
双链表定义
双链表就是在单链表结点上增添了一个指针域,指向当前结点的前驱。这样就可以方便的由其后继来找到其前驱,而实现输出终端结点到开始结点的数据序列。
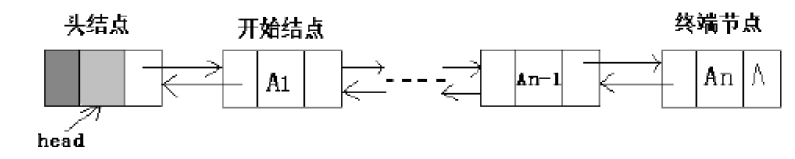
同样,双链表也分为带头结点的双链表和不带头结点的双链表,情况类似于单链表。带头结点的双链表 head->next 为null的时候链表为空。不带头结点的双链表head为null的时候链表为空。
1.采用尾插法建立双链表
void CreateDlistR (DLNode *&L, int a[], int n){
DLNode*s,*r;
inti;
L = (DLNode*)malloc(sizeof(DLNode));
L->next = NULL;
//和单链表一样r始终指向终端结点,开始头结点也是尾结点
r = L;
for(i = 1; i< = n; i++){
//创建新结点s->data = a[i];
s = (DLNode*)malloc(sizeof(DLNode));
/*下边3句将s插入在L的尾部并且r指向s,s->prior = r;这一句是和建立单链表不同的地方。 */
r->next = s;
s->prior = r;
r = s;
}
r->next = NULL;
}
2.查找结点的算法
在双链表中查找第一个结点值为x的结点。从第一个结点开始,边扫描边比较,若找到这样的结点,则返回结点指针,否则返回NULL。算法代码如下:
DLNode* Finfnode(DLNode *C, int x){
DLNode *p = C->next;
while(p != NULL){
if(p->data == x) {
break;
}
p = p->next;
}
return p;
//如果找到则p中内容是结点地址(循环因break结束),
//没找到 p中内容是NULL(循环因p等于NULL而结束)
//因此这一句可以将题干中要求的两种返回值的种情况统一。
}
3.插入结点的算法
假设在双链表中p所指的结点之后插入一个结点s,其操作语句描述为:
s->next = p->next;
s->prior = p;
p->next = s;
s->next->prior = s;
指针变化过程如图:
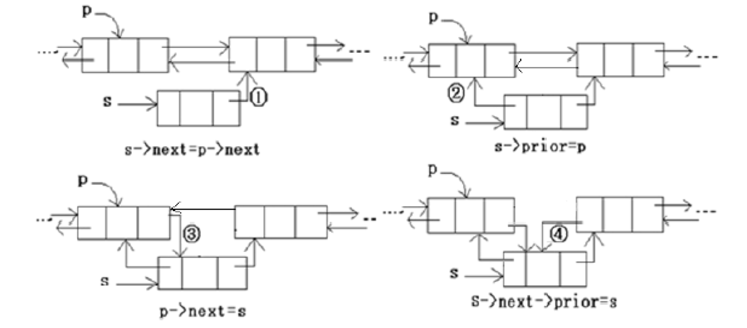
如果按照上面的顺序来插入,可以看成是一个万能的插入方式。先将要插入的结点两边链接好,可以保证不会发生链断之后找不到结点的情况。
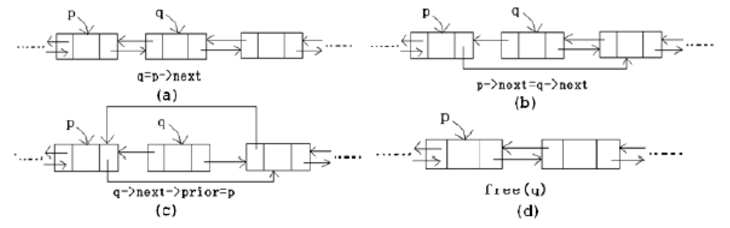
4.删除结点的算法
设要删除双链表中p结点的后继结点,其操作的语句为:
q= p->next;
p->next= q->next;
q->next->prior= p;
free(q);
指针变化过程如图所示:
循环单链表

只要将单链表的最后一个指针域(空指针)指向链表中第一个结点即可(这里之所以说第一个结点而不说是头结点是因为,如果循环单链表是带头结点的则最后一个结点的指针域要指向头结点;如果循环单链表不带头结点,则最后一个指针域要指向开始结点)。
带头结点的循环单链表当head等于head->next时链表为空;
不带头结点的循环单链表当head等于null时链表为空。
循环双链表
循环双链表的构造源自双链表,即将终端结点的nnext指针指向链表中第一个结点,将链表中第一个结点的prior指针指向终端结点。
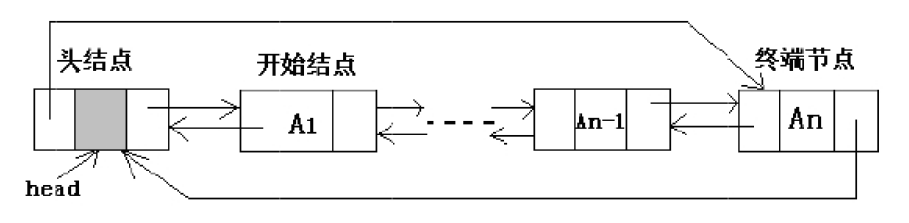
带头结点的循环双链表当head->next和heaad->prior两个指针都等于head时链表为空。
不带头结点的循环双链表当head等于null的时候为空。
循环链表的算法操作
循环单链表和循环双链表由对应的单链表和双链表改造而来,只需在终端结点和头结点间建立联系即可。
循环单链表终端结点的next结点指针指向表头结点;循环双链表终端结点的next指针指向表头结点,头结点的prior指针指向表尾结点。
如果p指针沿着循环链表行走,判断p走到表尾结点的条件是p->next == head。循环链表的各种操作均与非循环链表类似。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号