syncronized关键字
1、举例同步;
2、如何保证同步?原理
3、JDK6之前的实现
4、JDK6之后的实现过程
5、官网入手、讲解现象
6、偏向延迟和偏向不延迟
7、无锁升级到偏向锁
8、偏向锁升级到轻量级锁
9、轻量级锁升级到重量级锁
一、为什么需要syncronzied关键字
syncronzied关键字是java用来在并发场景做同步的。亲儿子
在并发场景中存在着线程安全问题。所以为了解决并发问题,使用syncronzied来进行同步操作。
案例
从一个例子入手
public class SyncronizedProOne {
private final static Logger logger = LoggerFactory.getLogger(ObjectAgeTest.class);
private static int money = 0;
private static CountDownLatch countDownLatch = new CountDownLatch(2);
public static void increment(int count){
money+=count;
}
public static void main(String[] args) throws InterruptedException {
logger.info("当前的money的值是:{}",money);
new Thread(()->{
for (int i = 0; i < 50000; i++) {
increment(2);
}
countDownLatch.countDown();
},"t1").start();
new Thread(()->{
for (int i = 0; i < 40000; i++) {
increment(5);
}
countDownLatch.countDown();
},"t2").start();
countDownLatch.await();
logger.info("当前的money的值是:{}",money);
}
}
理想中的money的值应该是:300000。但是最终控制台打印的值是:239946
出现问题
主要是下面这行代码,二者是等价的
money+=count; <===> money = money + count
这里因为是非原子性的操作。
假设在某个时刻,money的值是100,t1线程在执行加法操作的时候,t1线程看到的money是100,然后执行完加法之后得到101,这个时候t1线程发生了上下文切换,那么就会导致101还没有来得及赋值给money。
而上下文切换到t2的时候,发现money还是100,那么t2执行加法之后,给Money进行赋值为101。然后上下文再次切换,t1将101赋值给money,此时money也是101.
那么本来结果是102,但是两次加法之后,造成了结果是101,所以导致出现了数据安全问题。
解决问题
那么如何才能让其变成对的值呢?那么只需要在:money=money+count,这个阶段能够保证是原子性操作即可。
而且还要能够让多线程及时看到money的变化。那么首先对加法赋予原子性操作即可,保证可见性问题,只需要加上一个volatile关键字即可。
如下所示:
public class SyncronizedProTwo {
private final static Logger logger = LoggerFactory.getLogger(ObjectAgeTest.class);
private static volatile int money = 0;
private static CountDownLatch countDownLatch = new CountDownLatch(2);
public static void increment(int count){
money+=count;
}
private static Object lock = new Object();
public static void main(String[] args) throws InterruptedException {
logger.info("当前的money的值是:{}",money);
new Thread(()->{
synchronized (lock){
for (int i = 0; i < 50000; i++) {
increment(2);
}
}
countDownLatch.countDown();
},"t1").start();
new Thread(()->{
synchronized (lock) {
for (int i = 0; i < 40000; i++) {
increment(5);
}
}
countDownLatch.countDown();
},"t2").start();
countDownLatch.await();
logger.info("当前的money的值是:{}",money);
}
}
测试了多次输出结果:300000
syncronzied使用方式
syncronzied是可以解决线程安全问题的。但是上面的使用方式仅仅只是syncronzied关键字的使用方式之一。
因为syncronzied的使用方式比较固定,所以将其列出来:
| 作用范围 | 锁对象 |
|---|---|
| 非静态方法 | 当前对象 => this |
| 静态方法 | 类对象 => SynchronizedSample.class (一切皆对象,这个是类对象) |
| 代码块 | 指定对象 => lock (以上面的代码为例) |
思考
从使用方式上列举出来的,可以看到,不管是哪种使用方式锁对象都是一个明确的对象。
为什么????
先来看一下lock锁中的设计原理。
lock锁中用一个变量state作为锁是否被持有的一个标记,而syncronzied锁住的是一个对象,那么对象中哪里有标记这个标识呢?
难道是在对象中定义一个属性来表示标记么?如下:
public class LockFlag{
private int state;
}
但是很明显的是,对象也可能是没有属性。如Object,而且上面使用的锁对象正是Object类型的对象。
那么既然这样子可以实现,那么很明显在堆内存中对象是可以进行标记的。那么就需要来了解堆内存中的对象是怎样的?
二、对象分析
JVM规范中规定:对象由三部分组成:对象头、对象中的实例数据(可有可无,Object对象就没有)、对齐填充(以8个bit为单位,java对象的大小必须是8的倍数,如果不足8的倍数,需要进行填充到8的倍数)
所谓的实例数据如下所示:
public class A{
// 实例数据
private int age;
}
因为对象中可能不存在实例数据,所以这个不是本篇研究的重点。
那么重点就应该是对象头了。
2.1、对象头打印
对象头我们可以利用JOL工具类来进行分析
<!-- https://mvnrepository.com/artifact/org.openjdk.jol/jol-core -->
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
<!-- 这里将provided给去掉了 -->
</dependency>
然后写测试代码来进行测试:
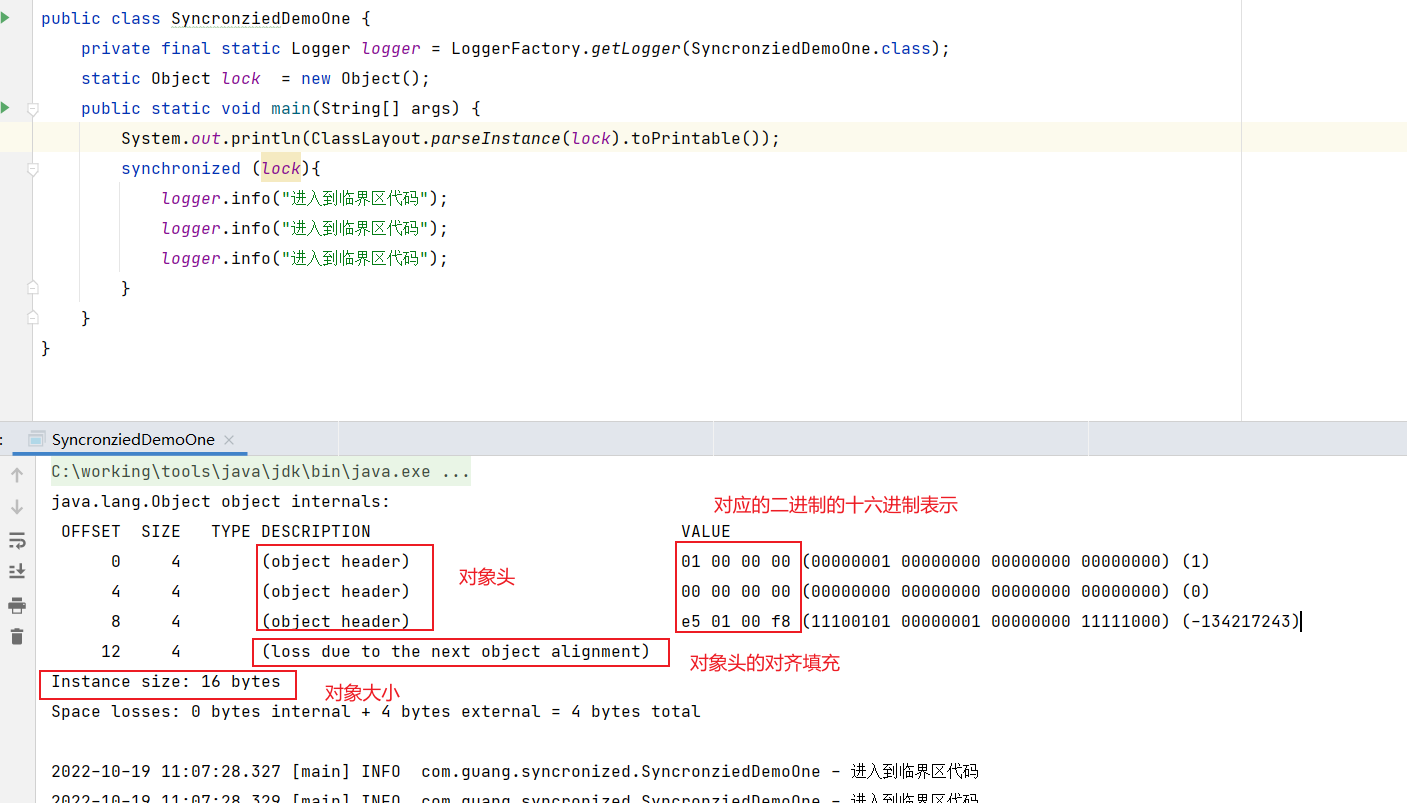
因为使用的Object类型的,没有实例数据,所以在上面没有体现出来。
但是看到了Object数据类型的大小占据了16个字节。在一道面试题中见到过,记录一下。
2.2、JVM对对象头的规范
从ORACLE中的官网中爬取下来的一部分截图:

每个在堆中的对象有公共的结构。在堆中的对象对象头的布局中,Type,GC状态、同步状态、对象hashcode
对象头由两个关键字:mark word和klass pointer组成
如果是数组的话,还有一个长度字段。
对关键属性分析一下:

这里解释了为什么可以通过:obj.getClass()方法得到对象的类的类型。
而上面的状态的标识又都是在mark word和klass pointer中的。
所以需要来了解一下mark word和klass pointer又都是什么?
klass pointer
表示指向一个对象,这个对象中可以看到对象布局和方法;
也就说klass pointer指针指向的java中的类的地址(或者是说指向java类中的首地址,也就是class文件的地址(方法区中的首地址));
mark word
看官方文档中的说明:
用二进制表示同步状态、hashcode。可能会在二进制中低位同步关联状态。在GC期间,可能会有GC状态标记。
可以知道,mark word中二进制是会变化的,因为需要表示这么多的状态。
那么来看下HotSpot虚拟机中对mark word的说明:

可以看到在64位操作系统中至少存在着四种状态的变化。
那么这里来做一个总结:
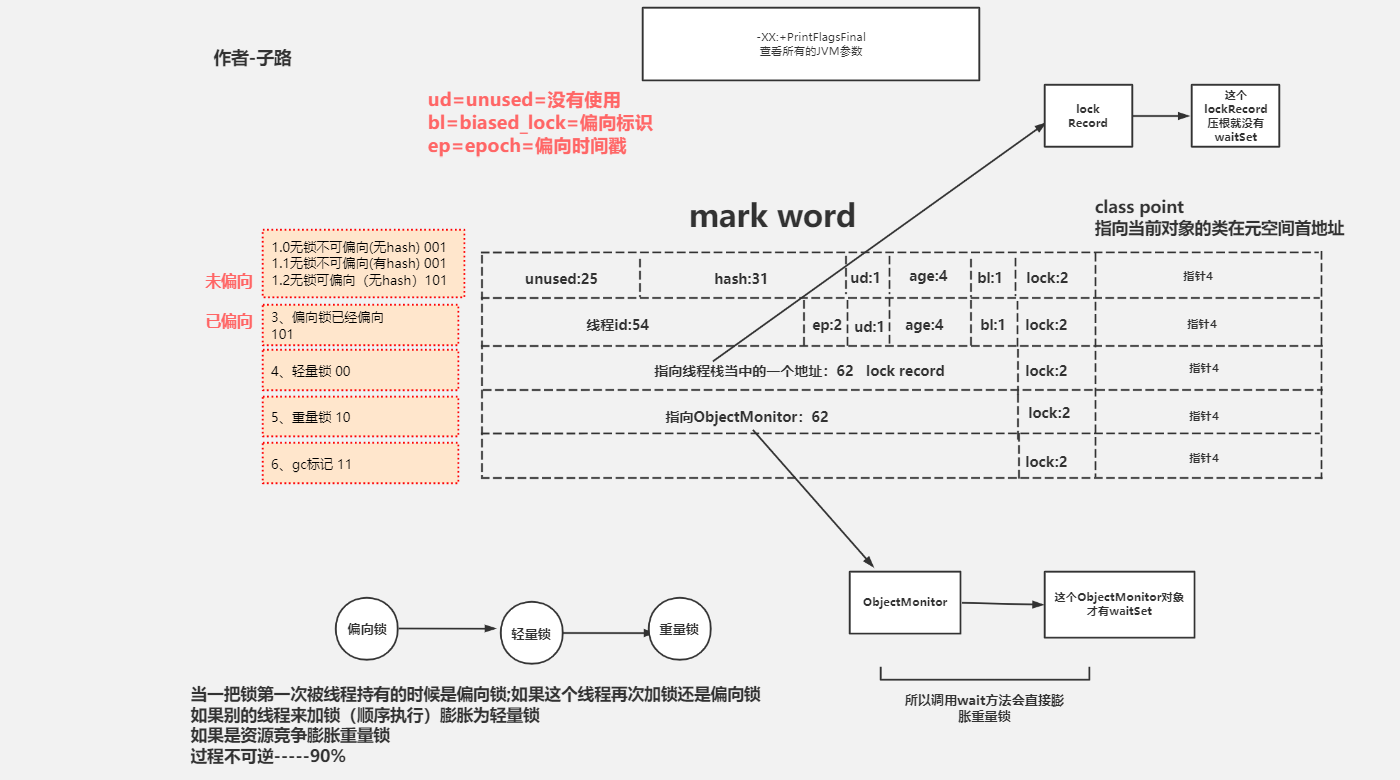
对象头怎么来看?
