

python的基础及练习
变是指变化,量是指反映某种状态
例:
level =1 或 2
username = ‘xuanxuan’
password = ‘123’
python里的“=”是赋值的意思,并不是真的等于
内存地址:并非真正的内存地址,而是python转变成的一串数字。print(id(username))查看内存地址
数值:变量被赋予的值
数值类型:就是数值的类型。print(type(username)) 查看数值类型
引用计数:就是指被调用的次数
例:
x = 'a' #a的引用计数 = 1
y = x #a的引用计数 = 2
垃圾回收机制:
变量被赋值之后,会在内存中划去一块区域,当一套程序程序运行完毕后,将解除相应内存中的占用
数字的默认缓冲区:
-5~256这个区间的数字的内存地址是相同的(为了节省内存)
“==”是数值的运算符,代表数值的真的等于
“is”是身份的运算符,代表内存地址和数值都一样才是true,否则false
例:
info = input('你好,客官!想要买点啥?')
print(info)
运行后,这里的系统会输出'你好,客官!想要买点啥?
这时需要客户输入
输入的内容就是赋值给info
最后打印info
这就是交互的过程
1、行前加“#”
2、快捷键:“ctrl + ?”
3、''' ''' 三引号中的内容是注释的内容(用于多行)
1、整型:int 整数 ,比如:游戏等级,身份证号,年龄
2、浮点型:float 小数, 比如:薪资,身高,体重
3、字符串:str在引号(单引号,双引号,三引号)里定义的一堆字符,比如:名字,国籍,地址
这了三引号内容被当作值赋予了变量,这时不作为注释
数字运算:
print(10 + 5)
print(10 - 5)
print(10 * 5)
print(10 / 5)
print(10 // 3)取整
print(10 % 3)取余
字符串运用的运算符只有两个(+,*)
name1 = 'xuan'
name2 = 'yuan'
print(name1+name2)字符串的拼接 运行结果:xuanyuan
name2 = 2
print(name1*name2)字符串的倍增 运行结果:xuanxuan
在[]内,用逗号分隔开,存放多个任意类型的元素
myinfo = ['xuanxuan',18,'student',['中国银行',2000]]
取姓名:print(myinfo[0])
取公司名字:print(myinfo[3][0])
定义花括号内,用逗号分割key:value,value可以是任意类型,但是key必须不可变类型
状态:存放多个值
'name' : 'xuanxuan',
'age' : 18
'jop' : 'student'
}
取姓名:print(info['name']) 当取值元素不存在时,会报错
或:print(info.get(name)) 当取值元素不存在时,会显示空
状态:成立,不成立,用来做逻辑运算---》判断
a = 1
b = 1
print(a != b) 不成立,so false
在id不变的情况下,value可以变,则称为可变类型,如列表,字典
例1:
a = [1,2,3,4,5]
print(id(a))
a[1] = 99
print(a)
print(id(a))
例2:
info = {
'name': 'xuanxuan',
'age': 18,
'job': 'student'
}
print(id(info))
info['age'] = 16
print(id(info))
如int,float,str类型
例:
x = 123
print(id(x))
x = 321
print(id(x))
例1:
name = 'xuanxuan'
age = 18
print('my name is %s my age is %s' % (name, age))
运行结果:my name is xuanxuan my age is 18
例2:补全信息
name = 'xuanxuan'
age = 18
sex = 'man'
job = 'teacher'
------------ info of %s -----------
Name : %s
Age : %s
Sex : %s
Job : %s
------------- end -----------------
'''
print(msg % (name, name, age, sex, job))
或者:在''' '''后加" % (name, name, age, sex, job)"
a = b = c = d = 1
a = 1 b = 2 print(a, b) a, b = b, a print(a, b)
运行结果: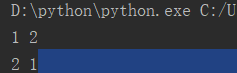
3、解压赋值
l = [1,2,3,4,5] a,b,c,d,e = l print(a,b,c,d,e)
运行结果:
12、基本逻辑运算符(if...elif...else)
即(如果...否则如果...否则)
age = 20 high = 170 success = True if age: print('ok') else: print('不OK') if age > 18: if success: print('咱们结婚吧!') else: print('去他妈的爱情!') elif high > 165: print('你真漂亮,亭亭玉立') else: print('你真可爱')
运行结果: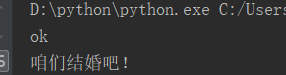
13、基本输入:input (默认数据类型为 字符串)
所以当有需要时,我们与要指定数据类型
score = int(input('请输入你的成绩:')) if score >= 90: print('优秀') elif score >= 80 and score < 90: print('良好') elif score >=60 and score < 80: print('合格') else: print('不及格,回家叫家长吧')
