
wordcount作业
1.github地址:
https://github.com/Jyc1997/wc(这是bin文件夹,最开始没搞清作业要求,所有代码改动都提交到了这里)
https://github.com/Jyc1997/WCALL(整个工程文件)
2.PSP表格:
|
psp2.1 |
psp阶段 |
预估耗时 (分钟) |
实际耗时 (分钟) |
|
Planning |
计划 |
20 |
20 |
|
·Estimate |
·估计这个任务需要多少时间 |
3930 |
2650 |
|
Development |
开发 |
3540 |
2540 |
|
·Analysis |
·需求分析 |
60 |
300 |
|
·Design Spec |
·生成设计文档 |
90 |
50 |
|
·Design Review |
·设计复审 |
60 |
20 |
|
·Coding Standard |
·代码规范 |
150 |
30 |
|
·Design |
·具体设计 |
150 |
60 |
|
·Coding |
·具体编码 |
2880 |
1920 |
|
·Code Review |
·代码复审 |
60 |
40 |
|
·Test |
·测试 |
90 |
120 |
|
Reporting |
报告 |
390 |
350 |
|
·Test Report |
·测试报告 |
240 |
80 |
|
·Size Measurement |
·计算工作量 |
60 |
20 |
|
·Postmortem & Process Inprovement Plan |
·事后总结,并提出过程改进计划 |
90 |
250 |
|
|
合计 |
3950 |
3000 |
3.解题思路:
step1:需求分析
通过对需求说明的分析,大致总结出以下功能要求:
实现四个基本功能,-c返回指定文件字符数,-w返回指定文件单词数,-l返回指定文件行数,-o将输出保存到指定文件;
实现三个扩展功能,-s递归处理当前目录和子目录里所有符合要求的文件,-a返回三种不同类型行的数量,-e加入停用词表;
实现一个隐形功能,可同时处理多个功能要求。
step2:技术分析
为了实现上述功能,初步整理了可能需要用到的技术
文件读写操作 参考博客:http://blog.csdn.net/hu1991die/article/details/41010025
字符,字符串,文件行统计,参考博客:http://blog.csdn.net/ycy0706/article/details/45457311
http://blog.sina.com.cn/s/blog_a22b01580101czxu.html
递归寻找所有文件夹下符合条件的文件,参考资料:https://zhidao.baidu.com/question/54064551
