


RabbitMQ
摘抄自网上仅用于自己学习
引言
消息服务擅长于解决多系统、异构系统间的数据交互(消息通知 / 通讯)问题,你也可以把它用于系统间服务的相互调用(RPC)。
RabbitMQ 简介
AMQP,即 Advanced Message Queueing Protocal,高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。消息中间件主要用于组件之间的解耦,消息的发送者无需知道消息使用者的存在,反之亦然。
AMQP 的主要特征是面向消息、队列、路由(包括点对点和发布订阅)、可靠性、安全。
RabbitMQ 是一个开源的 AMQP 实现,服务器端使用 erlang 语言编写,支持多种客户端,如:Python、Ruby、.NET、Java、JMS、C、PHP。。等,支持 AJAX。用于在分布式系统中存储转发消息,在易用性、扩展性、高可靠性方面表现好。
ConnectionFactory、Connection、Channel
ConnectionFactory、Connection、Channel 都是 RabbitMQ 对外提供的 API 中最基本的对象。Connection 是 RabbitMQ 的 socket 连接,它封装了 socket 协议相关部分逻辑。ConnectFactory 为 Connection 的制造工厂。
Channel 虚拟连接。它建立在TCP连接中,数据流动都是在 Channel 中进行的,是我们与 RabbitMQ 打交道的最重要的一个接口,我们大部分的业务操作是在 Channel 这个接口中完成的,包括 定义 Queue、定义 Exchange、绑定 Queue 与 Exchange、发布消息等。
那么,为什么使用 Channel,而不直接使用 TCP 连接?
对于 OS 来说,建立和关闭 TCP 连接是有代价的,频繁的建立关闭 TCP 连接对于系统的性能有很大的影响,而且 TCP 的连接也有限制,这也限制了系统处理高并发的能力。但是,在 TCP 连接中建立 Channel 是没有上述代价的。对于 Producer 或者 Consumer 来说,可以并发的使用多个 Channel 进行 publish 或者 receive。有实验表明,1s 时间可以 publish 10K 的数据包。这个结果,对于不同的硬件环境,这个数据不一样,但是,对于普通的 Consumer 或则 Producer 已经足够。
Queue
Queue(队列)是 RabbitMQ 的内部对象,用于存储消息。
RabbitMQ 中的消息都只能存储在 Queue 中,生产者生产消息并最终投递到 Queue 中,消费者可以从 Queue 中获取消息并消费。
多个消费者可以订阅同一个 Queue,这时 Queue 中的消息会被平均分摊给多个消费者进行处理,而不是每个消费者都收到消息并处理。
Message acknowledgement
在实际应用中,可能会发生消费者收到 Queue 中的消息,但没有处理完成就宕机(或者出现其他意外)的情况,这种情况下就会导致消息丢失。为了避免这种情况的发生,我们可以要求消费者在消费完消息后发送一个回执给 RabbitMQ,RabbitMQ 收到消息回执(Message acknowledgement)后才将该消息从 Queue 中移除;如果 RabbitMQ 没有收到回执并检测到消费者的 RabbitMQ 连接断开,则 RabbitMQ 会将该消息发送给其他的消费者(如果有多个消费者)进行处理。这里没有 timeout 的概念,一个消费者处理消息时间再长也不会导致该消息被发送给其他消费者,除非它的 RabbitMQ 连接断开。
这里会产生另外一个问题,如果我们的开发人员在处理完业务逻辑后,忘记发送回执给 RabbitMQ,这将会导致严重的 Bug —— Queue 中堆积的消息会越来越多,消费者重启后,会重复消费这些消息并重复执行业务逻辑。。。
