务会考虑数据本地性,对于reduce则不需要。 -
一旦
tasktracker被分配了任务,接下里就是执行,首先通过Hdfs把作业的Jar文件复制到tasktracker所在的文件系统。
实现作业Jar本地化。
同时,tasktracker把需要的文件从Hdfs复制到本地磁盘。
然后为任务建立一个本地工作目录,并将Jar中的内容解压到这里。
最后创建一个TaskRunner实例运行该任务。 -
TaskerRunner启动一个新的JVM用来运行每一个任务。 -
分别执行
MapTask或者ReduceTask,结束后告知TaskTracker结束信息,同时TaskTracker将该信息告知JobTracker
上面就是Maopreduce1作业运行的流程。我们先有个概念,后面介绍Yarn的时候做下对比。
这里说的
Mapreduce1指的是Hadoop初始版本(版本1以及更早的)中的Mapreduce分布式执行框架,也就是我们上面的作业流程。
Mapreduce2指的是使用Yarn(Hadoop 2以及以后版本)的Mapreduce执行方式。
这里Mapreduce1、Mapreduce2指的不是Hadoop版本,指的是Mapreduce程序的不同执行机制而已。
Yarn
Yarn (Yet Another Resource Negotiator)是在Hadoop 2引入的集群资源管理系统,最初的目的是为了改善MapReduce的实现。
但是由于其具有强大的通用性,可以支持其他的分布式计算框架。
在引入的Yarn后,Hadoop 2的生态就发生了一变化,如下:

Yarn提供请求和使用集群资源的API,但是一般都是由分布式框架(Saprk、Flink等)内部调用这些API,
用户则使用分布式系统提供的更高层的API。
这种方式向用户隐藏了资源管理的细节,一定程度上降低了开发难度和运维成本。
Yarn的结构很简单,如下
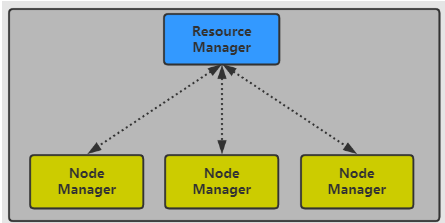
Yarn的核心思想是将资源管理和作业调度/监视功能拆分为单独的守护进程。
具体实现就是:
一个管理集群上资源使用的全局资源管理器(RM,ResourceManager);
运行在集群所有结点上并且能够启动和监控容器(Container)的结点管理器(Node Manager)
Container是用于执行特定应用程序的进程,每个资源都有资源限制(内存、CPU等)
Container可以是Unix进程,也可以Linux cgroup
Yarn的组成介绍就这么简单,接下来我们就看看它怎么提交执行一个任务。
提交任务
这里分为两部分,
第一部分会介绍Yarn任务提交流程,
第二部分会介绍Mapreduce 2 的提交流程
Yarn任务提交流程
Yarn 任务的提交流程如下:

-
为了在
Yarn上运行任务,Client会向ResourceManager发出运行Application Master process的请求。 -
Resource Manager找到一个可以运行Application Master的NodeManager。 -
NodeMager启动一个容器,运行Application Master。 -
此
时Application Master会做什么操作取决于Application本身,
可以是在在Application Master执行一个简单计算任务,将结果返回Client,
也可以向Resource Manager申请更多容器。 -
申请到更多的
container。
从上面的步骤可以发现,Yarn本身是不会为应用的各个部分(Client, Master, Process)之间提供交互。
大多数基于Yarn的任务使用某些远程通信机制(比如Hadoop RPC)向客户端传递信息。
这些RPC通信机制一般都是专属于该应用的。
MapReduce 2 任务提交流程
有了上面的基础,具体的应用怎么提交。
此处选用MapReduce 2,与一开始MapReduce 1做个对比
涉及到五个实体:
