

JDK源码解析-HashMap
一、参数解读
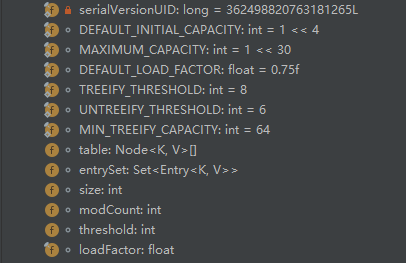
serialVersionUID用来保证序列化与反序列化时版本的兼容性。
1、DEFAULT_INITIAL_CAPACITY定义了HashMap初始时的容量为16
2、MAXIMUM_CAPACITY定义了HashMap的最大容量为2的30次方
3、DEFAULT_LOAD_FACTOR定义了扩容时的加载因子,也就是当容量已经占用了0.75后自动扩容
4、TREEIFY_THRESHOLD(树化阈值)定义了当数据量大于等于8时使用红黑树而不使用链表,因为在数据量较小的情况下,红黑树要维持自身平衡,对比链表并没有优势
5、UNTREEIFY_THRESHOLD(还原阈值)定义了当数据量小于等于6时使用链表,在这里有一个小知识点,就是中间值7没有操作,这是为了防止红黑树和链表之间频繁转换降低性能(ps:之前小米面试官问我当数据量从6到7到8和8到7到6会发生什么我没答出来,刻骨铭心的痛)
6、MIN_TREEIFY_CAPACITY(最小树型化阈值)当哈希表中的容量大于该值时,才允许树型化链表,否则,若桶内元素太多,则直接扩容,而不是树形化,为了避免进扩容和树形化的冲突,这个值不能小于4倍的树化阈值
7、table是在创建时初始化的表,长度总是2的幂次方,在某些情况下允许长度为0,每一个node本质上都是一个单向链表
8、entrySet功能为保存缓存
9、size是当前hashmap的大小
10、modCount记录了结构性修改的次数,这个参数在官方源码中的作用是这样说的:“此字段使哈希映射的集合视图上的迭代器快速失效”,说白了,因为hashmap是线程不安全的,使用迭代器迭代时,一旦modCount被修改了,就证明数据被修改了,迭代器就会抛出异常,这其实就是所谓的Fail-Fast 机制
11、threshold此参数是下一次扩容时的大小
12、loadFactor也是加载因子,前面那个是默认的加载因子,这个参数可以在构造hashmap时自定义
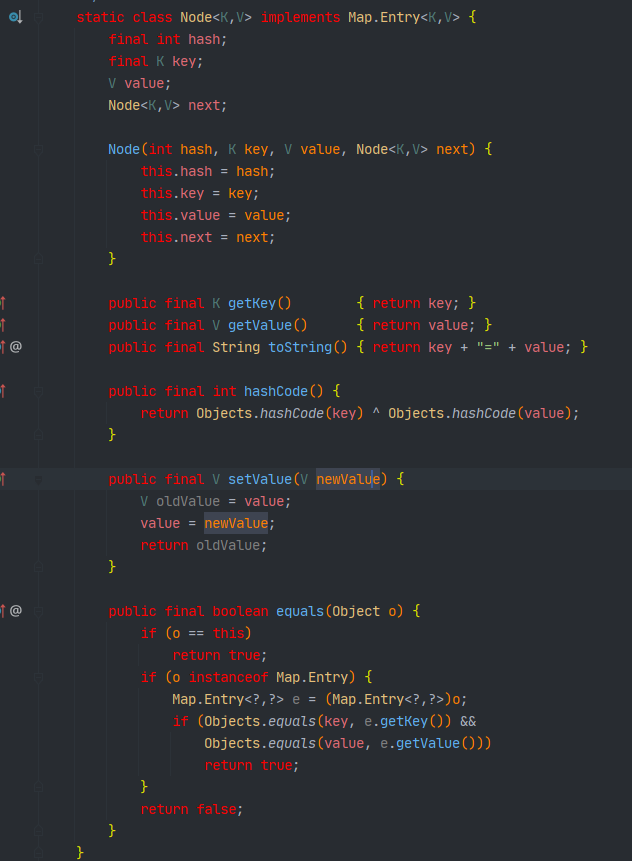
单向链表没什么好说的,看一下就行。
三、红黑树的实现
红黑树的实现代码太太太长了,看了一下,不贴上来了,告辞。
四、Hash的计算方式
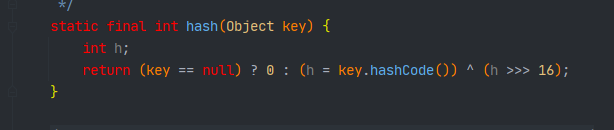
这里将key本身的hashCode与hashCode无符号右移16位进行异或运算生成一个新的hash值
至于为什么要这样做,源码中是这样说的
计算key.hashCode()并将哈希的高位扩展到低位。因为该表使用二的幂掩码,所以仅在当前掩码之上的位中变化的哈希集将总是冲突。(已知的例子有在小表格中保存连续整数的浮动键组。)所以我们应用了一个向下传播高位比特影响的变换。比特扩展的速度、效用和质量之间有一个折衷。因为许多常见的哈希集已经合理分布(因此不要从扩展中受益),并且因为我们使用树来处理容器中的大冲突集,所以我们只是以最便宜的方式异或一些移位的位,以减少系统损失,并结合最高位的影响,否则由于表的边界,最高位将永远不会用于索引计算。
大概就是说可以避免hash冲突,因为链表的查询是十分耗时的,我们希望hashmap中的元素尽可能的分布均匀,尽可能少的产生哈希冲突,在这里我查询了其它版本JDK中的这个方法,1.7和1.8都是使用无符号右移和异或降低冲突,这个方法称为扰动函数,防止不同的hashCode的高位不同但是低位相同导致的hash冲突,就是把高位的特征和低位的特征结合起来,从而降低hash冲突的概率。
这里可以深究一下,打个tag
想起来一个问题,如果已知要存储100个数据,hashmap初始容量应该设置为多少,答案为256,看到这里还不知道为什么的去面壁思过。
五、put方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; //如果table为空或者长度为0,则通过resize获取 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null) //当前位置为空,直接new一个节点并赋值 tab[i] = newNode(hash, key, value, null); else { //当前节点不为空 Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) //如果这个节点的TreeNode类型,则在红黑树中查找 e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { //否则则向单链表中添加数据 for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st //大于8则树化 treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) //判断是否需要扩容 resize(); afterNodeInsertion(evict); return null; } |
put方法执行流程
1、获取Node数组table,如果为空或者长度为0,调用resize方法获取对象得到长度
2、判断数组中指定下标下的节点是否为null,若为null,则new一个单向链表赋值
3、有数据则判断key有没有重复,重复则覆盖
4、不重复则判断是什么类型的节点,树型节点则添加,链表型节点需要判断长度是否超过阈值
5、判断数组需不需要扩容
未完待续


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构