目录
1、设计目标
- 对各个微服务的访问进行请求追踪,注重排查开发、线上问题
- 消息队列发送、多服务落盘,事后分析
- 日志分析
- 性能优化
2、日志流程
3、串联请求事务
3.1 请求ID
请求id:唯一标识一个Api请求链路。
为了分析前端的一条Api请求,需要在Api网关请求时产生一个guid,标识api的请求,并按照调用次序传递给微服务,微服务间可以互相调用,因此请求id按照调用次序依次传递。
3.2 处理服务器、服务
请求链路会穿越不同的服务器以及不同的服务,因此,需要记录服务器的IP或名称,服务的名称,这样在分析问题时可以快速找到故障点。
3.3 处理接口名
api的入口是唯一接口,但穿越不同节点后,实际执行接口会随着调用而改变,因此接口名需要被记录下来。
3.4 日志的发生时间
可提供时间索引,可按照时间进行分区分表等
3.5 接口返回状态码
状态码简单判断接口是否工作正常,有无错误,错误描述等
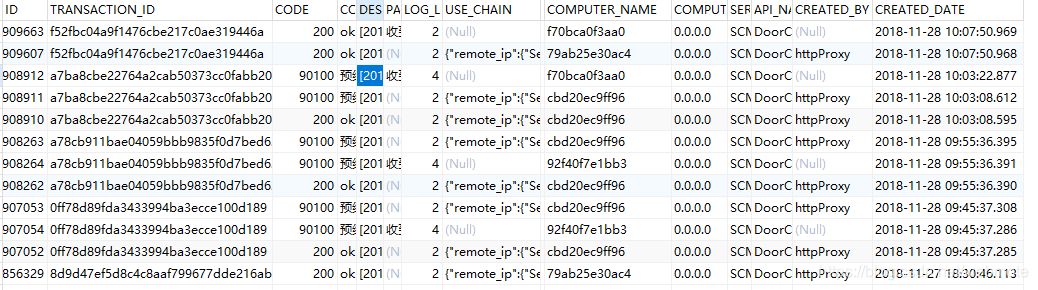
4、记录结构
5、RabbitMq队列

6、落盘
日志落盘采用RabbitMq的拉模式,考虑到日志的规模,如果采用推模式,很可能导致落盘阻塞,因此这里采用拉取模式,以落盘介质的流速为限制。
落盘可以采用多个微服务进行拉取,这样可以保证某个落盘服务故障后,仍然可以继续落盘。
落盘采用一个线程拉取队列,并存储在内存队列中,三个不同的落库线程,从内存队列中拉取并落库。
public static void Init()
{
_event = new AutoResetEvent(false);
_queue = new ConcurrentQueue<LogBase>();
new Thread(SaveLogInfo){IsBackground = true}.Start();
new Thread(SaveLogStat) { IsBackground = true }.Start();
new Thread(SaveLogBussiness) { IsBackground = true }.Start();
new Thread(SaveLogToDb) { IsBackground = true }.Start();
}
落库失败,可以降级到文件落盘。
7、性能优化
考虑到写库的性能限制,可以批量写库,使用insert value value批量方式能极大提高落库速度。
8、简单统计
可以快速分析api接口的访问次数以及响应的平均时间。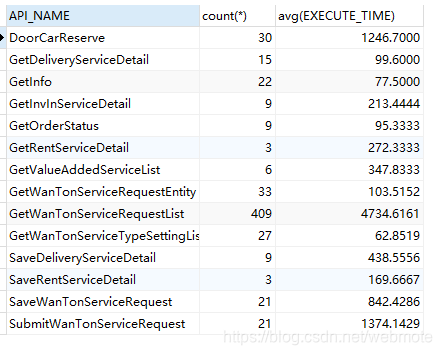
转载:https://www.cnblogs.com/lonelyxmas/p/10286277.html
