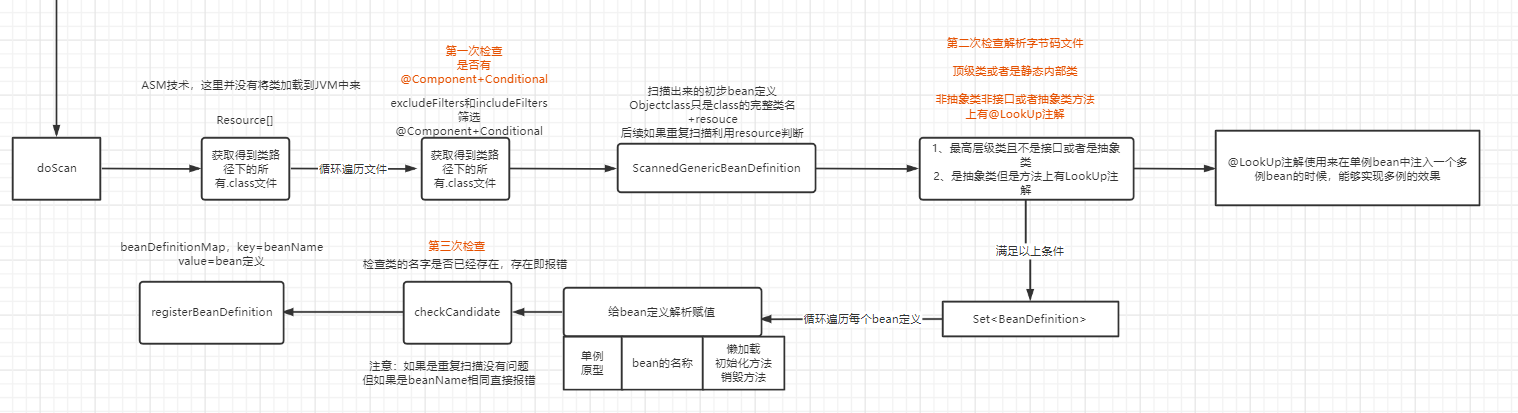
spring的扫描过程
bean的生命周期
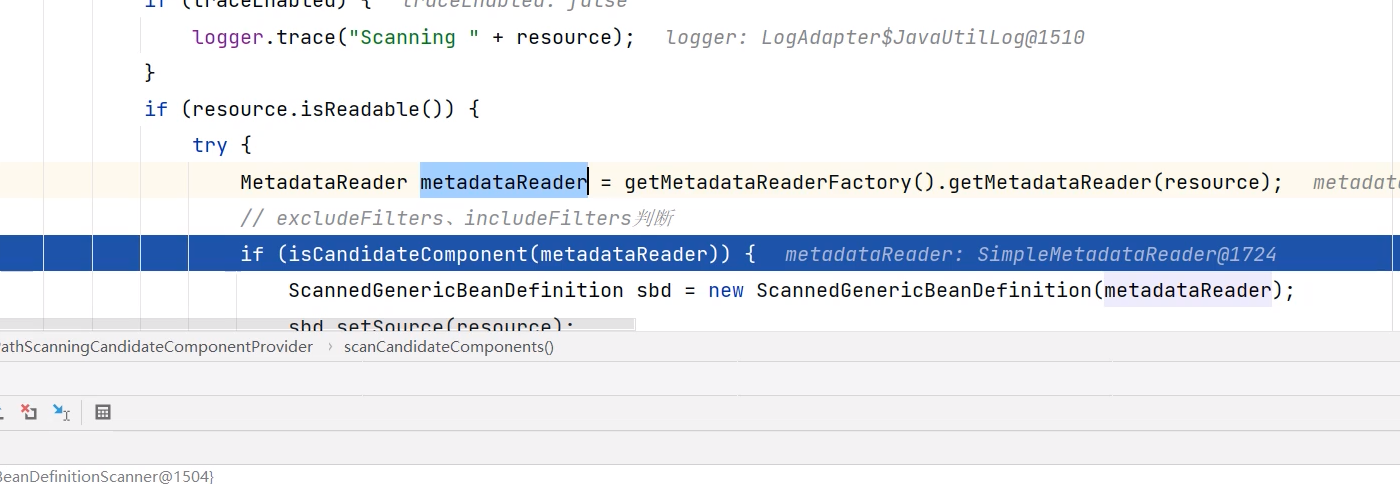
利用元数据读取器来读取class文件对应的注解、名称、接口、父类、抽象类等等数据。总之可以拿到类中所有的信息。
利用的是ASM技术,不把类加载到JVM中来,而是使用基于文件层面上的技术来进行实现的。
这里的metadataReader就相当于是类的一个代表,操作这个对象,就相当于是操作对应的class文件来做一些解析动作。


因为在创建ClassPathBeanDefinitionScanner的时候默认会来注册一个包含的过滤器:
this.includeFilters.add(new AnnotationTypeFilter(Component.class));
也就是说只要是类上加上了@Component注解,就会匹配成功,然后进行Conditional的判断,也就是条件匹配。
而添加上@Component只说明拥有了成为bean的可能(这里并不是说一定可能),如果不包含,那么就不可能成为一个bean。
如果可以,那么还可以指定进行排除的过滤器,可以看下对应的过滤器的说明。
继续说明@Conditional的匹配过程:
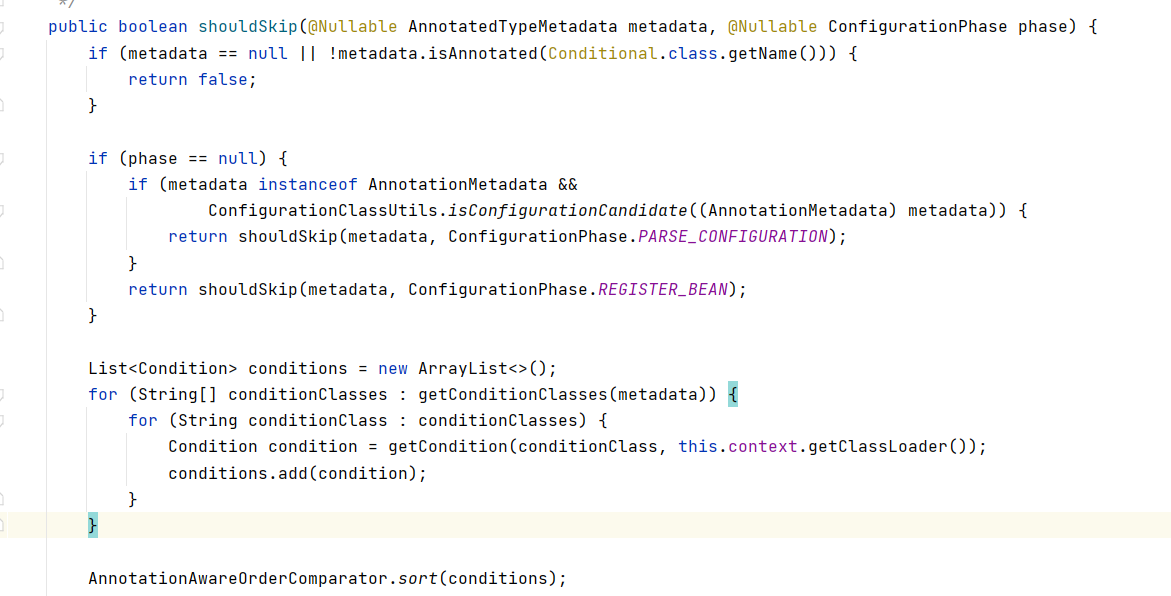
如果说类上没有@Conditional注解,那么表示的是不要跳过;看下方法前面是有一个!非操作。
而类上如果有@Conditional注解,那么则说明需要来进行匹配,调用对应的match方法来进行匹配选择,看看是否匹配,如果匹配那么则添加进来,进行下一步的操作。
举一个例子:
@Component
public class User{}
因为没有@Conditional注解,那么就添加进去。
再举一个有@Conditional注解的:
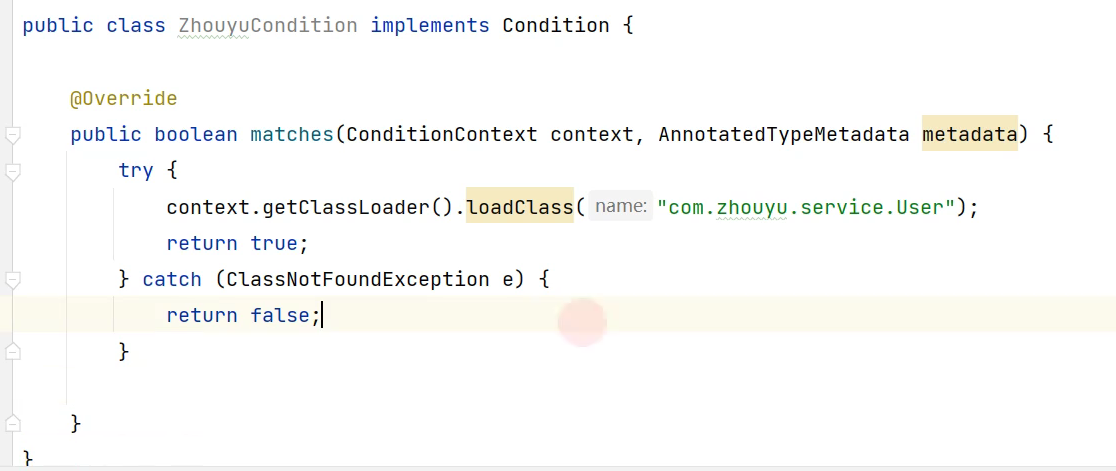
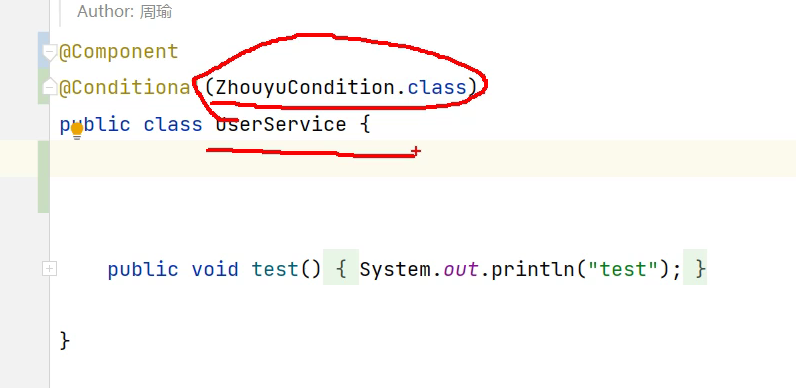
如果想要UserService成为一个bean,那么需要在类路径下找到com.zhouyu.service.User这个类之后,返回true,代表的是UserService才能够成为一个bean。
如果没有,那么UserService将不能够成为一个候选的bean。也就是说直接排除掉了成为bean的可能了。
主要过程就是说:扫描到了UserService这个class文件,判断里面有@Conditional注解,拿到里面的ZhouyuConditional的类,判断里面的match方法是否成立。如果成立了,那么UserService表示的是可能会成为一个bean。