正则表达式,参考资料:http://www.runoob.com/regexp/regexp-syntax.html
禁用词表,参考资料:https://zhidao.baidu.com/question/195369099.html?qq-pf-to=pcqq.group
4.程序设计实现过程:
周五开始规划,仔细分析过需求,并和室友讨论后,决定选用Java语言开发,出于个人习惯,最后还是做成了把所有函数都写在一个class里的样子,在实现过程中总共写了7个功能函数和2个附加函数,一个主函数,分别是计算行Lcount,计算单词Wcount,计算字符数Ccount,第二天写了获得所有符合条件的文件并且处理扩展函数Sfunc,高级行统计Afunc,禁用词表Efunc,第三天实现了文件写入writefunc,两个附加函数是统计空格数和统计标点符号数,到最后也没用上。
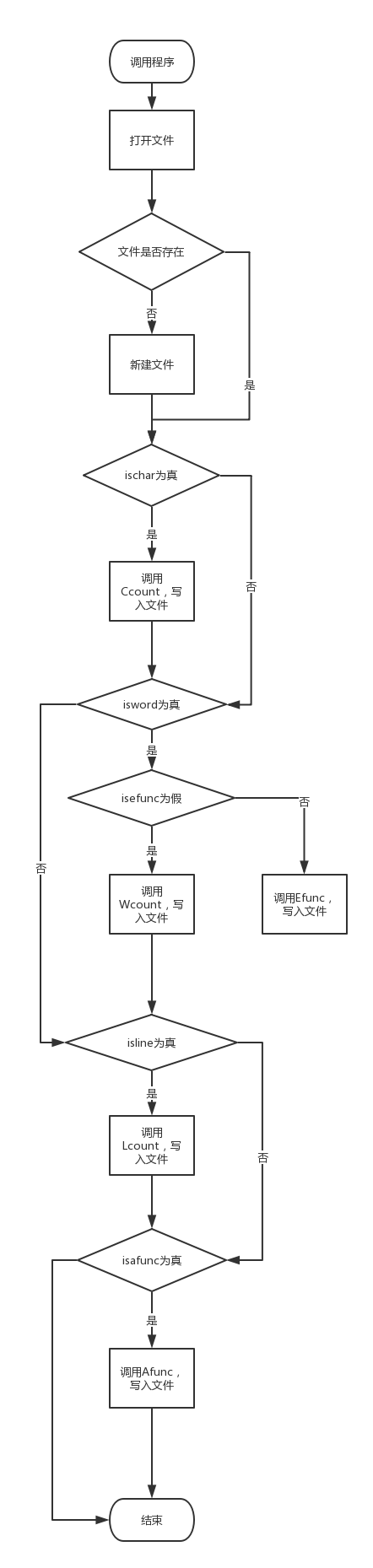
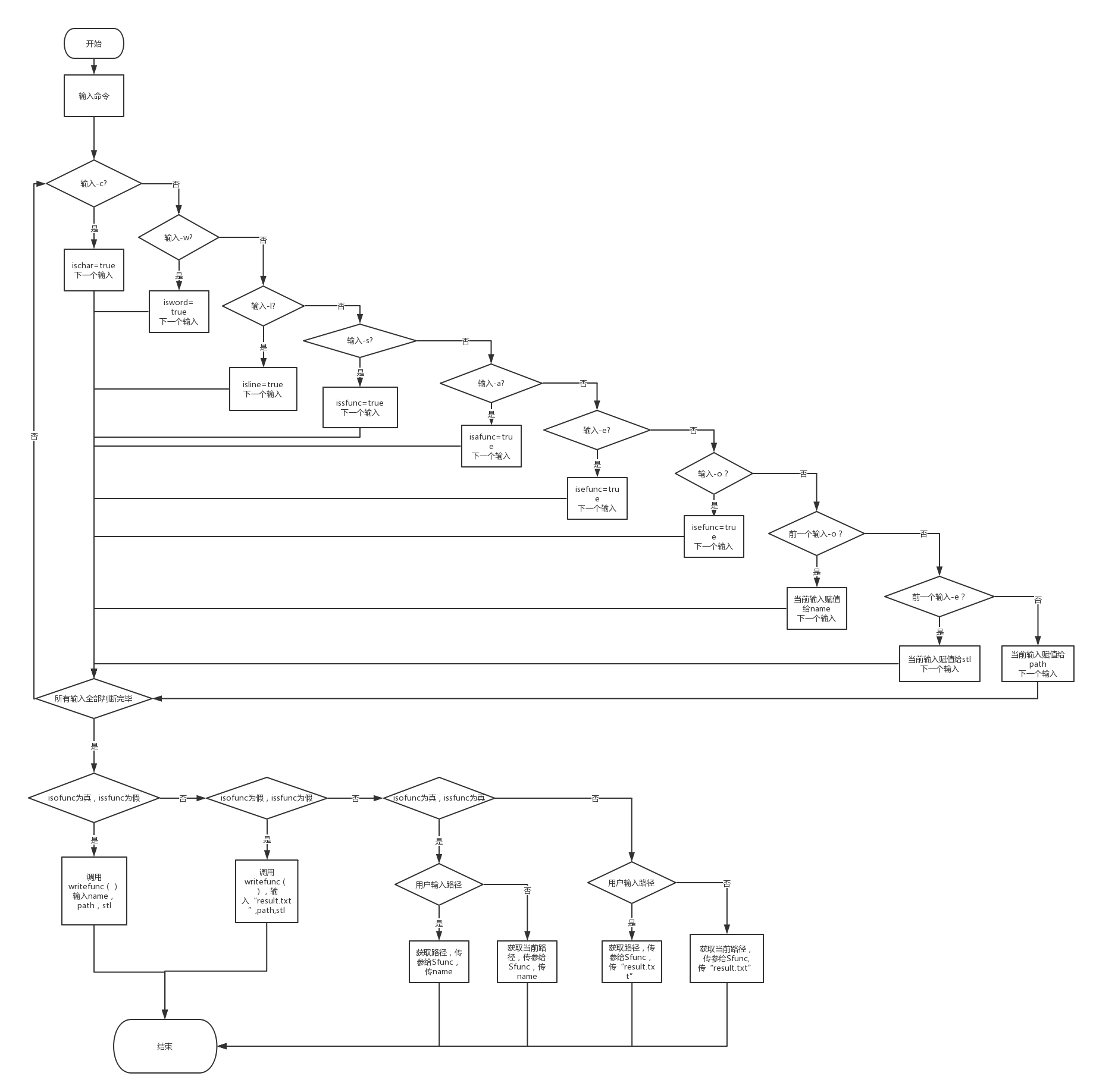
简单实现功能后开始组装,最初的想法是在主函数里挨个调用,并且没有写writefunc,而是直接在每个计算的函数里分别写了写入文件的方法,最后发现行不通,不仅会相互覆盖,也不能实现-o的功能,又是一番大改,加上了专门的写出writefunc,其中Lcount与Afunc同级,Wcount与Efunc同级,添加了一堆的bool值来判断某功能有没有被调用,统计函数也从void改成了int(Afunc是int[]),在writefunc里加入大量判断以实现正确输出,我将在第四部分结尾给出流程图。
具体到每个程序的实现上,三个基础功能实现起来很简单,没有任何难度,只是在wordcount上纠结了一下是统计所有分割字符还是用正则表达式分割计数(这也是加入两个附加函数的目的),最后选择了scanner类的useDelimiter()函数来分割文件行,三个扩展功能实现起来就很麻烦了,递归求文件用了网上的一个方法,逻辑也将在之后的流程图中给出。停用词表用了一个树状图,过滤出停用词生成树然后再比对,特殊行使用正则表达式,通过match每行与标准格式来计数,输出一个长度为3的数组。
writefunc流程图:
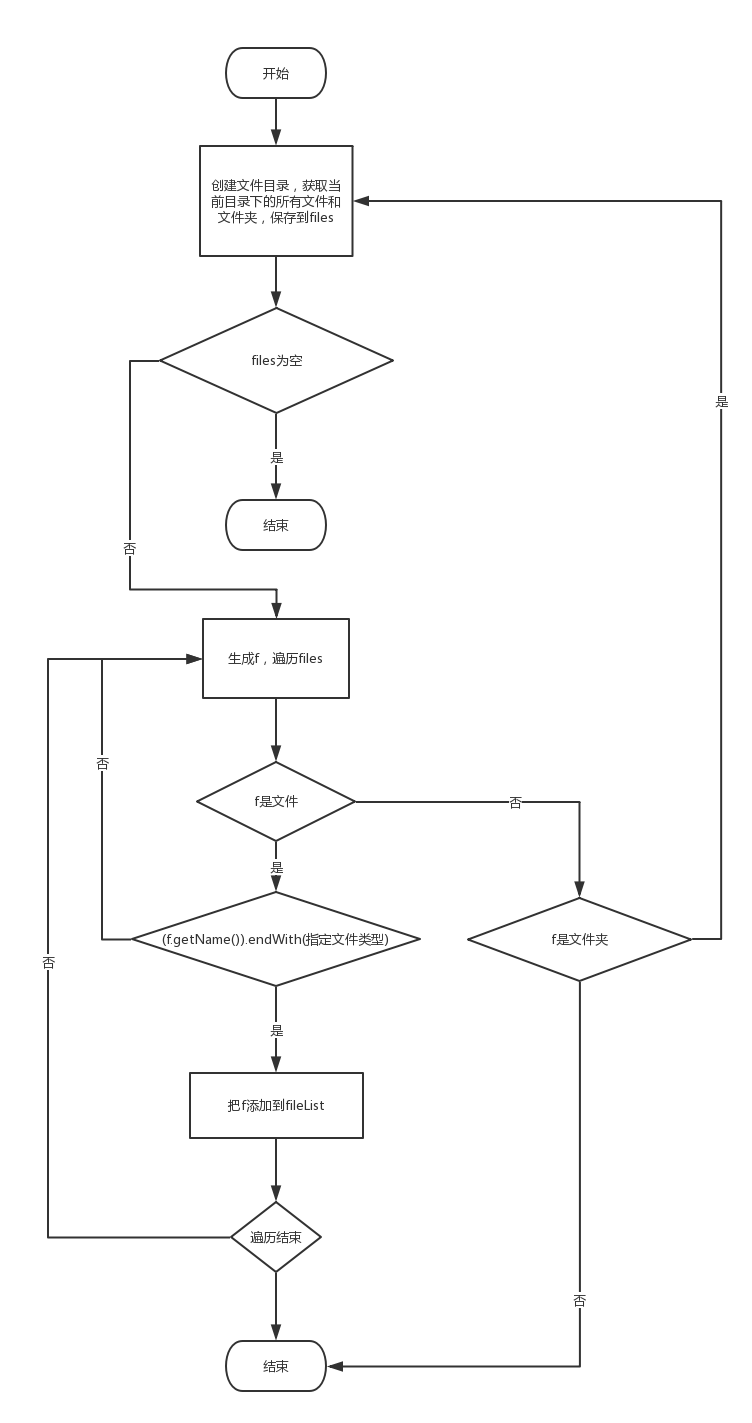
Sfunc流程图:
主函数流程图:
5.代码说明:
//扩展功能 //递归寻找所有文件 public static void Sfunc(String fileDir,String ftype,String filename,String stl) { List<File> fileList = new ArrayList<File>(); File file = new File(fileDir); File[] files = file.listFiles();// 获取目录下的所有文件或文件夹 if (files == null) {// 