Message durability
如果我们希望即使在 RabbitMQ 服务重启的情况下,也不会丢失信息,我们可以将 Queue 与 Message 都设置为可持久化的(durable),这样可以保证绝大部分情况下我们的 RabbitMQ 消息不会丢失。但依然解决不了小概率丢失事件的发生(比如,RabbitMQ 服务器已经接收到生产者的消息,但还没来得及持久化该消息时 RabbitMQ 服务器就断电了。。),如果我们需要对这种小概率事件也要管理起来,那么我们要用到事务。
Prefetch count
前面我们讲到如果有多个消费者同时订阅同一个 Queue 的消息,Queue 中的消息会被平摊给多个消费者。这时,如果每个消息的处理时间不同,就有可能会导致某些消费者一直在忙,而另外一些消费者很快就处理完手头工作并一直空闲的情况。我们可以通过设置 prefetchCount 来限制 Queue 每次发送给每个消费者的消息数,比如我们设置 prefetchCount=1,则 Queue 每次给每个消费者发送一条消息;消费者处理完这条消息后 Queue 会再给该消费者发送一个消息。
当 RabbitMQ 要将队列中的一条消息投递给消费者时,会遍历该队列上的消费者列表,选一个合适的消费者,然后将消息投递出去。其中,挑选消费者的一个依据就是看消费者对应的 channel 上为 ack 的消息数是否达到设置的 prefetch_count 个数,如果未 ack 的消息数达到了 prefetch_count 的个数,则不符合要求。当挑选到合适的消费者后,中断后续的遍历。
Exchange
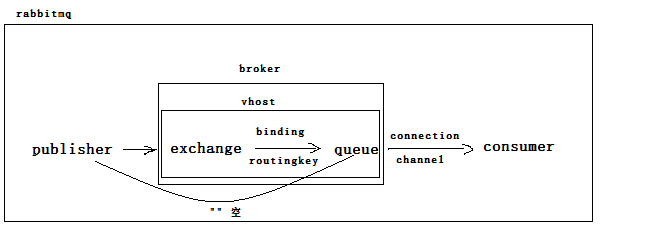
在前面有写消息投递到 Queue 中,实际上这在 RabbitMQ 中永远也不会发生。实际的情况是,生产者将消息发送到 Exchange(交换器),由 Exchange 将消息路由到一个或多个 Queue(或者丢弃)。
Exchange 是按照什么逻辑将消息路由到 Queue 的,在 Binding 一节中介绍。
RabbitMQ 中的 Exchange 有四种类型,不同的类型有不同的路由策略。
routing key
生产者在将消息发送给 Exchange 的时候,一般会指定一个 routing key,来指定这个消息的路由规则,而这个 routing key 需要在与 Exchange Type 及 binding key 联合使用才能最终生效。
在 Exchange Type 与 binding key 固定的情况下(正常使用时,这些内容都是固定配置好的),我们的生产者就可以在发送消息给 Exchange 时,通过指定 routing key 来决定消息流向哪里。
RabbitMQ 为 routing key 设定的长度限制为 255 bytes。
Binding
RabbitMQ 中通过 Binding 将 Exchange 与 Queue 关联起来,这样 RabbitMQ 就知道如何正确地将消息路由到指定的 Queue 了。
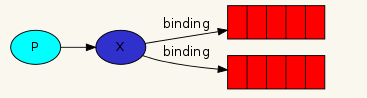
Binding key
在绑定(Binding)Exchange 与 Queue 的同时,一般会指定一个 Binding key;生产者将消息发送给 Exchange 时,一般会指定一个 routing key;当 binding key 与 routing key 相匹配时,消息将会被路由到对应的 Queue 中。这个将在 Exchange Type 章节说明。
在绑定多个 Queue 到同一个 Exchange 的时候,这些Binding 允许使用相同的 binding key。
binding key 不是在所有的情况下都生效,它依赖于 Exchange Type,比如 fanout 类型的 Exchange 就会无视 binding key,而是将消息路由到所有绑定到该 Exchange 的 Queue。