14、循环(while,for)
1、while循环
例1:
count = 0 while count < 10: count += 1 # count = count + 1 print('hi~%s' % count)
运行结果: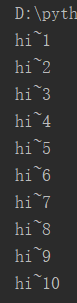
例2:取列表
pass:不执行任何操作,继续运行下边的操作
len(l):列表长度
i = 0 l = ['a', 'b', 'c', 'd','e'] while i < len(l): if i == 2: pass print(l[i]) i += 1
运行结果: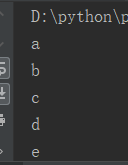
break:后面不执行,跳出循环
i = 0 l = ['a', 'b', 'c', 'd','e'] while i < len(l): if i == 2: break print(l[i]) i += 1
运行结果: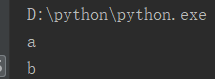
无限循环:while True
count = 0 while True: print('ha-%s' % count) count += 1
运行结果: 无限的+1下去
无限的+1下去
2、for循环
例1:字符串循环
result = 'hello,world' for i in result: print(i)
运行结果: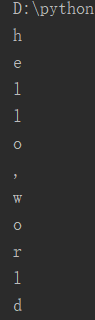
例2:字典循环
info = { 'name': 'aaa', 'age': 18, 'job': 'it' } for i in info.values(): #默认循环key,加.values()循环values print(i)
运行结果: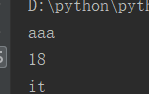
例3:列表循环:(元组循环基本一样,只是括号用小括号,能读不能改)
l = [1,2,3,4,5] for i in l: print(i)
运行结果: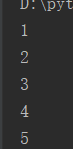
例4:continue(跳过下方,继续循环)
for i in range(10): if i == 7: continue print(i)
运行结果: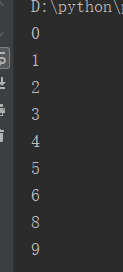
例5:步长
for i in range(0,10,2):#2是步长 print(i)
15、random模块
使用这个模块,必须先导入 import random
例:产生一个1~10的随机数,有以下三种方法:
import random l = [1,2,3,4,5,6,7,8,9,10] result = random.choice(l) print(result)
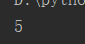
import random result = random.randint(0, 10) print(result)
import random result = random.randrange(10) print(result)
运行五次结果: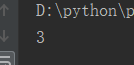
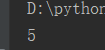
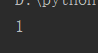
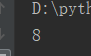
扩展练习:猜拳游戏
思想:
1、需要游戏的提示信息, print
2、需要与系统交互,才能和电脑猜拳,input
3、系统也需要出拳的程序,random
4、游戏的结果:赢,输,平
5、对于比赛结果的计数
6、需要循环,进行第二次游戏,while
import random win = 0 #胜利次数 lose = 0 #失败次数 tie = 0 #平局次数 while True: #建立游戏循环 print('胜:%s 败:%s 平:%s' % (win, lose, tie)) print('\033[1;31m 欢迎来猜拳!\033[0m') #给字体加颜色 print('1.石头 2.剪刀 3.布 4.退出游戏') l = ['石头', '剪刀', '布'] computer = random.choice(l) #电脑出拳 result = input('请出拳:') #玩家出拳 if (result == '1' and computer == '石头') or (result == '2' and computer == '剪刀') or (result == '3' and computer == '布'): #平局的条件 tie += 1 #平局计数+1 print('哎呦,不错哦,不要走,决战到天崩!!!') print('=' * 50) #分割每次打印的结果 elif (result == '1' and computer == '剪刀') or (result == '2' and computer == '布') or (result == '3' and computer == '石头'): #胜利的条件 win += 1 #胜利计数+1 print('连我你都可以赢,你简直是绝顶天才!!') print('=' * 50) elif result == '4': break #退出 elif result not in ('1', '2', '3', '4'): #防止选择其他无效选项,这里进行限制 print('喂喂喂,管住自己的手,别乱摸!!!') else: lose += 1 #失败计数+1 print('哈哈哈哈,你个垃圾!!') print('=' * 50)
16、字符串的类型取值
1)按索引值(正向取,方向取)只能取
正向取(从左往右)分别是:0,1,2,3,4......
方向取(从右往左)分别是:-1,-2,-3,-4.......
