
数据库仓库系列:(一)什么是数据仓库,为什么要数据仓库
最近全程参与了数仓的重建工作,颇有些心得。
于是萌生了写一篇关于数据仓库文章的想法。
编写此文章的过程中会查找更多的资料和结合自己工作经历,确保内容质量。
即是自己工作的记录和总结,也是更系统的捋一遍数仓。
文章会分为三个部分:
第一部分:介绍什么是数据仓库
第二部分:如何设计数据仓库
第三部分:从零开始设计一个数据仓库
罗拉的烦恼
昨天罗拉加班到十点多才下班,回来的时候还脸色明显不对劲,瘫在沙发上,闷闷不乐的。
八哥赶忙过去关心一下。
于是有了下面的对话
| 对话记录 |
|---|
**八哥**
罗拉,工作很忙吗?加班这么晚?还闷闷不乐的?
|
**罗拉**
哎,工作的事情,烦死了...| | |**八哥**
啥工作,说出来开心...额,说出来我看看能不能帮你
|
**罗拉**
最近公司搞了一个营销月活动,领导想看最近一个月每个用户消费情况,
包括按照年龄、性别、地址之类的分布。| | |
**八哥**
这个不是很常规的需求吗?应该不难吧?
|**罗拉**
需求看起来很简单,但是当我实际想统计的时候就一脸懵逼了| | |**八哥**
嗯,你说说看,难的点在哪里?
|
**罗拉**
这个需求中我们至少需要==全量用户信息、用户消费记录、产品清单==如果这三玩意在一个数据库中我们容易就做到这个需求,
可是这些分别在==mysql,mongoDB、hdfs文件==中
我想关联得经过重重转换,想想都头大...| | |
**八哥**
等等,听你这么说,
你们公司现在的数据来源很多,然后就这么堆着?
每次都拿原始数据来做分析?
|
**罗拉**
对啊,不然捏,其实一开始还好,但是现在随着公司发展,业务越来越多,越来越难搞了
每次弄个数据就怕遇到不同存储介质的,需要转来转去
还有经常做重复的东西。浪费时间| | |
**八哥**
不是,你们这情况就没想过弄个数据仓库吗?
|
**罗拉**
数据仓库?没有,但好像听过,那是什么玩意儿?给我说说| | |**八哥**
额,好吧,给你说说
os:完蛋,好像给自己挖坑了...
|
举个栗子
说到数据仓库,和数据库一字之差。那就不得不说一下他们之间的关系了。
首先我们先举个栗子,先初步认识一下两者的关系。
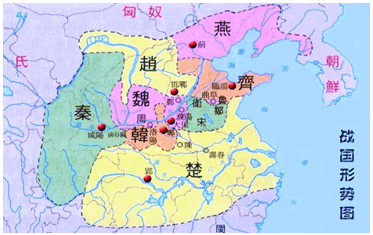
上图是我们战国时期的形势图。
我们耳熟能详的战国七雄:齐、楚、秦、燕、赵、魏、韩。
战国时期,能人辈出,各国都实行不同的方案发展自身,七个国家基本都有过一段时间兴盛时期。
但是这个时候东周还没有灭亡,明面上,周天子才是天才正统,七国还是属于分封国家。
分封国管理自己内部的事务,比如赋税、练兵、教育等,周天子一般不会干涉(好像后面也没啥能力干涉),但是周天子有需求,比如勤王,那么诸侯国理论上就要接受周天子的调遣。
在这个例子中,周王朝可以类比数据仓库,诸侯国可以类比数据库。(当然,这个类比不太准确,但是大家可以有个统筹的概念)。