上面的过程成立之后,下面紧接着会创建一个简单扫描过后的bean定义:
public ScannedGenericBeanDefinition(MetadataReader metadataReader) {
Assert.notNull(metadataReader, "MetadataReader must not be null");
this.metadata = metadataReader.getAnnotationMetadata();
// 这里只是把className设置到BeanDefinition中
setBeanClassName(this.metadata.getClassName());
setResource(metadataReader.getResource());
}
需要注意的是,这里的beanClassName是一个Object属性。而不是具体的class,因为这个时候只是简单的class文件而已,还没有真正的成为一个class对象。所以这里最开始存的是全限定类名。因为方便后来如果需要来进行加载的时候来进行加载。
只有真正的利用到这个类的时候,才会去加载来创建对象。
然后进行第二个判断:
protected boolean isCandidateComponent(AnnotatedBeanDefinition beanDefinition) {
AnnotationMetadata metadata = beanDefinition.getMetadata();
return (metadata.isIndependent() && (metadata.isConcrete() ||
(metadata.isAbstract() && metadata.hasAnnotatedMethods(Lookup.class.getName()))));
}
metadata.isIndependent():判断类是不是顶级类或者是加了static关键字修饰的静态内部类;
metadata.isConcrete():判断是不是接口或者是抽象类;
metadata.isAbstract():判断是不是抽象类;
metadata.hasAnnotatedMethods(Lookup.class.getName()):判断方法上是否有@LookUp注解。
总结来说:这里是基于class文件来判断类的一些信息。
要求是类必须是顶级类或者是加了static修饰的内部类+(要么是非抽象类+要么是非接口 或者 抽象类的方法上有@Lookup注解)
如果在接口或者是抽象类上面加了一个@Component注解,那么是不会成为一个bean的。
顶级类:
public class A{
}
静态内部类:
public class A{
public static class B{
}
}
那么生成的静态内部类如下所示:

因为如果是非静态内部类的情况下,如果B符合,那么创建对象还需要基于外部类创建对象来进行生成,而如果外部类是不符合条件的,那么这里就会有问题。
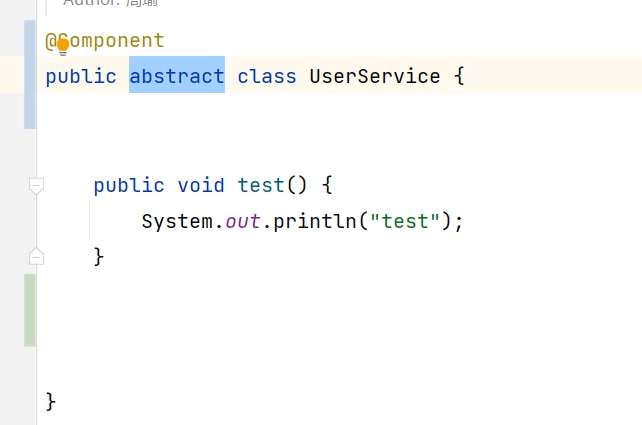
即使是使用上面这种方式,是无法成为一个bean的,在获取得到UserService这个类型的bean的时候会报错。
但是如果修改一下

修改成为这种方式的话,再来进行获取得到UserService类型的bean的时候,发现是可以成功进行操作的。
那么来看下具体的@LookUp注解使用场景:
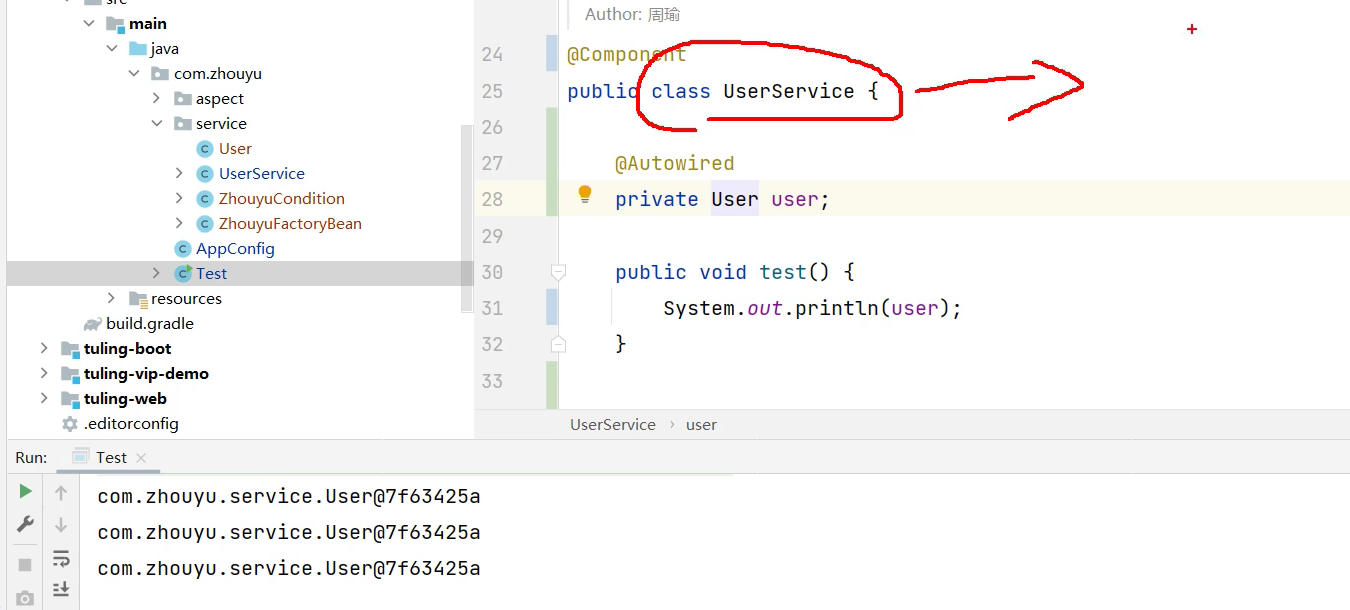
这里的User是多例,使用单例UserService多次调用test方法的时候,打印的user对象是同一个。
但是这里想要的打印的user每次都是不同的(因为user是多列),那么这里只需要在test方法上面加上@LookUp注解即可。
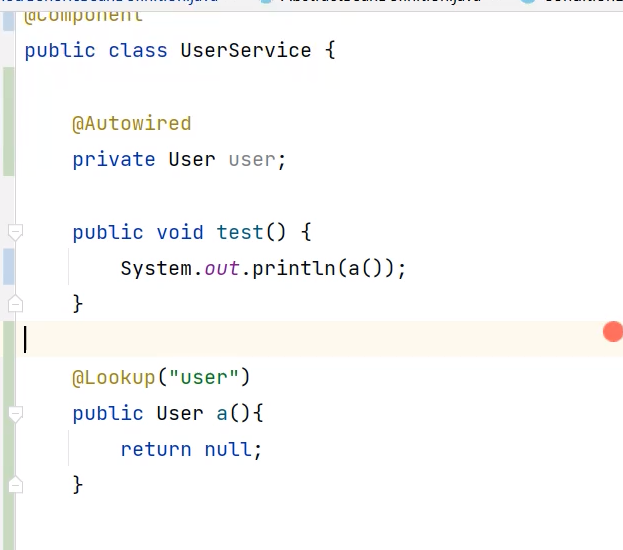
以上步骤结束后会添加到扫描完成之后的bean。但是这里得到的bean的scope、懒加载等等都没有解析得到对应的值,只有一个类的完整限定类名是有用的。
那么加下来将获取得到的所有的bean的定义开始来进行解析了。
开始一轮循环解析:
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
// 解析@Lazy、@Primary、@DependsOn、@Role、@Description
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
...........
}
首先来解析@Scope注解中的值;然后生成bean的名称;接着填充一些默认的属性;开始解析@Lazy、@Primary、@DependsOn、@Role、@Description等注解。
看下默认赋值:
protected void postProcessBeanDefinition(AbstractBeanDefinition beanDefinition, String beanName) {
// 设置BeanDefinition的默认值
beanDefinition.applyDefaults(this.beanDefinitionDefaults);
// AutowireCandidate表示某个Bean能否被用来做依赖注入
if (this.autowireCandidatePatterns != null) {