上面已经通过JOL工具类来打印对象头的二进制标志位了。但是这里打印的二进制为和我们理解的有点问题。
为了解释,下面来写段代码表示:
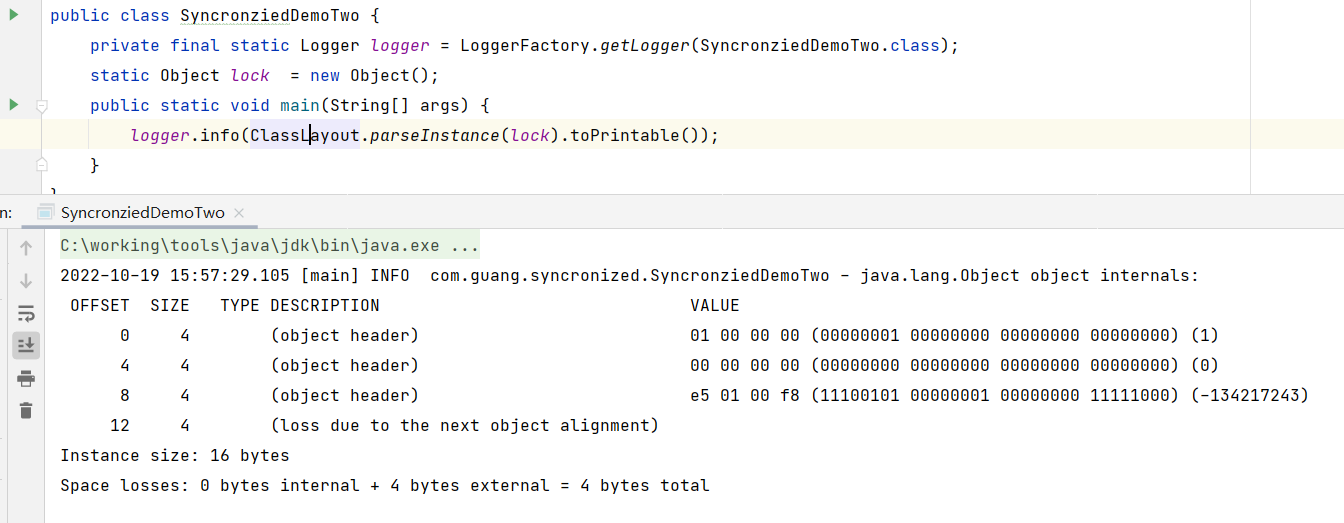
打印出来的对象头如下所示:
00000001 00000000 00000000 00000000 00000000 00000000 00000000 00000000
但是此时此刻一定要注意的是:因为X86架构计算机中是按照小端存储的。
如下所示:
!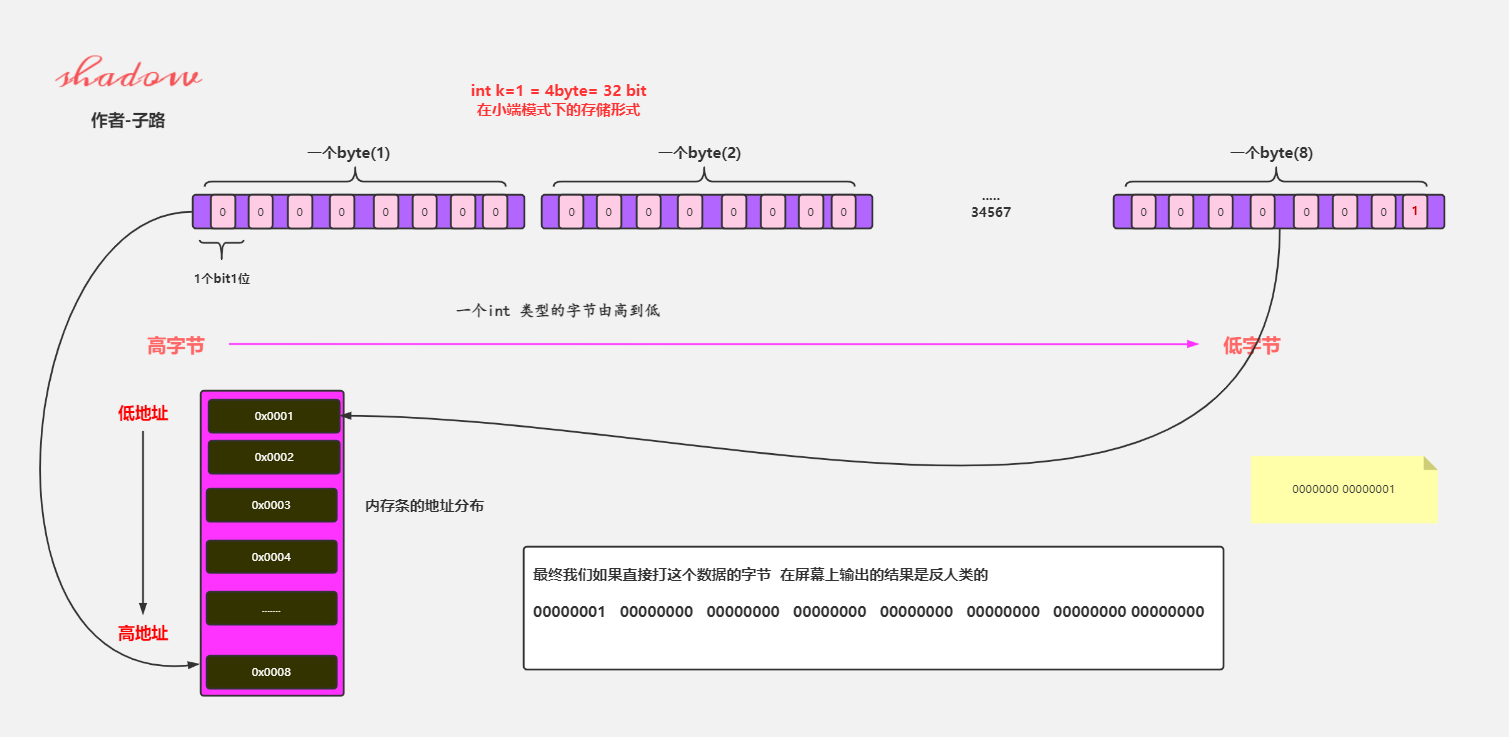
高位存在高地址,低位存在低地址。而在读的时候,也会从低位开始读,所以读取出来的顺序和我们看到的顺序是相反的。
那么将对应的二进制反过来看一下:
00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001
然后对照着上面的总结图来看一下:
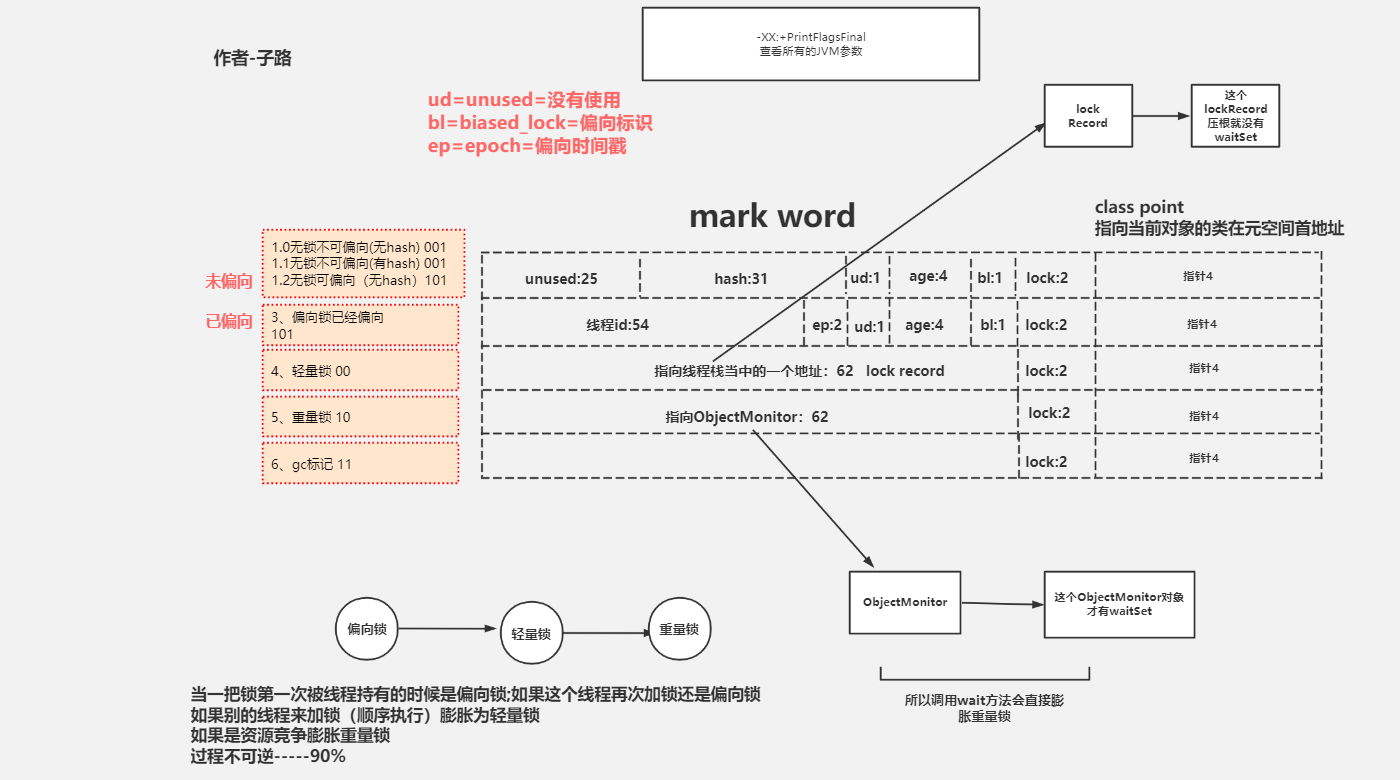
按照上面的未偏向划分:
00000000 00000000 00000000 0 未使用
0000000 00000000 00000000 00000000 hashcode
0 没有被使用
0000 GC + 对象年龄
0 偏向标识 (0不可以偏向线程;1表示可以偏向线程)
01 锁的状态。偏向锁、轻量级锁、重量级锁、GC标记
01 偏向锁
10 轻量级锁