那么,回到罗拉工作的问题,公司的数据来源很多,导致我们每进行一个数据统计都需要很多复杂的操作。
比如,罗拉公司中数据来源有以下几种

而我们需要统计的信息涉及到上面的所有数据源,我们必须把上面的数据都集中到一个存储介质中才能进行关联。
然而,即使我们这次需求做完了,如果我们需求有一点变化,我们可能都得重头来一遍。
比如这次我要计算最近七天消费分布,下次我要计算最近30天甚至最近半年、一年的指标。
由于我们之前只计算了近七天的指标,那对于其他的指标我们只能重新计算,
甚至可能出现数据源过大,如果存储介质选择不当,导致计算效率低下的问题。
为了解决这个问题,我们可以借鉴上面战国七雄的例子,设计一个数据仓库。
其结构图如下:
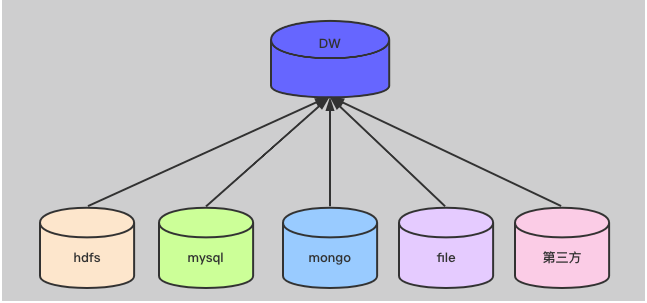
而我们要做的就是的目标就是捣鼓出一个DW。让我们的数据更加规范。
接下来我们就开始数据仓库方面的一些介绍。
什么是数据仓库
数据仓库的定义
数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化的(Time Variant)数据集合。用于支持管理决策(Decision Making Support)。
具体的含义后续介绍
数据库与数据仓库的区别
从逻辑、概念层面来看
数据仓库和数据库其实是一样的,它们都是通过某种数据库软件,基于某种数据模型来组织管理数据。
但是他们的侧重点不同:
通常数据库更关注业务交易处理(OLTP)层面;
而数据仓库关注数据分析(OLAP)层面。
这导致二者之间在一些方面有明显的区别:
| 数据库(DataBase) | 数据仓库(Data Warehouse) |
|---|---|
| 表结构相对复杂 | 表结构相对简单 |
| 存储结构相对紧凑 | 存储结构相对松散 |
| 较少数据冗余 | 较多数据冗余 |
| 一般读、写都有优化 | 一般只有读优化 |
| 相对简单的读、写查询 | 相对复杂的读查询 |
| 单次操作数据量较少 | 单次操作涉及数据量相对较大 |
通过上面的对比,结合实际使用,我们可知,数据库一般都会追求响应速度、数据的一致性等特点。
所以我们在设计数据库模型上一般都会遵循一些范式,比如1NF、2NF、3NF等。
目的都是为了减少数据的冗余和相应速度等。
而数据仓库强调的是数据分析的效率,复杂查询的响应速度和数据之间的相关性之类的分析。
所以,数据仓库一般都是多维模型,有较多的数据冗余,但是同时查询的效率也会提高。
这里的复杂查询不是指一个复杂的sql,而是数据仓库建好后,通过完善的数据指标简化原本复杂查询的需求。
所以,从某种意义上来说,数据仓库就是反范式设计的数据库
为什么要数据仓库
通过上看的对数据库和数据仓库的对比,罗拉还是有点似懂非懂。
好像懂了,但是就是不太明白,数据仓库和数据库的实际分工。
就是为什么要数据仓库?
我如果把所有数据源都放到一个库里面的是不是就是数据仓库?
