nodejs的基础概念
1.node 安装与相关配置。
2.Node.jsREPL(交互式解释器)
类似于控制台,可以输入命令,并接受系统的响应。
REPL 的功能:
1.读取:读取用户输入,解析输入的 js 数据结构,并存储在内存中。
2.执行:执行输入的数据结构。
3.打印:输出结果。
4.循环:可以循环1、2、3操作指导ctrl+c两次退出。
开启 Node 终端:node 即可开启。
运算符:+、-、*、/,还支持括号改变优先级。
变量定义:使用var来定义变量。常用的输出 API:console.log()。
多行表达式:这里指的是循环,与在 js 中做的循环是一致的。每输出一行回车就可以,node 会自动检测是否为连续多行表达式。
下划线_变量:可以使用下划线变量来获取上一个表达式的运算结果。
REPL 命令:
Ctrl+c 退出当前终端。
Ctrl+c 连续两次,退出Node REPL
Ctrl+d 退出 Node REPL
向上/向下键-查看输入的历史命令。
tab 键 列出当前命令
.help 列出使用命令
.break 退出多行表达式
.clear 退出多行表达式
.save filename 保存当前的 Node REPL 会话到指定文件。
.load filename 载入当前 Node REPL 会话的文件内容。
3. Node.js 回调函数
Node.js异步编程的直接体现就是回调。
异步编程依托于回调来实现,但是不能说使用回调就是异步化。
回调函数在完成任务后就会调用,Node使用了大量的回调函数,Node所有的API都支持回调函数。
注:阻塞是按顺序执行的,而非阻塞是不需要按顺序的,所以如果需要处理回调函数的参数,我们需要写在回调函数内。
4.Node.js事件循环
Node.js是单进程单线程应用,但是通过事件和回调支持并发, 所以性能很高。
Node.js的每一个API都是异步的(这里个人认为表达的意思应该是每一个API都是支持回调。参考第三部分),并作为一个独立线程运行,使用异步函数调用,并处理并发。
Node.js基本上所有的事件机制都是用设计模式中的观察者模式实现的。
Node.js单线程类似进入一个while(true)的事件循环,直到没有事件,观察者退出,每个异步事件都生成一个事件观察者。如果有事件发生就调用该回调函数。
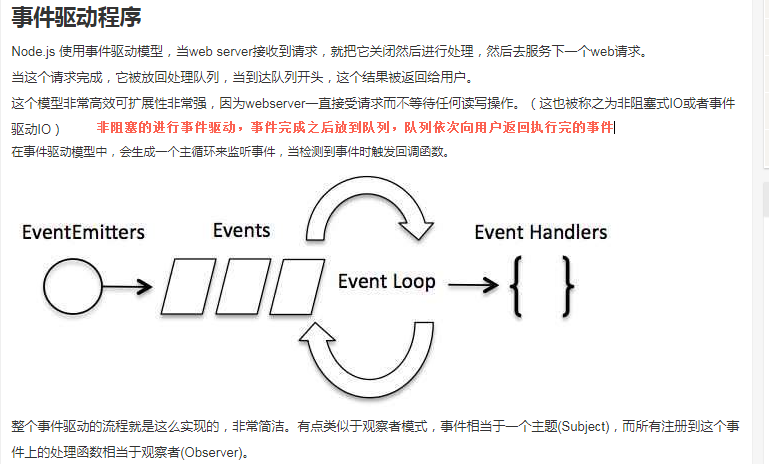
Node.js中内置多个事件,可以引入events模块,并通过实例化EventEmitter类来绑定和监听事件。
在Node中:执行异步操作的函数将回调函数作为最后一个参数,回调函数接受错误对象作为第一个参数。