beanDefinition.setAutowireCandidate(PatternMatchUtils.simpleMatch(this.autowireCandidatePatterns, beanName));
}
}
默认的值:
public void applyDefaults(BeanDefinitionDefaults defaults) {
// 懒加载等等
Boolean lazyInit = defaults.getLazyInit();
if (lazyInit != null) {
setLazyInit(lazyInit);
}
// 默认不会进行依赖注入
setAutowireMode(defaults.getAutowireMode());
setDependencyCheck(defaults.getDependencyCheck());
// 初始化方法和销毁方法等等
setInitMethodName(defaults.getInitMethodName());
setEnforceInitMethod(false);
setDestroyMethodName(defaults.getDestroyMethodName());
setEnforceDestroyMethod(false);
}
即使默认的已经有了,但是还会来解析@Lazy、@Primary、@DependsOn、@Role、@Description等注解。
看看有没有指定的值,放置覆盖掉开发者自己定义的。如果没有设置,那么使用默认的即可。
然后给每个正在解析的注解来进行赋值。赋值完成之后,那么这个时候就可以将bean放入到bean定义map中来了。
if (checkCandidate(beanName, candidate)) {
// bean定义中没有bean的名称,这里用BeanDefinitionHolder来进行存储的
// 最终还是会从definitionHolder获取得到bean定义的
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
// 添加到这里来,不管是原型bean还是单例bean的定义
beanDefinitions.add(definitionHolder);
// 注册
registerBeanDefinition(definitionHolder, this.registry);
}
那么看下这个check方法

check方法主要是看有没有重复的bean进行定义,如果bean名称重复了,大多数情况下都会直接抛出这里异常信息。
那么什么时候不抛出异常?而是直接执行到上面的兼容方法中来呢?
