Wordcount
项目地址
https://github.com/lililili9761/wordcount
项目简介
本次WordCount程序编写语言为JAVA,开发平台为IntelliJ IDEA。实现了基础功能和拓展功能,统计对象包括所有类型的文本文件。
项目的需求描述如下:
编写一个Wordcount,其需求为:对程序设计语言源文件统计字符数、单词数、行数,统计结果以指定格式输出到默认文件中,以及其他扩展功能,并能够快速地处理多个文件。可执行程序命名为:wc.exe,存储统计结果的文件默认为result.txt,放在与wc.exe相同的目录下。
- 基本功能
wc.exe -c file.c //返回文件 file.c 的字符数 wc.exe -w file.c //返回文件 file.c 的单词总数 wc.exe -l file.c //返回文件 file.c 的总行数 wc.exe -o outputFile.txt //将结果输出到指定文件outputFile.txt
- 拓展功能
wc.exe -s //递归处理目录下符合条件的文件 wc.exe -a file.c //返回更复杂的数据(代码行 / 空行 / 注释行) wc.exe -e stopList.txt // 停用词表,统计文件单词总数时,不统计该表中的单词
- 高级功能
wc.exe -x //该参数单独使用,如果命令行有该参数,则程序会显示图形界面,用户可以通过界面选取单个文件,程序就会显示文件的字符数、单词数、行数等全部统计信息。
更详细的需求见http://www.cnblogs.com/ningjing-zhiyuan/p/8563562.html,在此不一一赘述。
PSP表格
|
PSP2.1 |
PSP阶段 |
预估耗时 (分钟) |
实际耗时 (分钟) |
|
Planning |
计划 |
20 |
15 |
|
· Estimate |
· 估计这个任务需要多少时间 |
20 |
15 |
|
Development |
开发 |
980 |
1455 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
30 |
90 |
|
· Design Spec |
· 生成设计文档 |
45 |
60 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
15 |
20 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
20 |
10 |
|
· Design |
· 具体设计 |
60 |
45 |
|
· Coding |
· 具体编码 |
720 |
1080 |
|
· Code Review |
· 代码复审 |
30 |
60 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
60 |
90 |
|
Reporting |
报告 |
100 |
130 |
|
· Test Report |
· 测试报告 |
60 |
90 |
|
· Size Measurement |
· 计算工作量 |
10 |
10 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
30 |
30 |
|
|
合计 |
1100 |
1600 |
解题思路
因为本身的代码能力不够好,对JAVA也不够熟悉,所以在进行这个项目之前我花了一个晚上的时间去温习大二时的《面向对象》的课本,了解一些JAVA基本知识。代码中大多数使用的函数都是边写边查,关于这些函数的使用我在代码中做了很详细的注释。整个项目所涉及到的知识我最先开始了解的是关于文件输入输出流和缓冲区的知识,然后了解了String类的各种方法,之后在写判断代码行/空行/注释行时,还粗浅地学习了正则表达式,所学所了解的甚多。
大致的思路就是边学边写,从对文件进行基本的统计,到解析用户输入的参数,到根据用户输入的参数将统计的结果进行输出,到递归处理目录得到符合要求的需要进行计数处理的文件列表,再到对文件进行更复杂的统计以及加入停用词文件、解析得到停用词列表并词表内容进行读取——先完成基本的技术功能,再一个个去完成拓展功能,这一点在我前后共八次的git commit的描述上可以体现。
程序设计实现过程
我的整个项目包含一个Filecount类,一个对文件中字符、单词、行、代码行、空行、注释行进行计数的Filecounter函数,一个递归处理文件夹中文件对其进行计数的allPath函数,一个处理输出的Output函数以及一个可以从控制台接受用户输入的指令并切换工作模式的主函数main。
下面分别对这三个函数和main函数进行简要说明:
- Filecounter(String path,int isstop,String[] Stoplist)
path是要进行计数的文件的路径,isstop是判断是否需要对停用表进行处理,Stoplist是将停用表文件中的停用词读取后用来存放停用词的字符串数组。
- allPath(String dir, String fileClass)
dir是文件夹或文件的路径,fileClass是需要进行递归处理的文件类型。
- Output(String[] args, Filecount counter, String buffer)
args是用户输入的参数,是一个字符串数组;counter是对文件进行计数的类的实例,buffer是输出缓冲区
- main(String[] args)
args是用户输入的参数,是一个字符串数组。main()函数从控制台接受用户输入的参数,并根据参数的不同控制一些变量不同,从而做出不同的处理。
详细的思路将在“代码说明”中解释。
代码说明
因为我本身不常写代码,所以写的过程中体会到了很多”想出可能在大神看来很稀松平常的思路“的乐趣,下面贴出一部分对我而言觉得思路很有意思的代码。(知道你们觉得很普通但我觉得非常有意思!不接受批评哼!)
