



JUC之ConcurrentHashMap
在多线程下,使用 HashMap 进行 put 操作,插入的元素超过了容量(由负载因子决定)范围就会触发扩容操作,就是 rehash,这个会重新将原数组的内容重新 hash 到新的扩容数组中,在多线程的环境下,同时存在其他的元素也在进行 put 操作,如果 hash 值相同,可能出现同时在同一数组下用链表表示,造成闭环,导致在 get 时出现死循环,所以 HashMap 是线程不安全的。
HashTable 是线程安全的,他在所有涉及到多线程操作的地方都加上了 Synchronized 关键字来锁住整个 table,这就意味着所有的线程都在竞争一把锁,在多线程的环境下,他是安全的,但却是效率低下的。
ConcurrentHashMap
在 jdk1.7 的版本中,ConcurrentHashMap 是由一个 Segment 数组和多个 HashEntry 组成。

Segment 数组的意义就是将一个大的 table 分割成多个小的 table 来进行加锁,也就是锁分离技术,而每一个 Segment 元素存储的是 HashEntry 数组 + 链表,这个和 HashMap 的数据结构一样。
JDK1.8 的实现已经摒弃了 Segment 的概念,而是直接用 Node 数组+链表+红黑树 的数据结构来实现,并发控制使用 Synchronized 和 CAS 来操作,整个看起来就像是优化过且线程安全的 HashMap,虽然在 JDK1.8 中还能看到 Segment 的数据结构,但是已经简化了属性,只为兼容旧版本。 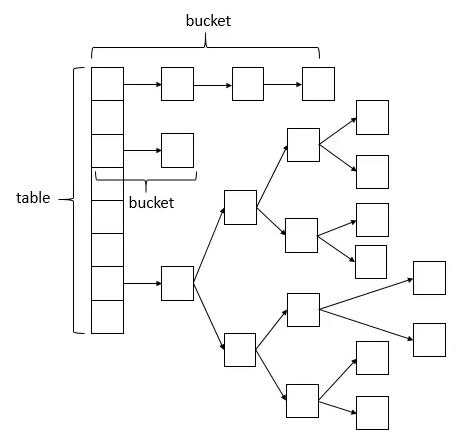
说明:ConcurrentHashMap 的数据结构(数组+链表+红黑树),桶中的结构可能是链表,也可能是红黑树,红黑树是为了提高查找效率。
Node:链表,只允许对数据进行查找,不允许进行修改。
TreeNode:继承自 Node,但是数据结构换成了二叉树结构,是红黑树的数据存储结构,用于红黑树中存储数据,当链表的节点数大于 8 时会转换成红黑树的结构,通过 TreeNode 作为存储结构代替 Node 来转换成红黑树。
总结:
JDK1.8 版本的 ConcurrentHashMap 的数据结构已经接近 HashMap,相对而言,ConcurrentHashMap 只是增加了同步的操作来控制并发,从 JDK1.7 版本的 ReentrantLock + Segment + HashEntry,到 JDK1.8 版本中 Synchronized + CAS + HashEntry + 红黑树,相比较而言:
1)JDK1.8 的实现降低锁的粒度,JDK1.7 版本锁的粒度是基于 Segment 的,包含多个 HashEntry,而 JDK1.8 锁的粒度就是 HashEntry(首节点)
2)JDK1.8 版本的数据结构变得更加简单,使得操作也更加清晰流畅,因为已经使用 Synchronized 来进行同步,所以不需要分段锁的概念,也就不需要 Segment 这种数据结构了(分段树,区间树),由于粒度的降低,实现的复杂度也增加了
3)JDK1.8 使用红黑树来优化链表,基于长度很长的链表的遍历是一个很漫长的过程,而红黑树的遍历效率很高,代替一定阈值的链表,加快检索速度
4)JDK1.8 使用内置锁 Synchronized 来代替重入锁 ReentrantLock 的原因:
因为粒度降低了,在相对而言的低粒度加锁方式上,Synchronized 并不比 ReentrantLock 差,在粗粒度加锁中 ReentrantLock 可能通过 Condition 来控制低粒度的边界,更加的灵活,而在低粒度中,Condition 的优势就没有了
JVM 的开发团队从没放弃过 Synchronized,而且基于 JVM 的 Synchronized 优化空间更大,使用内嵌的关键字比使用 API 更加自然
在大量的数据操作下,对于 JVM 的内存压力,基于 API 的 ReentrantLock 会开销更多的内存,虽不是瓶颈,也是选择的一个依据。

