
线性表的链式存储
线性表的链式存储
1 链式存储
在一个数据结构中,如果一个结点有多个前驱或后继时,使用顺序存储就比较麻烦,即使是线性结构,如果没有足够大的存储空间供使用,也是无法实现的。这时就可以使用链式下存储,在这种存储方式下,除了存放一个结点的信息外,还需附设指针,用指针来体现结点之间的逻辑关系,如果有多个前驱和后继,就可附设相应个数的指针,指针指向的就是这个结点的前驱和后继。
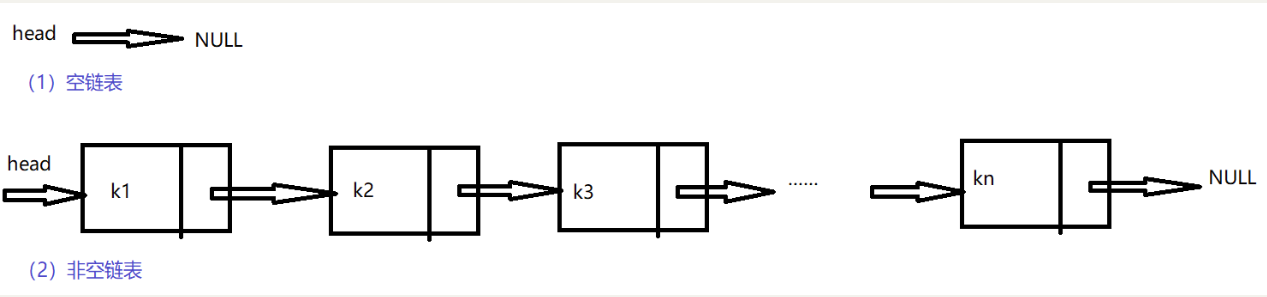
在线性结构中,每个结点最多只有一个前驱和后继,这里只关心它的后继(单向不循环链表),除放该结点的信息之外,还存放一个指针指向它的后继.

info字段存放该结点的数据信息,next字段是指针,存放后继结点的存放地址,线性表的最后一个结点没有后继,指向NULL。

在这种存储方式下,必须有一个指针指向第一个结点的位置,一般用head来表示。
2 单链表(不带头)
2.1 基本概念及描述
单链表是线性表存储的一种形式,结点一般有两个域,info和next,同时要有head。
2.2 实现
创建一个链表从一个空链表开始,不断插入新的结点,知道head就可以找到第一个结点,再根据指针域找到它的后继结点,依次类推,找到所有的结点,知道遇到一个结点的指针域为空。
typedef int datatype;
typedef struct link_node
{
datatype info;
struct link_node* next;
}node;
node* Init();
node* Destroy();
void display(node* head);
node *Find(node* head, int i);
node* Insert(node* head, datatype x, int pos);
node* Dele(node* head, datatype x);
(1)初始化和销毁
node* Init()
{
return NULL;
}
void Destroy(node*head)
{
free(head);
head = NULL;
}
(2)打印链表各结点的值
void display(node* head)
{
node* p = head;
if (!p)
{
printf("单链表是空的!!!\n");
}
else
{
while (p)
{
printf("%d ", p->info);
p = p->next;
}
printf("\n");
}
}
(3)查找链表第i个结点,返回地址
单链表不同于顺序表,不能随机访问某个结点,必须从头开始遍历
node *Find(node* head, int i)
{
node* p = head;
