KafkStream架构
Kafka Stream 的整体架构图如下。
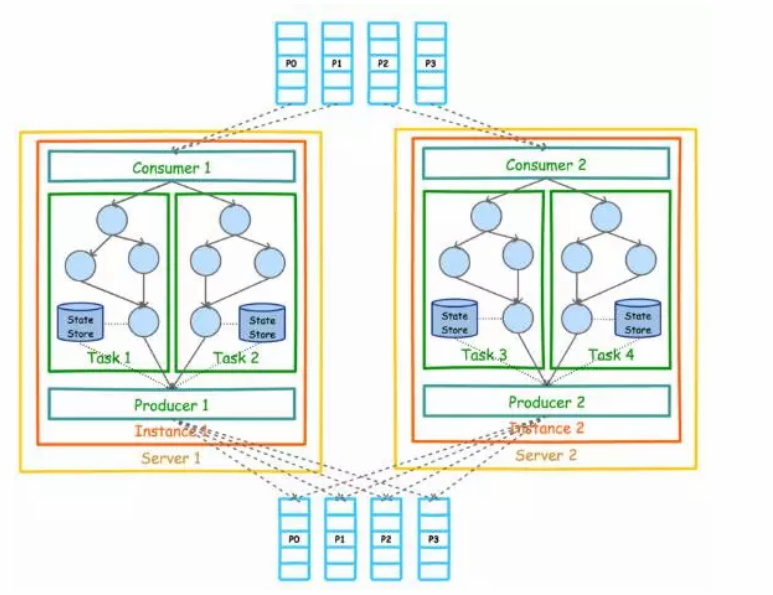
目前KafkaStream的数据源智能是如上图所示的Kafka,但是处理结果并不一定是如上图所示的输出到Kafka,实际上KStream和Ktable的实例化都需要输入源节点,也就是源Topic。
KStream<String, String> stream = builder.stream("words-stream");
KTable<String, String> table = builder.table("words-table", "words-store");
另外,上图中的Consumer和Producer并不需要在开发者应用中显示实例化,而是由KafkaStream 根据参数隐式实例化和管理,从而降低了使用门槛。
开发者主需要将重心放到开发核心业务逻辑,也即上图中的Task内的部分。
1.1 Stream分区和任务
Kafka分区数据的消息层用于存储和传输。Kafka Streams分区数据用于处理。 在这两种情况下,这种分区使数据弹性,可扩展,高性能和容错。Kafka Streams使用了分区和任务的概念,基于Kafka主题分区的并行性模型。在并发环境行,Kafka Streams和Kafka之间有着紧密的联系:
- 每个流分区是完全有序的数据记录队列,并映射到kafka主题的分区。
- 流的数据消息与主题的消息映射。
- 数据记录中的keys决定了Kafka和Kafka Streams中数据的分区,即,如何将数据路由到指定的分区。
应用程序的处理器拓扑通过将其分成多个任务来进行扩展,更具体点说,Kafka Streams根据输入流分区创建固定数量的任务,其中每个任务分配一个输入流的分区列表(即,Kafka主题)。分区对任务的分配不会改变,因此每个任务是应用程序并行性的固定单位。然后,任务可以基于分配的分区实现自己的处理器拓扑;他们还可以为每个分配的分区维护一个缓冲,并从这些记录缓冲一次一个地处理消息。作为结果,流任务可以独立和并行的处理而无需手动干预。
重要的是要理解Kafka Streams不是资源管理器,而是可在任何地方都能“运行”的流处理应用程序库。多个实例的应用程序在同一台机器上执行,或分布多个机器上,并且任务可以通过该库自动的分发到这些运行的实例上。分区对任务的分配永远不会改变;如果一个应用程式实例失败,则其被分配的任务将自动地在其他的实例重新创建,并从相同的流分区继续消费。
下面展示了2个分区,每个任务分配了输出流的1个分区。

1.2 线程模型
Kafka Streams允许用户配置线程数,可用于平衡处理应用程序的实例。每个线程的处理器拓扑独立的执行一个或多个任务。例如,下面展示了一个流线程运行2个流任务。
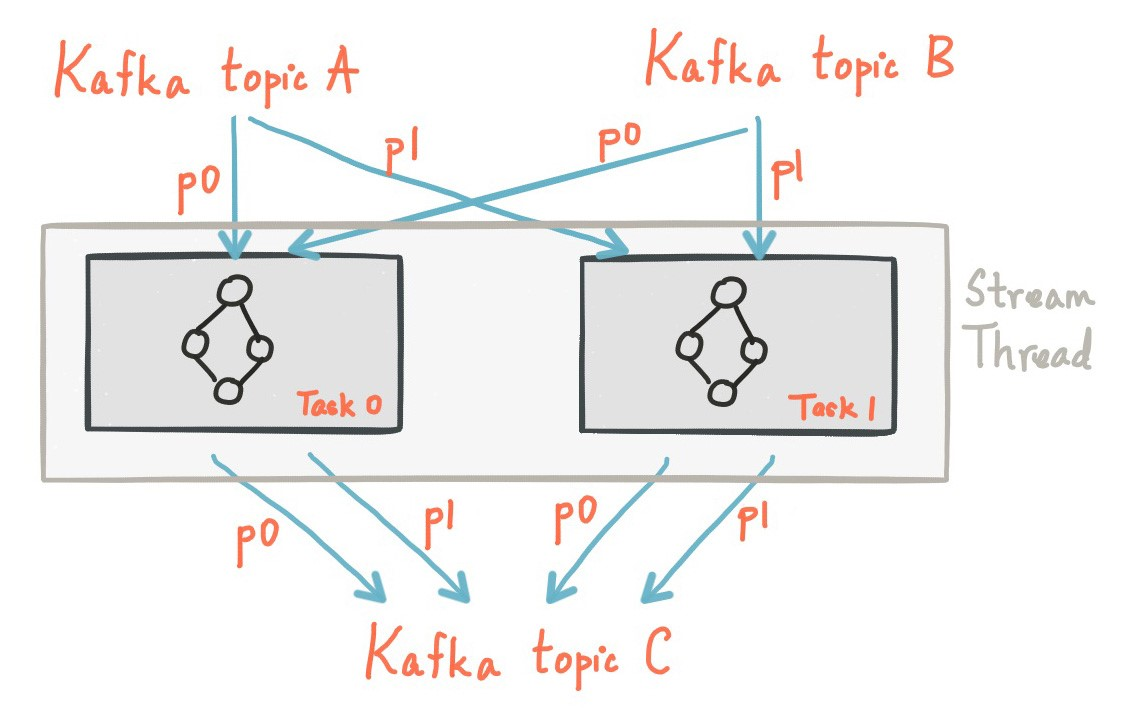