5.Node.js EventEmitter
Node.js 所有的异步I/O操作在完成时都会发送一个事件到事件队列。
Node.js里面的许多对象都会分发事件:一个net.Server对象会在每次有新连接时分发一个事件,一个fs.readStream对象会在文件被打开的时候发出一个事件。所有产生的事件的对象都是events.EventEmitter的实例。
EventEmitter类
events模块只提供了一个对象,events.EventEmitter。EventEmitter的核心就是事件触发与事件监听器功能的封装。
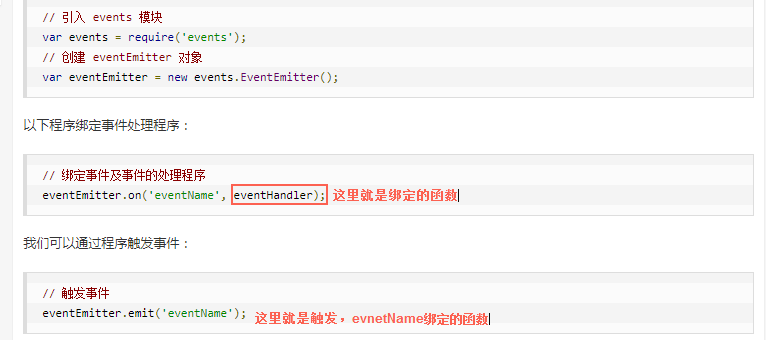
// 引入 events 模块 var events = require('events'); // 创建 eventEmitter 对象 var eventEmitter = new events.EventEmitter();
EventEmitter对象如果再实例化时发生错误,就会触发error事件。当添加新的监听器时,newListener事件会触发,当监听器被移除时,removeListener事件被触发。
简例说明EventEmitter用法:
//event.js文件 var EventEmitter = require('events').EventEmitter; var event = new EventEmitter(); event.on('some_evnet', function() { console.log('some_event 事件触发'); }); setTimeOut(function() { event.emit('some_event'); }, 1000);
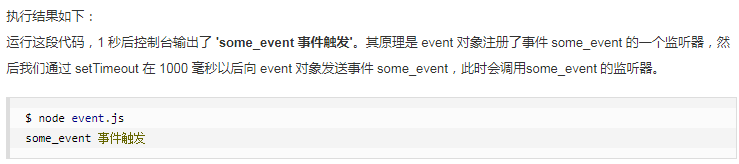
EventEmitter的每个事件由一个事件名和若干个参数组成,事件名是一个字符串,通常表达一定的含义,对于每个事件EventEmitter支持若干个事件监听器。
当事件触发时,注册到这个事件的监听器被依次调用,事件参数作为回调函数参数传递。
简例代码:
//event.js文件 var events = require('events'); var emitter = new events.EventEmitter(); emitter.on('someEvent',function(arg1, arg2) { console.log('listener1',arg1,arg2); }); emitter.on('someEvent',function(arg1, arg2) { console.log('listener2',arg1,arg2); }) emitter.emit('someEvent', 'arg1参数', 'arg2参数');
执行结果:

