

js遍历树形结构方法
如下图的nodeList是一个标准的树形结构数组,他的层级最深是三层,在实际工作中我们碰到的树形结构层级不定,有可能更深,每个节点的属性也复杂的多, 所以能够访问任意层级的方法是首选。这里就以遍历nodeList并输出所有id为例。
let nodeList = [
{id: '1-1', children: [{id: '1-2-1'}, {id: '1-2-2'}]},
{id: '2-1'},
{id: '3-1', children: [{id: '3-2-1', children: [{id: '3-3-1'}]}]}
]
方法一: 普通递归
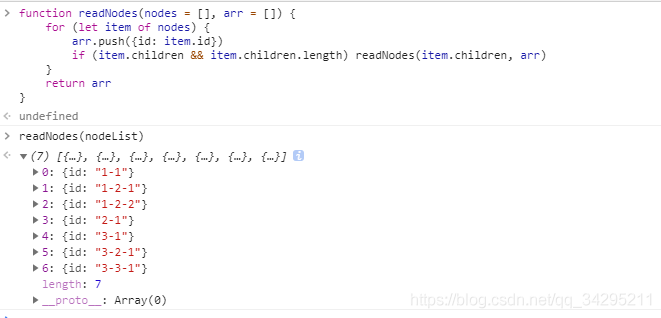
function readNodes (nodes = [], arr = []) {
for (let item of nodes) {
arr.push(item.id)
if (item.children && item.children.length) readNodes(item.children, arr)
}
return arr
}

这个方法比较常见,第一点就是你需要用额外的变量保存最后的结果,第二点就是可递归的条件是当前访问节点具有子节点,nodeList的children属性便是记录了子节点数据,我们不仅要判断children是否存在,还得判断children的长度是否为空。在函数中写上默认值是一个比较好的习惯,因为你无法保证别人在使用你方法的时候会不会给你传值,同时可以保证你函数的健壮性。
方法二:利用generator 函数返回的遍历器
function* gen (nodes = []) {
for (let item of nodes) {
yield item.id
if (item.children && item.children.length) yield* gen(item.children)
}
}

这个方法虽然也用到了递归,但相比方法二显得更加的简洁,易读。方法二的核心有三点,第一点是generator函数(生成器函数)的返回结果是一个遍历器,遍历器可以被扩展运算符(...),for ... of...,Array.from, 解构赋值等访问, 通常我们都会输出数组。第二点是紧跟yield的值会被当成遍历结果输出,例如这里的item.id,当我们用for...of...去遍历的时候,遍历的就是item.id。第三点就是在生成器函数中访问生成器函数并期望他可以正常被遍历访问的时候必须用yield* ,如上图的yield* readNodes(item.children), 不然的话直接使用readNodes(item.children),将会导致item.children并不会被遍历到。
小结一下,以上方法的核心功能就是遍历树状的结构,至于你想最后输出什么内容,只要改变一下方法中的返回值就行。比如我们想把树形结构的节点都拉平,变成一维数组的样子:

又或者我们不想让最后的一维数组中的父节点还出现children属性,只要自己希望出现的属性,我们可以这么做
是举一反三,顺势而为了。
爱生活、爱编程!