int j = 1;
if (i < 1) return NULL;
while (p && i != j)
{
p = p->next;
j++;
}
return p;
}
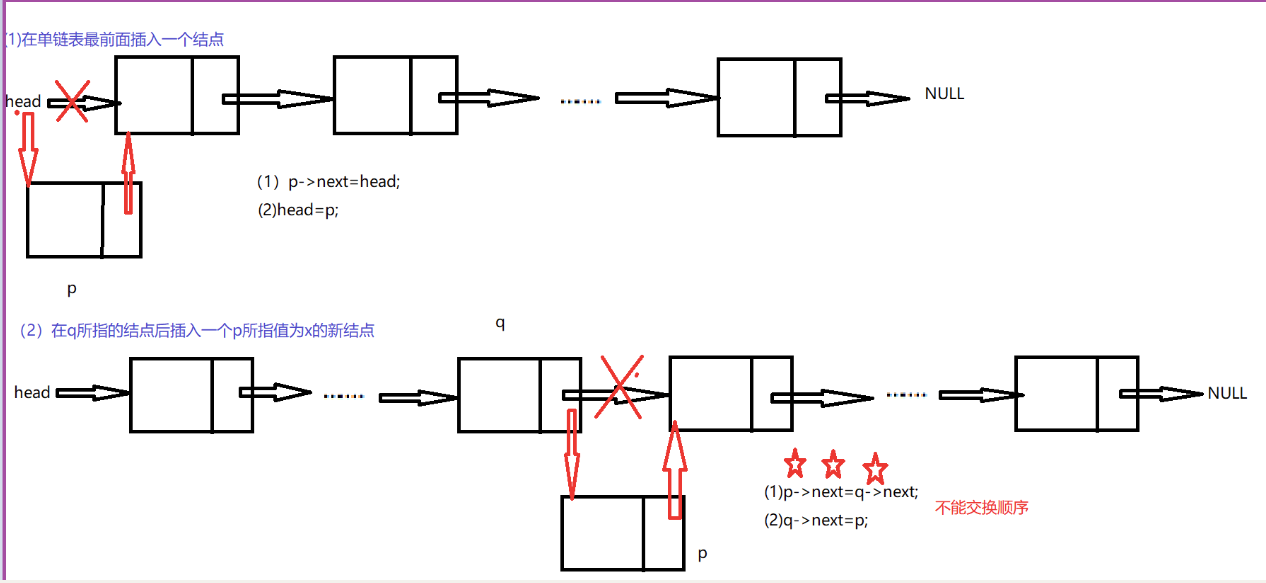
(4)插入
将新结点p插入到q结点的后面,插入到链表的最前面要做特殊处理
node* Insert(node* head, datatype x, int i)
{
node* p, * q;
q = Find(head, i);
//存在第i个结点
if (!q && i != 0)
printf("没有找到第i个结点!!!");
else
{
p = (node*)malloc(sizeof(node));
p->info = x;
//插入的结点作为第一个结点
if (i == 0)
{
p->next = head;
head = p;
}
else
{
p->next = q->next;
q->next = p;
}
}
return head;
}
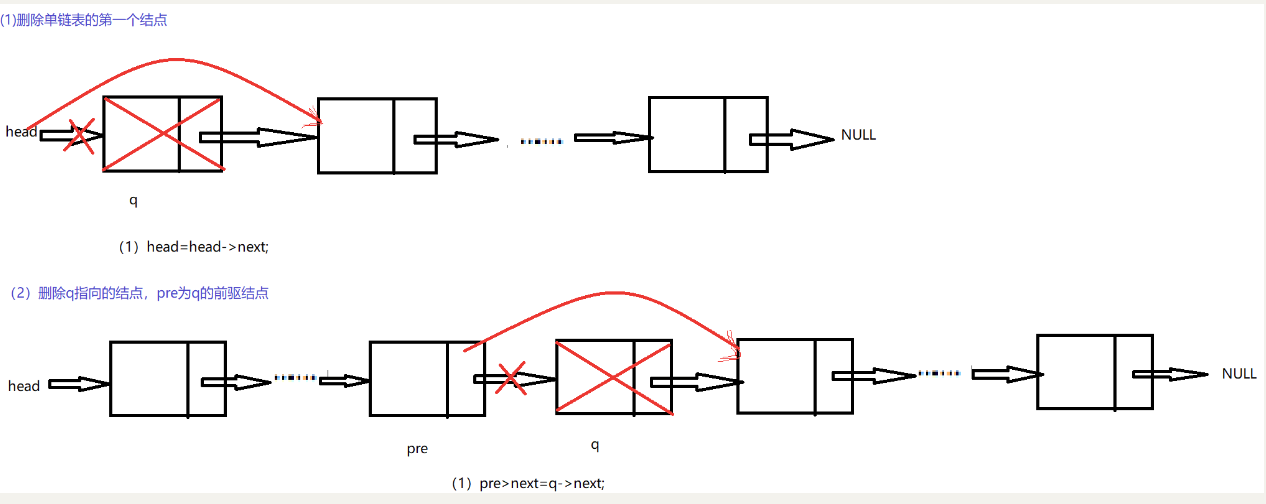
(3)删除
要想删除某个指定的结点,必须涉及到前驱结点,pre指向前驱结点,删除q结点,由于单链表第一个结点没有前驱结点,必须进行特殊处理。
node* Dele(node* head, datatype x)
{
node* pre = NULL, *p;
if (!head)
{
printf("单链表是空的!!!");
}
p = head;
while (p && p->info!=x)
{
pre = p;
p = p->next;
}
if (p)
{
if (!pre)head = head->next;
else pre->next = p->next;
free(p);
}
return head;
}
3 带头结点的单链表
3.1 基本概念及描述
单链表的插入和删除操作必须对在空链表插入新结点,删除一个结点称为空链表做特殊处理。为了减少对特殊情况的处理,可以在单链表设置一个特殊的结点,由单链表的首指针指示。只要有这个单链表,这个结点就永远不会删除,这种链表就是带头结点的单链表。

3.2 实现
在带头单链表中,head指示的是头结点,而不是数据结构中的第一个结点,第一个结点实际上是由head->next指示的。其基本操作也和不带头单链表的实现是一样的。
(1)初始化和销毁
node* Init()
{
node* head;
head = (node*)malloc(sizeof(node));
head->next = NULL;
return head;
}
void Destroy(node* p)
{