例:
result = ‘hello world’ print(result[0]) #正向取“h” print(result[-1]) #方向去“d”
2)切片(顾头不顾尾)
result = ‘hello world’
print(result[6:]) #索引6左边的不要,不包含6 print(result[:2]) #索引2右边的不要,包含2 print(result[0:3]) #取索引0到索引3的字符,其他的不要,包含0,不包含3 print(result[-3:-1]) #取索引-3到索引-1的字符,其他的不要,包含-3,不包含-1 print(result[0:6:2]) #取索引0到索引6,并且以2为步长的字符,其他的不要,包含0,不包含6
3)长度(len)
result = 'hello world' print(len(result)) #变量result的值,的字符串的长度(空格也算)
l = [1,2,3,'a','b',[1,2,3]] #列表中的每个列表,数字,字符串,都是1个长度单位 print(len(l))
result = { 'a': 1, 'b': 2, 'c': 3 } print(len(result)) #每一组键值对为1个长度单位
4)成员运算(in,not in)
in:在...里面
result = '1807这个班好厉害!' if '1807' in result: #这里1807是字符串,所以要加引号 print('ok') else: print('不OK')
运行结果: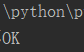
not in:不在...里面
result = '1807这个班好厉害!' if '厉害' not in result: print('ok') else: print('不OK')
运行结果: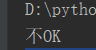
5)移除(strip 移除,lstrip 左边移除,rstrip 右边移除)
result = '------LINUX------' print(result.strip('-')) #strip()不加参数,默认是空格 print(result.lstrip('-')) print(result.rstrip('-'))
运行结果分别是: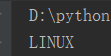
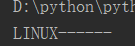
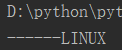
6)切分(split,rsplit)把一个字符串转变成列表
result = '192.168.1.250' print(result.split('.'))
result = '192 168 1 250' print(result.split()) #split()默认按空格分割,从左往右分割
上边两组代码的运行结果一样: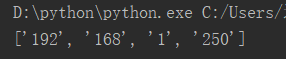
result = '192.168.1.250' print(result.rsplit('.', 1)) #反向(从右往左)分割,以“.”为分隔符,分割一次
运行结果: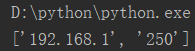
result = '192.168.1.250' print(result.split('.', 1)) #默认从左往右分割,以“.”为分隔符,分割一次
运行结果: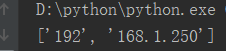
7)大写,小写,首字母 (lower,upper,title)
content = 'linux' print(content.upper())
运行结果: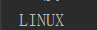
content = 'linux' result = content.upper() print(result.lower())
运行结果: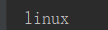
name = 'hello world' print(name.title())
运行结果: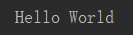
8)startswith endswith(判断字符串开头和结尾)
name = 'hello world' print(name.startswith('o')) print(name.endswith('s'))
运行结果:
9)格式化 format
两种用法:推荐用第二种
result = 'my name is {} my age is {}'.format('xuanxuan ', 18) print(result)
result = 'my name is {name} my age is {age}'.format(age = 18, name='xuanxuan') print(result)
运行结果:
10)替换(replace)
把“my”替换成“you”
result = 'my name is xuanxuan my age is 18'.replace('my', 'you') print(result)
运行结果:
把“my”替换成“you”,从左往右替换一个
result = 'my name is xuanxuan my age is 18'.replace('my', 'you',1) print(result)
运行结果: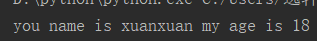
了解:
index:从左往右查找匹配字符的索引值 rindex:从右往左
result = 'mynameisxuanxuanmyageis18'.index('y') print(result)
输出结果: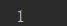
find:从左往右查找匹配字符串的第一个字符的索引值 rfind:从右往左
result = 'mynameisxuanxuanmyageis18'.find('xuanxuan') print(result)
输出结果:

count:查找一个字符串中匹配的字符串出现的次数