重复注册扫描的时候,但是也不会将在bean定义map中重复定义。
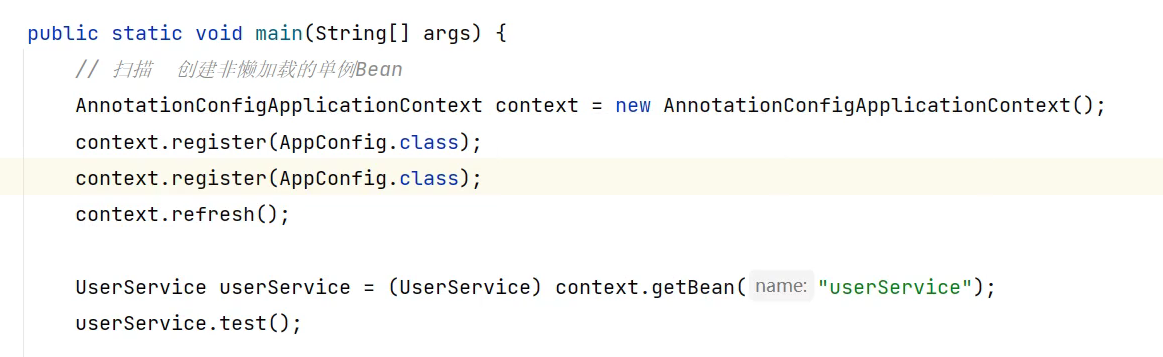
这里因为重复扫描,而扫描两次,但是第二次的扫描过程中如果有添加进来的,那么这里将不会来进行注册。
判断的逻辑是什么?
protected boolean isCompatible(BeanDefinition newDefinition, BeanDefinition existingDefinition) {
return (!(existingDefinition instanceof ScannedGenericBeanDefinition) || // explicitly registered overriding bean
(newDefinition.getSource() != null && newDefinition.getSource().equals(existingDefinition.getSource())) || // scanned same file twice
newDefinition.equals(existingDefinition)); // scanned equivalent class twice
}
根据bean定义中的source,这下子终于明白了为什么在最开始的时候设置source了。
这里总结一下:如果是bean的名称冲突,那么这里将会来报错;如果是扫描多次的时候,这里不会报错,也不会将再次扫描进来的添加到bean定义map中来。
原型也会存在里面,在创建的时候只需要根据原型bean来进行创建即可。
那么至此,扫描过程结束。这个时候bean定义map中会有很多的bean定义了。
那么接下来就需要根据bean定义来创建bean了。
是创建非懒加载的单例bean。
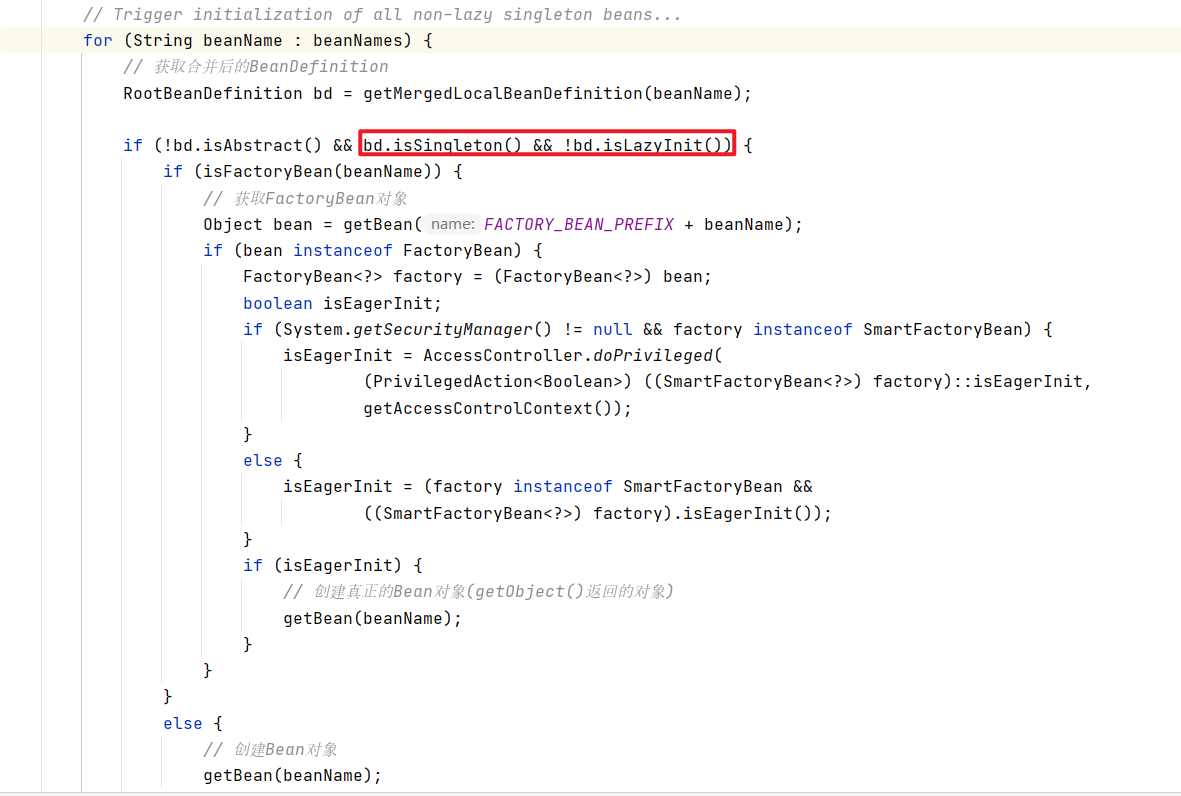
循环挨个判断每个bean,从if条件判断中可以看到是非懒加载的单例bean定义对象才会来创建得到对应的对象。
注意:判断抽象的bean定义对象,而不是判断bean定义对应的类是抽象的
通常都是xml中可以来定义抽象bean定义。

那么这种抽象bean定义的作用是什么?