free(p);
p = NULL;
}
(2)打印链表结点的值
void display(node* head)
{
node* p = head->next;
if (!p)
{
printf("链表为空!!!\n");
}
while (p)
{
printf("%d ", p->info);
p = p->next;
}
printf("\n");
}
(3)在带头结点的单链表中查找第i个结点
node* Find(node* head, int i)
{
int j = 0;
node* p = head;
if (i < 0)
{
printf("不存在这个结点!!!\n");
}
if (i == 0) return p;
while (p && j != i)
{
p = p->next;
j++;
}
return p;
}
(4)插入
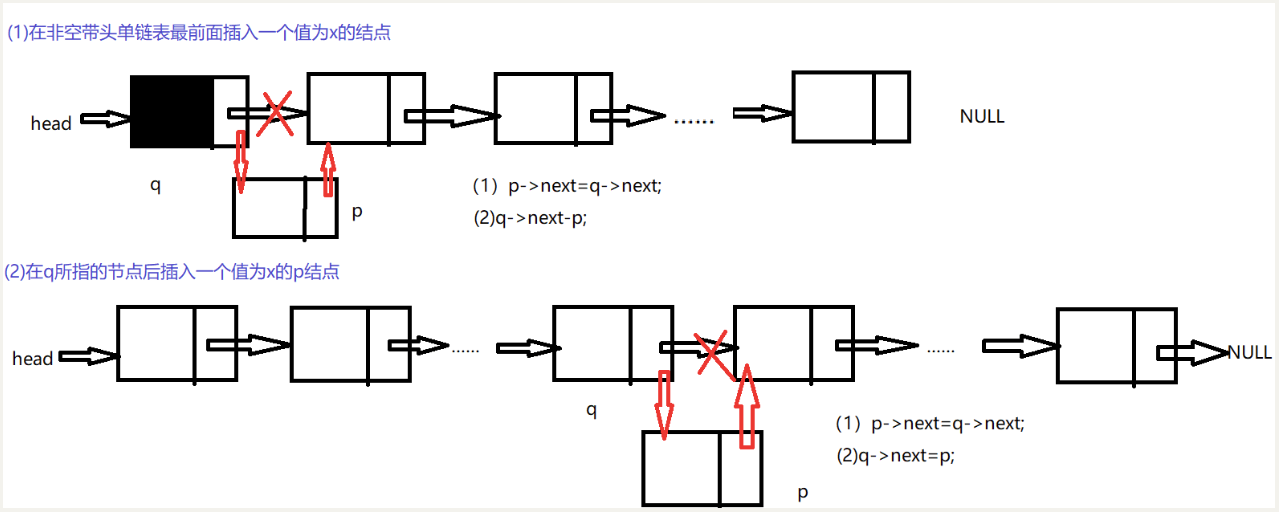
node* Insert(node* head, datatype x, int i)
{
node* p, * q;
q = Find(head, i);
if (!q)
{
printf("没有找到!!!");
}
p = (node*)malloc(sizeof(node));
p->info = x;
p->next = q->next;
q->next = p;
return head;
}
(5)删除

node* Dele(node* head, datatype x)
{
node* pre = head, * q;
q = head->next;
while (q && q->info != x)
{
pre = q;
q = q->next;
}
if (q)
{
pre->next = q->next;
free(q);
}
return head;
}
4 循环单链表
4.1 基本概念及描述
无论是单链表还是带头的单链表,从表中的某个结点开始,都只能访问到它后面的结点,不能访问它前面的结点,除非再从链表的首指针开始访问。我们希望从任意一个结点开始都可以访问到所有其他的结点,可以设置最后一个结点的指针指向表中的第一个结点,这种链表就叫做循环链表,

4.2 实现
对于循环链表,若首指针为head,某个结点p是最后一个结点的特征应该是p->next==head。
(1)初始化和销毁
node* Init()
{
return NULL;
}
void Destroy(node* p)
{
free(p);
p = NULL;
}
(2)打印链表结点的值
void display(node* head)
{
node* p=head;
if (!head)
{