Exchange Types
RabbitMQ 常用的 Exchange Type 有 fanout、direct、topic、headers 这四种(AMQP规范里还提到两种分别是 system 与 自定义,这里忽略)。
fanout
faout 类型的 Exchange 路由规则非常简单,它会把所有发送到该 Exchange 的消息路由到所有与它绑定的 Queue 中。
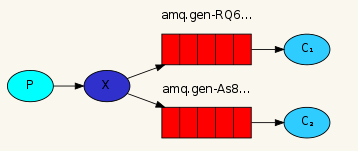
上图中,生产者(P)发送到 Exchange(X)的所有消息都会路由到图中的两个 Queue ,并最终被两个消费者(C1 和 C2)消费。
direct
direct 类型的 Exchange 路由规则也很简单,它会把那些 binding key 与 routing key 完全匹配的 Queue 中。
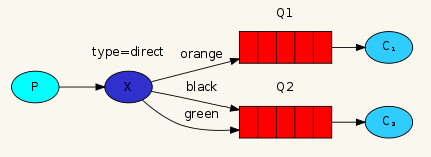
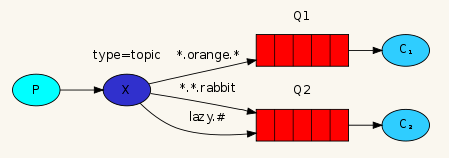
topic
与 direct 类型的Exchange 路由规则相比,topic 类型的 Exchange 在匹配规则上进行了扩展,他约定:
- routing key 为一个句点号 “ . ” 分隔的字符串,如 "topic.man"、"topic.woman"
- binding key 与 routing key 一样也是句点号 “ . ” 分隔的字符串
- binding key 中可以存在两种特殊字符 " * " 和 " # ",用于做模糊匹配,其中 " * " 用于匹配一个单词, " # " 用于匹配多个单词(可以是 0 个)
headers
headers 类型的 Exchange 不依赖于 routing key 与 binding key 的匹配规则来路由消息,而是根据发送的消息内容中的 headers 属性进行匹配。
在绑定 Queue 与 Exchange 时指定一组键值对;当消息发送到 Exchange 时, RabbitMQ 会取到该消息的 headers(也是一个键值对的形式),对比其中的键值对是否完全匹配 Queue 与 Exchange 绑定时指定的键值对;如果完全匹配则消息会路由到该 Queue,否则不会路由到该 Queue 。
RPC
MQ 本身是基于异步的消息处理,前面的示例中所有的生产者(P)将消息发送到 RabbitMQ 后不会知道消费者(C)处理成功或者失败(甚至有没有消费者来处理这条消息都不知道)。但实际的应用场景中,我们很可能需要一些同步处理,需要同步等待服务端将我的消息处理完成后再进行下一步的处理。这相当于 RPC(Remote Procedure Call,远程过程调用)。在 RabbitMQ 中也支持 RPC。
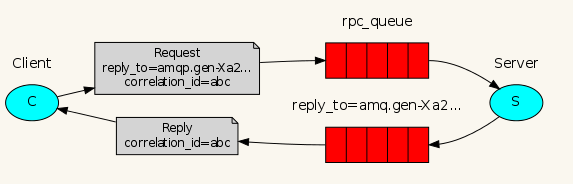
RabbitMQ 中实现 RPC 的机制是:
- 客户端发送请求(消息)时,在消息的属性(MessageProperties,在 AMQP 协议中定义了 14 种的 properties,这些属性会随着消息一起发送)中设置两个值 replyTo(一个 Queue 的名称,用于告诉服务器处理完成后将通知我的消息发送到这个 Queue 中)和 CorrelationId(此次请求的标识号,服务器处理完成后需要将此属性返还,客户端将根据这个 id 了解哪条请求被成功执行了或执行失败)
- 服务器端收到消息并处理
- 服务器端处理完消息后,将生成一条应答消息到 replyTo 指定的 Queue,同时带上 correlationId 属性
- 客户端之前已订阅 replyTo 指定的 Queue,从中收到服务器的应答消息后,根据其中的 correlationId 属性分析哪条请求被执行了,根据执行结果进行后续业务处理
https://www.cnblogs.com/williamjie/p/9481774.html