也对,上面的文字太过空泛,就好像在上思修课,听了都想睡觉。
那下面八哥就结合图文和罗拉公司的案例,给大家扯一扯数据仓库的作用吧。
一般公司的三个阶段与架构演变
以罗拉的公司为例,公司主要的业务是生产化妆品,主要通过线上销售,也就是我们说的电商。
一般来说,电商公司会有三个阶段。(当然,挂得早也许就没有第二、第三阶段了)
第一阶段
几个人,甚至一个人,找个地方,弄个服务器,做个下单的页面,搞个mysql。
放个鞭炮就可以开门营业了,这个时候属于初创阶段。
我们的数据很简单,并且数量也比较少,可能就只有简单的销售记录。
此时的架构如下:
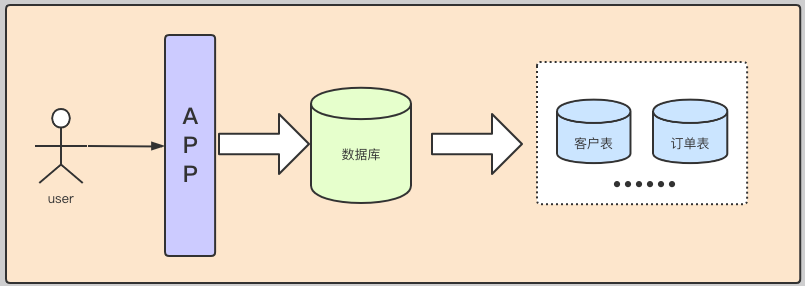
基本我们的统计需求都可以通过简单的查询实现,并且服务器也没啥压力,速度杠杠滴。
第二阶段
由于经营有方,我们获得订单越来越多,招聘了一些员工,产生的数据量也越来越多,
并且有了一些运营推广的需求,我们存储的数据类型也越来越多。
单库,单服务器已经撑不住了。
于是我们升级了架构:变成了多服务器和多业务库(即分库分表)。
此时的架构如下:
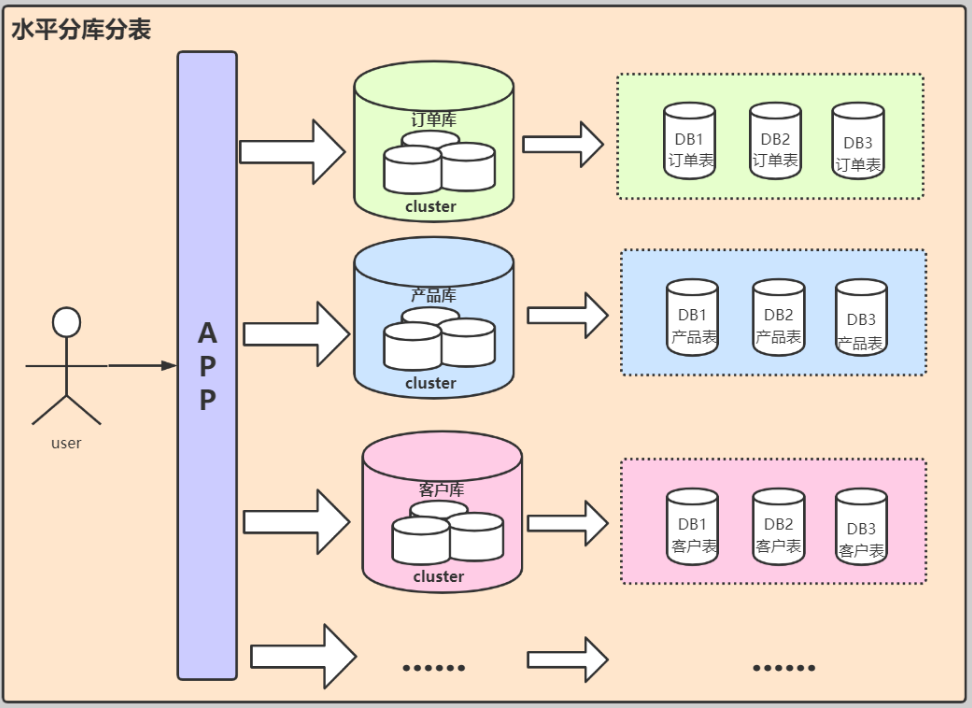
这个时候我们还能通过复杂的语句从业务库查询我们需要的指标。
第三阶段
随着口碑越来越好,我们获得客户和订单指数级别增加,招的员工越来越多。