printf("链表是空的!!!\n");
}
else
{
printf("%d ", p->info);
p = p->next;
while (p != head)
{
printf("%d ", p->info);
p = p->next;
}
printf("\n");
}
}
(3)寻找链表尾结点的地址
node* rear(node* head)
{
node* p;
if (!head)
p = head;
else
{
p = head;
while (p->next != head)
{
p = p->next;
}
}
return p;
}
(4)查找值为x的结点,返回这个结点
node* Find(node* head,datatype x)
{
node* q;
if (!head)
{
printf("链表是空的!!!");
return NULL;
}
q = head;
while (q->next != head && q->info != x)
{
q = q->next;
}
if (q->info == x)
{
return q;
}
else
return NULL;
}
(5)插入
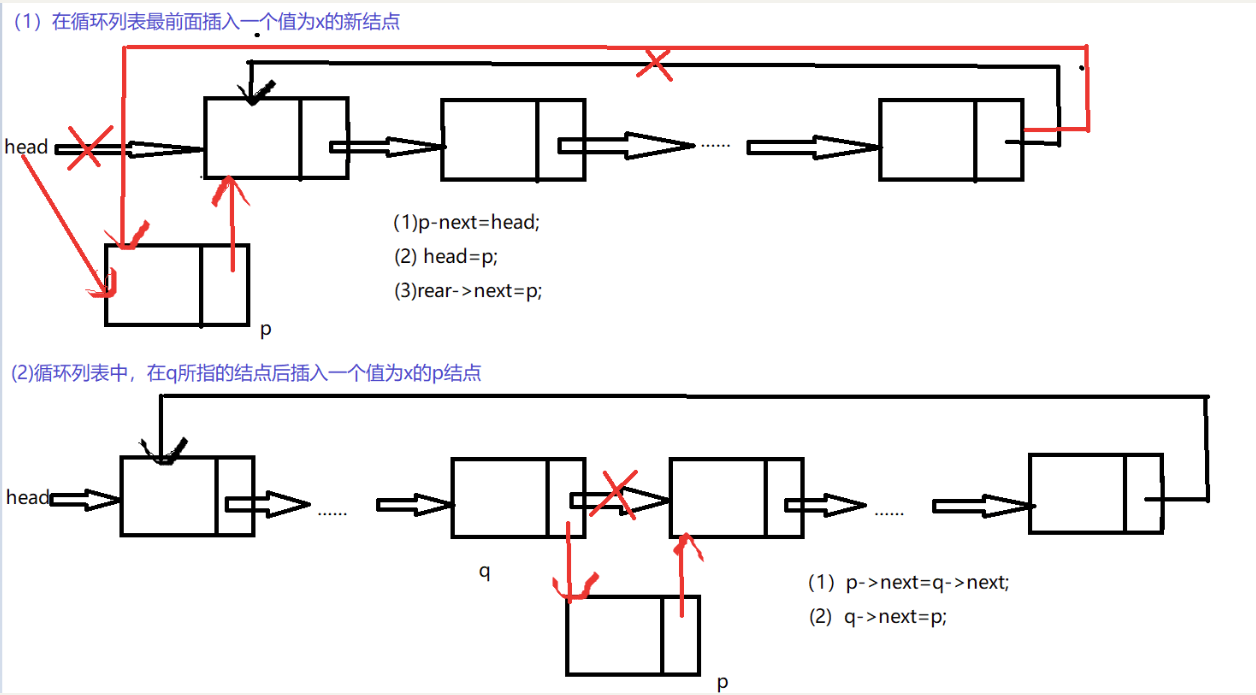
node* Insert(node* head, datatype x, int i)
{
//i=0时,就是插入在链表的头部
node* p, * q, *myrear;
int j;
p = (node*)malloc(sizeof(node));
p->info = x;
if (i < 0)
{
printf("没有找到指定插入的位置!!!\n");
}
if (i == 0 && !head)//链表为空,在头部插入
{
p->next = p;
head = p;
return head;
}
if (i == 0 && head)//链表不为空,在头部插入
{
p->next = head;
myrear = rear(head);
myrear->next = p;
return head;
}
if (i > 0 && !head)//链表为空
{
printf("没有找到指定插入的位置!!!\n");
return head;
}
if (i > 0 && head)
{
q = head;
j = 1;
while (i!= j && q->next != head)
{
q = q->next;
j++;
}
if (i != j)//走到尾
{
printf("不存在第i个结点!!!\n");
return head;
}
else
{
p->next = q->next;
q->next = p;
return head;