如果目录为空,直接退出 return; } // 遍历,目录下的所有文件,挑选所有合适的文件 for (File f : files) { if (f.isFile()) {//是文件,下一步判断 String fname = f.getName(); if(fname.endsWith(ftype)) {//后缀名合格,加入list fileList.add(f);} } else if (f.isDirectory()) { //是文件夹,递归求这个文件夹下的文件和文件夹 System.out.println(f.getAbsolutePath()); Sfunc(f.getAbsolutePath(),ftype,filename,stl); } } //继续处理,根据输入判断一下处理方式,没什么好说的 int m = fileList.size(); int i =0; while (i<m) { String path2 = (fileList.get(i)).getName(); if(isofunc) writefunc(filename,path2,stl); else writefunc("result.txt",path2,stl); } } //停用词表 public static int Efunc(String slt,String path) { int cnum=0; try { //读停用词表 InputStreamReader isr = new InputStreamReader(new FileInputStream(slt)); BufferedReader br = new BufferedReader(isr); String line = null; TreeMap<String,Integer> tm = new TreeMap<String,Integer>();//构建停用词树 //读取文件 while((line=br.readLine())!=null){ line.toLowerCase();//全小写 String str[] = line.split("\\s+|\\?+|\\.+|,+|,+");//分割停用词 for(String s: str) {//遍历 if(!tm.containsKey(s))//如果树里没有这个单词 { tm.put(s,1);//加进去 } } } br.close(); //读文件 InputStreamReader isr2 = new InputStreamReader(new FileInputStream(path)); BufferedReader br2 = new BufferedReader(isr2); String line2 = null; while((line2=br.readLine())!