Client:提交MapReduce job的客户端YARN Resource Manager:负责协调分配集群计算资源YARN Node Managers:启动并监视集群中机器上的计算容器。MapReduce Application Master:协调MapReduce job的任务执行。HDFS:用于在其他实体之间共享Job文件
Application Master和MapReduce Tasks在容器中运行,他们由Resource Manager调度,由Node Managers管理
提交流程如下:
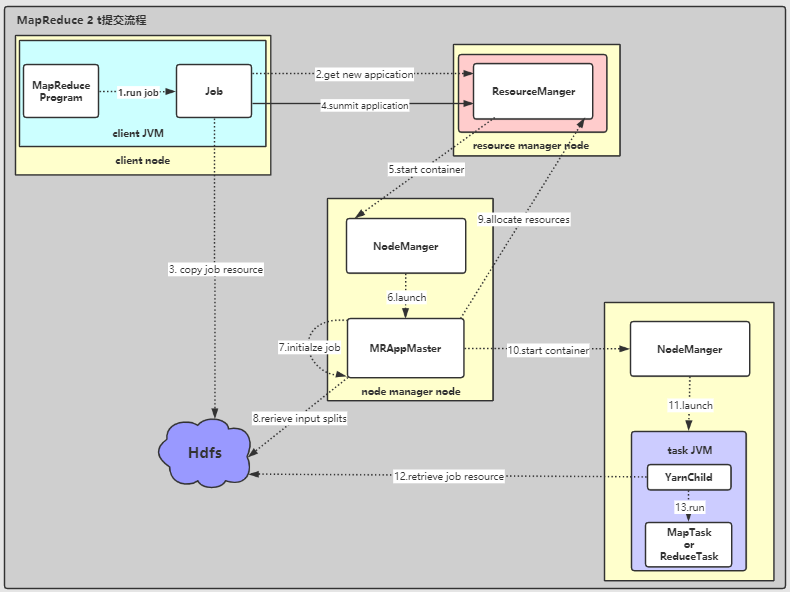
-
Job.sumbit()方法创建一个内部的JobSummiter实例,并调用其sunbmitJobInternal()方法。
作业提交后,waitForCompletion()会每秒轮询返回作业的进度。
如果作业完成后,如果成功则显示作业计数器,否则输出错误。 -
JobSummiter向Resource Manager申请一个用于MapReduce job ID的新Application ID。
这个过程会检查作业,输出说明:
例如,如果没有指定输出目录,或者输出目录已经存在,则不会提交作业,并向MapReduce程序抛出错误;
计算作业的输入分片。
如果无法计算分片(例如,因为输入路径不存在),则作业不提交,并向MapReduce程序抛出错误。 -
将运行作业需要的资源(作业
Jar文件,配置文件,计算所得的输入分片)复制到以JobId命名的HDFS的目录下。
作业Jar的会有多个副本(mapreduce.client.submit.file.replication默认10),
当Node Managers运行任务时,可以跨集群访问许多副本。 -
通过调用
Resource Manager的submitApplication()提交任务。 -
Resource Manager收到submitApplication()的调用请求后,将请求传递给Yarn的调度器(Scheduler)。
Scheduler会为其分配一个容器, -
Node Manager在容器中启动一个Application Master,主类为MRAppMaster。 -
由于
MRAppMaster将从任务接收进度和完成报告,它通过创建许多簿记对象(bookkeeping objects)来初始化作业,以跟踪作业的进度。 -
接下来,
MRAppMaster从共享文件系统检索在客户机中计算的输入切片,
它会为每个切片建立一个map task;
建立mapreduce.job.reduces(由Job.setNumReduceTasks())数量的reduce task。
MRAppMaster根据任务的情况决定是执行一个uber task还是向Resource Manager请求更多的资源。 -
MRAppMaster向Resource Manager为job中所有的map、reduce tasks申请容器。 -
一旦
Resource Manager的Scheduler为task在指定的Node Manager分配了容器以后,Application Master就会请求Node Manager分配容器。 -
Node Manager收到请,启动容器。容器中的主类为YarnChild,运行在专用的JVM中,所以map、reduce、甚至YarnChild本身出现的错误都不会影响Node Manager。 -
在运行
task之前,YarnChild会对任务需要的资源进行本地化,包括job配置、JAR文件以及其他来自Hdfs的文件。 -
最后执行
map 或 reduce任务。
关于的ubertask细节说明:
MRAppMaster必须决定如何运行MapReduce job。
利用并行的优势,确实可以提高任务的执行效率,
但是在小任务或少任务的情况下,
在新的容器中分配和运行任务所额外消耗的时间大于并行执行带来效率的提升。
这个时候在一个节点上顺序运行这些任务反而能获得更好的效率。
这样的job被称为uber task
简单的说就是并行执行的时候任务效率的提升还不够弥补你重新申请资源、创建容器、分发任务等消耗的时间。
那么怎样才算small job呢?