子类bean定义继承父bean定义中的属性,比如说懒加载、单例原型等等。抽象bean定义不能生成bean,但是对应的子类bean定义是可以的。
因为有时候需要使用到父类bean定义中的,这里也相当于是做一个抽取,那么不同的子类来进行继承即可。
这就相当于是java中的父类是抽象类,而抽象类是无法来进行实例化的。只有不是抽象的子类才可以。
那么就意味着:抽象bean定义只有一个且不能够修改(其他的bean定义也会来进行继承),而子类都是不同的。
最终需要来进行合并bean,从而形成新的bean定义。在合并的过程中,如果子类有自己定义的属性,那么就使用自己的;如果没有,那么就使用父类中的属性。
注意合并bean之后,一定是新的bean。加入A、B、C、D四个bean定义。
对于A来说是抽象的父定义,B、C为非抽象的bean定义。B、C继承了A,那么B、C中没有的,会来继承父类的;如果B来继承的时候,此时把父类中的给属性改了,C再来进行继承的时候就会有问题。
所以说A、B、C都保持原始的状态,如果生成的时候,生成一个新的bean定义来进行保存即可。
那么如果还有一个bean定义D继承了非抽象的B或者是C,那么这里也直接进行生成即可。
所以这里考虑到应该有一个递归实现。这里也确实是这样子来进行操作的。
总结一下这里的步骤:
所有的bean定义首先会来进行合并bean定义,在之后的使用过程中都是来使用合并过后的bean定义。
FactoryBean
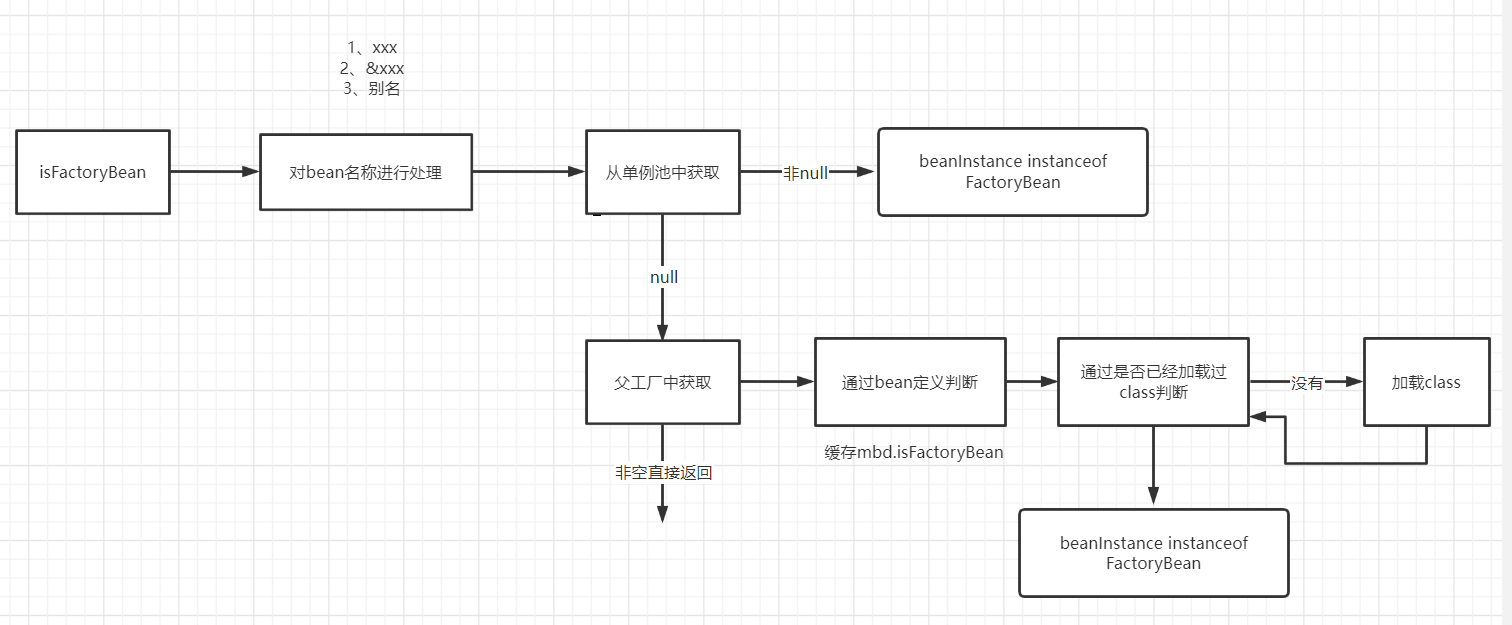
在创建的过程中,在判断是否是一个FactoryBean。
这个方法在源码中的很多地方都会使用到,是一个通用的,所以考虑的地方地方比较多。
public boolean isFactoryBean(String name) throws NoSuchBeanDefinitionException {
String beanName = transformedBeanName(name);
Object beanInstance = getSingleton(beanName, false);
if (beanInstance != null) {
return (beanInstance instanceof FactoryBean);
}
// No singleton instance found -> check bean definition.