11 重量级锁
00 GC标记
所以这样子来研究才是对的。
三、syncronized关键字的几种状态说明
无锁状态
对于一个对象来说,在没有进入到同步块中时,都是无锁状态。
无锁状态下又划分成两个状态:是否可偏向。
是否可偏向的意思就是说,对于lock对象锁来说,是否可以让锁对象偏向某个线程。
在JVM中,规定了项目启动的四秒钟内是禁止可偏向的。
为什么?这个在研究下面的状态后再来分析。
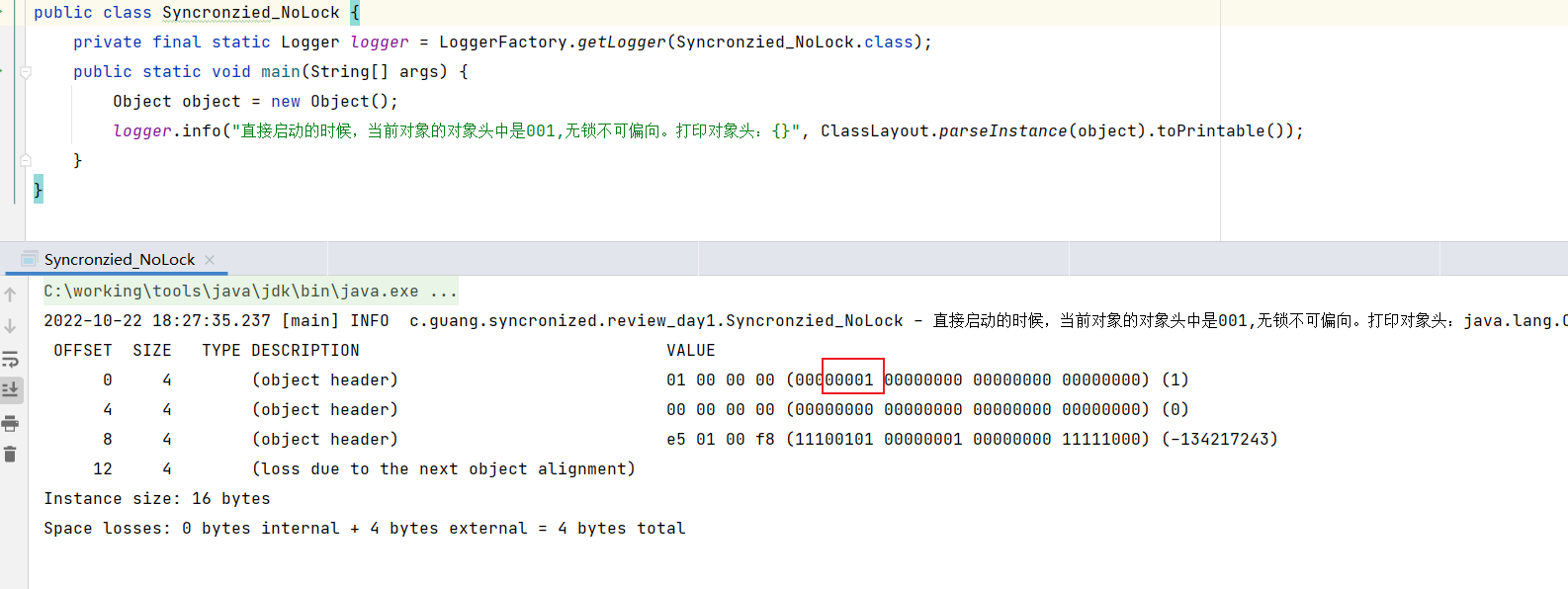
无锁不可偏向
默认情况下,项目启动的时候,就是无锁不可偏向的。直接看下代码:
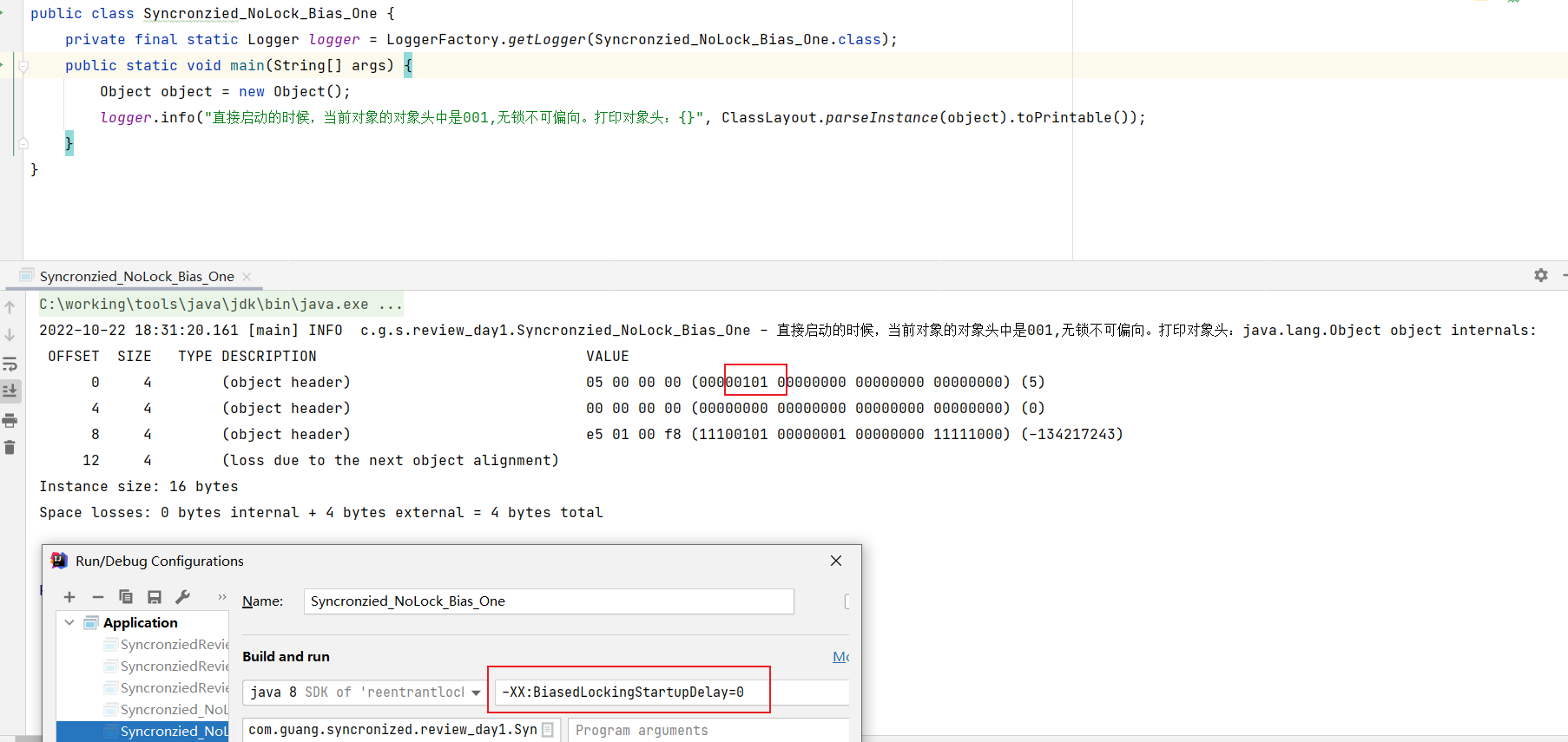
无锁可偏向
我们有两种方式可以获取得到无锁可偏向。
- 1、设置偏向延迟为0;在idea中添加VM参数:-XX:BiasedLockingStartupDelay=0
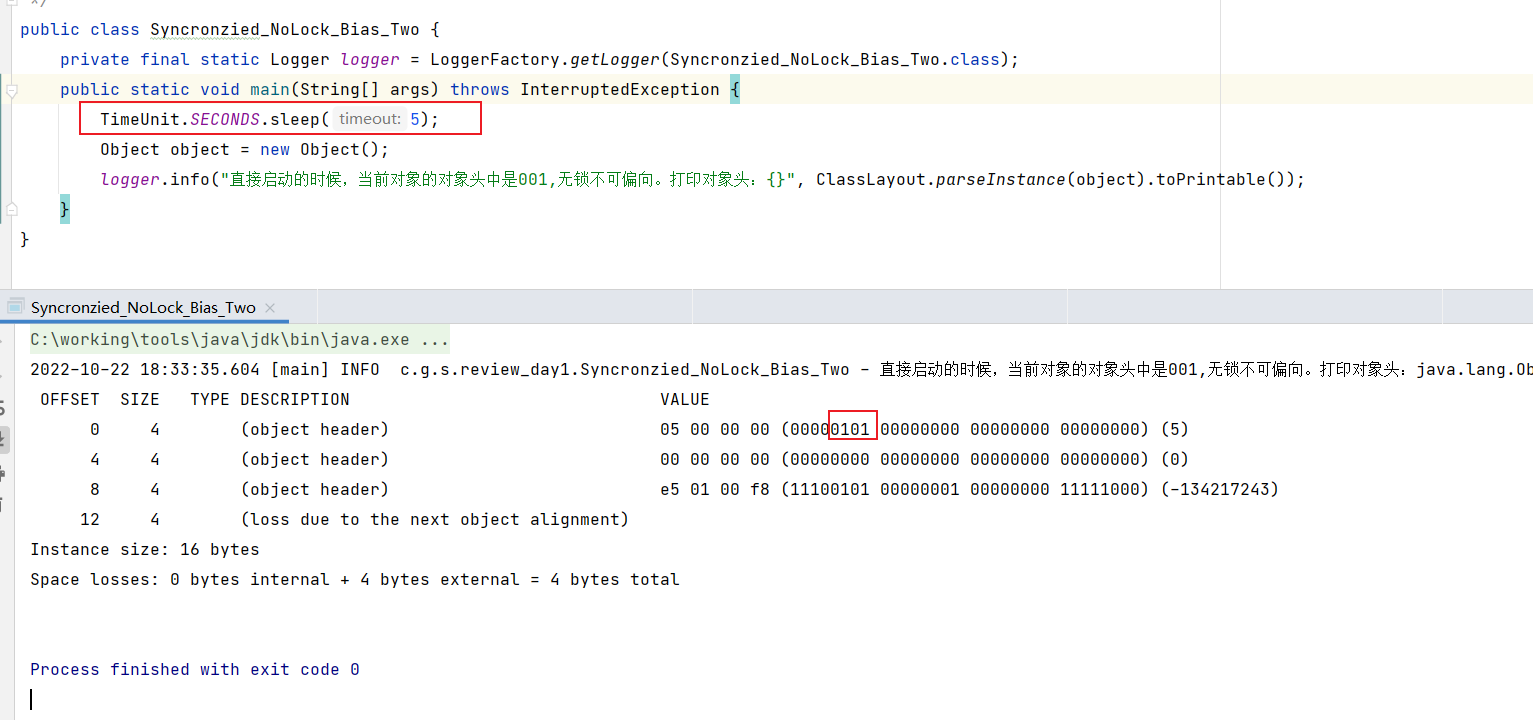
- 2、让线程先睡眠,再运行程序;
分别来测试一下:
注意:我忘记了修改注释了,所以下面两个测试不要看注释
1、设置偏向延迟为0
2、线程睡眠
偏向锁
大前提:当锁对象为无锁可偏向时,如果线程进入到同步代码块中来,那么将会导致锁对象的对象头偏向当前线程。
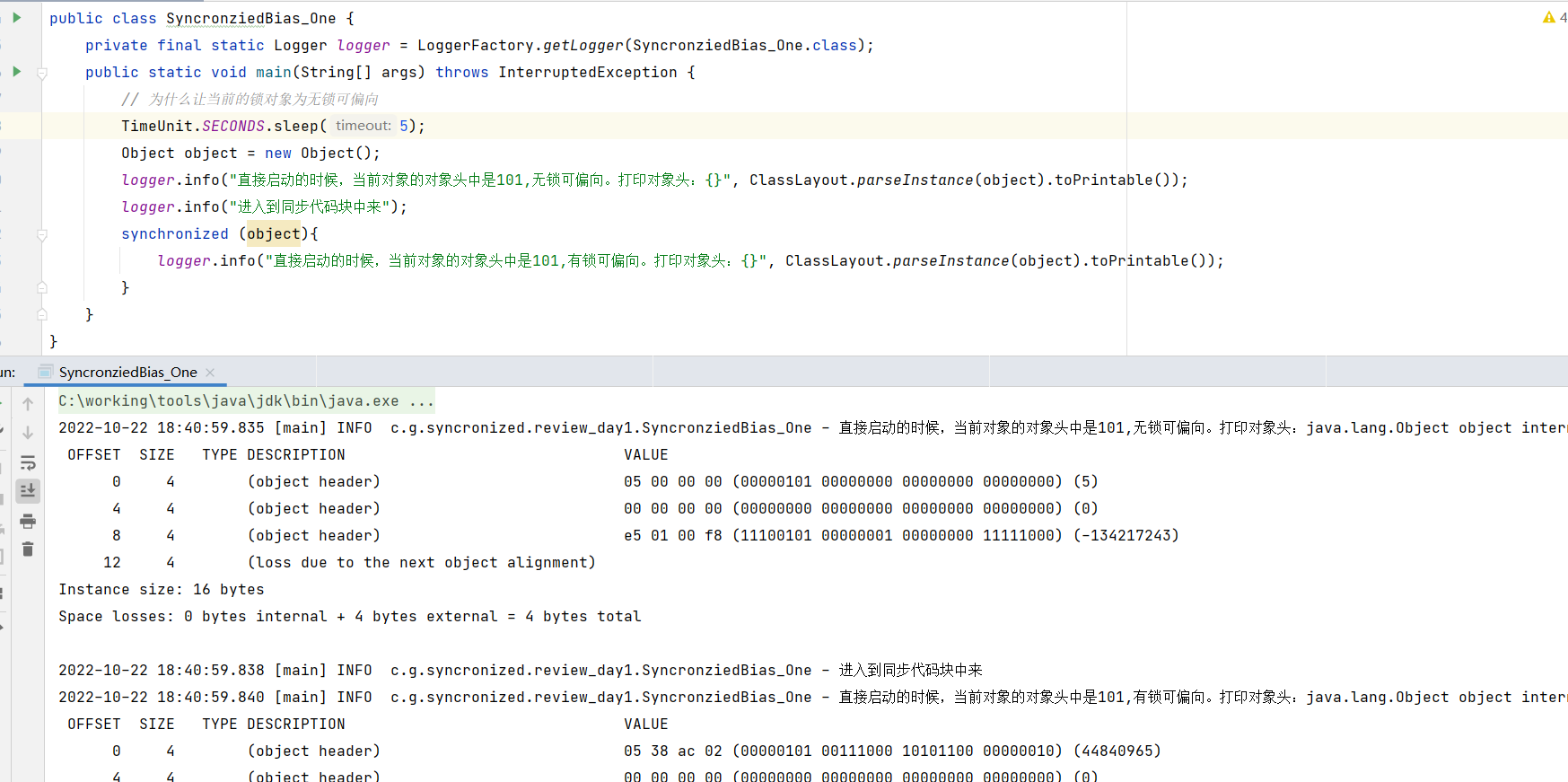
仔细观察一下,可以发现:尽管对象头中标记都是101,但是发现后面的不同。
