数据结构与算法小结——排序(六)
3.2 快速排序
快速排序综合性能优越,其主要思想在于找一个pivotvalue,通过不断的比较、交换,将序列变成pivotvalue前的值都比它小,在其后的值都比它大;然后,再对pivotvalue前面的序列和后面的序列分别使用同样的方法得到具有该性质的序列.....不断递归调用至最底层即排好序。其基本流程如图 1所示。
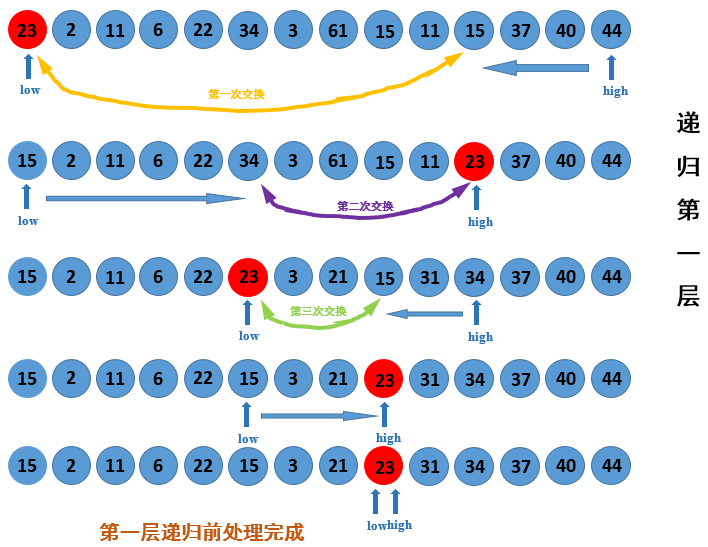
图 1 快速排序基本流程
分析快速排序的时间复杂度,可以画出一个二叉树,二叉树的结点即是每一层递归选用的pivotvalue。显然,如果pivotvalue选择得当,使得递归调用的二叉树为完全二叉树,则树的深度为lgn,快速排序的时间复杂度是O(nlgn)。但如果pivotvalue的值选的不好,在最坏的情况下,递归调用成了线性表,则树的深度为n,快排的时间复杂度为n2。
所以,快排的性能很大程度上取决于pivotvalue的选取,原则应尽量使得pivotvalue为待排序的中间值。上面介绍的是选择顺序表第一个元素作为pivotvalue,更好的做法是三数取中法,即去a[low]、a[high]以及a[(high+low)/2]三者中的中间值作为枢轴pivotvalue,这样它成为待排序列中间值的概率会大很多。
另外一处可以优化的地方是,从图中可以发现,在递归前处理中做了很多的交换,但可以发现,由于high和low的不断向中间靠拢,比较完后的值不会在参与本层递归的比较了,所以可以采取替换代替交换的方法,直接替换原来待交换的位置的值为交换以后的值即可。
分析快速排序算法的空间复杂度,由于用了递归,需开辟栈空间,栈空间的大小即为二叉树的深度,根据上述分析可知,快排空间复杂度为O(lgn~n)。
快排由于跳跃着交换位置,是一种不稳定的排序算法。
总结快速排序的时间、空间复杂度,稳定性以及适用场合如图 2。
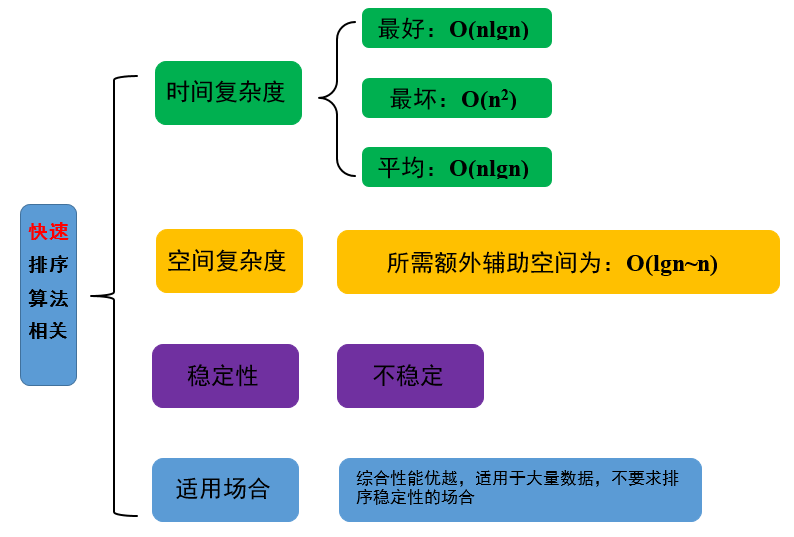
图 2 快速排序算法相关
最后,快速排序用了递归,归并排序也有递归的算法,我想了一下它俩的区别。
快速排序和归并排序的区别在于,归并排序通过递归分别将前一半和后一半排好序以后,整个序列还不是有序的,需要重新循环进行一个排序的步骤;但快速排序由于设置了pivotvalue,通过来回交换,已经使得前一步的所有值小于后一半的所有值了,所以分别递归排好了前一半和后一半,整个序列就是有序的了。简单来说就是,快速排序进行了递归的前处理,归并排序则进行了递归的后处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号