默认情况下:small job是有少于10个mapper,只有一个reducer,一个输入大小小于一个HDFS Block大小的job。
当然也可以通过参数 mapreduce.job.ubertask.maxmaps ,mapreduce.job.ubertask.maxreduces , mapreduce.job.ubertask.maxbytes 进行设置。
对于Ubertasks,mapreduce.job.ubertask.enable必须设置为true。
对于步骤9补充说明:
在这个过程中,会先申请map任务的容器,
因为所有的map任务都必须在reduce的排序阶段开始之前完成(Shuffle and Sort机制)。
对reduce任务的请求直到5%的map任务完成才会发出(reduce slow start机制)。
对于reduce任务,可以在集群的任何结点运行,
但是对map任务,会有数据本地性的要求(详情此处不展开)
申请还为任务指定内存和cpu。默认情况下,每个map和reduce任务分配1024 MB内存和1个虚拟核,
可以通过mapreduce.map.memory.mb , mapreduce.reduce.memory.mb , mapreduce.map.cpu.vcores和 mapreduce.reduce.cpu.vcores进行配置
Yarn 与mapreduce 1
上面就是Mapreduce2的任务提交执行流程,一开始我们就介绍了Mapreduce1,现在我们对比下两个有啥区别。
本质就是结合
Mapreduce 2对比Yarn与Mapreduce1调度的区别,所以后面Mapreduce 2直接用Yarn替换
Mapreduce 1 中,作业执行过程由两类守护进程控制,分别为一个jobtracker和多个tasktracker。
jobtracker 通过调度tasktracker上的任务来协调运行在系统的Job,并记录返回的任务进度。
tasktracker负责运行任务并向`jobtracker``发送任务进度。
jobtracker同时负责作业的调度(分配任务与tasktracker匹配)和任务进度监控(任务跟踪、失败重启、记录流水、维护进度、计数器等)
Yarn 中,也有两类守护进程Resource Manager 和Nonde Manager分别类比jobtracker和tasktracker。
但是不一样的地方在于,jobtracker的职责在Yarn中被拆分,由两个实体Reource Manger 和``Application Master```(每个Job有一个)。
jobtracker 也可以存储作业历史,或者通过运行一个独立守护进程作为历史作业服务器。而与对应的,Yarn提供一个时间轴服务器(timeline server)来存储应用的历史。
二者组成类比
| Mapreduce 1 | Yarn |
|---|---|
jobtracker |
Reource MangerApplication Mastertimeline server |
tasktracker |
Nonde Manager |
Slot |
container |
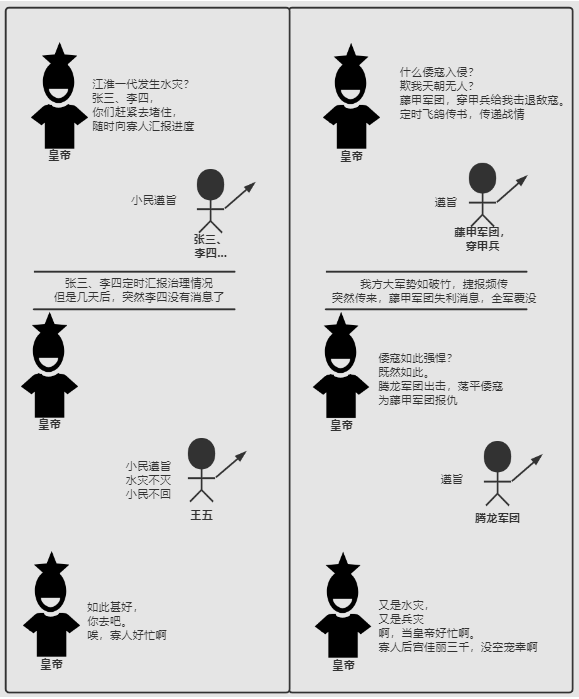
对于二者的区别,心血来潮想了个例子,希望能够帮助理解。
有三个角色:皇帝、大臣、打工人

现在有两个情况,
1:发生水灾,需要赈灾
2:敌寇入侵,边疆告急
在这种情况下 Mapreduce 1 的做法是:
Yarn的做法:
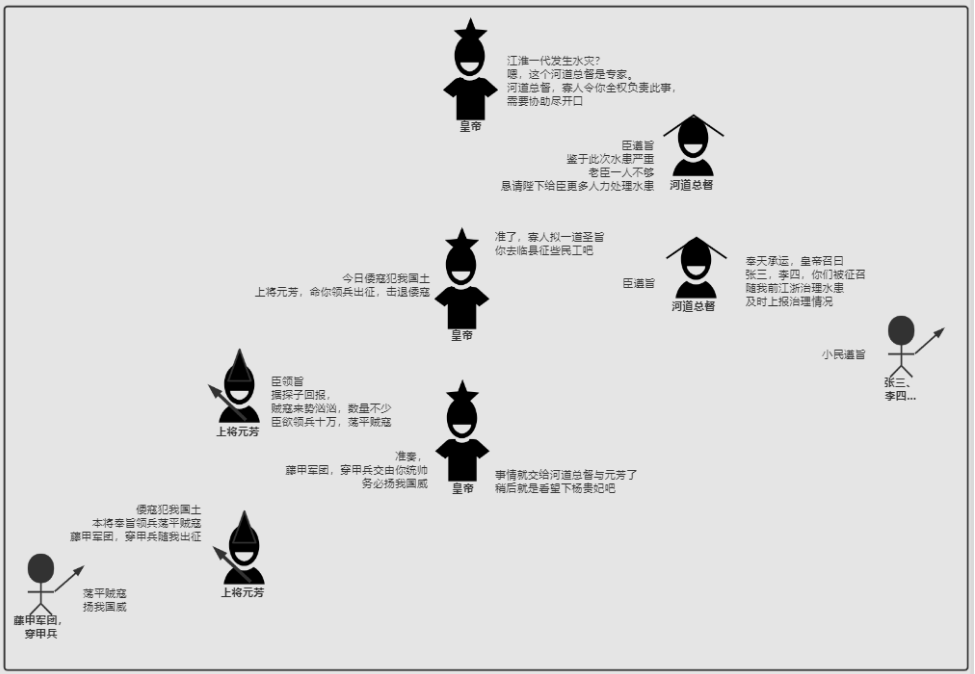
简单的说,就是Yarn让专业的人做专业的事情。
遇到事情找个专家,我只负责提需求和提供资源,
其他的让专家去做。
这个专家就是
MRAppMaster(Mapreduce),而对应的Spark也有自己的专家
