

rabbitmq集群
参考:https://www.cnblogs.com/knowledgesea/p/6535766.html
考虑 rabbitmq 的高可用性,我们需要给 RabbitMQ 搭建集群环境。
一、rabbitmq 有3种模式,集群模式是2种。
1. 单一模式:即单机情况不做集群,就单独运行一个 rabbitmq
2. 普通模式:默认模式,以两个节点(rabbit01、rabbit02)为例来说明。对于 queue 来说,消息实体只存在于其中一个节点,rabbit01 和 rabbit02 两个节点仅有相同的元数据,及队列的结构。当消息进入 rabbit01 节点的 queue 后,consumer 从 rabbit02 节点消费时,RabbitMQ 会临时在 rabbit01、rabbit02 间进行消息传输,把 A 中的消息实体取出并经过 B 发送给 consumer。所以 consumer 应尽量连接每一个节点,从中取消息。即对于同一个逻辑队列,要在多个节点建立物理 queue。否则无论 consumer 连 rabbit01 或者 rabbit02,出口总在 rabbit01,会产生瓶颈。当 rabbit01 节点故障后,rabbit02 节点无法取到 rabbit01 节点中还未消费的消息实体。如果做了消息持久化,那么等rabbit01 节点恢复,然后才可被消费;如果没有持久化,就会产生消息丢失的现象。
3. 镜像模式:把需要的队列做成镜像队列,与多个节点属于 RabbitMQ 的 HA 方案。该模式解决了普通模式中的问题,其实质和普通模式不同之处在于,消息实体会主动在镜像节点间同步,而不是在客户端取数据时临时拉取。该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。所以在对可靠性要求较高的场合中适用。
二、搭建 RabbitMQ 的普通模式集群
1. 环境准备
1)两台 CentOS7 的机器(cat /etc/redhat-release),hostname 分别是:
cat /etc/hosts

保证两台机器都能互相 ping 通。
2. 分别在两个机器上安装 rabbitmq
/usr/lib/rabbitmq/bin
安装成功后有些常用操作
./rabbitmq-server -deched --后台启动服务
./rabbitmqctl start_app --启动服务
./rabbitmqctl stop_app --关闭服务
./rabbitmq-plugins enable rabbitmq_management --启动web管理插件
./rabbitmqctl add_user zlh zlh --添加用户,密码
./rabbitmqctl set_user_tags zlh administrator --设置zlh为admin权限
3. 设置 .erlang.cookie
RabbitMQ 的集群是依赖 erlang 集群,而 erlang 集群是通过这个 cookie 进行通信认证的,因此,我们做集群第一步就是修改 cookie。
在 $HOME 或者 /var/lib/rabbitmq 中,文件名称为 .erlang.cookie,他是一个隐藏文件。修改两个机器中的 .erlang.cookie 文件中 cookie 值一致,且权限为 owner 只读。
chmod 600 .erlang.cookie
4. 查看集群状态,我的已经做好了

5. 常用命令
1)停止当前机器中 rabbitmq 服务
./rabbitmqctl stop_app
2)加入集群
./rabbitmqctl join_cluster --ram rabbit@mini2
3)开启当前机器的 rabbitmq 服务
./rabbitmqctl start_app
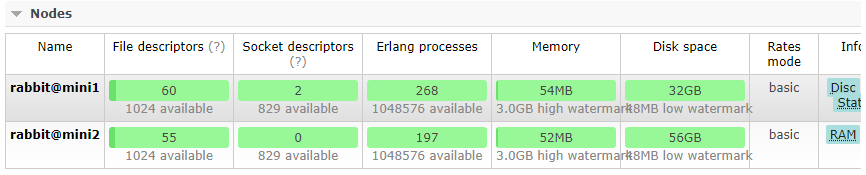
6. 打开网页查看 nodes
三、搭建 rabbitmq 的镜像高可用模式集群
镜像模式要依赖 policy 模块。
policy 中文是政策,策略的意思,那么他就是要设置,哪些 exchanges 或者 queue 的数据需要复制同步,如何复制同步。
./rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
参数意思为:
ha-all:策略名称
^:匹配符。只有一个 ^ 代表匹配所有,^zl 为匹配名称为 zl 的 exchanges 或者 queue
ha-mode:为匹配类型,分为3种模式:all- 所有 queue,exctly- 部分(需配置 ha-params参数,此参数为 int 类型,比如 3,众多集群中的随机 3 台机器),node- 指定(需配置 ha-params参数,此参数为数组类型,比如 ["rabbit@mini1","rabbit@mini2"] 这样指定为 F与G这 2 台机器)。
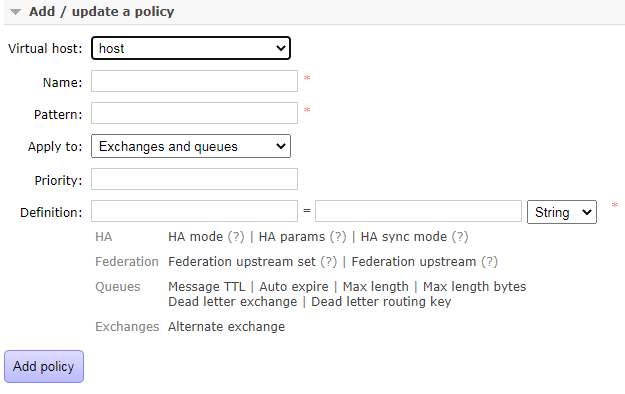
在 web 管理界面也能配置

 浙公网安备 33010602011771号
浙公网安备 33010602011771号