if (!containsBeanDefinition(beanName) && getParentBeanFactory() instanceof ConfigurableBeanFactory) {
// No bean definition found in this factory -> delegate to parent.
return ((ConfigurableBeanFactory) getParentBeanFactory()).isFactoryBean(name);
}
return isFactoryBean(beanName, getMergedLocalBeanDefinition(beanName));
}
这里的判断很有意思。首先根据名称来获取得到bean定义,而在创建的时候单例池中肯定时候没有的
如果不是在创建的过程中来进行获取得到的时候,那么基于class对象就很容易的判断出来。
如果说子类工厂中没有,那么从父类工厂中获取得到。
父子bean工程:
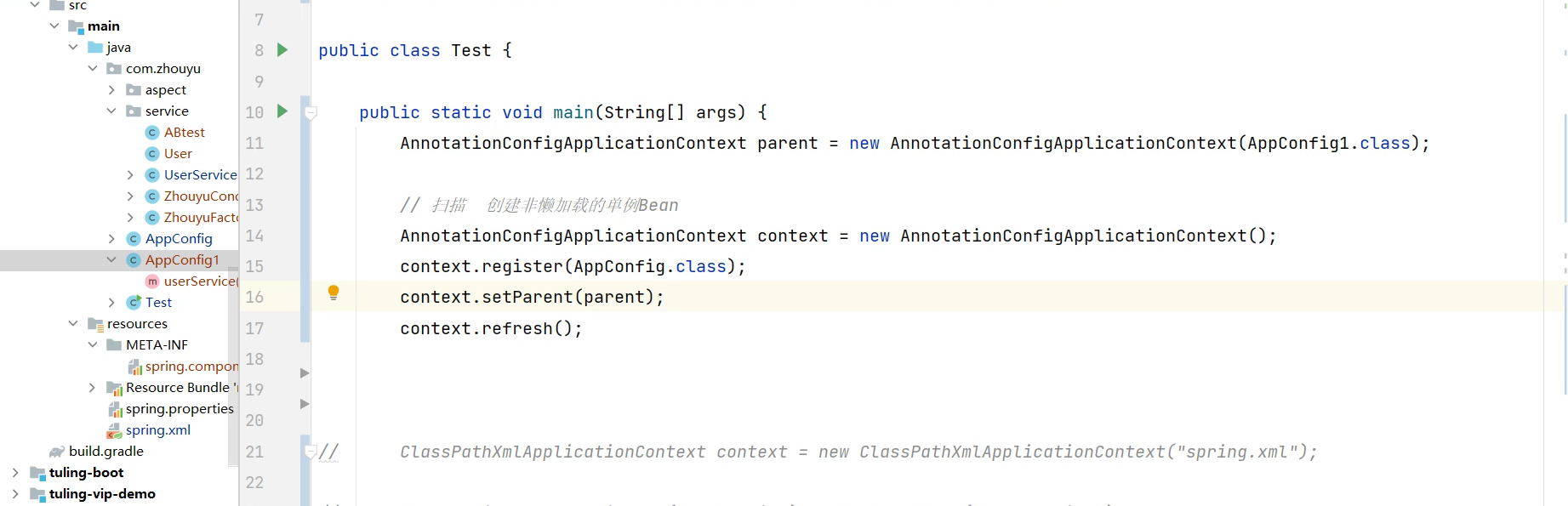
两个工厂扫描的是不同的包路径。【spring和springmvc进行整合的时候需要使用到】
那么无论是父bean工厂,还是子类工厂,最终都需要判断是不是isFactoryBean。
protected boolean isFactoryBean(String beanName, RootBeanDefinition mbd) {
Boolean result = mbd.isFactoryBean;
if (result == null) {
// 根据BeanDefinition推测Bean类型(获取BeanDefinition的beanClass属性)
Class<?> beanType = predictBeanType(beanName, mbd, FactoryBean.class);
// 判断是不是实现了FactoryBean接口
result = (beanType != null && FactoryBean.class.isAssignableFrom(beanType));
// 这里来进行置换
mbd.isFactoryBean = result;
}
return result;
}
可以从这里看到bean定义中的isFactoryBean起到了一个缓存的作用。因为下一次在使用的时候再次来进行判断的时候,就可以直接获取得到对应的值。
接着看,下面还会有缓存的思想。
protected Class<?> predictBeanType(String beanName, RootBeanDefinition mbd, Class<?>... typesToMatch) {
Class<?> targetType = mbd.getTargetType();
if (targetType != null) {
return targetType;
}
if (mbd.getFactoryMethodName() != null) {
return null;
}
return resolveBeanClass(mbd, beanName, typesToMatch);
}
第一次来的时候上面的肯定都不会执行,继续
// 如果beanClass被加载了 也就是说是否是class对象
if (mbd.hasBeanClass()) {
return mbd.getBeanClass();
}
// 如果beanClass没有被加载
if (System.getSecurityManager() != null) {
return AccessController.doPrivileged((PrivilegedExceptionAction<Class<?>>)
() -> doResolveBeanClass(mbd, typesToMatch), getAccessControlContext());
}
else {
// 真正的加载类到JVM中
return doResolveBeanClass(mbd, typesToMatch);
}
执行到了doResolveBeanClass这一步之后,那么上面的mbd.getBeanClass()就为一个真正的class了。
再来进行判断的时候targetType也有值了,最终isFactoryBean也有值了。所以一次调用之后,就可以确定是否是真的factorybean,后续的就不需要再次来进行判断了。
if (isFactoryBean(beanName)) {
// 获取FactoryBean对象
Object bean = getBean(FACTORY_BEAN_PREFIX + beanName);
if (bean instanceof FactoryBean) {
FactoryBean<?> factory = (FactoryBean<?>) bean;
boolean isEagerInit;
if (System.getSecurityManager() != null && factory instanceof SmartFactoryBean) {
isEagerInit = AccessController.doPrivileged(
(PrivilegedAction<Boolean>) ((SmartFactoryBean<?>) factory)::isEagerInit,
getAccessControlContext());
}
else {
isEagerInit = (factory instanceof SmartFactoryBean &&
((SmartFactoryBean<?>) factory).isEagerInit());
}
if (isEagerInit) {
// 创建真正的Bean对象(getObject()返回的对象)
getBean(beanName);
}
}
}
这一段的逻辑就是去创建原始的实现了factorybean接口的类的bean,然后来判断是否实现了SmartFactoryBean中的isEagerInit方法来进行添加加载这里的getObject所产生的对象。
那么紧接着会来创建对应的对象,因为getBean这个方法用的地方是在是太多了,已经成了一个通用的方法了。
所以这里考虑的问题什么的复杂。
protected <T> T doGetBean(