由此也总结下Yarn带来的优势:
- 可拓展性(
Scalability)
Yarn可以在比MapReduce 1更大的集群上运行。
MapReduce 1在4000个节点和40000个任务的时候达到拓展性的瓶颈。
主要是因为jobtracker需要管理作业和任务。
Yarn就拆分了这个,将作业与任务拆分,由Manager/Application Master分别负责,可以轻松将拓展至10,000 个节点 100,000 个任务。 - 可用性(
Availability)
高可用性(HA)通常是通过复制另一个守护进程所需的状态来实现的,以便在活跃状态的守护进程挂掉时接管提供服务所需的工作。
但是,jobtracker的内存中有大量快速变化的复杂状态(例如,每个任务状态每隔几秒更新一次),这使得将在jobtracker服务配置HA非常困难。
而对于Yarn而言,由于职责被拆分,那么HA也随之变成了分治问题。
可以先提供Resource Manager的HA,同时如果有需要可以为每个人应用也提供HA。
实际上对于
Mapreduce 2对Resource Manager和Application Master都提供了HA,稍候介绍。
- 利用率(
Utilization)
MapReduce 1中,每个tasktracker都静态配置若干个slot,在配置的时候被划分为map slot和reduce slot,只能执行固定的任务。
而在Yarn中,Node Manager管理一个资源池,只要有资源,任务就可以运行。
同时资源是精细化管理的,任务可以按需申请资源。 - 多租户(
Multitenancy)
其实,某种程度上来说,统一的资源管理,向其他分布式应用开放Hadoop才是Yarn的最大优势。
比如我们可以部署Spark、Flink等等。此时MapReduce也仅仅是在这之上的一个应用罢了
High Availability
接下来再说一下HA吧。
这里主要结合Mapreduce 2 来说明
HA 针对的都是出现错误或失败的情况。
在我们这里,出现错误或失败的场景有以下几个
- 任务失败
Application Master失败Node Manager失败Resource Manager失败
接下来我们分别看看这些情况怎么解决。
task 失败
任务失败的情况有可能出现下面的情况:
- 用户
map、reduce task代码问题,这种失败最常见,此时在task JVM在退出前会向Application Master发送错误报告,该报告会被计入用户日志。最后Application Master会将该任务将任务尝试标记为failed,并释放容器,使其资源可供另一个任务使用。 - 另一种情况是
task JVM突然退出,可能存在一个JVM bug,导致JVM在特定环境下退出MapReduce的用户代码。
这种情况下,Node Manager发现进程已经退出,会告知Application Master,并将任务尝试标记为failed。 - 还有一种是任务超时或者挂起,一旦
Application Master注意到有一段时间没有收到任务进度更新了,就会将该任务标记为failed,由参数mapreduce.task.timeout(默认10分钟,0表示关闭超时,此时长时间运行任务永远不会标记为failed,慎用)设置。
task 失败的处理方式:
Application Master发现任务失败后,会重新调度该任务,会进行避免在之前失败的Node Manager上调度该任务。
如果一个任务连续失败四次(mapreduce.map.maxattempts,mapreduce.reduce.maxattempts),就不会继续重调,整个Job也就失败。- 而有些场景在少数任务失败,结果仍旧可以使用,那么此时我们不希望停止任务,可以配置一个允许任务失败的阀值(百分比),此时不会触发Job失败。