result = 'mynameisfengzimyageis18'.count('my') print(result)
输出结果:
17、列表类型
1)列表按照索引取值(正向取+反向取值):既可以存也可以取
l = ['a','b','c','d','e','f'] l[2] = 10 print(l)
运行结果:

2)列表切片(顾头不顾尾,步长)
l = ['a','b','c','d','e','f'] print(l[2:5]) print(l[0:5:2]) print(l[::2])
运行结果: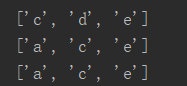
3)列表长度(len)
l = ['a','b','c','d','e','f'] print(l.__len__()) print(len(l))
运行结果:
4)列表成员运算(in,not in)
l = ['a','b','c','d','e','f'] i = 'h' if i not in l: print(i) if i in l: print(i)
运行结果: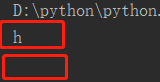 ,第二种因为条件不成立,并且也没有定义不成立的结果,所以什么也没有
,第二种因为条件不成立,并且也没有定义不成立的结果,所以什么也没有
5)列表追加(append, extend)
append:插入元素 extend:插入列表
l = ['a','b','c','d','e','f'] l.append(1) l.append('hh') print(l) s = [1,2,3,4,5] l.extend(s) print(l)
运行结果:
6)列表插入(insert)
l = ['a','b','c','d','e','f'] l.insert(3,'sss') #在索引为3的位置上插入sss print(l)
运行结果:
7)列表删除(pop,remove)
pop:从列表中取出(按索引) remove:从列表中删除(按元素名)
l = ['a','b','c','d','e','f','d'] l.pop() #不加参数默认从后往左取出 print(l) l.pop(1) #添加索引参数,按照索引取出 print(l) result = l.pop(1) #将pop取出的值赋予变量 print(result) print(l)
运行结果: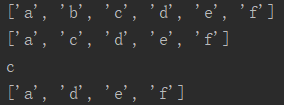
l = ['a','b','c','d','e','f','d'] name = l.remove('b') #remove真正把元素从列表里删除而不是取出 print(name) print(l.count('d')) #统计个数 l.reverse() #翻转(镜像) print(l) l.sort() #列表里字符串和整数没法sort print(l) l.clear() #清空列表 print(l)
运行结果: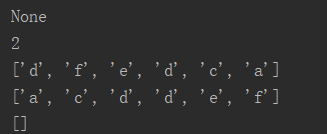
练习:
1)有列表data=['小黑', '28',[1990,3.14]],分别取出列表中的名字,年龄,出生的年,月,日赋值给不同的变量
data=['小黑', '28',[1990,3.14]] name = data.pop(0) print(name) age = data[0] print(age) birthday = data[1][0] #取生日的年份 print(birthday)
2)用列表模拟队列(先进先出)
l = [] l.append('a') l.append('b') l.append('c') print(l) print(l.pop(0)) #a print(l.pop(0)) #b print(l.pop(0)) #c 或 l.reverse() print(l.pop()) print(l.pop()) print(l.pop())
3)用列表模拟堆栈(先进后出,后进先出)
l = [] l.append('a') l.append('b') l.append('c') print(l) print(l.pop()) #c print(l.pop()) #b print(l.pop()) #a
4)把一个列表合并成一个字符串(join)
l = ['a','b','c','d','e','f','d'] result = ''.join(l) print(result)
运行结果:
18、元组类型(与列表基本相同,但只读)
t = ('a','b','c','d','e','f') t[0] = 1 print(t)
修改元组的元素,会报错
19、字典类型
fromkey 快速建立空字典
result = {}.fromkeys(['name','age', 'job'], None)
print(result)
运行结果:
popitem 取键值对
info = { 'name':'aaa', 'age': 18, 'job': 'IT' } a = info.popitem() #取键值对(默认从后往前取) print(info) print(a) #注意,取出的键值对是元组形式
运行结果:
pop 指定key,取值
info = { 'name':'aaa', 'age': 18, 'job': 'IT' } a = info.pop('name') #pop指定key取值 print(a) print(info)
运行结果:
items() 把字典编程列表形式,里面为元组形式
info = { 'name':'aaa', 'age': 18, 'job': 'IT' } res = info.items() #把一个字典变成列表形式,里面为元组格式('name','aaa') for i in res: print(i)
运行结果: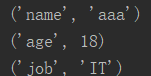
update() 合并字典
把2个字典合并成一个字典,info为主字典,如果info2和info字典的key相同,value不同,info2把info值覆盖
info = { 'name':'aaa', 'age': 18, 'job': 'IT' } info2 = { 'name2':'aaa', 'age2': 18, 'job': 'teacher' } info.update(info2)print(info)
