爬取全部校园新闻
作业要求:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3002
0.从新闻url获取点击次数,并整理成函数
- newsUrl
- newsId(re.search())
- clickUrl(str.format())
- requests.get(clickUrl)
- re.search()/.split()
- str.lstrip(),str.rstrip()
- int
- 整理成函数
- 获取新闻发布时间及类型转换也整理成函数
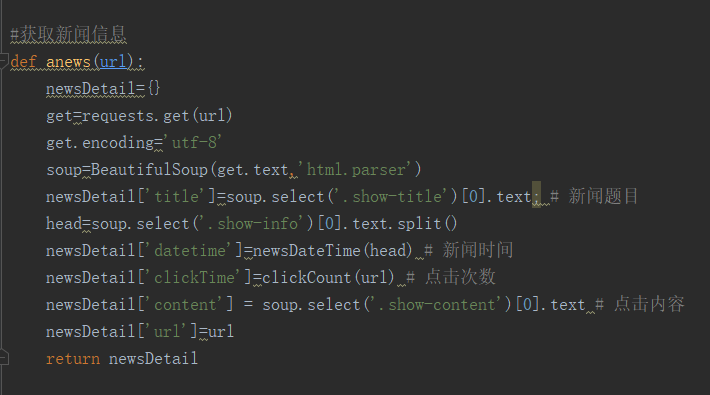
1.从新闻url获取新闻详情: 字典,anews
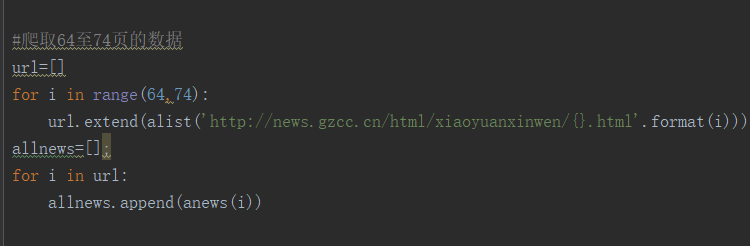
2.从列表页的url获取新闻url:列表append(字典) alist

3.生成所页列表页的url并获取全部新闻 :列表extend(列表) allnews
*每个同学爬学号尾数开始的10个列表页
4.设置合理的爬取间隔
import time
import random
time.sleep(random.random()*3)

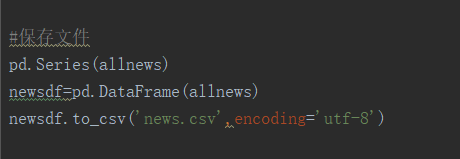
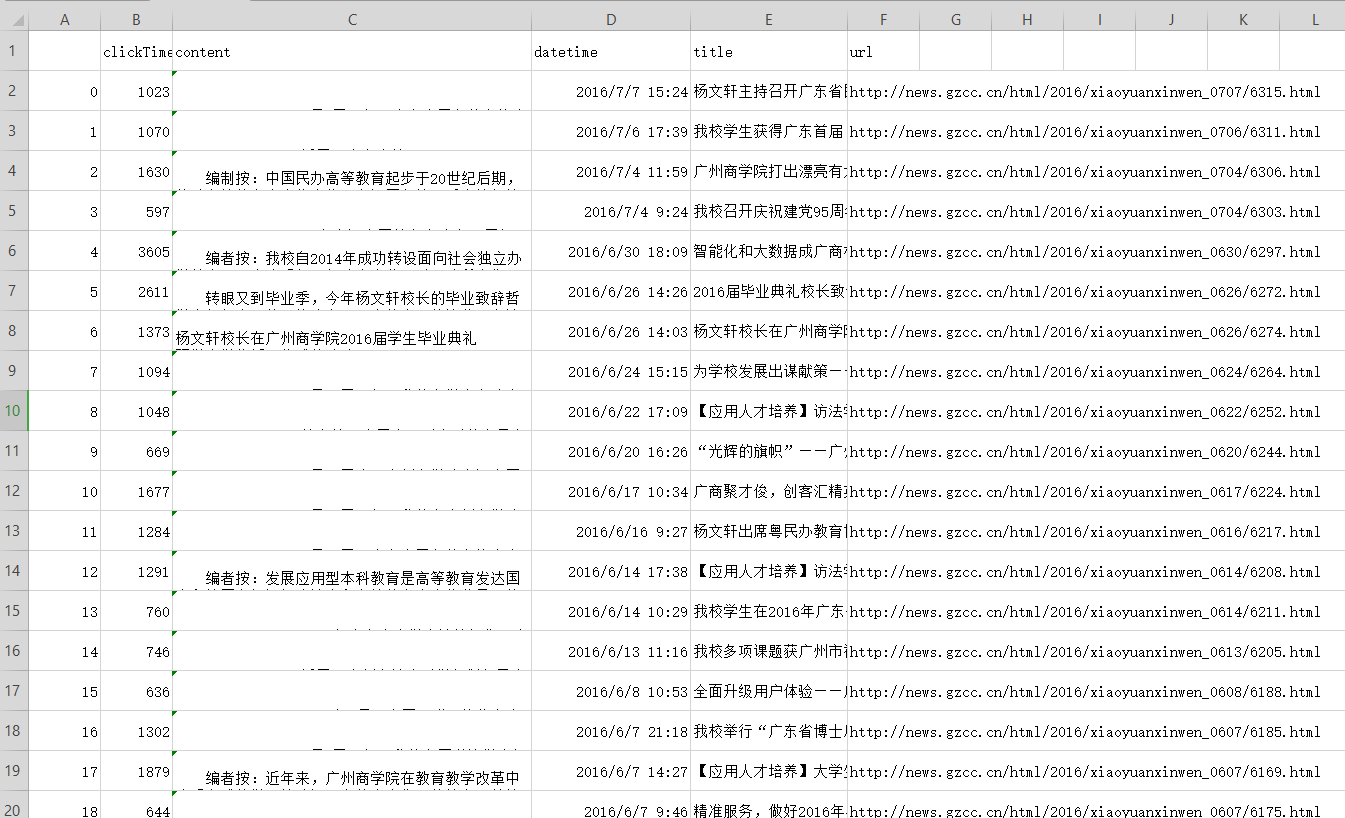
5.用pandas做简单的数据处理并保存
保存到csv或excel文件
newsdf.to_csv(r'F:\duym\爬虫\gzccnews.csv')