
Kafka-Consumer高CPU问题分析
一、当前配置
Flink:版本1.4
Flink-Kafka-Connector:0.10.x
Kafka-Brokers:3个
Topic-Partitoins:3个
Topic-Replication:2个
二、现象描述
Flink通过Kafka-Connector连接Kafka消费数据,当Kafka异常,Broker节点不可用时,Kafka的Consumer线程会把Flink进程的CPU打爆至100%其中:
- 一个节点不可用时:Flink可以恢复
- 二个节点不可用时:CPU持续100%
- 三个节点不可用时:CPU持续100%
三、问题分析:
CPU持续高,首先想到是Flink在消费数据时没有对异常进行处理,频繁异常打爆了CPU,我们去检查Flink的输出日志,输出日志并没有找到有价值的信息,初次分析宣告失败。
没办法,只能用动用大杀器,分析下进程的CPU占用了线程以及堆栈
1、查看占用CPU高的进程,确认无误这些进程全是Flink的JOP

2、打印进程堆栈
jstack 10348>> 10348.txt 得到进程的所有线程堆栈信息。
3、查找占用CPU高的线程
ps -mp pid -o THREAD,tid,time 查找占用cpu搞的线程
4、查看线程堆栈,发现大部分错误集中在KafkaConsumer.poll方法上。
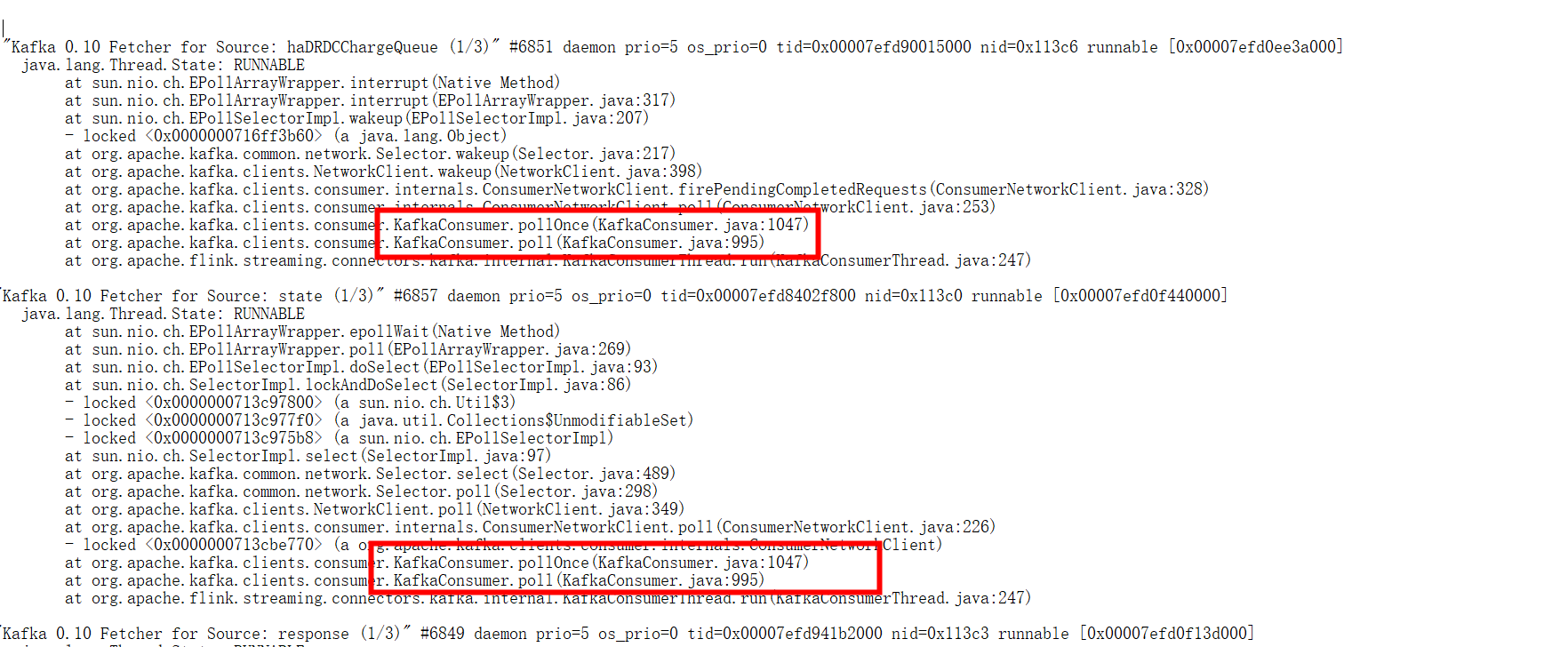
到这基本可以定位原因了,应该是Kafka的ConsumerPoll方法导致CPU高。
围绕KafkaConsumer需要指定排查计划,主要是两个方向
1、Kafka和Flink跟Poll相关的参数调整。
2、Kafka和Flink对Kafka消费时是否有Bug。
中间确实尝试了好多条路,其中
1、验证调整了KafkaConsumer的max.poll.interval.ms参数,不起作用。
2、Kafka的相关Jop并没有进行重启,所以不需要调整Flink重试相关的参数。
3、调整Flink的flink.poll-timeout参数,不起作用。
最终发现,原来是Kafka-Consumer0.10版本的一个Bug。
详细的Bug描述如下:https://issues.apache.org/jira/browse/KAFKA-5766。
有了Bug解决起来就迅速多了,根据Bug制定解决验证方案:
1、升级Flink的Kafka-ConnnectorAPI。
2、调整reconnect.backoff.ms参数。
此时升级Flink的Kafka-Connector就解决了该问题。
中间还出现一个小插曲:因为我们的复制因子是2,当其中两个节点宕机后,CPU也暴增到100%。增加了不少弯路。后分析,只有两个复制因子,1个Parition分布在两个Broker上,假如两个Broker宕机,其实是和三个集群宕机影响是一样的。
三、事后总结
1、Kafka-Topic的复制因子和分区要根据实际需要需求设置。假如有三个节点,重要的业务Topic建议分区3个,复制因子3个,用性能换稳定。
2、Kafka的0.10版的Consumer消费时,有Bug,Broder节点异常关闭时,Client会打爆CPU,0.11及以上修复。
3、Flink版本的Kafka-Connector,0.11可以消费0.10的Kafka.