通过mapreduce.map.failures.maxpercent、mapreduce.reduce.failures.maxpercent设置。 - 还有一个情况是任务尝试被kill,这种情况
Application Master制动标记killed不属于任务失败。
推测机制(Speculative Execution),如果发现task执行的时间运行速度明显慢于平均水平,就会在其他的结点启动一个相同的任务,称为推测执行。
这个不一定有效,仅仅是投机性的尝试。
当任务成功完成时,任何正在运行的重复任务都将被终止,因为不再需要它们。
就是推测任务与原始任务谁能上位就看谁先完成了。
Application Master 失败
当遇到Application Master失败时,Yarn也会进行尝试。
可以通过配置mapreduce.am.max-attempts property(默认:2)配置重试次数,
同时,Yarn对于集群中运行的Application Master最大尝试次数加了限制,也需要通过 yarn.resourcemanager.am.max-attempts(默认:2)进行配置。
重试的流程如下:
Application Master 向Resource Manager发送心跳,如果Application Master发生故障,Resource Manager将检测故障,并在新的容器中启动运行Application Master的新实例
在MapReduce,它可以使用作业历史记录来恢复(失败的)应用程序已经运行的任务的状态,这样它们就不必重新运行。
默认情况下恢复是启用的,但是可以通过设置yarn.app.mapreduce.am.job.recovery来禁用。
MapReduce client轮询Application Master的进度报告,
但如果它的Application Master失败,客户端需要定位新的实例。
在Job初始化期间,client向Resource Manager请求Application Master的地址,然后对其进行缓存,这样在每次需要轮询Application Master时,
就不会向Resource Manager发出请求,从而使Resource Manager负担过重。
但是,如果Application Master失败,client将发出状态更新时超时,此时client将向Resource Manager请求新的Application Master的地址。
Node Manager 失败
如果Node Manager因崩溃或运行缓慢而发生故障,它将停止向Resource Manager发送心跳(或发送频率非常低)。
Resource Manager 如果在10分钟内(yarn.resourcemanager.nm.liveness-monitor.expiry-interval-ms )没有收到Node Manager的心跳信息,
就会告诉该Node Manager,停止发送心跳,并将它从自己的Nodes池中移除。
在此Node Manager失败的task 或 Application Master 都会按照之前的说的方式恢复。
此外,即使map tasks在失败的Node Manager上运行并成功完成但属于未完成的job,
Application Master也会安排它们重新运行,
因为它们的中间输出驻留在故障Node Manager的本地文件系统上,reduce任务可能无法访问。
如果一个Node Manager失败任务次数过多,该Node Manager会被Application Master拉入黑名单。
对于 MapReduce,如果一个Job在某个
Node Manager失败3个任务(mapreduce.job.maxtaskfailures.per.tracker),就会尝试在其他的结点进行调度。