}
}
}
(6)删除
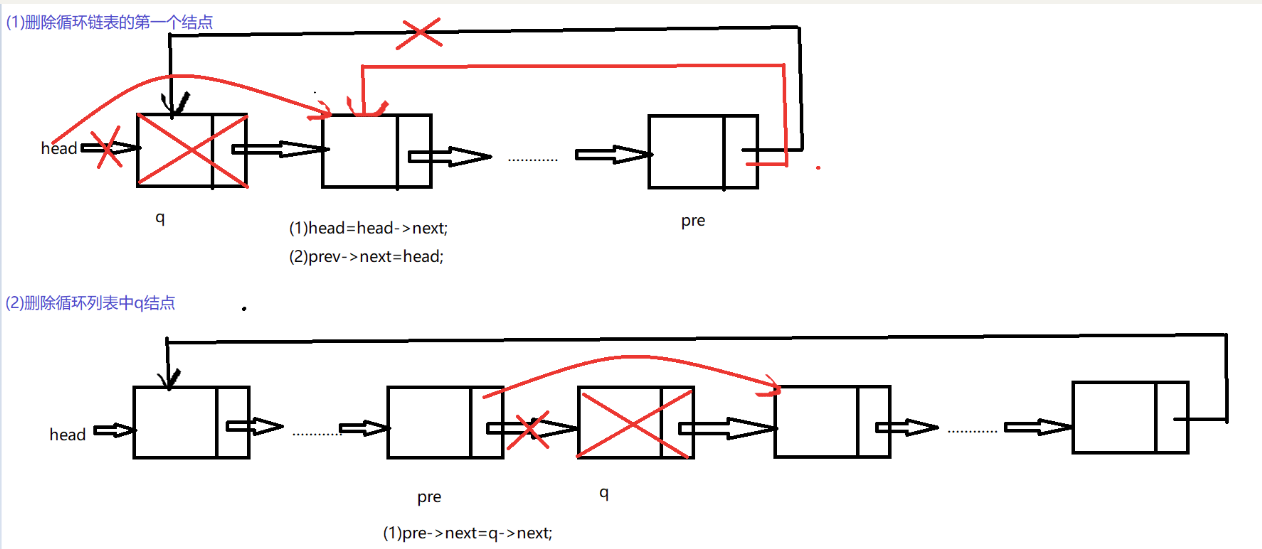
node* Dele(node* head, datatype x)
{
node* pre = NULL, * q;
if (!head)
{
printf("链表为空,无法进行删除操作!!!\n");
return head;
}
q = head;
while (q->next != head && q->info != x)
{
pre = q;
q = q->next;
}
if (q->info != x)//找到尾,没有找到
{
printf("没有找到!!!\n");
}
else
{
if (q != head)
{
pre->next = q->next;
free(q);
q = NULL;
}
else if(head->next==head)
{
free(q);
q = NULL;
}
else
{
pre = head->next;
while (pre->next != q)
{
pre = pre->next;
}
head = head->next;
pre->next = head;
free(q);
q = NULL;
}
}
return head;
}
5.双链表
5.1 基本概念及描述
使用单链表时,要想找一个结点的前驱结点,必须从头开始遍历,可以在一个结点中再加一个指针域,指向它的前驱结点,这是访问它的前驱结点就会方便很多,这就构成了双链表。

<span style="color:red;">这是红色的文字</span>
5.2 实现
双链表的第一个结点没有前驱,它的llink是NULL,最后一个结点没有后继,它的rlink是NULL
(1)初始化
dnode* init()
{
return NULL;
}
(2)打印双链表的值
void display(dnode* head)
{
dnode* p;
p = head;
if (!p)
printf("链表是空的\n");
else
{
while (p)
{
printf("%d ", p->info);
p = p->rlink;
}
printf("\n");
}
}
(3)查找一个第i个结点
dnode* find(dnode* head, int i)//在链表中查找第i个结点
{
int j = 1;
dnode* p = head;
if (i < 1)
printf("该结点不存在!!!\n");
while (p && i != j)
{
p = p->rlink;
j++;
}
if (!p)
printf("该结点不存在!!!\n");
return p;
}
(4)插入