因为在偏向锁中,需要记录一下偏向锁偏向线程的ID。这里是不同的。
轻量级锁
轻量级锁是如何发生的呢?
我总结了一下,分为以下两种情况:
- 1、多个线程交替执行;没有交集;
- 2、多个线程互斥执行;
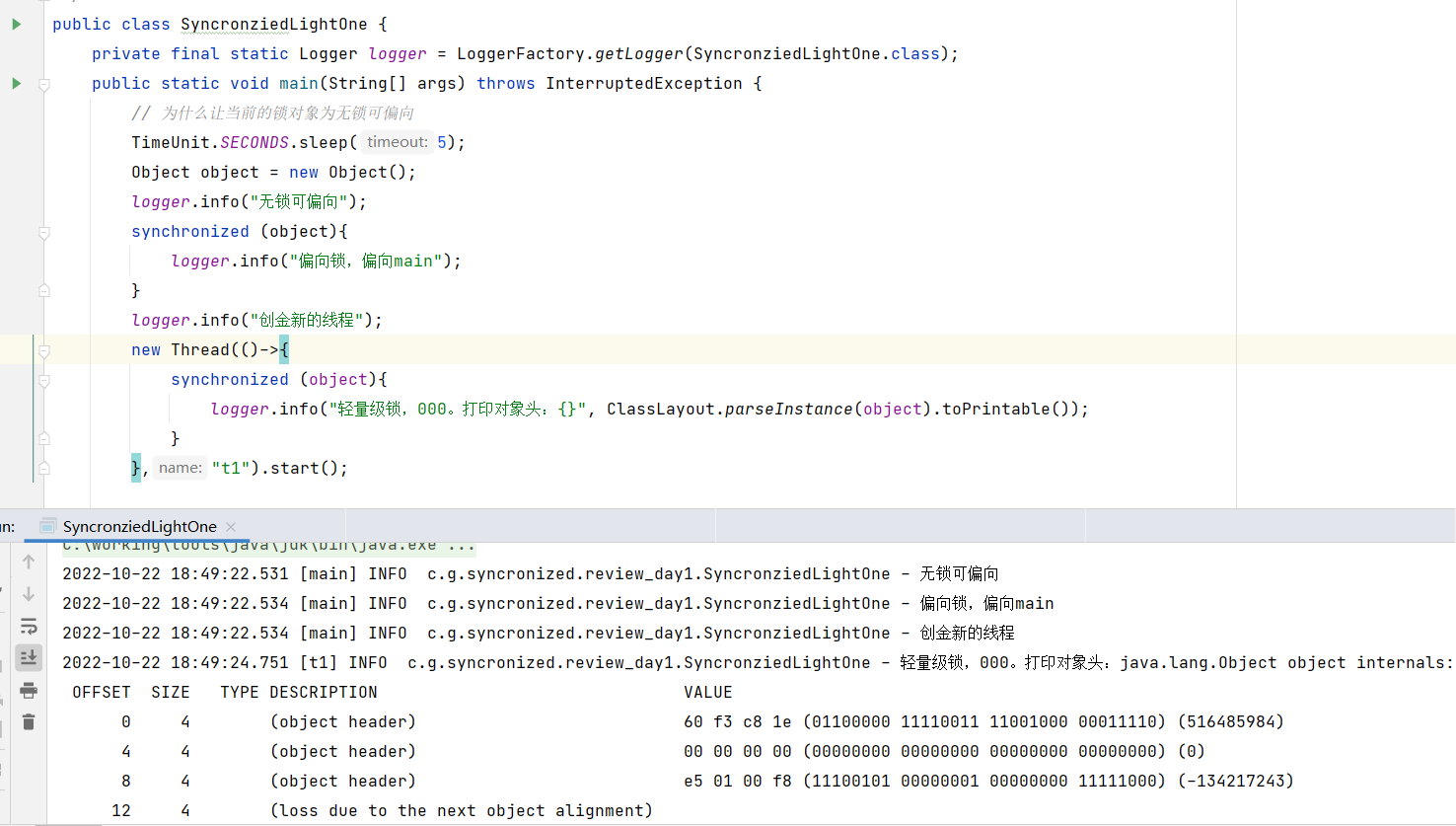
下面写代码看一下:
1、多个线程交替执行
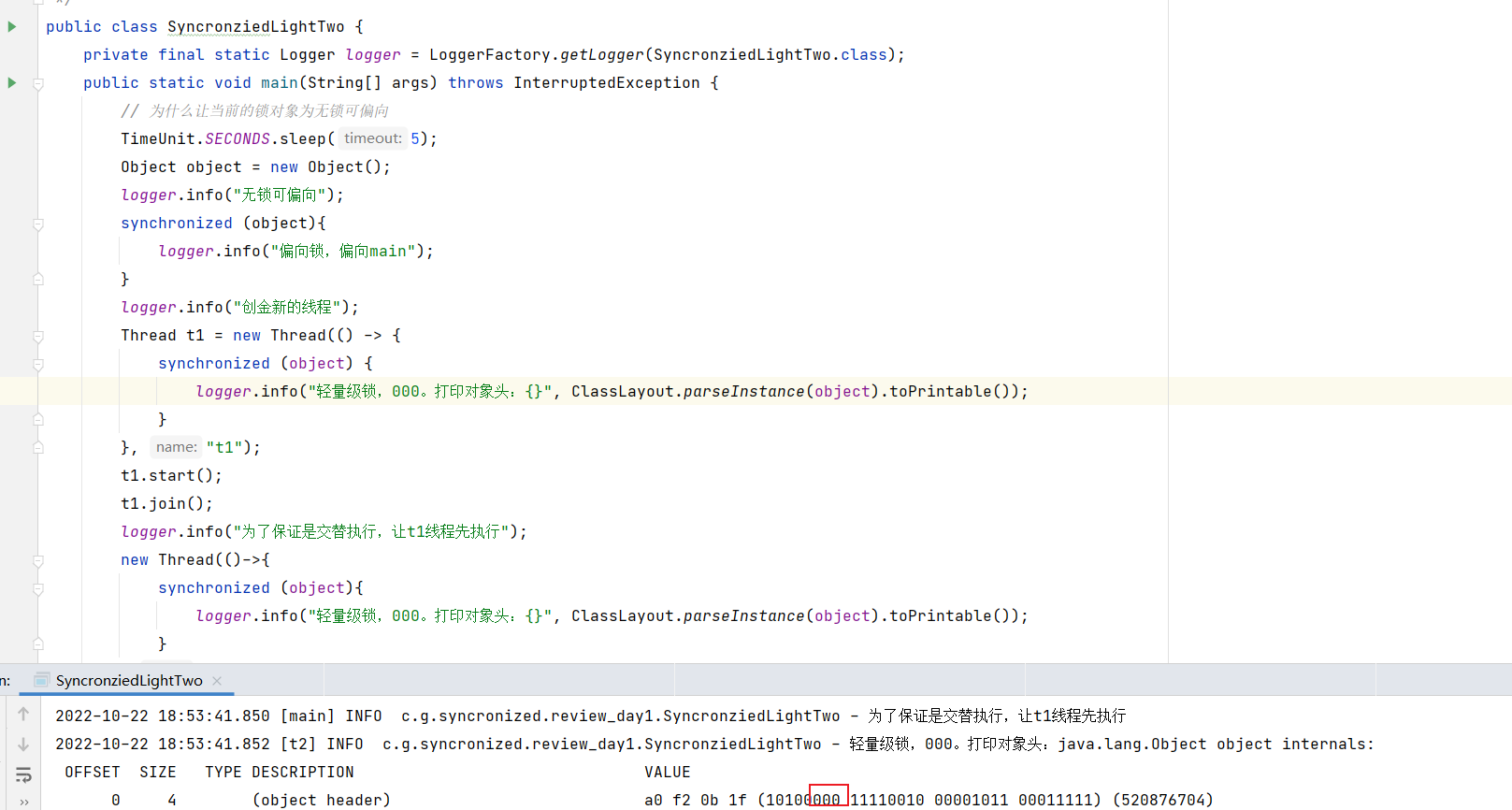
2、多个线程互斥执行;
重量级锁
在某一时刻,同步块中的锁产生了竞争。
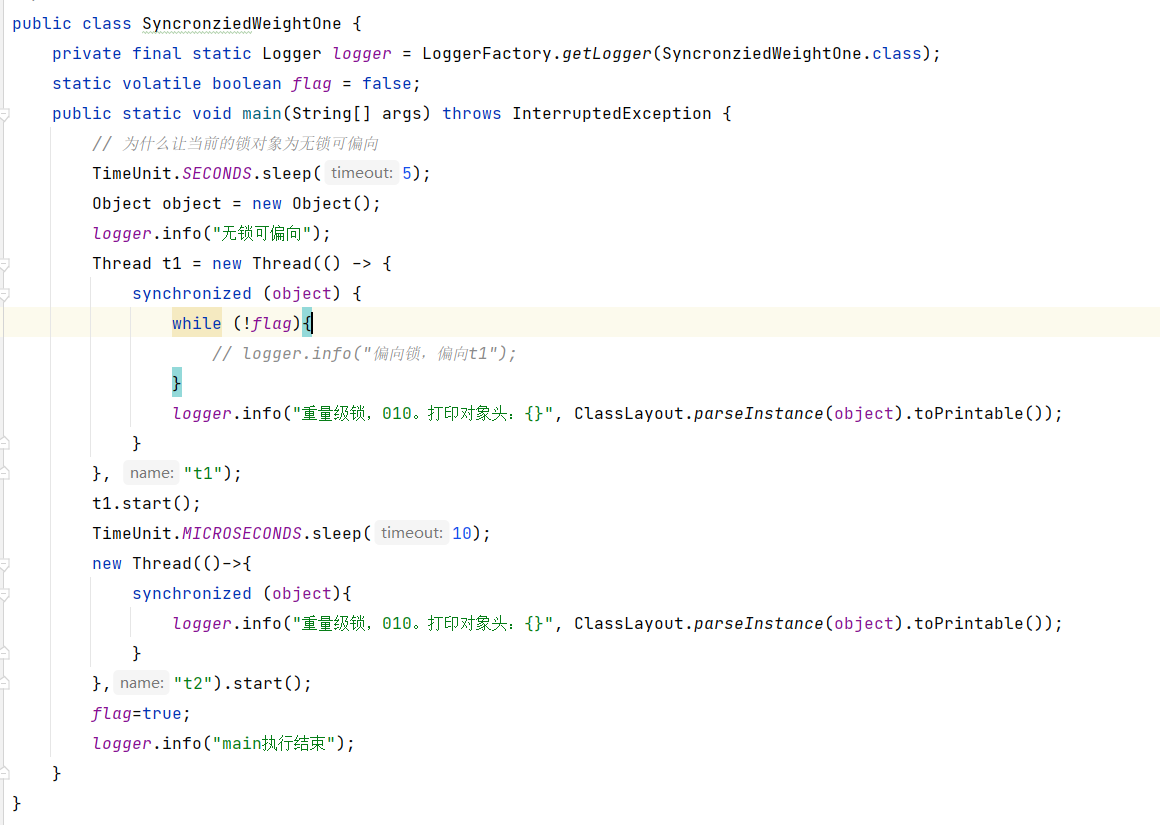
对应的打印结果看下:
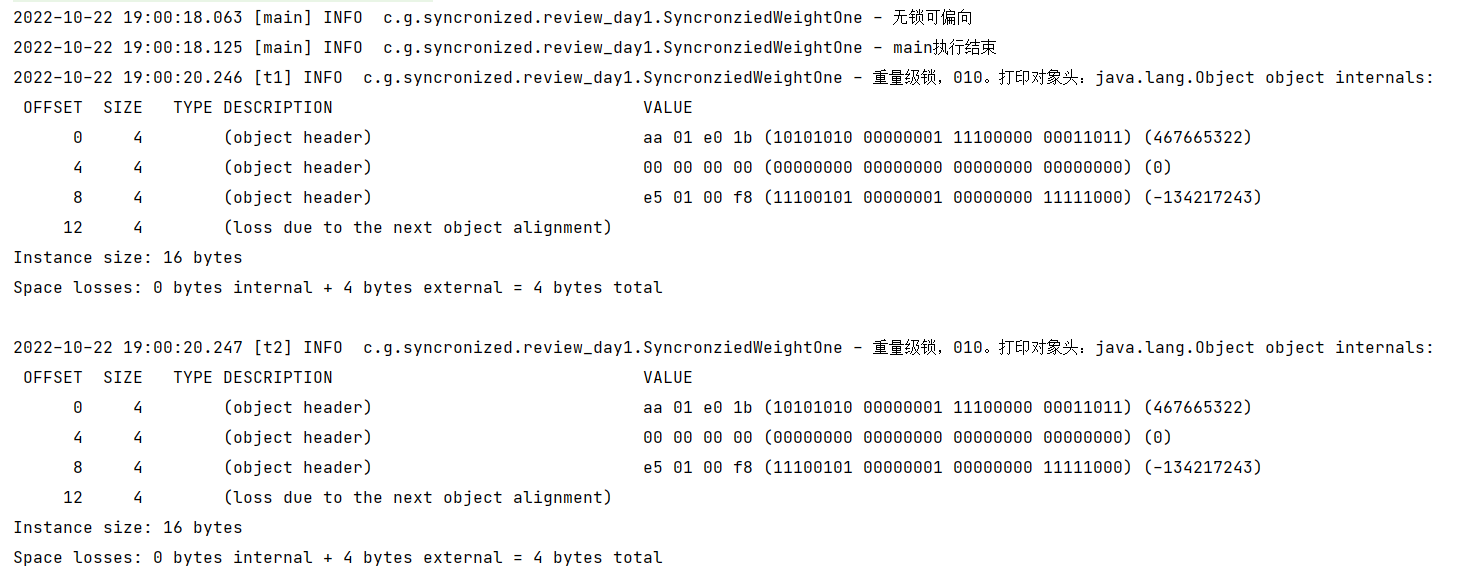
补充说明
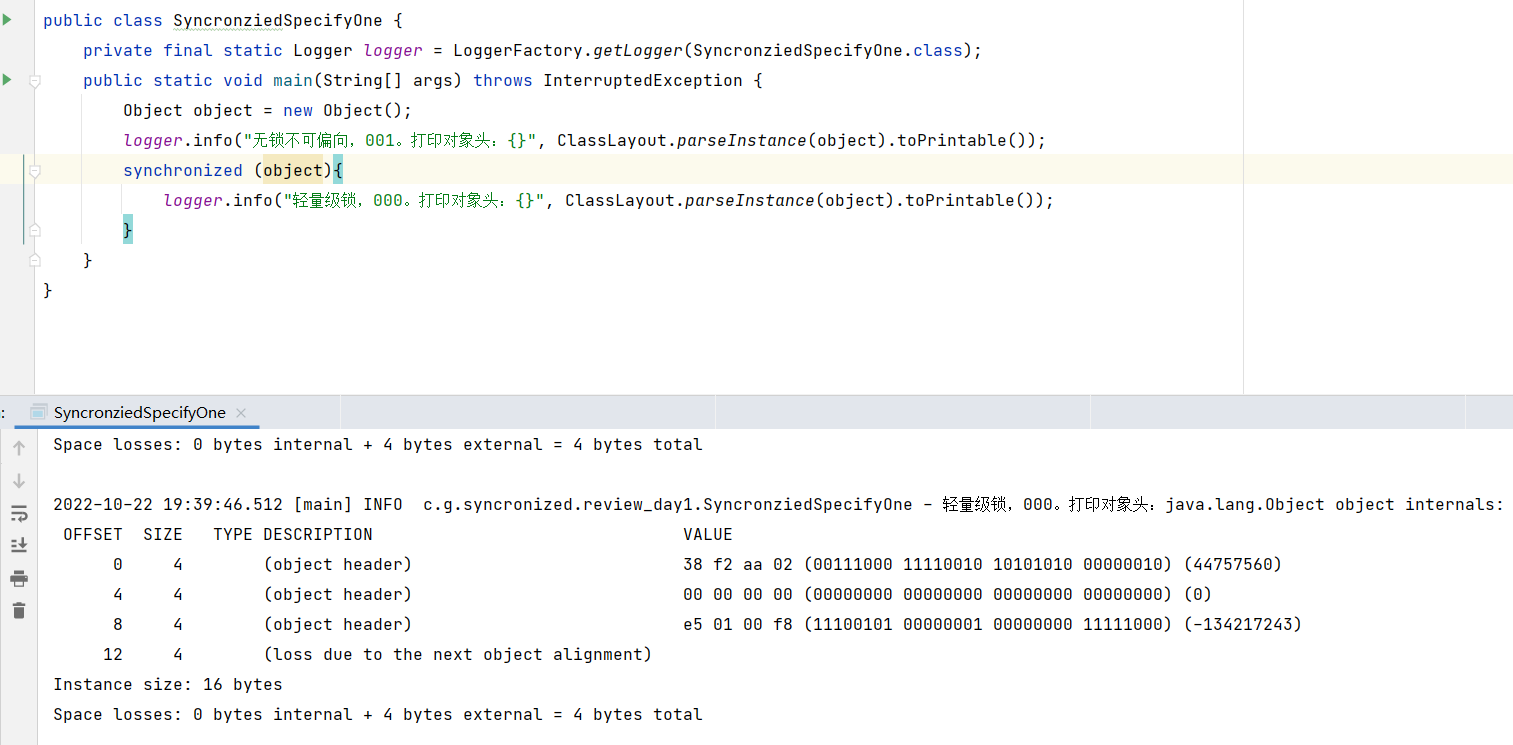
但是有几种情况不得不来补充一下,以下几种场景分别都是存在的。
锁对象不可偏向时进入到同步代码块,直接进入到轻量级锁
代码演示:
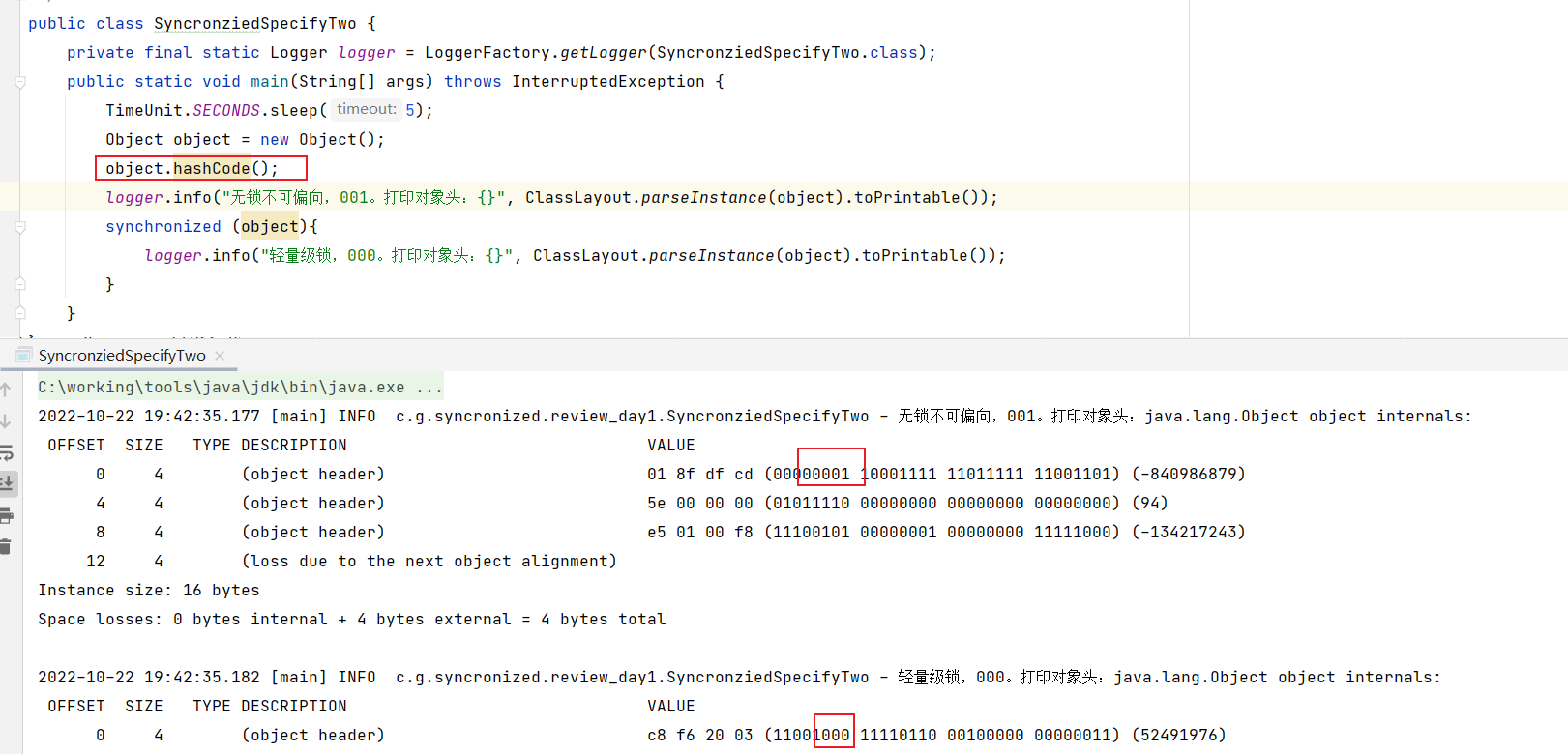
对象调用hashcode进入到同步块中,直接升级成轻量级锁
又忘了修改注释了,不要看注释
锁对象调用wait方法会直接进入到重量级锁
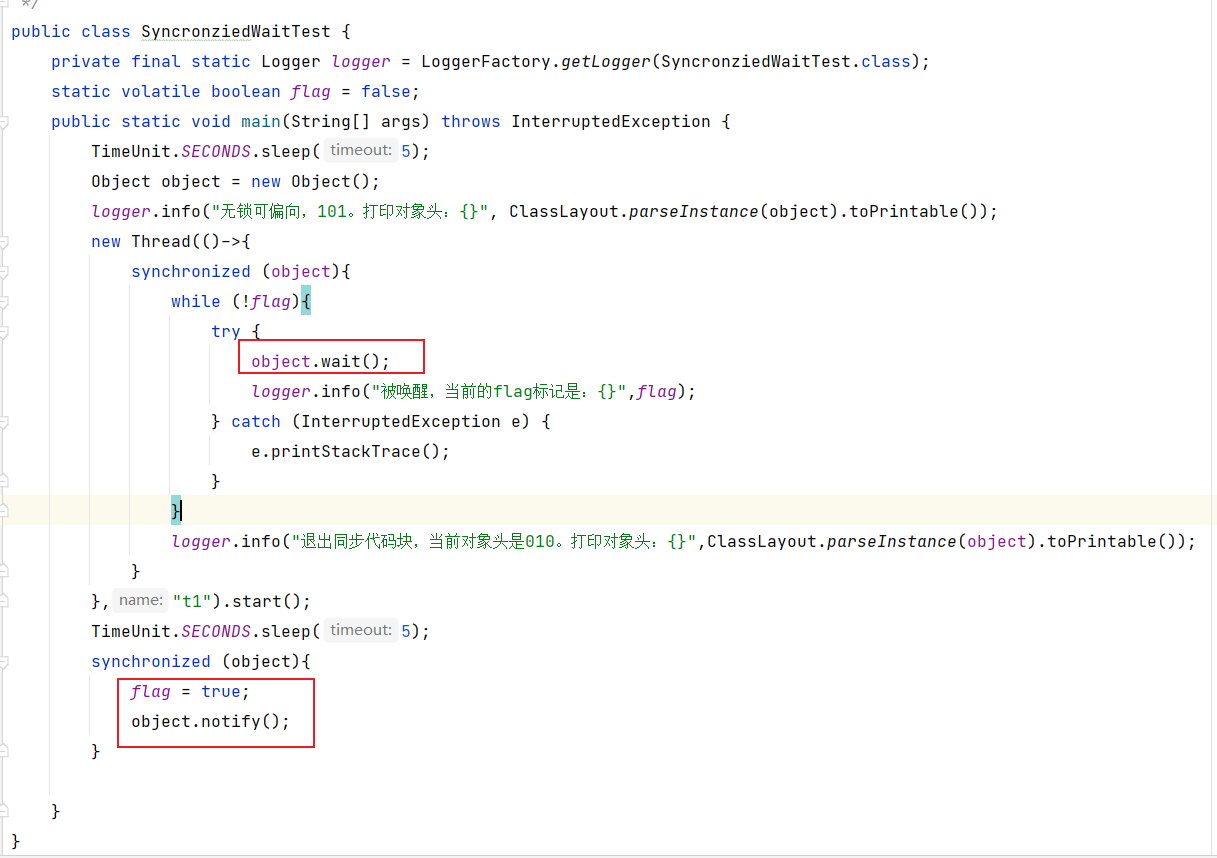
对应输出:
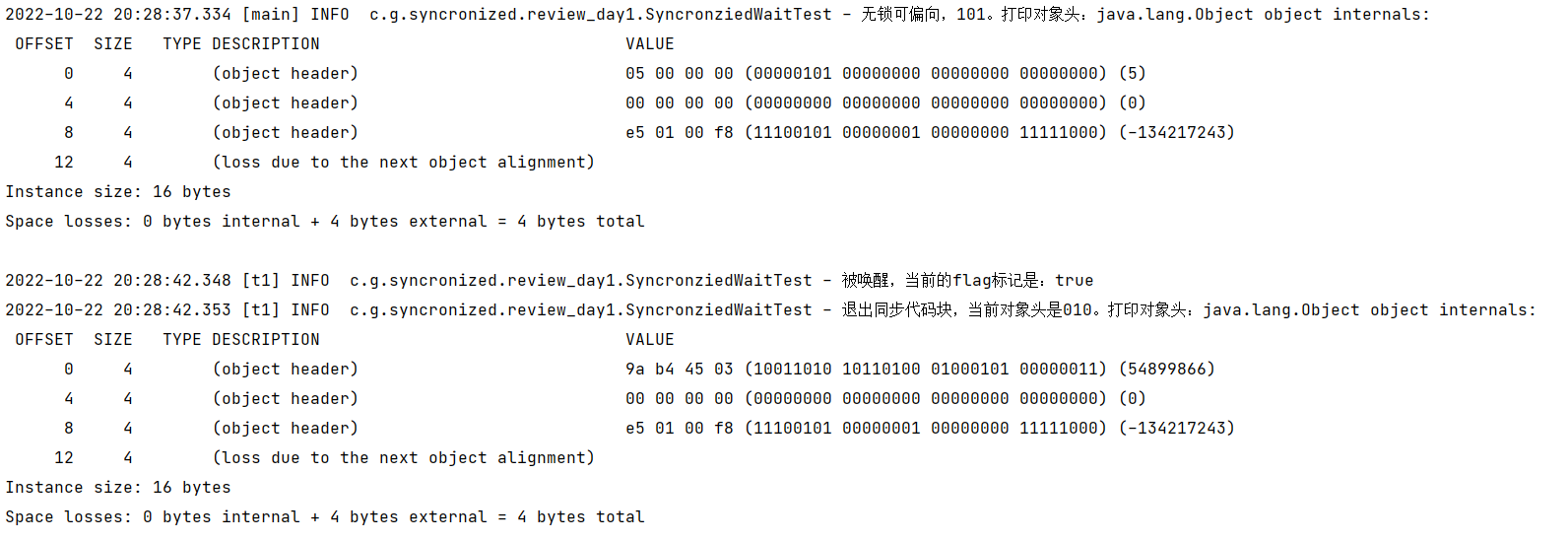
补充一个特殊代码
对应的输出:

这里很奇怪,按照我们的理解,t2线程对象头中的信息应该是000才对,但是这里是101.
偏向锁,而且偏向的线程居然还是t1.
所以这里我才要来补充说明:
因为没有专业测试大佬和底层知识,所以只能够靠自己的猜想来进行猜测,然后给出自己的证明过程。
我的猜测:
在我看来,因为t1线程执行完成了,OS应该是释放了资源。但是在给t2线程分配资源的时候,复用了原来的线程ID号。
因为OS分配的线程号我们不知道是不是一样的。
但是对于JVM来说,JVM知道肯定不会是同一个线程的,但是对于syncronzied关键字来说,他是根据线程ID来判断的。
因为t2线程复用的线程t1的ID号,所以t2线程中认为当前线程(本来说是t2),认为是t1线程的ID。
所以没有发生锁撤销,直接复用了。
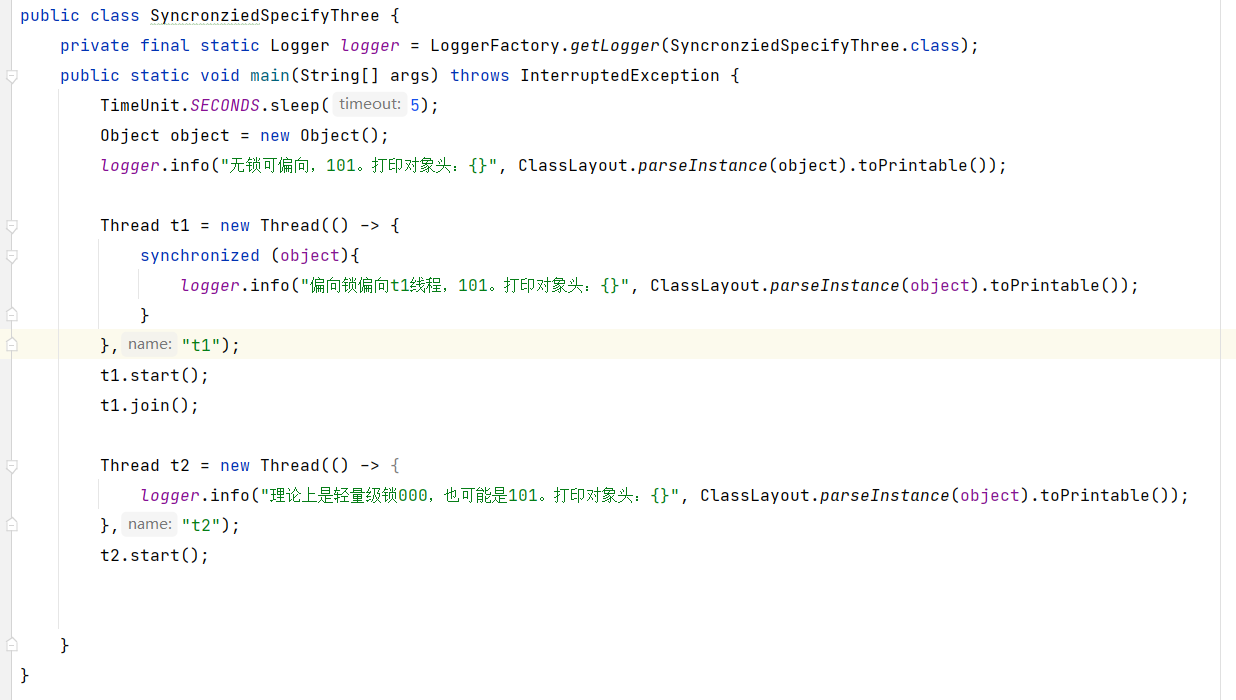
代码证明
但是证明失败!!!!!
于是乎,我以为是JVM中的线程ID被复用了,我又从Thread类中找到了关于线程ID的描述
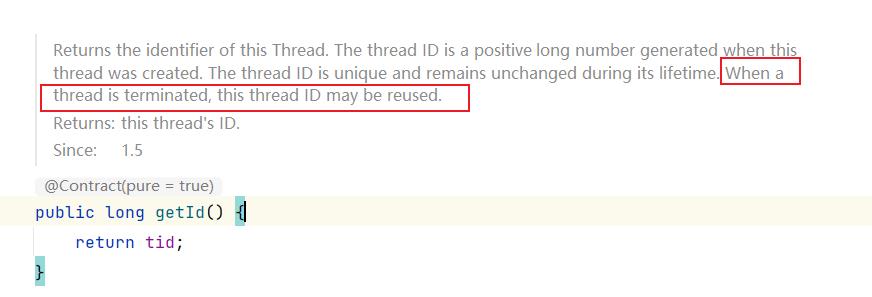
线程在其生命周期中是一个唯一且不可改变的。
只有当线程终止的时候,线程的ID号才可能被复用。
因为当前t1线程没有终止,所以对于JVM中的线程ID来说,是不可能被复用的。
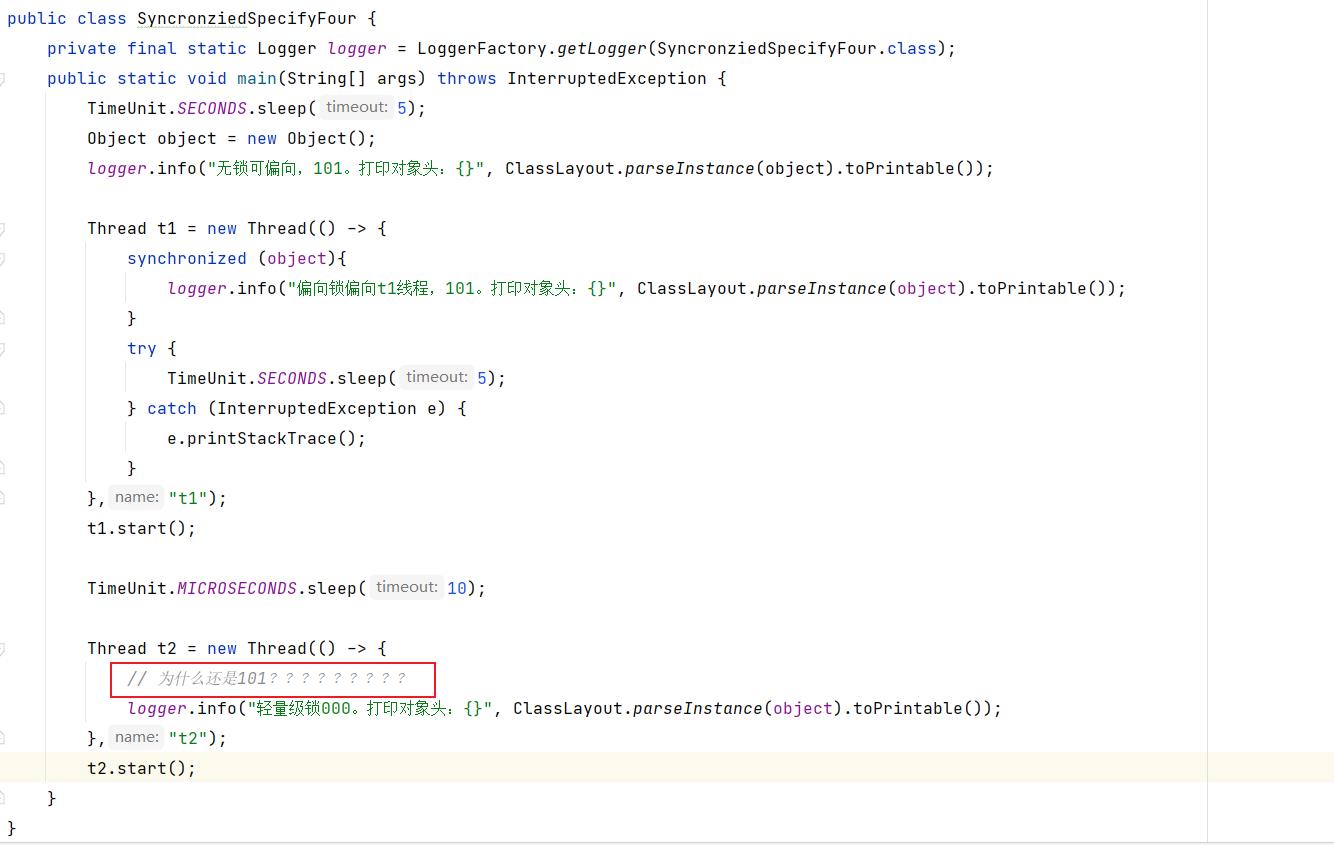
但是我检查了代码,发现t2线程根本没有加锁!!!!!!!!!!!!