注意,Resource Manager不会跨应用程序执行黑名单(编写时),
因此来自新作业的任务可能会在坏节点上调度,即使它们已被运行较早作业的应用程序主程序列入黑名单。
Resource Manager 失败
Resource Manager失败是很严重的,一旦它失败, job和task容器都无法启动。
在默认配置中,Resource Manager是一个单故障点,因为在(不太可能的)机器故障的情况下,所有正在运行的作业都失败了并且无法恢复。
要实现高可用性(HA),必须在一个active-standby配置中运行一对Resource Manager。
如果 active Resource Manager发生故障,则standby Resource Manager可以接管,而不会对client造成重大中断。
通过将运行中的应用程序信息存储在高可用的状态存储区中(通过ZooKeeper/HDFS备份),实现standby Resource Manager 恢复active Resource Manager(失败)的关键状态。
Node Manager 信息没有存储在状态存储中,因为当Node Manager 发出第一次心跳时,新的Resource Manager可以相对较快地对其进行重构。
因为
task由Application Master管理,所以task不属于Resource Manager的状态,因此于Resource Manager存储的状态比jobtracker中的状态更容易管理。
目前,有两种持久化RMStateStore的方式,分别为:FileSystemRMStateStore和ZKRMStateStore。
整体架构如下:
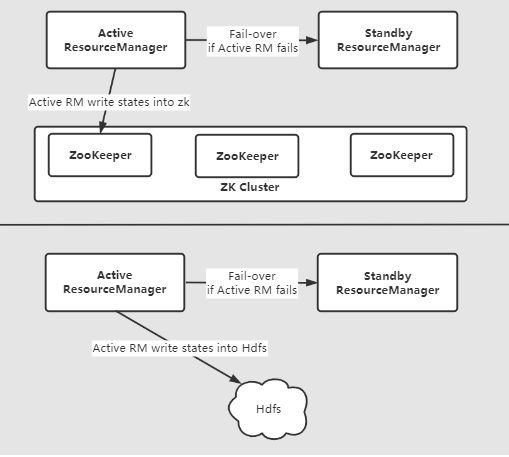
我们可以通过手动或自动重启ResourceManager。
被提升为active 状态的ResourceManager加载ResourceManager内部状态,并根据ResourceManager restart特性尽可能从上一个active Resource Manager 离开的地方继续操作。
对于以前提交给ResourceManager的每个托管Application,都会产生一个新的尝试。
应用程序可以定期checkpoint,以避免丢失任何工作。
状态存储必须在两个Active/Standby Resource Managers中都可见。
从上图可以看到我们可以选择的状态存储介质有两个FileSystemRMStateStore 和 ZKRMStateStore。
ZKRMStateStore隐式地允许在任何时间点对单ResourceManagers进行写访问,
因此在HA集群中推荐使用ZKRMStateStore。
在使用ZKRMStateStore时,不需要单独的防御机制来解决可能出现的脑裂情况,即多个Resource Manager可能扮演active角色。
并且ResourceManager可以选择嵌入基于zookeeper的ActiveStandbyElector来决定哪个Resource Manager应该是active的。
当active的ResourceManager关闭或失去响应时,另一个Resource Manager会自动被选为active,然后由它接管。
注意,不需要像HDFS那样运行一个单独的
ZKFC守护进程,因为嵌入在Resource Manager中的ActiveStandbyElector充当故障检测器和leader elector,所以不需要单独的ZKFC守护进程。
关于Yarn的内容就介绍到这里,更详细的内容可以参考官网
之后会更新一些Hdfs读写的源码追踪相关文章,有兴趣可以关注【兔八哥杂谈】

 浙公网安备 33010602011771号
浙公网安备 33010602011771号