分工也从大家都是领导到有ceo、cto、cfo、cio等。办公地方也换到更加高大上的地方。
随着团队越来越专业,营销手段、经营策略也会越来越专业。
而这一些都需要数据的支撑。
但是我们现在需要的数据非常专业或非常全面。
比如以前我们只关心“日营收、月营收、营收同比、环比等”。
但是我们现在为了精准营销,我们更关注“客户性别比例、年龄分层、消费分级、地域差异、消费组成、回购率”等更加细分的数据。
这个时候我们关注的都是一些非常精细化和用户集群分析。这些一般都能对公司的决策起到关键性作用。
那么这个时候,之前的业务库基本无法支撑我们的数据需求了,我们就需要建立一个数据仓库来支持管理决策。
看来罗拉公司发展不错,公司正处于第二到第三阶段的时候。也就是需要建立数据仓库的时候。
这个时候的架构一般都是以下面的结构为蓝图:
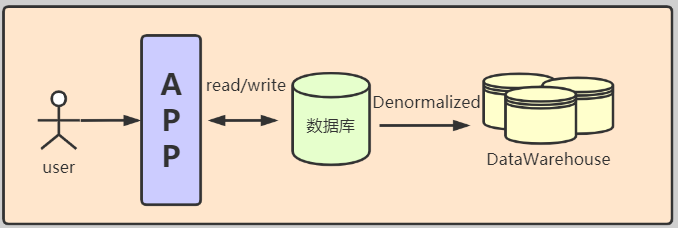
如果需要分不同的组或数据隔离、以免相互影响,除了配置权限,也可能会通过配置数据目录(Data Catalog)来实现目的。
此时架构会变成下面的样子:
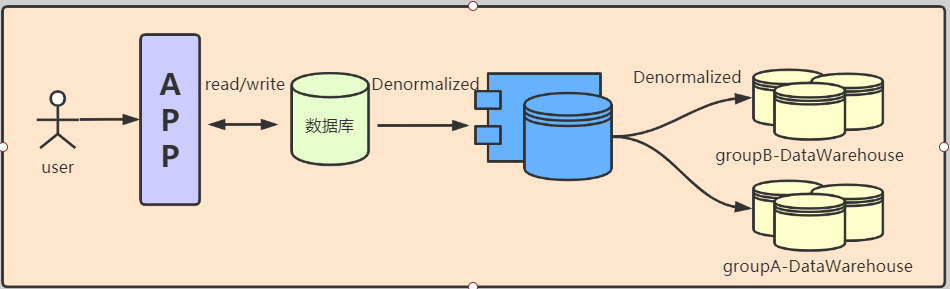
实际中的架构,无论哪个阶段都会比图中的复杂,但是基本以此为蓝图进行拓展。
为什么要数据仓库?