代码说明我将代码的注释中进行(可以说是)逐字逐句的解释。
1 public void Filecounter(String path,int isstop,String[] Stoplist) throws IOException { 2 String str = ""; 3 FileInputStream fis = new FileInputStream(path);//打开文件输入流 4 InputStreamReader isr = new InputStreamReader(fis); 5 BufferedReader br = new BufferedReader(isr);//字符流写入缓冲区 6 String[] Strings = path.split("\\\\");//将文件路径按\\进行分词操作 7 Filename = Strings[Strings.length - 1]; 8 //文件路径分词后得到的字符串数组的最后一个是文件名,获取文件名以备输出 9 boolean note = false;//用于纪录/**/类型的注释的开始与结束 10 11 //readLine()每次读取一行,转化为字符串,br.readLine()为null时,不执行 12 while ((str = br.readLine()) != null) { 13 Charcount += str.length();//字符计数 14 str = str.trim();//用trim函数去除每一行第一个字符前的空格,以便之后所有的计数操作 15 String[] wordc = str.split(" |,");//根据需求按空格或逗号进行分词操作,将得到的单词放入一个字符串数组 16 Wordcount += wordc.length;//单词计数:字符串数组的长度就是单词的个数 17 //当需要对停词表中的词进行处理时 18 if(isstop == 1){ 19 for(String w : wordc){ 20 for(String words : Stoplist){ 21 //equalsIngnoreCase()与equal()不同,是不区分大小写的比较 22 if(w.equalsIgnoreCase(words)){ 23 Wordcount--;//如果Stoplist中的词与wordc中的词匹配,将单词数减一 24 } 25 } 26 } 27 } 28 Linecount++;//行计数 29 Charcount=Charcount+Linecount-1; 30 /* 31 这里是因为readLine()获得的一行不包括该行末尾的换行符 32 前面的Charcount仅仅计算了一行中除了换行符外的字符 33 在计算出行数后,由于最后一行不包含换行符,而前面所有行都包含换行符,所以做出这样的计算 34 */ 35 if(str.matches("//.*")){//正则表达式的使用 36 Notelinecount++; 37 } 38 else if(str.matches("^/\\*.*\\*/$")){ 39 Notelinecount++; 40 } 41 else if(note){ 42 Notelinecount++; 43 if(str.matches(".*\\*/$")){ 44 note=false; 45 } 46 } 47 else if(str.matches("^/\\*.*[^\\*/$]")){ 48 Notelinecount++; 49 note=true; 50 } 51 else if(!note&&(str.matches("[\\s&&[^\\n]]*"))||(str.matches("[{}]"))) 52 { 53 Spacelinecount++; 54 } 55 else{ 56 Codelinecount++; 57 } 58 59 } 60 isr.close(); 61 }
关于对注释行的判断有一个情况我想解释:当str匹配到“/*”时,note变量置为true并且注释行行数加一,接着读取下一行,此时note变量为true,注释行行数加一,循环进行下去,注释行行数不断增加直到str匹配到“*/”,note重新变为false,可以进行其他类型的行的计数操作。关于正则:http://www.jb51.net/tools/zhengze.html。
for(int i=0;i<args.length;i++){ if(!(Pattern.matches(configg,args[i]))){ if(args[i-1].equals("-e")){ Stoplistpath=args[i]; isstop=1; } if(args[i-1].equals("-o")){ outputpath=args[i]; changeoutput=1; } else{ path = args[i]; } } }
这是在main()函数里的一个循环代码的截取,其中configg是用于匹配“-字母”类型参数的正则表达式,args在前文已经提到过,是一个用户输入的参数构成的数组。当用户参数arg[i]与匹配“-字母”类型参数正则表达式不匹配时,说明此时的参数是一个类似于file.c、result.txt的参数。那么我们去寻找此用户参数的前一个用户参数arg[i-1](根据需求这个所谓的“前一个用户参数”一定是一个“-x”类型的参数),我们将args[i-1]分别与“-e”、“-o”进行匹配,若匹配成功那么arg[i]就是-s或者-o也就是停词表文件或者输出文件的路径,如果不匹配,那么arg[i]就是需要对其进行计数操作的文件路径。(关于其他参数的处理在Output()函数中也有进行)
if(isstop==1){ //打开文件输入流 FileInputStream stop = new FileInputStream(Stoplistpath); //字符流写入缓冲区 InputStreamReader Stopstream = new InputStreamReader(stop); BufferedReader Stopbuffer = new BufferedReader(Stopstream); String Stopstring=""; while((Stopstring=Stopbuffer.readLine())!=null){ Stoplist=Stopstring.split(" "); } }
这是获得Stoplist的操作。这段代码没有什么特别之处,贴出来仅仅是为了......赞叹一句split()真好用!