于是乎,马上加锁看看
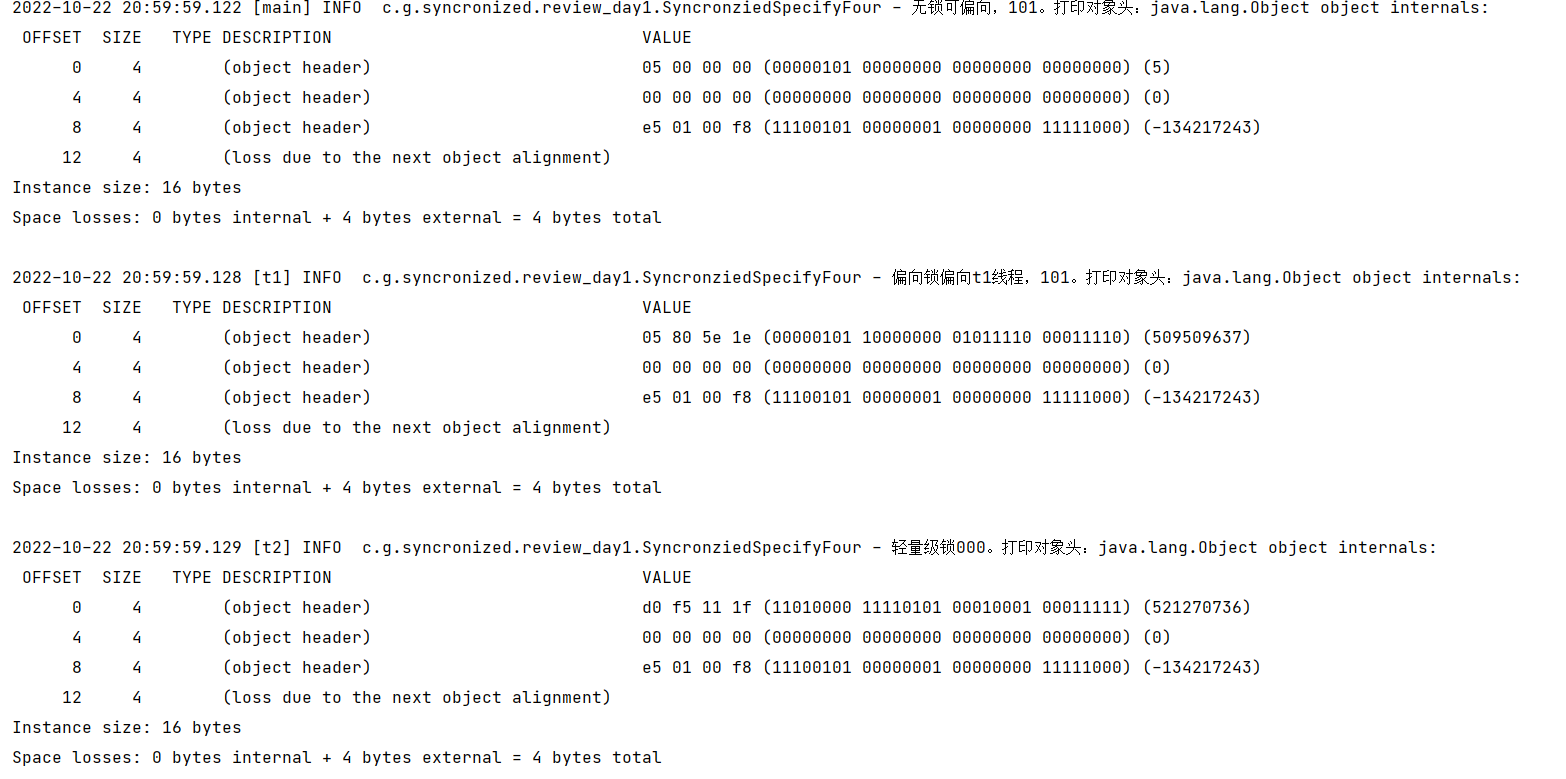
马上变成了轻量级锁。
但是我又马上写了另外一个代码。

测试结果:
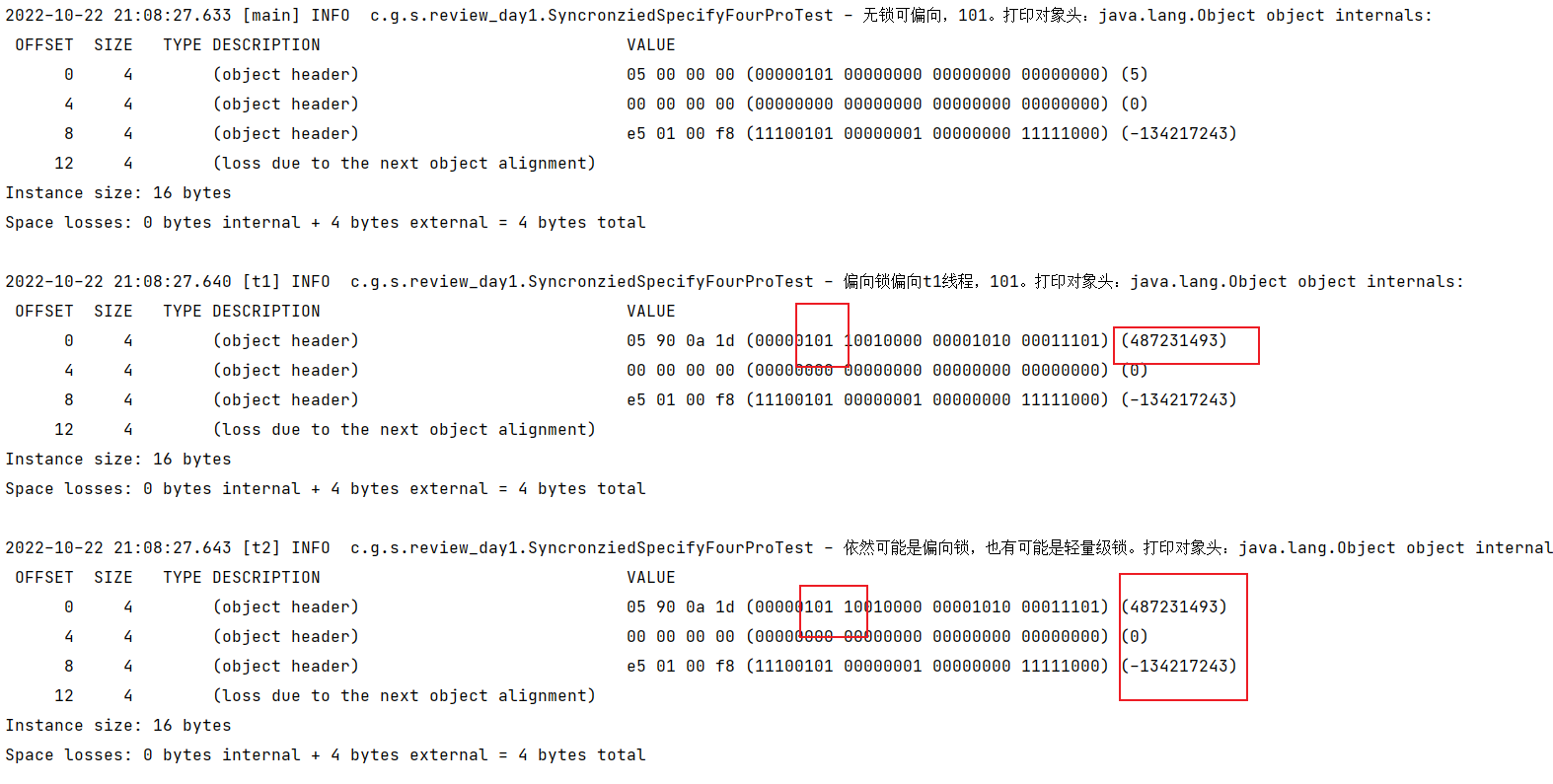
完美的解决方案。
四、锁升级过程
偏向锁升级到轻量级锁
引用安琪拉博客中的一张流程图
从无锁到偏向锁转化的过程(JVM -XX:+UseBiasedLocking 开启偏向锁)
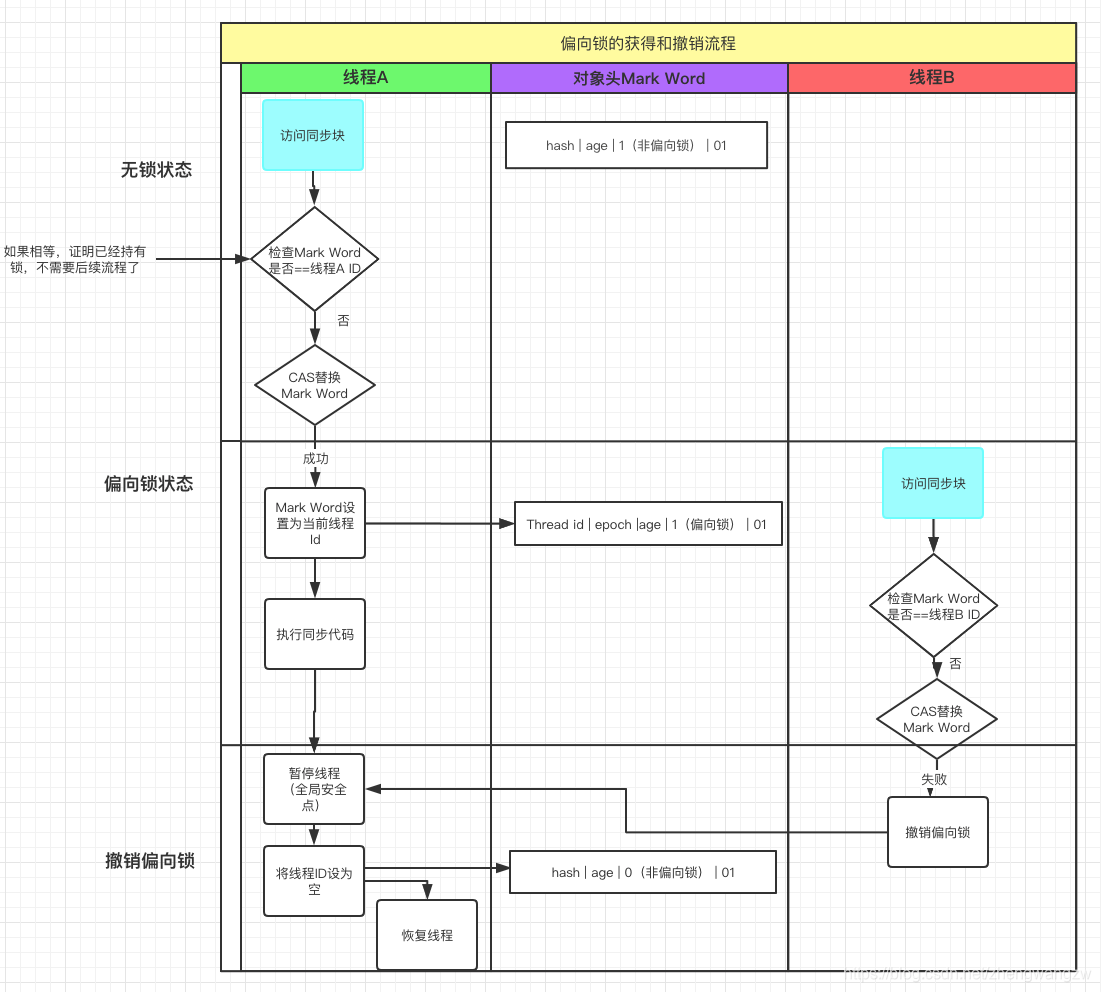
- 1、首先A 线程访问同步代码块,使用CAS 操作将Lock对象的Thread ID 放到
Mark Word当中,表示偏向这个线程; - 2、如果CAS 成功,此时线程A 就获取了锁;
- 3、如果线程CAS 失败,证明有别的线程持有锁,例如上图的线程B 来CAS 就失败的,这个时候启动偏向锁撤销 (revoke bias);
- 4、锁撤销流程:
-
- 1-1、 让 A线程在全局安全点阻塞(类似于GC前线程在安全点阻塞);
- 1-2、遍历线程栈,查看是否有被锁对象的锁记录( Lock Record);如果有Lock Record,需要修复锁记录和Markword,使其变成无锁状态;
- 1-3、恢复A线程执行,将是否为偏向锁状态置为 0 ,开始进行轻量级加锁流程 (后面讲述)
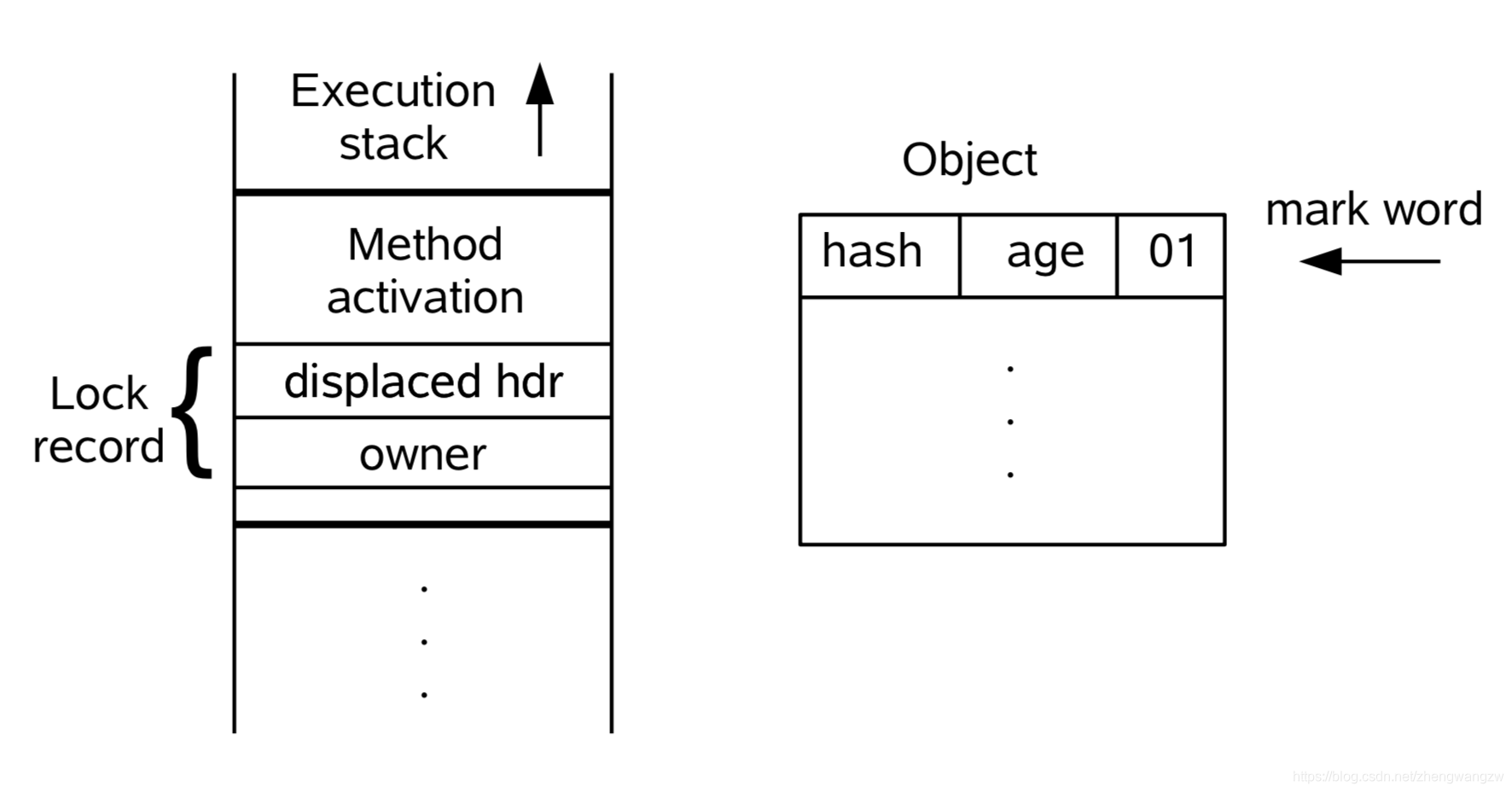
下面看下这个Lock Record的过程:
锁撤销之后(偏向锁状态为0,表示不可偏向任何线程)。现在无论是A线程还是B线程执行到同步代码块进行加锁,流程如下:
- 1、线程在自己的栈桢中创建锁记录 LockRecord;
- 2、线程A 将
Mark Word拷贝到线程栈的 Lock Record中,这个位置叫 displayced hdr,如下图所示:
1、将锁记录中的Owner指针指向加锁的对象(存放对象地址);
2、将锁对象的对象头的MarkWord替换为指向锁记录的指针。[这里也就说明了为什么还可以使用对象的hashcode
这二步如下图所示:
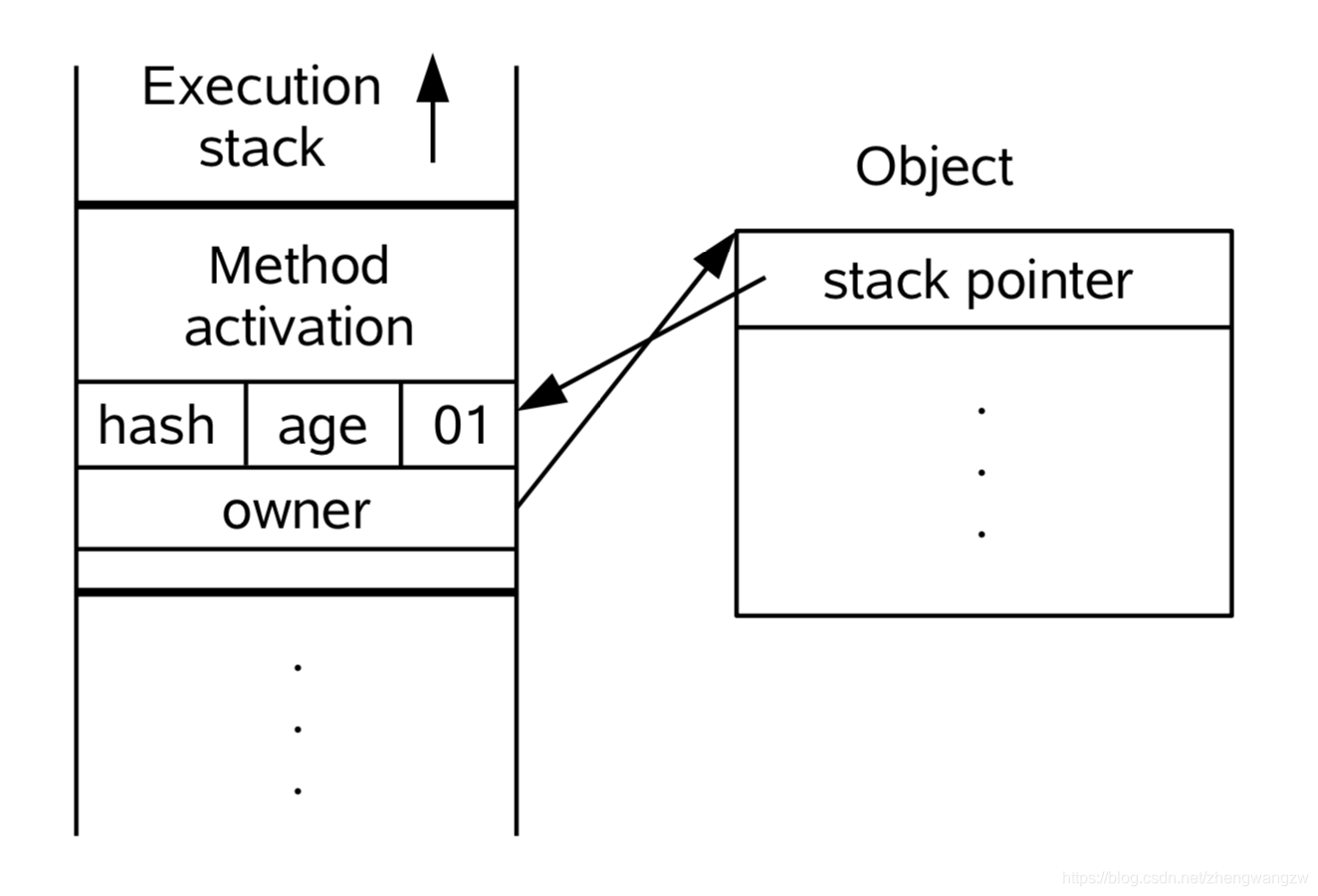
这时锁标志位变成 00 ,表示轻量级锁
所以上最开始的总结图中,可以看到,为什么只能够看到Lock Record的值和锁表示00了。
轻量级锁升级到重量级锁
当锁升级为轻量级锁之后,如果依然有新线程过来竞争锁,首先新线程会自旋尝试获取锁,尝试到一定次数(默认10次)依然没有拿到,锁就会升级成重量级锁。
那么为什么这么设计?