通过对上面三个阶段的分析,我们其实很容易得出一个结论,我们建立数据仓库最懂得目的就是要把事务处理与数据分析解耦合,增加系统的可拓展性。
解不解耦合其实就是业务库与数据仓库的关系,之前我们简单介绍了数据库与数据仓库的区别。
这里我们稍微唠嗑深一点。如果我们解耦合与不解耦合会有什么差别
不解耦合
如果我们不解耦合,也就是我们的数据分析直接来自业务库,导致几个问题数据分析的时候。
结构复杂、大规模查询慢
业务库一般是针对业务专门设计的,为了减少数据冗余,会遵循3NF范式。
这就导致表之间的关系其实是一张网,通过外键、主键之类的进行关联。
我们很多的业务表信息都是一堆编码,通过编码去关联详情。
如下:
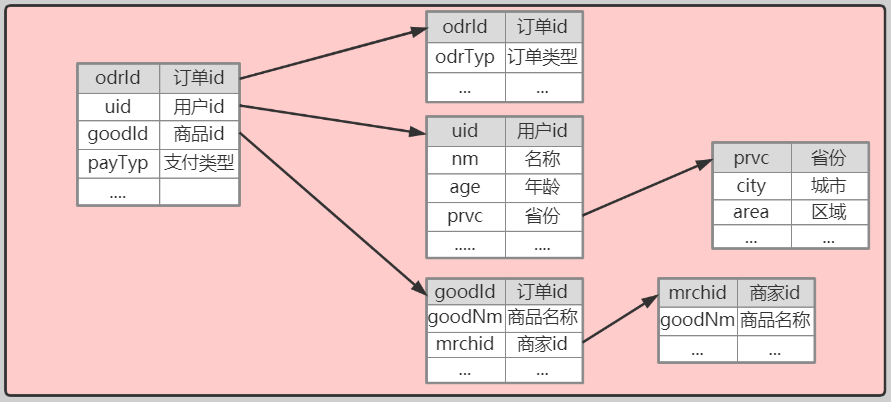
此时如果对于一些数据分析涉及到具体详情信息,我们可能需要通过多层关联才能得到,这就给分析数据增加很大的复杂度。
此时如果每个表都是大表,数据量都很大,那么我们就可以带薪蹲坑了(编码一分钟,执行九分钟)。
如果在同一个数据库还能勉强做,如果想罗拉那样,数据满天星,mysql、mongo、hdfs哪里都有的话,老实说这个时候做关联操作实在是有心无力。
脏数据乱入
业务库一般存储了所有的业务数据,与此同时,在业务过程中可能由于各种原因比如网络、宕机、数据校验不完善等原因,会产生一些列脏数据。
脏数据包括但不限于以下情况:
| 脏数据情况 | 案例 |
|---|---|
| 核心数据为空 | uid、odrId为null |
| 数据不合法 | 手机号码、身份证、日期之类的不符合规范 |
| 数据错误 | 比如在线时长、登陆时长超过合理值 |
| 数据重复 | 数据重复上报 |
如果我们在做数据分析的时候还得对于所有的脏数据再处理一次,那这效率,像罗拉这样加班就算了。
如果拿数据支持管理决策,一不小心因为处理脏数据不完善,搞个错误数据,误了公司决策,这个锅你背得动吗?
无法反应历史
业务库一般的不会存储很长历史的数据以保证响应速度,这样对于我们需要做一个历史衍变、趋势之类的数据分析,单靠业务库就已经很难实现了。
而历史趋势对于我们后续的决策是很有借鉴意义。
比如营收,销量之类的做个历史分析
如果我们的数据分析,都和业务库扯在一起,至少上面的问题基本都会有。
如果我们把数据分析部分拆出来呢?