启动更多的流线程或更多应用程序实例,只需复制拓扑逻辑(ps,就是多复制几个代码到不同的机器上运行),达到并行处理处理不同的Kafka分区子集的目的。要注意的是,这些线程之间不共享状态。因此无需协调内部的线程。这使它非常简单在应用实例和线程之间并行拓扑。Kafka主题分区的分配是通过Kafka Streams利用Kafka的协调功能在多个流线程之间透明处理。
如上所述,Kafka Streams扩展流处理应用程序是很容易的:你只需要运行你的应用程序实例,Kafka Streams负责在实例中运行的任务之间分配分区。你可以启动和应用程序线程一个多的输入Kafka主题分区。这样,所有运行中的应用实例,每个线程(或更确切的说,它运行的任务)至少有一个输入分区可以处理。
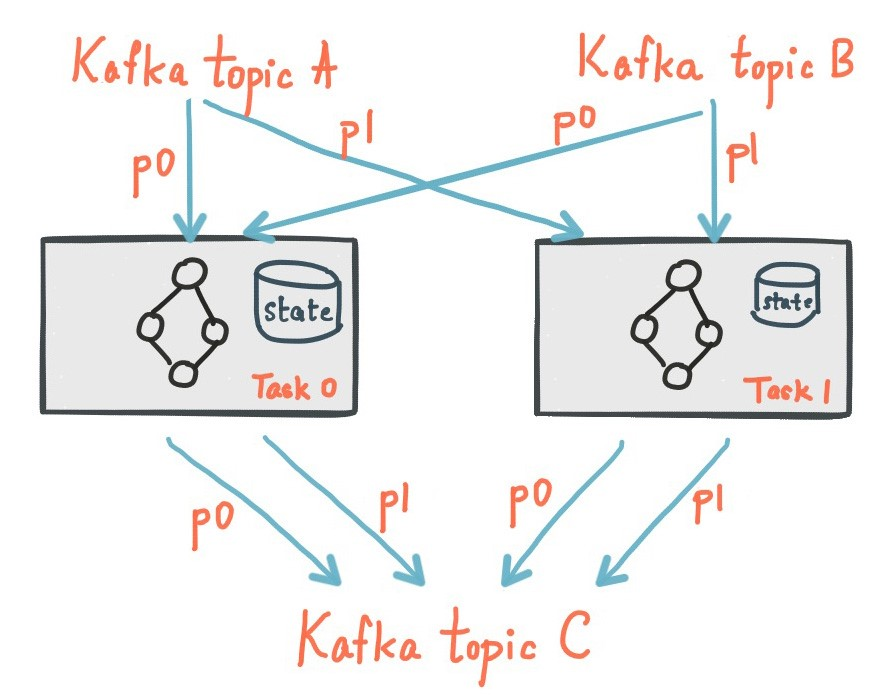
1.3 本地状态存储
存储,其实是流处理器应用程序可用来存储和查询数据,对于实现状态性操作是一个很重要的能力。例如,当你调用状态性操作时,如 join()或aggregate(),或当你在窗口化流时,Kafka Streams DSL会自动创建和管理这些状态存储。
在Kafka Streams应用程序的每个流任务可以键入一个或多个本地状态存储,这些本地状态存储可以通过API存储和查询处理所需的数据。Kafka Streams也为本地状态存储提供了容错和自动恢复的能力。
下图显示了两个流任务及其专用本地状态存储。
1.4 故障容错
Kafka Streams基于Kafka分区的高可用和副本故障容错能力。因此,当流数据持久到Kafka,即使应用程序故障,如果需要重新处理它,它也是可用的。Kafka Streams中的任务利用Kafka消费者客户端提供的故障容错的能力来处理故障。如果任务故障,Kafka Streams将自动的在剩余运行中的应用实例重新启动该任务。
此外,Kafka Streams还确保了本地状态仓库对故障的稳定性。对于每个状态仓库都维持一个追踪所有的状态更新的变更日志主题。这些变更日志主题也分区,因此,每个本地状态存储实例,任务访问仓里,都有自己的专用的变更日志分区。变更主题日志也启用了日志压缩,以便可以安全的清除旧数据,以防止主题无限制的增长。如果任务失败并在其他的机器上重新运行,则Kafka Streams在恢复新启动的任务进行处理之前,重放相应的变更日志主题,保障在故障之前将其关联的状态存储恢复。故障处理对于终端用户是完全透明的。
请注意,任务(重新)初始化的成本通常主要取决于通过重放状态仓库变更日志主题来恢复状态的时间。为了减少恢复时间,用户可以配置他们的应用程序增加本地状态的备用副本(即。完全的复制状态)。当一个任务迁移发生时,Kafka Streams尝试去分配任务给应用实例。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号