一般来说,同步代码块内的代码应该很快就执行结束,这时候线程B 自旋一段时间是很容易拿到锁的,但是如果不巧,没拿到,自旋其实就是死循环,很耗CPU的,所以就直接转成重量级锁咯,这样就不用了线程一直自旋了。减少CPU的消耗
升级到了重量级锁后,可以看到对象头中只会存在一个ObjectPointer了。
那么下面再来看下这个对象:
下图详细介绍重要变量的作用
ObjectMonitor() {
_header = NULL;
_count = 0; // 重入次数(syncronized支持可重入)
_waiters = 0, // 等待线程数
_recursions = 0;
_object = NULL;
_owner = NULL; // 当前持有锁的线程
_WaitSet = NULL; // 调用了 wait 方法的线程被阻塞 放置在这个集合中
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ;
FreeNext = NULL ;
_EntryList = NULL ; // 等待锁 处于block的线程的集合 有资格成为候选资源的线程
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
}
对象关联的 ObjectMonitor 对象有线程内部竞争锁的机制,在多线程场景下,因为抢不到锁而且自旋失败的情况下,将会进入到WaitSet队列中来,等待其他的线程执行Object.notify() or Object.notifyAll() 将该线程唤醒。然后该线程又进入到EntryList中来。
这段解释来自Thread类对WAITING状态的描述:
A thread that is waiting indefinitely for another thread to perform a particular action is in this state.
A thread in the waiting state is waiting for another thread to perform a particular action. For example, a thread that has called Object.wait() on an object is waiting for another thread to call Object.notify() or Object.notifyAll() on that object. A thread that has called Thread.join() is waiting for a specified thread to terminate.
如下图所示:
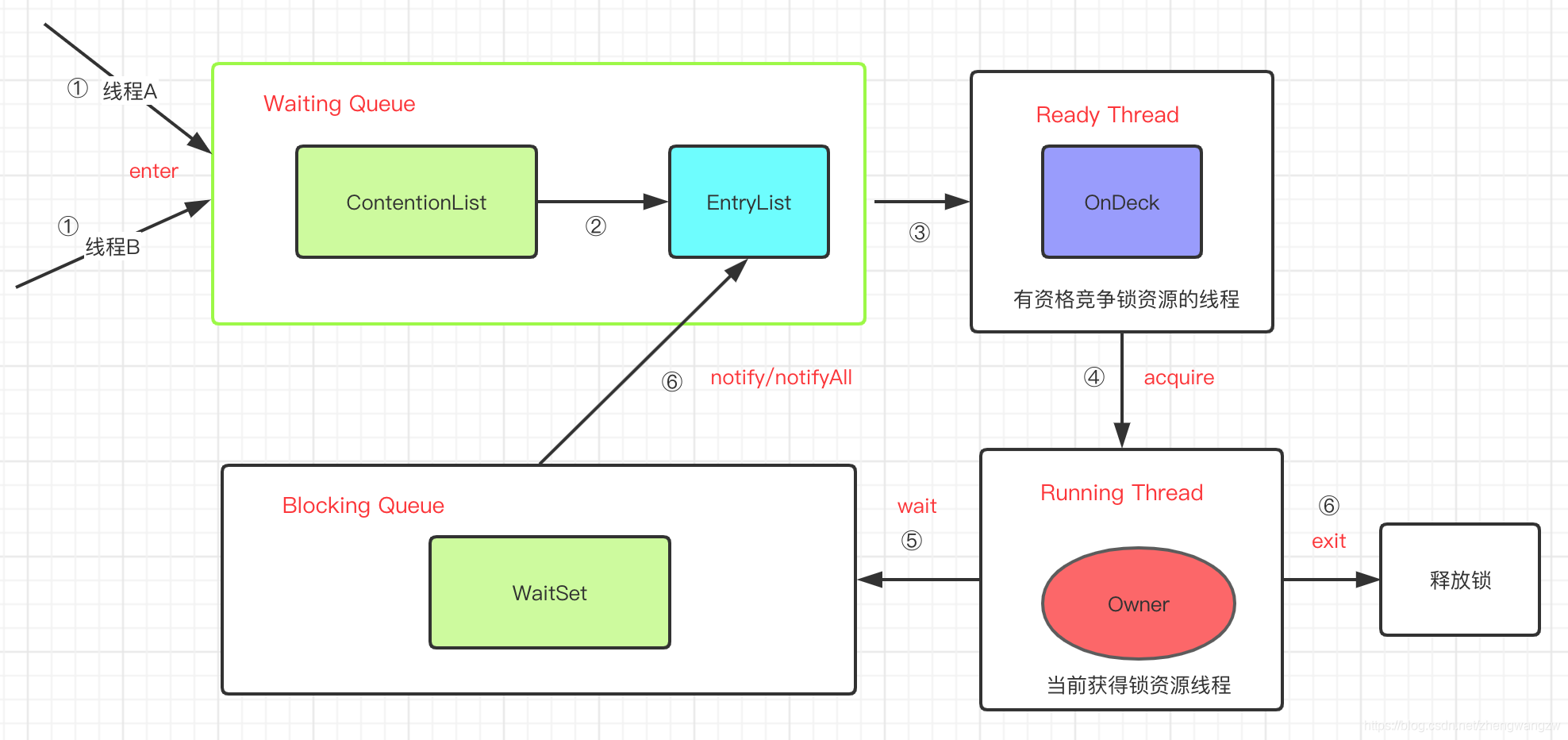
因为在ObjectMonitor中没有体现出来ContentionList,首先说明下ContentionList集合的由来。
JVM 每次从Waiting Queue 的尾部取出一个线程放到OnDeck作为候选者,但是如果并发比较高,Waiting Queue会被大量线程执行CAS操作,为了降低对尾部元素的竞争,将Waiting Queue 拆分成ContentionList 和 EntryList 二个队列, JVM将一部分线程移到EntryList 作为准备进OnDeck的预备线程。另外说明几点:
- 1、所有请求锁的线程首先被放在ContentionList这个竞争队列中;
- 2、Contention List 中那些有资格成为候选资源的线程被移动到 Entry List 中;
- 3、任意时刻,最多只有一个线程正在竞争锁资源,该线程被成为 OnDeck;
- 4、当前已经获取到所资源的线程被称为 Owner;
- 5、处于 ContentionList、EntryList中的线程都处于阻塞状态,该阻塞是由操作系统来完成的(Linux 内核下采用
pthread_mutex_lock内核函数实现的);。而WaitSet处于Waitting状态 ,
因为这里需要调用内核函数,设计到了用户态到内核态的切换,导致效率低下。所以这是JDK升级的原因之一。
JDK6之前的实现逻辑
- 1、当有两个线程t1、线程t2都要开始给 money变量 + 钱,要进行操作的时候 ,发现方法上加了synchronized锁,这时线程调度到t1线程执行,t1线程就抢先拿到了锁。拿到锁的步骤为:
-
- 将
ObjectMonitor中的 _owner设置成 t1线程; - 将 mark word 设置为 ObjectMonitor对象地址,锁标志位改为10;【此刻存在锁竞争,锁升级】
- 将t2线程阻塞放到 ContentionList 队列;
- 然后线程t1执行完临界区代码之后,就会将锁释放掉,然后唤醒阻塞着的线程,线程t2从ContentionList 进入到entrySet中,然后进入到OnDesk中来,获取得到锁之后,执行代码。
- 将
为什么要进行升级?
在JDK6之前,syncronzied的实现逻辑是依赖底层操作系统的 mutex 相关指令实现,加锁解锁需要在用户态和内核态之间切换,性能损耗非常明显。
但是Sun公司研究人员发现,大多数对象的加锁和解锁都是在特定的线程中完成。也就是出现线程竞争锁的情况概率比较低。他们做了一个实验,找了一些典型的软件,测试同一个线程加锁解锁的重复率,如下图所示,可以看到重复加锁比例非常高。早期JVM 有 19% 的执行时间浪费在锁上。
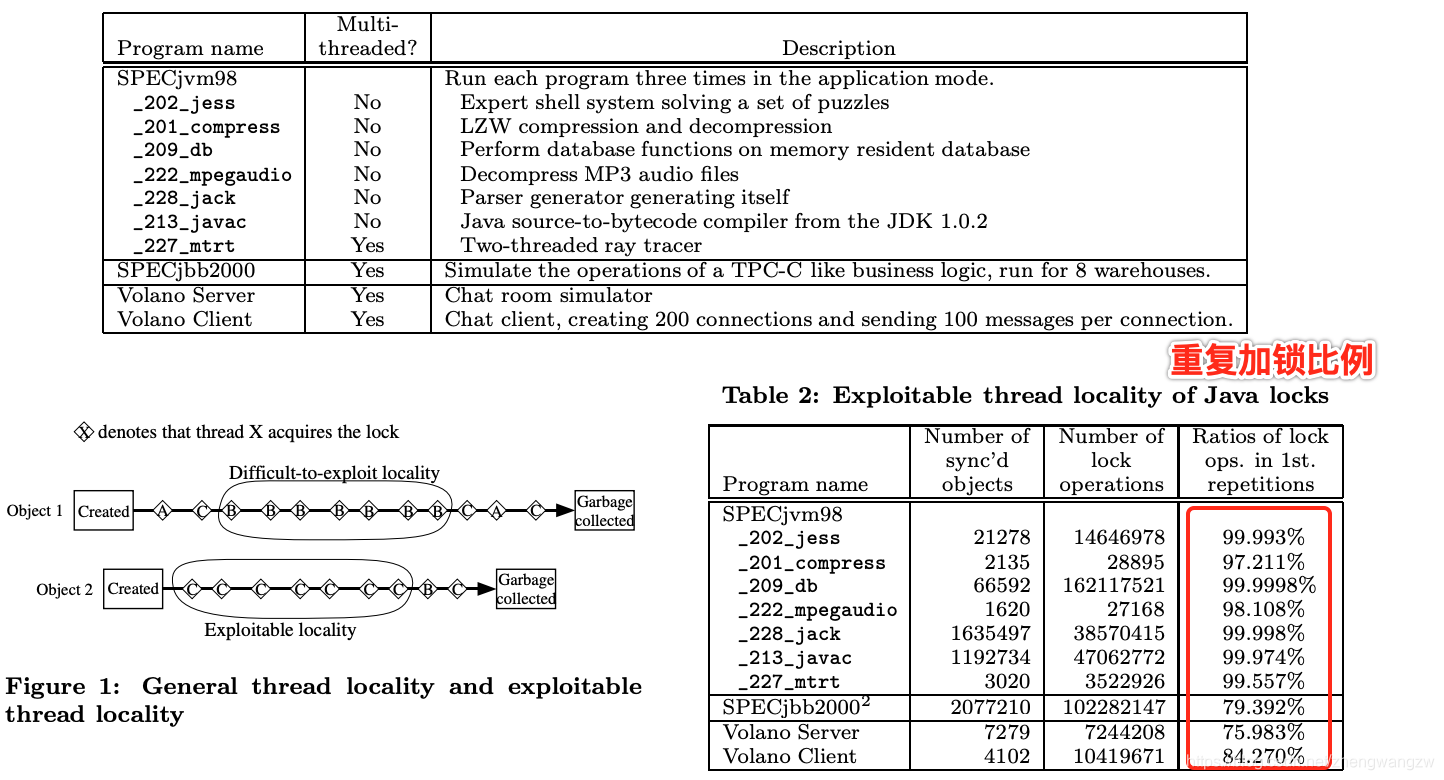
Thin locks are a lot cheaper than inflated locks, but their performance suffers from the fact that every compare-and-swap operation must be executed atomically on multi-processor machines, although most objects are locked and unlocked only by one particular thread.