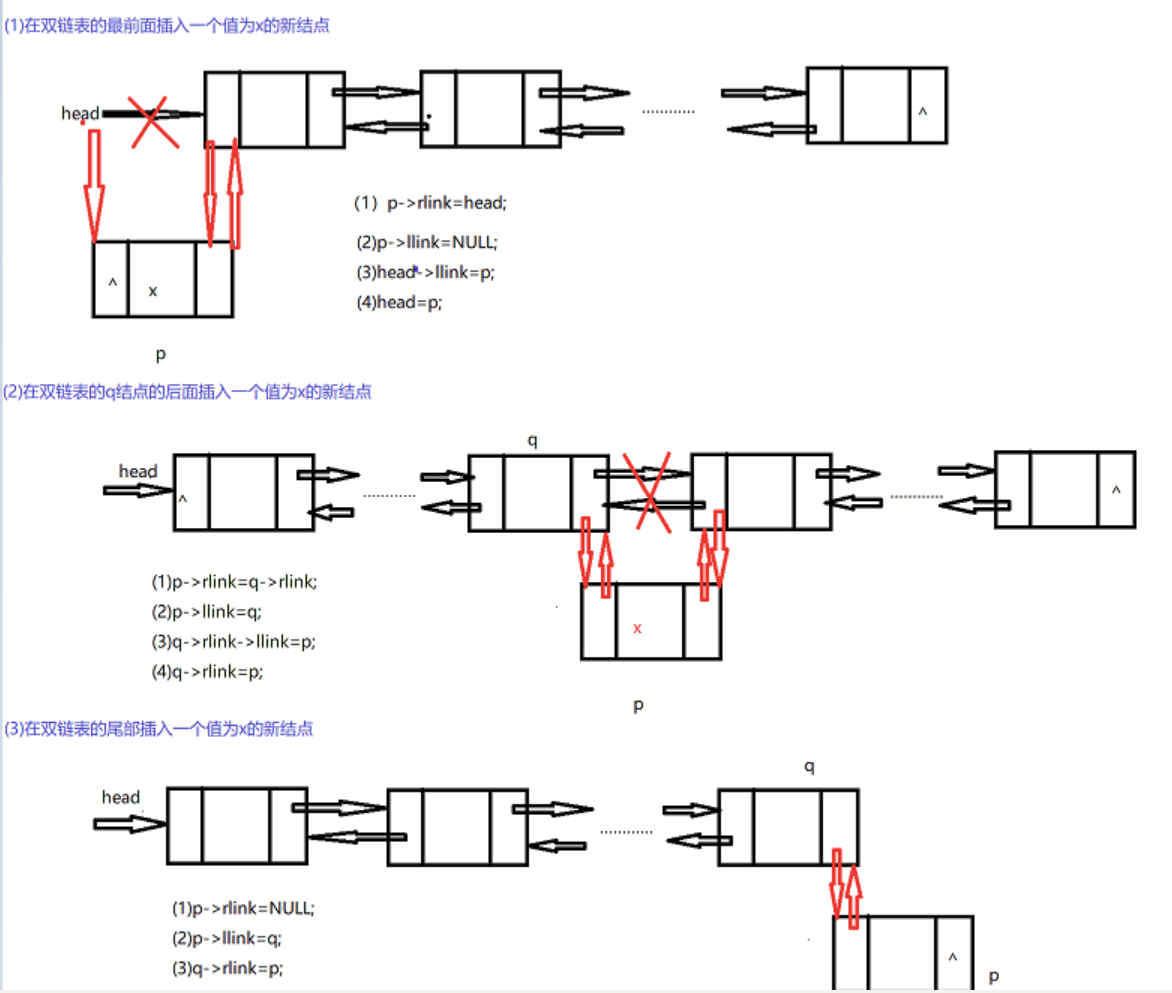
dnode* insert(dnode* head, datatype x, int i)//在第i个结点之后插入值为x的新结点
{
dnode* p, * q;
p = (dnode*)malloc(sizeof(dnode*));
p->info = x;
if (i == 0)//在最前面插入
{
p->llink = NULL;
p->rlink = head;
if (!head)//原链表为空
{
head = p;
}
else//链表不为空
{
head->llink = p;
head = p;
}
return head;
}
q = find(head, i);
if (!q)
{
printf("第i个结点不存在!!!\n");
free(p);
return head;
}
if (q->rlink == NULL)//在最后一个结点后插入
{
p->rlink = NULL;
p->llink = q;
q->rlink = p;
}
else
{
p->rlink = q->rlink;
p->llink = q;
q->rlink->llink = p;
q->rlink = p;
}
return head;
}
(5)删除
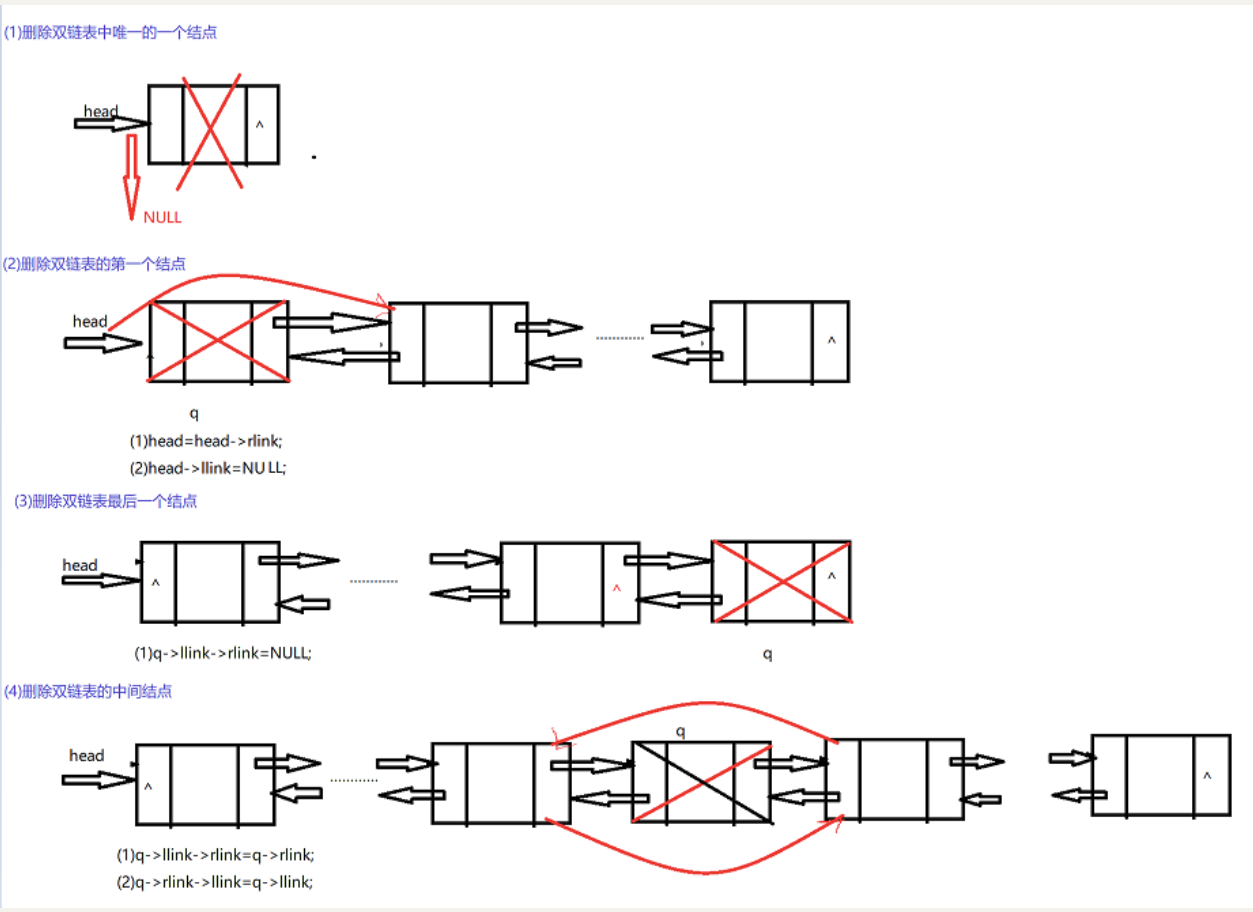
dnode* del(dnode* head, datatype x)//删除值为x的结点
{
dnode* q;
if (!head)
printf("链表为空,不能进行删除操作!!!\n");
q = head;
while (q && q->info != x)
{
q = q->rlink;
}
if (!q)
printf("没有找到值为x的结点!!!\n");
if (q == head && head->rlink)
{
head = head->rlink;
head->llink = NULL;
free(q);
return head;
}
if (q == head && !head->rlink)
{
free(q);
head = NULL;
return head;
}
else
{
if (!q->rlink)//删除双链表的最后一个结点
{
q->llink->rlink = NULL;
free(q);
return head;
}
else
{
q->llink->rlink = q->rlink;
q->rlink->llink = q->llink;
free(q);
return head;
}
}
}
6.链式栈
栈的链式存储称为链式栈,也是一个特殊的单链表,这种特殊的单链表,它的插入和删除操作都在同一端进行,栈顶指针用top。