当然就是通过解耦合啦
解耦合
业务库服务业务,我们通过建立数据仓库达到业务处理与数据分析分离的目的。
如果我们的数据仓库设计的合理,那么会极大提高我们数据分析人员数据分析的效率和质量。
究其主要是基于以下几点。
表结构清晰
我们数据仓库一般都是通过etl一天更新一次,对于每天的数据量我们都是心里有数的,并且为了分析方便,我们会刻意冗余数据。
在数据仓库中,我们数据的设计模型(详细的模型分类后面再说)一般采用星型结构。
主要有两部分组成:事实表、维度表
- 事实表
处于星星结构的中心,存储某种业务各个维度的数据,其中各个维度一般都是对应编码。
比如订单表:
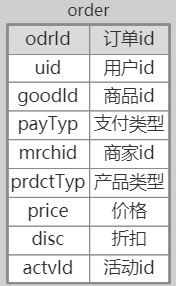
- 维度表
维度表可以看作是事实表的发散表,对应着事实表里面的每一个维度。根据我们的需要,我们可以选择我们需要的维度进行分析关联。
比如下面的表:
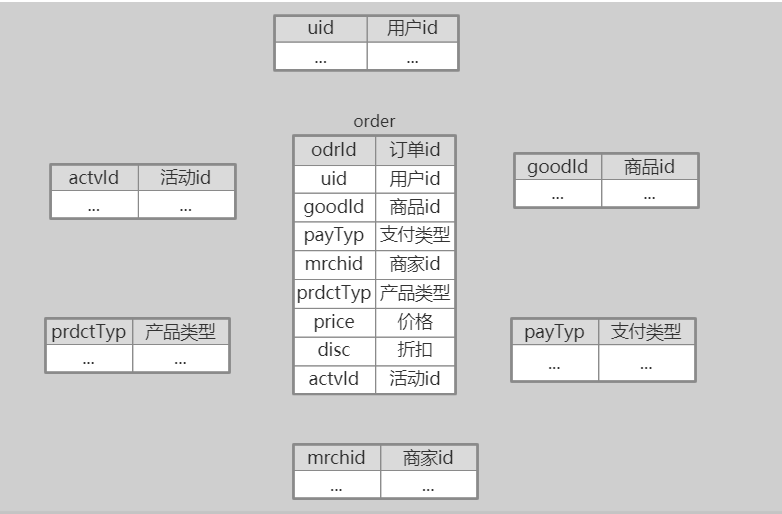
这个时候我们分析数据的步骤就变成了下面模式化的步骤:
- 选择分析主题(营收、登陆、时长等)
- 找相关业务表(即营收事实表、登陆事实表、时间事实表等)
- 根据分析数据需求确定维度(即确定事实表需要关联的维度表)
- 计算结果(关联需要的维度后计算结果)
通过以上设计,表结构简单清晰,数据分析的步骤规范、易于理解。
无脏数据
之前我们直接用业务库的数据,可能存在各种各样的脏数据。
在数据仓库中,我们对于模型在设计方面最基本的要求有几点:
- 数据字段类型统一:同一个含义的字段要类型一致(比如,登陆、消费都有用户id,要么都是
int、要么都是string)。 - 命名要规范:采用驼峰或分隔要统一,切勿混用,不要出现
usrId,musr_id同时出现的情况 - 相同含义的字段保持一致:比如手机号码,决定用
msdn就不要在出现phoneNumber之类的 - 缺省值处理:对于缺省值或异常错误的数据要有默认值。方便分析的时候删选过滤。
- 字段命名可理解:不要乱七八糟乱取名字,便于理解的名字,最好维护一个英文缩写表。
为了达到上面的需求,我们每天都会通过etl对业务数据进行处理。
脏数据对我们数据分析的影响很大,所以对于每一个业务,我们在etl的数据清洗过程中就对脏数据进行处理,同时把业务数据按照我们数据模型设计的规范导入到数据仓库。
这样我们在数据分析的过程中就不需要要费劲处理脏数据了,顶多就一个过滤。
反应历史
数据仓库一般都是采用分布式存储,典型的就是基于hive的数据仓库。我们可以存储大量的历史数据。
可以支撑我们做历史分析。
快速复杂查询
正如八哥前面说过的,快速复杂查询不是说执行一个复杂的sql能够很快返回结果。
而是我们通过建立合理、规范的数据仓库,使得原本在业务库需要通过各种关联才得到的结果在数据仓库中可以用过简单关联和计算就得到到结果。
单靠仓库本身的比如hive查询可能需要花费较长的时间,因为基于mapreduce,是硬伤,但是我们可以通过将构建多维查询比如通过kylin、druid、clickhouse等将所有的查询可能保存下来,达到秒级查询效率也是可以。
总结
通过上面的介绍,我们可以对数据仓库做一句话总结:
数据仓库就是为了业务处理和数据分析解耦的。
至于如何设计一个数据仓库,我们后面继续再继续。
欢迎关注【兔八哥杂谈】,会持续分享更多内容.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号