运行结果:
get() 取值
info = { 'name':'aaa', 'age': 18, 'job': 'IT' } name1 = info.get('name') print(name1)
运行结果: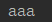
clear() 清空字典
info = { 'name':'aaa', 'age': 18, 'job': 'IT' } info.clear()#清空字典 print(info)
运行结果:
values() keys() 取所有的值
info = { 'name':'aaa', 'age': 18, 'job': 'IT' } print(info.values()) #取所有的值 print(info.keys()) #取所有的键 for i in info: #默认是key循环 print(i)
运行结果: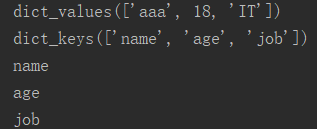
20、集合 特点去重
l = [1,2,3,4,5,5,5,5] s = set(l) print(s)
运行结果: ,这种格式,就是集合
,这种格式,就是集合
s.add() 添加 remove() 删除
l = [1,2,3,4,5,5,5,5] s = set(l) s.add(10) print(s)
运行结果: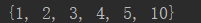
21、文件处理
1)取消路径中的特殊符号"\"含义 (三种方法)
假设:a.txt文件的路径是C:\Users\fengzi\Desktop\a.txt,则
f = open(r'C:\Users\fengzi\Desktop\a.txt') #前边加“r“,意在说明是目录路径 f = open('C:\\Users\\fengzi\\Desktop\\a.txt') #用转义符去转义 f = open('C:/Users/fengzi/Desktop/a.txt') #将转义符"\"换成“/”
使用 f = open(r'C:\Users\fengzi\Desktop\a.txt', 'r') 这种方式 会同时占用系统和python 两个的内存
所以当结束任务时必须使用 f.close() 结束任务
2)读取文件中的内容
第一种方式 f.read a.txt文件中的内容是
①windows默认打开方式是“gbk”,可能需要指定打开格式utf8,encoding='utf8',也有可能不需要指定也可以打开
f = open(r'C:\Users\逸轩\Desktop\a.txt', 'r', encoding='utf8') data = f.read() #全部读取 print(data) f.close()
运行结果:
②防止文件过大,可以采用一行一行的形式读取
f = open(r'C:\Users\逸轩\Desktop\a.txt', 'r') data = f.readline()
data2 = f.readline() print(data)
print(data2) f.close()
运行结果:
③改成列表形式
f = open(r'C:\Users\逸轩\Desktop\a.txt', 'r') data = f.readlines() print(data) f.close()
运行结果:
由于有换行符"\n",所以要去掉
f = open(r'C:\Users\逸轩\Desktop\a.txt', 'r') #告诉操作系统打开一个a.txt文件 data = f.readlines() #把文件内容以列表形式赋予给data变量 for i in data: #循环data列表取出每个元素 print(i.replace('\n', '')) #把每个元素的'\n'去掉 f.close() #告诉操作系统关闭文件
运行结果: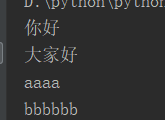
再还原回列表
l = [] #定义一个空列表 f = open(r'C:\Users\逸轩\Desktop\a.txt', 'r') #告诉操作系统打开一个a.txt文件 data = f.readlines() #把文件内容以列表形式赋予给data变量 for i in data: #循环data列表取出每个元素 y = i.replace('\n', '') #把每个元素的'\n'去掉 l.append(y) #加入到空列表当中 f.close() #告诉操作系统关闭文件 print(l)
运行结果:
第二种方式with open 不需要手动结束任务
with open(r'C:\Users\逸轩\Desktop\tt.txt','r') as f: print(f.read())
3)写入文件 f.write (什么方式写,什么方式读)
f = open('a.txt', 'w') f.write('你好') f.close()
这种方式写入,就是默认的gbk格式,打开的时候需要选择选择gbk,读取的时候不需要
f = open('a.txt', 'r') print(f.read()) f.close()
下边是用utf8格式:
f = open('a.txt', 'w',encoding='utf-8') f.write('你好') f.close()
读取:
f = open('a.txt', 'r',encoding='utf-8') print(f.read()) f.close
f.writelines的用法
f = open('a.txt', 'w',encoding='utf-8') #r模式为只读模式 w为写模式(覆盖写)a时光标移动到末尾追加 f.writelines(['你\t好aaa\n','bbbb\n', 'ccccc\n','fff\000ff']) #writelines传入列表写入文件中变成字符串(\t为2个空格,\n为换行符,\000为一个空格)
f.close()
f.tell() 查看光标的位置,f.seek() 移动光标
f = open('a.txt', 'w',encoding='utf-8') print(f.fell())
f.seek(4) #utf-8下seek移动光标到第四个字节(英文占1个字节,中文站3个字节)
f.seek(0,2) #0,2为把光标移动到末尾
f.close()