在上述例子中,emitter为事件注册了两个监听器,然后触发了事件。这是最简单的EventEmitter的用法。
EventEmitter提供了多个属性,如on用于事件绑定,emit用于触发一个事件。
具体的API
error事件
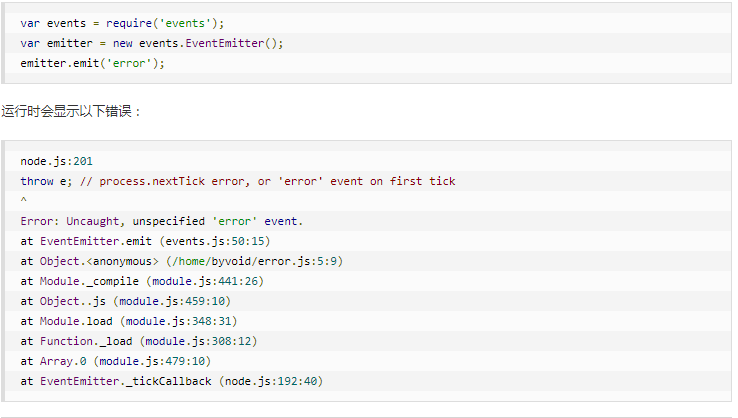
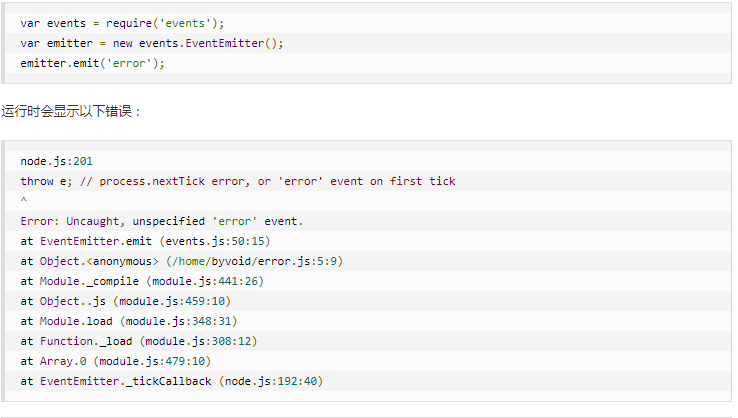
EventEmitter定义了一个特殊的事件error,它包含了错误的语义,我们在遇到异常时,通常会触发error事件。
当error被触发时,EventEmitter规定如果没有响应的监听器,Node.js会把它当做异常,退出程序并输出错误信息。
我们一般要为会触发error事件的对象设置监听器,避免出现错误后整个程序崩溃。
关于EventEmitter,
我们大多时候只会在对象中继承它,包括fs、net、http在内的。只要是支持事件响应的核心模块都是EventEmitter的子类。原因有二:
1.具有某个实体功能的对象实现事件符合语义,事件的监听和发生应该是一个对象的方法。
2.js的对象机制是基于原型的,支持部分多继承,继承EventEmitter不会打乱对象原有的继承关系。
注:补充:实践队列中出现一个未绑定事件会触发error事件,若未绑定error事件则程序抛出异常结束。
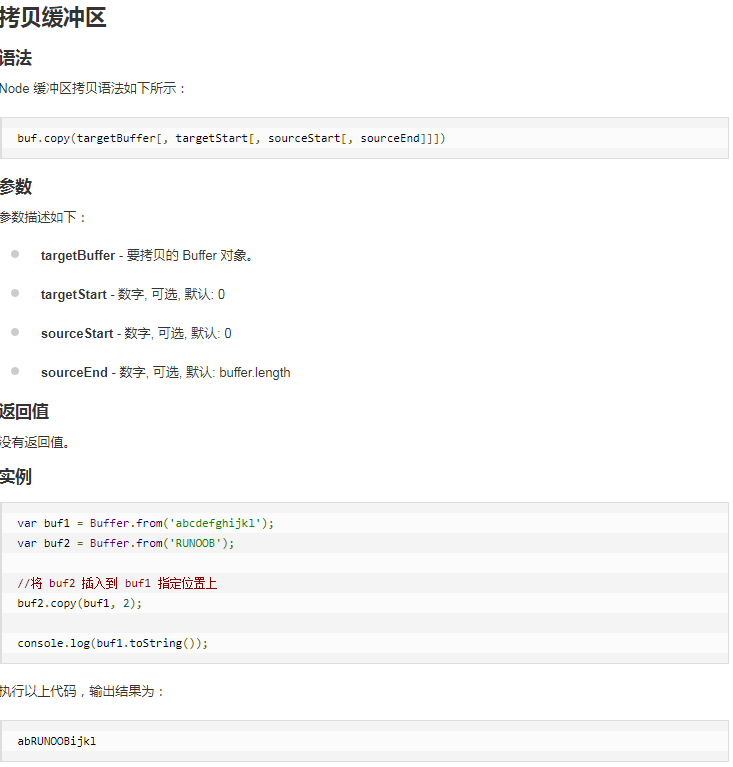
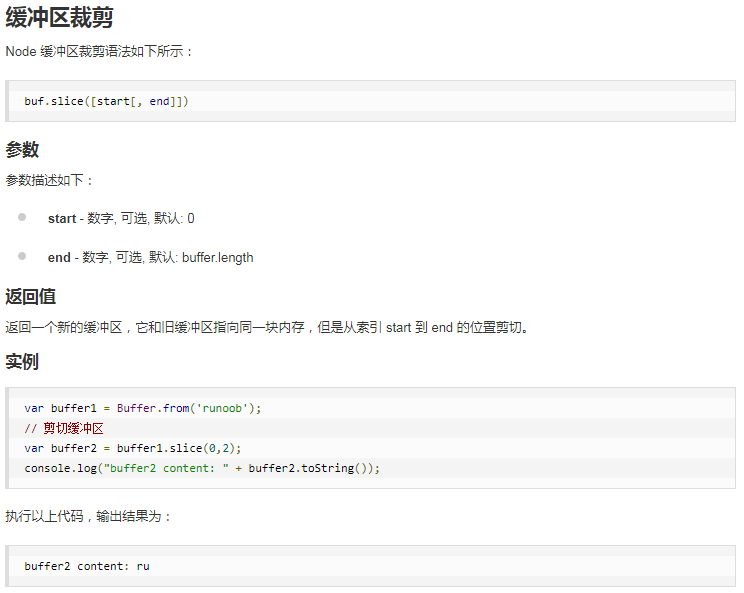
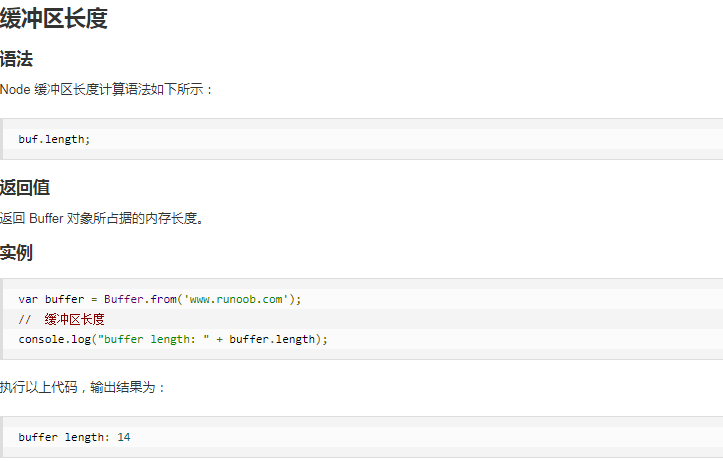
6.Node.js Buffer(缓冲区)
js只有字符串数据类型,没有二进制数据类型。但是在处理流时,必须使用二进制数据,因此在Node.js中定义了Buffer类,该类用来创建一个专门存放二进制数据的缓存区。
Buffer与字符编码
Buffer实例一般用于表示编码字符的序列,比如UTF-8、UCS2、Base64、或者十六进制编码的数据,通过使用显式的字符编码,就可以在Buffer实例与普通的JavaScript字符串之间进行相互转换。
const buf = Buffer.from('runoob','ascii');
//输出72756e6f6f62
console.log(buf.toString('hex'));
//输出cnVub29i
console.log(buf.toString('base64'));
Node.js目前支持的字符编码包括:
ascII 仅支持7位ASCII数据。如果设置去掉高位的话,这种编码是非常快。
utf8 多字节编码的Unicode字符,许多网页和其他文档格式都使用UTF-8。
utf16le 2或4个字节,小字节编码的Unicode字符。支持代理对(U+100000至U+10FFF)。
usc2 utf16le的别名。
base64 Base64编码。
latin1 一种把Buffer编码成一字节编码的字符串的方式。
binary Latin1的别名。
hex 将两个字节编码为两个十六进制字节。
创建Buffer类
Buffer提供了以下API创建Buffer类:
//创建一个长度为10、且用0填充的buffer const buf1 = buffer.alloc(10); //创建一个长度为10、且用0x1填充的buffer。 const buf2 = Buffer.alloc(10,1); //创建一个长度为10、且未初始化的Buffer。 //这个方法比调用Buffer.alloc()更快。 //但返回的Buffer实例可能包含旧数据。 //因此需要使用fill()或write()重写。 const buf3 = Buffer.allocUnsafe(10); //创建一个包含[0x1, 0x2, 0x3]的Buffer const buf4 = Buffer.from([1,2,3]); //创建一个包含 UTF-8 字节 [0x74, 0xc3, 0xa9, 0x73, 0x74] 的 Buffer。 const buf5 = Buffer.from('tést'); // 创建一个包含 Latin-1 字节 [0x74, 0xe9, 0x73, 0x74] 的 Buffer。 const buf6 = Buffer.from('tést', 'latin1');
写入缓冲区
语法:
写入Node缓冲区的语法如下所示:
buf.write(string[, offset[, length]][,encoding])
参数:

根据encoding的字符编码写入string到buf中的offset位置。length参数是写入的字节数。如果buf没有足够的空间保存整个字符串,则只会写入string的一部分,只部分解码的字符不会被写入。
返回值:
返回实际写入的大小。如果buffer空间不足,则只会写入部分字符串。
从缓存区读取数据
语法读取Node缓冲区数据的语法如下:
buf.toString([encoding[, start[,end]]])

buf = Buffer.alloc(26); for(var i = 0; i < 26; i++) { buf[i] = i + 97; } console.log(buf.toString('ascii')); //输出:abcdefghijklmnopqrstuvwxyz console.log(buf.toString('ascii', 0, 5)); // 输出: abcde console.log(buf.toString('utf8', 0 ,5)); //输出:abcde console.log(buf.toString(undefined, 0, 5)); //使用 'utf8' 编码, 并输出: abcde

将Buffer转换为JSON对象
语法:将Node Buffer转换为JSON对象的函数语法格式:
buf.toJSON()
当字符串化为一个Buffer实例时,JSON.stringify()会隐式地调用该toJson();

const buf = Buffer.from([0x1, 0x2, 0x3, 0x4, 0x5]); const json = JSON.stringify(buf); // 输出: {"type":"Buffer","data":[1,2,3,4,5]} console.log(json); const copy = JSON.parse(json, (key, value) => { return value && value.type === 'Buffer' ? Buffer.from(value.data) : value; }); // 输出: <Buffer 01 02 03 04 05> console.log(copy);

缓冲区合并
语法:
Buffer.concat(list[, totalLength])

var buffer1 = Buffer.from(('菜鸟教程')); var buffer2 = Buffer.from(('www.runoob.com')); var buffer3 = Buffer.concat([buffer1,buffer2]); console.log("buffer3 内容: " + buffer3.toString());

缓冲区比较
语法:
buf.compare(otherBuffer);

var buffer1 = Buffer.from('ABC'); var buffer2 = Buffer.from('ABCD'); var result = buffer1.compare(buffer2); if(result < 0) { console.log(buffer1 + " 在 " + buffer2 + "之前"); }else if(result == 0){ console.log(buffer1 + " 与 " + buffer2 + "相同"); }else { console.log(buffer1 + " 在 " + buffer2 + "之后"); }