6.1 基本操作
typedef int datatype;
typedef struct Link_stack_node
{
datatype info;
struct Link_stack_node* next;
struct Link_stack_node* top;
}node;
node* init();
int empty(node* top);
datatype read(node* top);//读取栈顶结点的值
void display(node* top);//输出链式栈各个结点的值
node* push(node* top, datatype x);//向链式栈中插入一个值为x的结点(进栈)
node* pop(node* top);//删除链式栈的栈顶结点(出栈)
6.2 具体实现
#include"Link_stack.h"
node* init()
{
return NULL;
}
int empty(node* top)
{
return (top ? 0 : 1);//==top!=NULL?0:1
}
datatype read(node* top)//读取栈顶结点的值
{
if (!top)
{
printf("链式栈是空的!!!");
}
else
{
return top->info;
}
}
void display(node* top)//输出链式栈各个结点的值
{
node* p;
p = top;
if (!top)
{
printf("链式栈是空的!!!");
}
while (p)
{
printf("%d ", p->info);
p = p->next;
}
printf("\n");
}
node* push(node* top, datatype x)//向链式栈中插入一个值为x的结点(进栈)
{
node* p;
p = (node*)malloc(sizeof(node));
p->info = x;
p->next = top;
top = p;
return top;
}
node* pop(node* top)//删除链式栈的栈顶结点(出栈)
{
node* q;
q = top;
top = top->next;
free(q);
return top;
}
7.链式队列
7.1 基本操作
typedef int datatype;
typedef struct Link_node
{
datatype info;
struct Link_node* next;
}node;
typedef struct
{
//定义队列的队首和队尾指针
node* front, * rear;
}queue;
queue* init();