=null){ line2.toLowerCase(); String str[] = line2.split("\\s+|\\?+|\\.+|,+|,+");//分割处理文件单词 for(String s: str) { if(!tm.containsKey(s)){//如果这个单词不在屏蔽树表里 cnum++;//单词数++ } } } br2.close(); return cnum; }catch(IOException e) { e.printStackTrace(); return 0; } }
以上两个函数分别是递归寻找文件和屏蔽词表,简单解释一下屏蔽词函数:构建一个树来保存屏蔽词,再与需要处理的文件进行对比,最后输出统计词数量。整体实现起来不难,就是有点绕,而且还需要用到新的数据结构(TreeMap)
6.测试设计过程
最开始测试能否正常运行,只是运行,没有写入参数
wc.exe
单路径测试:
测试4个基本功能
wc.exe -c -w -l test.txt -o output.txt
分别测试三个扩展功能
wc.exe -s test.txt -c
wc.exe -e stop.txt test.txt
wc.exe -a test.txt
全路径测试
有停用词表的全路径测试
wc.exe -c -l -s -e stop.txt -a -o output.txt test.txt
没有停用词表的全路径测试
wc.exe -c -l -s -w -a -o output.txt test.txt
测试脚本swt.bat
wc.exe -c -s test.txt
wc.exe -l test.txt
wc.exe -w test.txt
wc.exe -o newfile.txt test.txt
wc.exe -s -e stop.txt -o.newfile1.txt -c test.txt -a
wc.exe -s -e stop.txt -o.newfile1.txt -c test.txt -a -l
从测试结果来看大部分都是正常的,有时会报空指针错。
资料整理
参考博客:http://blog.csdn.net/hu1991die/article/details/41010025
参考博客:http://blog.csdn.net/ycy0706/article/details/45457311
http://blog.sina.com.cn/s/blog_a22b01580101czxu.html
参考资料:https://zhidao.baidu.com/question/54064551
参考资料:http://www.runoob.com/regexp/regexp-syntax.html
参考资料:https://zhidao.baidu.com/question/195369099.html?qq-pf-to=pcqq.group
感谢百度百科,google对本程序的大力支持,引用太多就不一一列举了