String name, @Nullable Class<T> requiredType, @Nullable Object[] args, boolean typeCheckOnly)
throws BeansException {
// name有可能是 &xxx 或者 xxx,如果name是&xxx,那么beanName就是xxx
// name有可能传入进来的是别名,那么beanName就是id
String beanName = transformedBeanName(name);
Object beanInstance;
// Eagerly check singleton cache for manually registered singletons.
Object sharedInstance = getSingleton(beanName);
if (sharedInstance != null && args == null) {
if (logger.isTraceEnabled()) {
if (isSingletonCurrentlyInCreation(beanName)) {
logger.trace("Returning eagerly cached instance of singleton bean '" + beanName +
"' that is not fully initialized yet - a consequence of a circular reference");
}
else {
logger.trace("Returning cached instance of singleton bean '" + beanName + "'");
}
}
// 如果sharedInstance是FactoryBean,那么就调用getObject()返回对象
beanInstance = getObjectForBeanInstance(sharedInstance, name, beanName, null);
}
首先需要注意的是:在单例池中factorybean对应的bean的名称是xxx,而不是&xxx。如果如果是&xxx被传递进来了,那么这里会来得到单例池中的bean的名字,然后从单例池中来进行获取。获取得到之后再次来进行判断:
protected Object getObjectForBeanInstance(
Object beanInstance, String name, String beanName, @Nullable RootBeanDefinition mbd) {
// Don't let calling code try to dereference the factory if the bean isn't a factory.
// 如果&xxx,那么就直接返回单例池中的对象
if (BeanFactoryUtils.isFactoryDereference(name)) {
// 如果为null,就返回null
if (beanInstance instanceof NullBean) {
return beanInstance;
}
// 如果一个bean对象没有实现factorybean接口
// 而使用context.getBean("&xxx");的时候报错
if (!(beanInstance instanceof FactoryBean)) {
throw new BeanIsNotAFactoryException(beanName, beanInstance.getClass());
}
// 这里也会将缓存设置。
if (mbd != null) {
mbd.isFactoryBean = true;
}
// 这里返回的是单例池中的实现了factorybean接口的对象
return beanInstance;
}
// Now we have the bean instance, which may be a normal bean or a FactoryBean.
// If it's a FactoryBean, we use it to create a bean instance, unless the
// caller actually wants a reference to the factory.
// 单例池中的对象不是FactoryBean,则直接返回
if (!(beanInstance instanceof FactoryBean)) {
return beanInstance;
}
Object object = null;
if (mbd != null) {
mbd.isFactoryBean = true;
}
else {
// 从factoryBeanObjectCache中直接拿对象
object = getCachedObjectForFactoryBean(beanName);
}
if (object == null) {
// Return bean instance from factory.
FactoryBean<?> factory = (FactoryBean<?>) beanInstance;
// Caches object obtained from FactoryBean if it is a singleton.
if (mbd == null && containsBeanDefinition(beanName)) {
mbd = getMergedLocalBeanDefinition(beanName);
}
// synthetic为true,表示这个Bean不是正常的一个Bean,可能只是起到辅助作用的,所以这种Bean就不用去执行PostProcessor了
boolean synthetic = (mbd != null && mbd.isSynthetic());
object = getObjectFromFactoryBean(factory, beanName, !synthetic);
}
return object;
}
上面考虑的是所有的非懒加载的单例bean都加载完成之后的步骤。
那么如果是刚刚来进行加载呢?
扫描过程
判断FactoryBean

 浙公网安备 33010602011771号
浙公网安备 33010602011771号