鉴于篇幅和时间原因不再贴出更多的代码进行解释,有兴趣的可以看代码中的注释。
测试设计过程
根据用户可能输入的各种不同指令,我们将可能的分支用流程图表示。

考虑在测试所有功能的基础上,覆盖程序的每一条可执行路径。
我设计了10个测试用例进行测试:
| 测试编号 | 测试内容 | 用户输入的指令 |
| 1 | 基本字符测试 | -c output.txt |
| 2 | 单词和行数测试 | -w -l Filecount.java |
| 3 | 拓展行数测试 | -a output.txt |
| 4 | 停用词测试 | -w -e stopList.txt Filecount.java |
| 5 | 递归测试 | -s -w -l -a E:\wordc\*.txt |
| 6 | 指定输出测试 | -s -w -l -c -a E:\wordc\*.txt -o output.txt |
| 7 | 全套测试 | -s -w -l -c -a -e stopList.txt E:\wordc\*.txt -o output.txt |
| 8 | 测试同时读取不同文件 | -c output.txt -w result.txt -l stopList.txt |
| 9 | 错误文件名测试 | -c wrong.c |
| 10 | 错误指令测试 | -b output.txt |
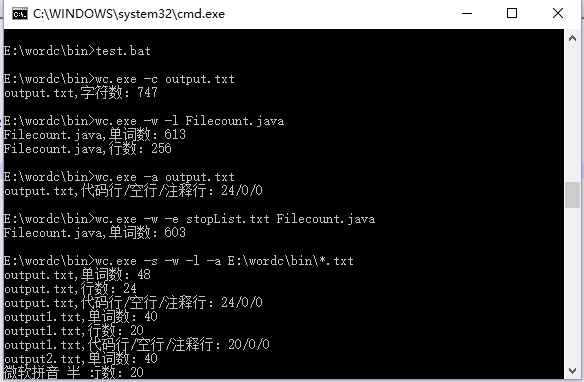
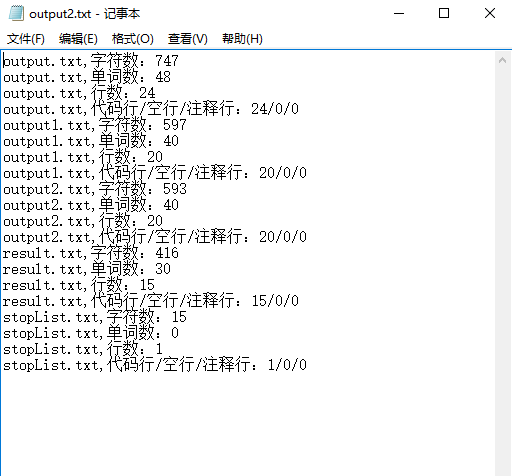
测试都是在cmd的命令行中进行。通过测试也找出了一些错误并已经修复。错误测试中程序也不会崩溃,一定的程度上反映了程序的健壮性。
此外在我bin目录下还放有一个test.bat脚本文件,里面包含了上述的十条指令,在cmd命令行该文件所在路径下输入test.bat即可逐条输出测试的结果,方便批量测试与输出。
参考链接
- http://www.jb51.net/tools/zhengze.html 正则表达式
- http://blog.csdn.net/chaoyueygw/article/details/53466887java 递归读取目录文件
- http://www.cnblogs.com/DM-Star/p/8597100.html 测试用例图片来源
- http://blog.csdn.net/honjane/article/details/40739337 使用IDEA生成可执行文件jar,转为exe文件
- https://www.cnblogs.com/hahaccy/p/8047003.html JAVA file I/O
-
http://www.cnblogs.com/June-c/p/8612418.html test.bat的编写灵感