It was reported that 19% of the total execution time was wasted by thread synchronization in an early version of Java virtual machine。
也就是说,对于大多数并发场景下,导致的锁竞争并不是这么剧烈。
在轻量级锁中就可以解决问题。
描述一种情况:t1线程持有锁执行完临界区代码之后,而t2线程此时才刚刚进来,然后执行代码。
从时间轴上来看,t1线程和t2线程并没有并发。
但是因为类似情况有点多,而获取得到锁需要利用操作系统的内置函数,进行用户态到内核态切换,导致了性能上的降低。
所以研究人员决定来进行升级。因此JDK 6 之后做了改进,引入了偏向锁和轻量级锁
测试waitset代码
来演示一下syncronzied关键字中的waitset集合中的线程顺序。
public class SyncronziedWaitSetTestOne {
private final static Logger logger = LoggerFactory.getLogger(SyncronziedWaitSetTestOne.class);
static List<Thread> threadList = new ArrayList<>();
static Object lock = new Object();
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
Thread thread = new Thread(() -> {
synchronized (lock) {
logger.info("thread execure");
// 这里无意义的睡眠,只是想让其在控制台上打印时好看一点
try {
TimeUnit.MICROSECONDS.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "t" + i);
threadList.add(thread);
}
logger.info("获取得到锁的顺序应该是正序0-9");
synchronized (lock){
for (Thread thread : threadList) {
logger.info("{}-->启动顺序,正序0-9",thread.getName());
thread.start();
try {
// 为什么满足能够顺序调用start方法!也就是说,控制线程进入到syncronzied中的顺序
// 但是具体取决于是哪个线程被OS调用,取决于OS
TimeUnit.MICROSECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
世界看输出结果:
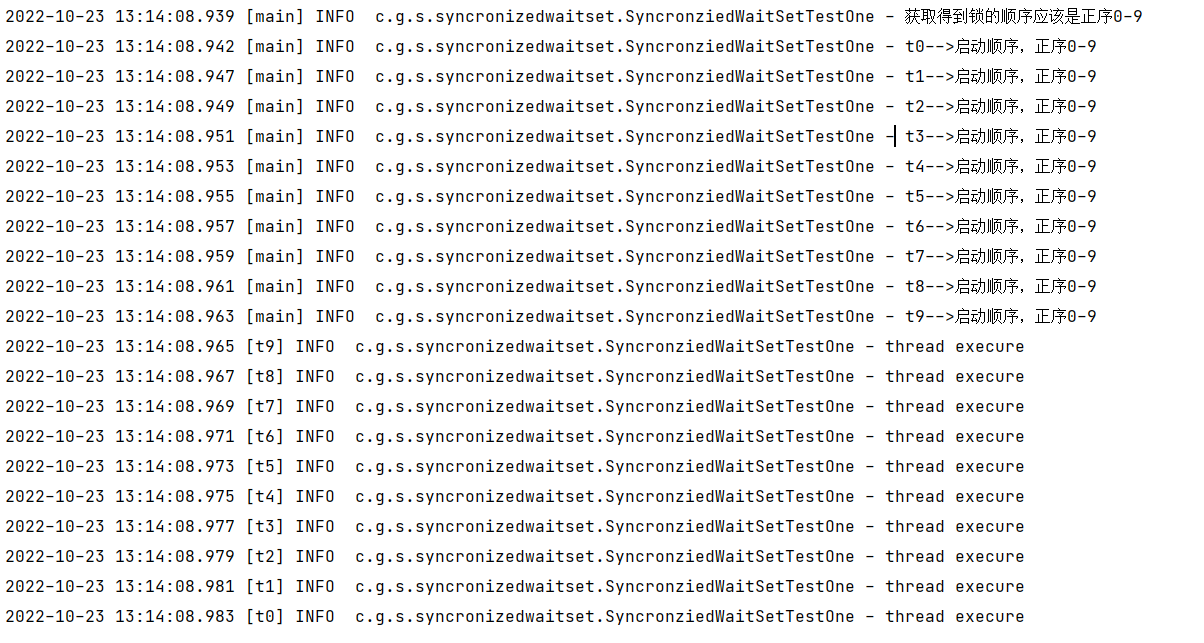
这里说明了waitset中是先进后出的。先进去的反而获取不到锁,而后出进去的反而先执行。
那么下面再次来证明一下这里的原理。
public class SyncronziedWaitSetTestTwo {
private final static Logger logger = LoggerFactory.getLogger(SyncronziedWaitSetTestTwo.class);
static Object lock = new Object();
static volatile boolean flag = false;
public static void main(String[] args) throws InterruptedException {
new Thread(()->{
synchronized (lock){
while (!flag){
logger.info("因为条件不满足而释放锁");
try {
lock.wait();
logger.info("被唤醒了,再次检查是否满足条件");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
logger.info("条件满足,执行临界区代码");
}
},"tom").start();
// 为了满足先进入到waitset集合中来
TimeUnit.MICROSECONDS.sleep(10);
synchronized (lock){
for (int i = 0; i < 5; i++) {
new Thread(()->{
synchronized (lock){
logger.info("当前当前名称是:{}",Thread.currentThread().getName());
}
},"normal"+i).start();
TimeUnit.MICROSECONDS.sleep(1);
}
flag = true;
lock.notifyAll();
logger.info("打印输出顺序");
}
}
}
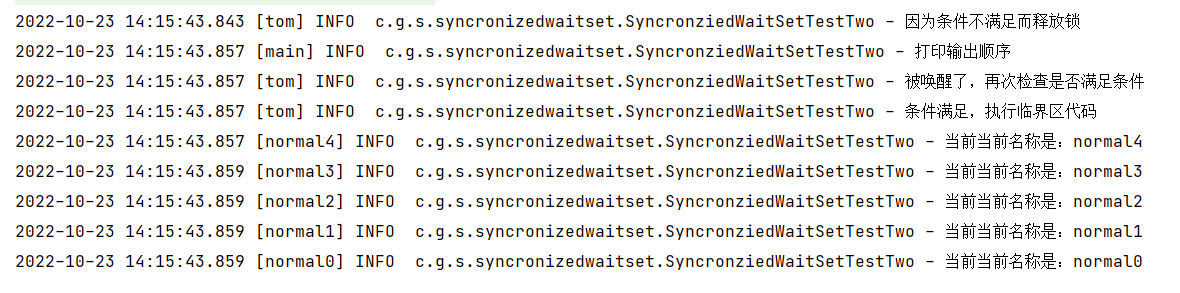
我在这里做了一个大胆的假设(因为没有看过底层C++实现)
我觉得在ContentionList 中应该是顺序进入的,但是在waitset中应该是采用了头插入且遍历的时候,也是从头部先获取得到线程。
那么再来总结一下,其中的状态转变:
如下所示:

五、syncronzied是非公平锁
和lock非公平锁有点类似
主要有以下二点原因:
- 1、Synchronized 在线程竞争锁时,首先做的不是直接进ContentionList 队列排队,而是尝试自旋获取锁(可能ContentionList 有别的线程在等锁),如果获取不到才进入 ContentionList,这明显对于已经进入队列的线程是不公平的;
- 2、另一个不公平的是自旋获取锁的线程还可能直接抢占 OnDeck 线程的锁资源。这明显对于已经进入队列的线程是不公平的;
六、锁的重偏向和批量撤销
对于一个类的对象来说,如果锁撤销次数太多,那么JVM会认为存在着问题。
偏向锁撤销的过程中:首先释放锁,然后将锁还原成无锁,然后复制对象头中的信息到对象头中去,然后升级成轻量级锁
当JVM撤销太多次了之后,JVM认为类设计存在着问题,将会进行批量撤销。
轻量级锁撤销到一定次数(默认20)之后,剩下的就不再撤销了,就再次重新偏向即可
JVM默认是>=20次的时候,会使用重偏向。但是20次以下不包含20,依然会进行锁的膨胀,先撤销,然后升级成轻量级锁
但是如果此时此刻,还有另外一个线程仍然发生了锁的撤销,在达到40次后,JVM认为严重出现了问题。直接将锁升级成轻量级锁。
写一段代码来表示:
public class BatchRevokeTestOne {
private final static Logger logger = LoggerFactory.getLogger(BatchRevokeTestOne.class);
public static void main(String[] args) throws InterruptedException {
List<Abc> abcList = new ArrayList<>();
// 为了让对象头中呈现出无锁可偏向
TimeUnit.SECONDS.sleep(5);
Thread t1 = new Thread(() -> {
for (int i = 0; i < 200; i++) {
Abc abc = new Abc();
// 让abc对象都偏向t1线程
synchronized (abc) {
abcList.add(abc);
}
}
// 为了不让线程ID复用
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "t1");
t1.start();
// 为了让线程t1先启动
TimeUnit.MICROSECONDS.sleep(10);
Thread t2 = new Thread(() -> {
int cout = 1;
for (Abc abc : abcList) {
synchronized (abc) {
// 应该是轻量级锁了!但是依然是偏向锁前几个是轻量级锁,而后面的将成为偏向锁
if (cout == 15) {
logger.info("当前对象是list集合中的第{}个对象,应该是轻量锁000,对应的对象头是:{}", cout + 1, ClassLayout.parseInstance(abc).toPrintable());
}
// 20之后的就应该是批量锁撤销
if (cout == 20) {
logger.info("当前对象是list集合中的第{}个对象,应该是偏向锁101,对应的对象头是:{}", cout, ClassLayout.parseInstance(abc).toPrintable());
return;
}
}
cout++;
}
}, "t2");
t2.start();
t2.join();
logger.info("再次将当前类的对象进行偏向");
// 但是如果此时锁对象仍然有偏向其他线程了的,那么就会导致40之后的升级到轻量级锁
// 批量撤销
new Thread(() -> {
int count = 1;
for (int i = 0; i < abcList.size(); i++) {
Abc abc = abcList.get(i);
synchronized (abc){
if (count==15){
logger.info("count为:{},应该是偏向锁101,对应的对象头是:{}", count,ClassLayout.parseInstance(abc).toPrintable());
}
if (count==25){
logger.info("count为:{},应该是轻量级锁000,对应的对象头是:{}",count, ClassLayout.parseInstance(abc).toPrintable());
}
if (count==70){
logger.info("count为:{},应该是轻量级锁000,对应的对象头是:{}",count, ClassLayout.parseInstance(abc).toPrintable());
return;
}
}
count++;
}
}, "t3").start();
}
}
日志打印:
2022-10-23 15:47:20.714 [t2] INFO c.g.s.syncronizedbatchrevoke.BatchRevokeTestOne - 当前对象是list集合中的第16个对象,应该是轻量锁000,对应的对象头是:com.guang.syncronized.syncronizedbatchrevoke.Abc object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 78 f1 fd 1e (01111000 11110001 11111101 00011110) (519958904)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 34 6b 01 f8 (00110100 01101011 00000001 11111000) (-134124748)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
2022-10-23 15:47:20.720 [t2] INFO c.g.s.syncronizedbatchrevoke.BatchRevokeTestOne - 当前对象是list集合中的第20个对象,应该是偏向锁101,对应的对象头是:com.guang.syncronized.syncronizedbatchrevoke.Abc object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 f9 a4 1d (00000101 11111001 10100100 00011101) (497350917)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 34 6b 01 f8 (00110100 01101011 00000001 11111000) (-134124748)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
2022-10-23 15:47:20.720 [main] INFO c.g.s.syncronizedbatchrevoke.BatchRevokeTestOne - 再次将当前类的对象进行偏向
2022-10-23 15:47:20.722 [t3] INFO c.g.s.syncronizedbatchrevoke.BatchRevokeTestOne - count为:15,应该是偏向锁101,对应的对象头是:com.guang.syncronized.syncronizedbatchrevoke.Abc object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) a8 f3 ed 1e (10101000 11110011 11101101 00011110) (518910888)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 34 6b 01 f8 (00110100 01101011 00000001 11111000) (-134124748)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
2022-10-23 15:47:20.723 [t3] INFO c.g.s.syncronizedbatchrevoke.BatchRevokeTestOne - count为:25,应该是轻量级锁000,对应的对象头是:com.guang.syncronized.syncronizedbatchrevoke.Abc object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 91 7b 1e (00000101 10010001 01111011 00011110) (511414533)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 34 6b 01 f8 (00110100 01101011 00000001 11111000) (-134124748)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
2022-10-23 15:47:20.723 [t3] INFO c.g.s.syncronizedbatchrevoke.BatchRevokeTestOne - count为:70,应该是轻量级锁000,对应的对象头是:com.guang.syncronized.syncronizedbatchrevoke.Abc object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 91 7b 1e (00000101 10010001 01111011 00011110) (511414533)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 34 6b 01 f8 (00110100 01101011 00000001 11111000) (-134124748)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
可以看到在20次及其之后,是可以进行偏向的。
但是在进行20-40之间进行锁升级的时候,没有测试出来对应的效果。
写到最后
我总结一下全文内容
0、生产上既然用了syncronized关键字,那么一定是存在并发场景的。一般来说是需要禁用掉偏向锁的。
-XX:-UseBiasedLocking //关闭偏向锁(默认打开)
// 如果有大并发场景下,直接启用重量级锁
-XX:+UseHeavyMonitors //设置重量级锁
但是重量级锁其实现原理是通过操作系统调用MutexLock来保证竞态资源的互斥,所以会产生用户态与内核态的切换;
操作系统中的程序,一般都是在用户态下运行的。当程序需要借助操作系统来完成一些自己无法完成的操作时,便会从用户态切换到内核态,如果频繁切换,这样的开销还是很大的
CAS:
比较实际内存值与预期内存值,相同则更新内存值,否则什么都不做(这是Java调用的一串cpu指令,不具体讨论)
更新失败的原因就是各个线程cpu缓存的可见性问题
1、syncronzied为什么可以保证在并发场景下线程同步;
2、jdk6之前syncronized关键字的实现过程以及为什么做优化;
3、jdk6之后的syncronized关键字的四种状态以及状态之间的切换;
4、几种特殊情况的状态转换;
5、查看对象头中的几种特殊情况;
6、waitset的顺序性问题;
7、锁的撤销和重偏向问题;
禁用掉偏向锁,之后,加锁之后的代码:
public class SyncronizedFobbindonBiasTest {
private final static Logger logger = LoggerFactory.getLogger(SyncronizedFobbindonBiasTest.class);
public static void main(String[] args) throws InterruptedException {
TimeUnit.SECONDS.sleep(5);
Object lock = new Object();
logger.info("无锁不可偏向,001,打印对象头:{}", ClassLayout.parseInstance(lock).toPrintable());
synchronized (lock){
logger.info("偏向锁,000,打印对象头:{}", ClassLayout.parseInstance(lock).toPrintable());
}
}
}
打印输出结果:
2022-10-23 16:13:41.737 [main] INFO c.g.s.s.SyncronizedFobbindonBiasTest - 无锁不可偏向,打印对象头:java.lang.Object object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) e5 01 00 f8 (11100101 00000001 00000000 11111000) (-134217243)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
2022-10-23 16:13:41.741 [main] INFO c.g.s.s.SyncronizedFobbindonBiasTest - 偏向锁,打印对象头:java.lang.Object object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 88 f4 20 03 (10001000 11110100 00100000 00000011) (52491400)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) e5 01 00 f8 (11100101 00000001 00000000 11111000) (-134217243)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total

 浙公网安备 33010602011771号
浙公网安备 33010602011771号