int empty(queue qu);
void display(queue qu);
datatype read(queue qu);
queue* insert(queue* qu, datatype x);
queue* dele(queue* qu);
7.2 具体实现
queue* init()
{
queue* qu;
qu = (queue*)malloc(sizeof(queue));
qu->front = NULL;
qu->rear = NULL;
}
int empty(queue qu)
{
return (qu.front ? 0 : 1);
}
void display(queue qu)
{
node* p;
p = qu.front;
if (!p)
printf("链式队列为空!!!");
while (p)
{
printf("%d ", p->info);
p = p->next;
}
printf("\n");
}
datatype read(queue qu)
{
if (!qu.front)
printf("链式队列为空!!!");
return qu.front->info;
}
queue* insert(queue* qu, datatype x)
{
node* p;
p = (node*)malloc(sizeof(node));
p->info = x;
p->next = NULL;
if (qu->front == NULL)//在空链表中插入
{
qu->front = qu->rear = p;
}
else
{
qu->rear->next = p;
qu->rear = p;
}
return qu;
}
queue* dele(queue* qu)
{
node* q;
if (!qu->front)
printf("队列为空,不能删除!!!");
q = qu->front;
qu->front = q->next;
free(q);
if (qu->front == NULL)
qu->rear = NULL;
return qu;
}
7.3 测试代码
void Link_queue_test2()
{
queue* qu;
qu=init();
display(*qu);
printf("%d \n", empty(*qu));
insert(qu, 1);
insert(qu, 2);
insert(qu, 3);
insert(qu, 4);
insert(qu, 5);
insert(qu, 6);
display(*qu);
dele(qu);
display(*qu);
dele(qu);
display(*qu);
}

